创建不可变集合、Stream流、异常体系、日志框架
- 创建不可变集合
- 什么是不可变集合?
- 为什么要创建不可变集合?
- 如何创建不可变集合?
- 不可变集合的特点?
- Stream流
- Stream流的概述
- Stream流的获取
- Stream流的常用API(中间操作方法)
- Stream流的综合应用
- 收集Stream流
- 异常处理
- 异常概述、体系
- 常见运行时异常
- 常见编译时异常
- 异常的默认处理流程
- 编译时异常的处理机制
- 运行时异常的处理机制
- 异常处理使代码更稳健的案例
- 自定义异常
- 日志框架
- 日志技术的概述
- 日志技术体系结构
- Logback概述
- Logback快速入门
- Logback配置详解-输出位置,格式设置
- Logback配置详解-日志级别设置
创建不可变集合
什么是不可变集合?
1.不可变集合,就是不可被修改的集合。
2.集合的数据项在创建的时候提供,并且在整个生命周期都不可改变。否则报错。

为什么要创建不可变集合?
1.如果某个数据不能被修改,把它防御性地拷贝到不可变集合中是个很好的实践。
2.或者当集合对象被不可信的库调用时,不可变形式是安全的。
如何创建不可变集合?
1.在List、Set、Map接口中,都存在of方法,可以创建一个不可变的集合。
2.这个集合不能添加,不能删除,不能修改。

package unchange_collection;
import java.util.List;
import java.util.Map;
import java.util.Set;
public class CollectionDemo {
public static void main(String[] args) {
// 不可变的List集合
List<Double> lists = List.of(569.5,700.5,523.6,570.5);
System.out.println(lists);
// 不可变的Set集合
Set<String> names = Set.of("snow","dream","yang");
System.out.println(names);
// 不可变的Map集合
Map<String,Integer> maps = Map.of("java",2,"html",1,"mysql",3);
System.out.println(maps);
}
}
不可变集合的特点?
定义完成后不可以修改,或者添加、删除。
Stream流
Stream流的概述
什么是Stream流?
在Java8中,得益于Lambda所带来的函数式编程,引入了一个全新的Stream流概念。
目的:用于简化集合和数组操作的API。

案例:体验Stream流的作用
需求:按照下面的要求完成集合的创建和遍历
1.创建一个集合,存储多个字符串元素
List<String> list = new ArrayList<>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张强");
list.add("张三丰");
2.把集合中所有以“张”开头的元素存储到一个新的集合。
3.把“张”开头的集合中的长度为3的元素存储到一个新的集合。
4.遍历上一步得到的集合中的元素输出。
package d2_stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class StreamTest {
public static void main(String[] args) {
List<String> names = new ArrayList <>();
Collections.addAll(names, "张无忌","周芷若","赵敏","张强","张三丰");
System.out.println(names); // [张无忌, 周芷若, 赵敏, 张强, 张三丰]
// 从集合中找出姓张的放到新集合中
List<String> zhangList = new ArrayList <>();
for (String name : names) {
if(name.startsWith("张")){
zhangList.add(name);
}
}
System.out.println(zhangList); // [张无忌, 张强, 张三丰]
// 找名称长度是3的姓名
List<String> zhangThree = new ArrayList <>();
for (String name : zhangList) {
if(name.length() == 3){
zhangThree.add(name);
}
}
System.out.println(zhangThree); // [张无忌, 张三丰]
// 使用Stream实现的
names.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 3).forEach(s -> System.out.println(s));
}
}
Stream流的思想

Stream流式思想的核心:
1.先得到集合或者数组的Stream流(就是一根传送带)
2.把元素放上去
3.然后就用这个Stream流简化的API来方便的操作元素。
Stream流的获取
Stream流的三类方法:
1.获取Stream流:
创建一条流水线,并把数据放到流水线上准备进行操作。
2.中间方法:
流水线上的操作。一次操作完毕之后,还可以继续进行其他操作。
3.终结方法:
一个Stream流只能有一个终结方法,是流水线上的最后一个操作。
Stream操作集合或者数组的第一步是先得到Stream流,然后才能使用流的功能。
集合获取Stream流的方式:
1.可以使用Collection接口中的默认方法Stream()生成流

数组获取Stream流的方式:

package d2_stream;
import java.util.*;
import java.util.stream.Stream;
public class StreamTest1 {
public static void main(String[] args) {
/**---Collection集合获取流---*/
Collection<String> list = new ArrayList <>();
Stream<String> s = list.stream();
// Map集合获取流
Map<String,Integer> maps = new HashMap <>();
// 键流
Stream<String> keyStream = maps.keySet().stream();
// 值流
Stream <Integer> valueStream = maps.values().stream();
// 键值对流
Stream<Map.Entry<String,Integer>> keyandvalueStream = maps.entrySet().stream();
/**---数组获取流---*/
// 方法一
String[] names = {"A","B","C","D","E"};
Stream<String> nameStream = Arrays.stream(names);
// 方法二
Stream<String> nameStream2 = Stream.of(names);
}
}
Stream流的常用API(中间操作方法)
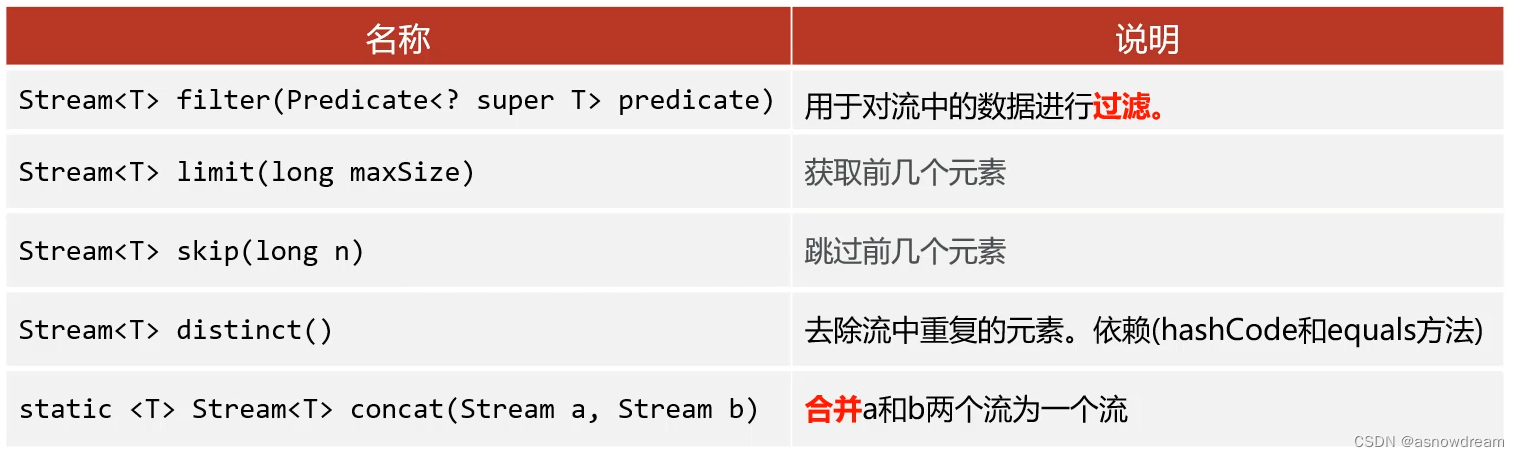
StreamTest2.java实现类:
package d2_stream;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.stream.Stream;
public class StreamTest2 {
public static void main(String[] args) {
List<String> list = new ArrayList <>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张华");
list.add("张三丰");
list.add("张三丰");
// 筛选获取姓张的遍历
list.stream().filter((String s) -> {
return s.startsWith("张");
}).forEach(new Consumer <String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
System.out.println("--------------------------");
// 简化
list.stream().filter(s -> s.startsWith("张")).forEach( s -> System.out.println(s) );
System.out.println("--------------------------");
// 筛选获取长度
long size = list.stream().filter(s -> s.length() == 3).count();
System.out.println(size);
System.out.println("--------------------------");
// 筛选后选取前两个
list.stream().filter(s -> s.startsWith("张")).limit(2).forEach(s -> System.out.println(s));
System.out.println("--------------------------");
// 简化
list.stream().filter(s -> s.startsWith("张")).limit(2).forEach(System.out::println);
System.out.println("--------------------------");
// 筛选后跳过前两个
list.stream().filter(s -> s.startsWith("张")).skip(2).forEach(System.out::println);
System.out.println("--------------------------");
// Map加工方法 给集合元素的前面都加上一个,开心的,
list.stream().map(new Function <String, String>() {
@Override
public String apply(String s) {
return "开心的:" + s;
}
}).forEach(new Consumer <String>() {
@Override
public void accept(String s) {
System.out.println(s);
}
});
System.out.println("--------------------------");
// 简化 第一个是原材料,第二是加工后的
list.stream().map(s -> "开心的:" + s).forEach( s -> System.out.println(s));
System.out.println("--------------------------");
// 进一步简化
list.stream().map(s -> "开心的:" + s).forEach(System.out::println);
System.out.println("--------------------------");
// 把所有名称,都加工成一个学生对象。
list.stream().map(s -> new Student(s)).forEach(s -> System.out.println(s));
System.out.println("--------------------------");
// 简化
list.stream().map(Student::new).forEach(System.out::println);
System.out.println("--------------------------");
// 合并流
Stream<String> s1 = list.stream().filter(s -> s.startsWith("张"));
Stream<String> s2 = Stream.of("java1","java2");
Stream<String> s3 = Stream.concat(s1, s2);
s3.distinct().forEach(s -> System.out.println(s));
}
}
Student.java学生类:
package d2_stream;
public class Student {
private String name;
public Student() {
}
public Student(String name) {
this.name = name;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
'}';
}
}
注意:
1.中间方法也称为非终结方法,调用完成后返回新的Stream流可以继续使用,支持链式编辑。
2.在Stream流中无法直接修改集合、数组中的数据。

注意:终结操作方法,调用完成后流就无法继续使用了,原因是不会返回Stream了。
终结和非终结方法的含义是什么?
终结方法后流不可以继续使用,非终结方法会赶回新的流,支持链式编程。
Stream流的综合应用
案例:
需求:某个公司的开发部门,分为开发一部和二部,现在需要进行年中数据结算。
分析:
1.员工信息至少包含了(名称、性别、奖金、处罚记录)。
2.开发一部有4个员工、开发二部有5名员工。
3.分别赛选出2个部门的最高工资的员工信息,封装成优秀员工对象Topperformer。
package d2_stream;
import java.math.BigDecimal;
import java.math.RoundingMode;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Stream;
public class StreamTest4 {
public static double allMoney;
public static double allMoney2; // 2个部门去掉最高工资,最低工资的总和
public static void main(String[] args) {
List<Employee> one = new ArrayList<>();
one.add(new Employee("猪八戒",'男',30000,25000,null));
one.add(new Employee("孙悟空",'男',25000,1000,"顶撞上司"));
one.add(new Employee("沙僧",'男',20000,20000,null));
one.add(new Employee("小白龙",'男',20000,25000,null));
List<Employee> two = new ArrayList<>();
two.add(new Employee("武松",'男',15000,9000,null));
two.add(new Employee("李逵",'男',20000,10000,null));
two.add(new Employee("西门庆",'男',50000,10000,"被打"));
two.add(new Employee("潘金莲",'女',3500,1000,"被打"));
two.add(new Employee("武大郎",'男',20000,0,"下毒"));
// 开发一部的最高工资的员工 指定大小规则
Employee e = one.stream().max((o1,o2)->Double.compare(o1.getSalary()+o1.getBonus(), o2.getSalary()+o2.getBonus())).get();
System.out.println(e);
// 加工成优秀员工对象
Topperformer t = one.stream().max((o1,o2)->Double.compare(o1.getSalary()+o1.getBonus(), o2.getSalary()+o2.getBonus())).map(a -> new Topperformer( a.getName(), a.getSalary()+ a.getBonus())).get();
System.out.println(t);
// 统计平均工资,去掉最高工资和最低工资
one.stream().sorted((o1,o2) -> Double.compare(o1.getSalary()+o1.getBonus(), o2.getSalary()+o2.getBonus())).skip(1).limit(one.size() - 2).forEach(e1 -> {
// 求出总和,剩余员工的工资总和
allMoney += (e1.getSalary() + e1.getBonus());
});
System.out.println("开发一部的平均工资是:"+ allMoney / (one.size() - 2));
// 合并2个集合流,再统计
Stream<Employee> s1 = one.stream();
Stream<Employee> s2 = two.stream();
Stream<Employee> s3 = Stream.concat(s1, s2);
s3.sorted((o1,o2) -> Double.compare(o1.getSalary()+o1.getBonus(), o2.getSalary()+o2.getBonus())).skip(1).limit(one.size() + two.size() - 2).forEach(e1 -> {
// 求出总和,剩余员工的工资总和
allMoney2 += (e1.getSalary() + e1.getBonus());
});
// BigDecima1精准解决精度问题
BigDecimal a = BigDecimal.valueOf(allMoney2);
BigDecimal b = BigDecimal.valueOf(one.size() + two.size() - 2);
System.out.println("开发部的平均工资是:"+ a.divide(b,2, RoundingMode.HALF_UP));
}
}
收集Stream流
Stream流的收集操作:
1.收集Stream流的含义:就是把Stream流操作后的结果数据转回到集合或者数组中去。
2.Stream流:方便操作集合/数组的手段。
3.集合/数组:才是开发中的目的。
Stream流的收集方法:

Collectors工具类提供了具体的收集方式:

package d2_stream;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.List;
import java.util.Set;
import java.util.function.IntFunction;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class StreamTest5 {
public static void main(String[] args) {
List <String> list = new ArrayList <>();
list.add("张无忌");
list.add("周芷若");
list.add("赵敏");
list.add("张华");
list.add("张三丰");
list.add("张三丰");
// 过滤
Stream<String> s = list.stream().filter(e -> e.startsWith("张"));
// 结果装入list集合
List<String> zhangList = s.collect(Collectors.toList());
System.out.println(zhangList);
// 结果装入set集合, 注意流只能使用一次
Stream<String> s1 = list.stream().filter(e -> e.startsWith("张"));
Set <String> zhangSet = s1.collect(Collectors.toSet());
System.out.println(zhangSet);
// 收集结果装入数组
Stream<String> s2 = list.stream().filter(e -> e.startsWith("张"));
Object[] arrs = s2.toArray();
// 转化成字符串数组
String[] arrs1 = s2.toArray(new IntFunction <String[]>() {
@Override
public String[] apply(int value) {
return new String[value];
}
});
// 简化
// String[] arrs1 = s2.toArray(value -> new String[value]);
// 进一步简化
// String[] arrs1 = s2.toArray(String[]::new);
System.out.println("Arrays数组内容:" + Arrays.toString(arrs));
}
}
异常处理
异常概述、体系
什么是异常?
异常是程序在“编译”或者“执行”的过程中可能出现的问题。
注意:语法错误不算在异常体系中。
比如:数组索引越界、空指针异常、日期格式化异常,等。
为什么要学习异常?
1.异常一旦出现了,如果没有提前处理,程序就会退出JVM虚拟机而终止。
2.研究异常并且避免异常,然后提前处理异常,体现的是程序的安全,健壮性。
异常体系有哪些?
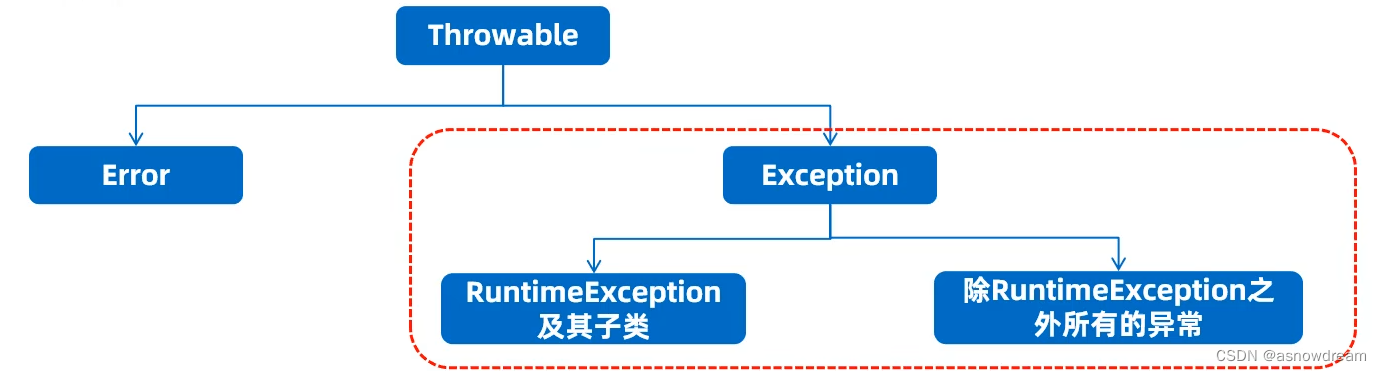
1.Error:
系统级别问题、JVM退出等,代码无法控制。2.Exception:
java.lang包下,称为异常类,它表示程序本身可以处理的问题。
2.1.RuntimeException及其子类:
运行时异常,编译阶段不会报错。(空指针异常,数组索引越界异常)。
2.2.除RuntimeException之外所有的异常:
编译时异常,编译期必须处理的,否则程序不能通过编译。(日期格式化异常)。
编译时异常和运行时异常:

简单来说:
1.编译时异常:没有继承RuntimeExcpetion的异常,就是在编译的时候出现的异常。
2.运行时异常:继承自RuntimeExcpetion的异常或其子类,编译阶段不报错,就是在运行时出现的异常。
常见运行时异常
运行时异常:
直接继承自RuntimeException或者其子类,编译阶段不会报错,运行时可能出现的错误。
运行时异常示例:
1.数组索引越界异常:ArrayIndexOutOfBoundsException。
2.空指针异常:NullPointerException,直接输出没问题,但是调用空指针的变量的功能就会报错。3.数学操作异常:ArithmeticException。
4.类型转换异常:ClassCastException。
5.数字转换异常:NumberFormatException。
运行时异常:一般是程序员业务没有考虑好或者是编译逻辑不严重引起的程序错误。
public class ExceptionDemo {
public static void main(String[] args) {
System.out.println("程序开始。。。。。。");
// 数组索引越界异常:ArrayIndexOutOfBoundsException
int[] arr = {1,2,3};
System.out.println(arr[2]);
// System.out.println(arr[3]); // 运行出错,程序终止
// 空指针异常:NullPointerException
String name = null;
System.out.println(name);
// System.out.println(name.length()); // 运行出错,程序终止
// 类转换异常:ClassCastException
Object o = 23;
// String s = (String) o; // 运行出错,程序终止
// 数学操作异常:ArithmeticException
// int c = 10 / 0;
// 数学操作异常:NumberFormatException
String number = "23aa";
// Integer it = Integer.valueOf(number); // 运行出错,程序终止
// System.out.println(it + 1);
System.out.println("程序结束。。。。。");
}
}
常见编译时异常
编译时异常:
不是RuntimeException或者其子类的异常,编译阶就报错,必须处理,否则代码不通过。
编译时异常示例:
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class ExceptionDemo {
public static void main(String[] args) throws ParseException {
String date = "2015-01-12 10:23:21";
// 创建一个简单日期格式化类:
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
// 解析字符串时间成为日期对象
Date d = sdf.parse(date);
System.out.println(d);
}
}
日期解析异常:ParseException
编译时异常的作用是什么:
1.是担心程序员的技术不行,在编译阶段就爆出一个错误,目的在于提醒不要出错!
2.编译时异常是可遇不可求。
编译时异常的特点:
1.编译时异常:继承自Exception的异常或者其子类。
2.编译阶段报错,必须处理,否则代码不通过。
异常的默认处理流程
1.默认会在出现异常的代码哪里自动的创建一个异常对象:ArithmeticException.
2.异常会从方法中出现的点这里抛出给调用者,调用者最终抛出给JVM虚拟机。
3.虚拟机接收到异常对象后,先在控制台直接输出异常栈信息数据。
4.直接从当前执行的异常点干掉当前程序。
5.后续代码没有机会执行了,因为程序已经死亡。
public class ExceptionDemo {
public static void main(String[] args) {
System.out.println("程序开始。。。。。。。");
chu(10, 2);
System.out.println("程序结束。。。。。。。");
}
public static void chu(int a,int b){
System.out.println(a);
System.out.println(b);
int c = a / b;
System.out.println(c);
}
}
默认异常处理机制:默认的异常处理机制并不好,一旦真的出现异常,程序立即死亡!
编译时异常的处理机制
编译时异常是编译阶段就出错的,所以必须处理,否则代码根本无法通过。
编译时异常的处理形式有三种:
1.出现异常直接抛出去给调用者,调用者也继续抛出去。
2.出现异常自己捕获处理,不麻烦别人。
3.前两者结合,出现异常直接抛出去给调用者,调用者捕获处理。
异常处理方式1——throws
1.throws:用在方法上,可以将方法内部出现的异常抛出去给本方法的调用者处理。
2.这种方法并不好,发生异常的方法自己不处理异常,如果异常最终抛出去给虚拟机将引起程序死亡。
抛出异常格式:
方法 throws 异常1,异常2,异常3...{}
规范做法:
方法 throws Exception{}
package d7_exception_handle;
import java.io.FileInputStream;
import java.io.InputStream;
import java.text.SimpleDateFormat;
import java.util.Date;
public class ExceptionDemoD1 {
public static void main(String[] args) throws Exception {
System.out.println("程序开始----");
parseTime("2011-11-11 11:11:11");
System.out.println("程序结束----");
}
public static void parseTime(String date) throws Exception {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = sdf.parse(date);
System.out.println(d);
InputStream is = new FileInputStream("E:/snow.jpg");
}
}
异常处理方式2——try…catch…
1.监视捕获异常,用在方法内部,可以将方法内部出现的异常直接捕获处理。
2.这种方式还可以,发生异常的方法自己独立完成异常的处理,程序可以继续往下执行。
格式:
try{
// 监视可能出现异常的代码!
}catch(异常类型1 变量){
// 处理异常
}catch(异常类型2 变量){
// 处理异常
}
建议格式:
try{
// 监视可能出现异常的代码!
}catch(异常类型1 变量){
// 直接打印异常栈信息
e.printStackTrace();
}
Exception可以捕获处理一切异常类型!
package d7_exception_handle;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.InputStream;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class ExceptionDemoD2 {
public static void main(String[] args) {
System.out.println("程序开始----");
parseTime("2022-11-11 11:11:11");
System.out.println("程序结束----");
}
public static void parseTime(String date){
try {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = sdf.parse(date);
System.out.println(d);
} catch (ParseException e) {
// 解析出现问题
e.printStackTrace();
}
try {
InputStream is = new FileInputStream("E:/snow.jpg");
} catch (FileNotFoundException e) {
e.printStackTrace();
}
}
}
异常处理方式3——前两者结合
1.方法直接将异常通过throws抛出去给调用者。
2.调用者收到异常后直接捕获处理。
package d7_exception_handle;
import java.io.FileInputStream;
import java.io.InputStream;
import java.text.SimpleDateFormat;
import java.util.Date;
public class ExceptionDemoD3 {
public static void main(String[] args) {
System.out.println("程序开始。。。。");
try {
parseTime("2022-11-11 11:11:11");
System.out.println("功能操作成功了。。。");
} catch (Exception e) {
e.printStackTrace();
System.out.println("功能操作失败了。。。");
}
System.out.println("程序结束。。。。");
}
public static void parseTime(String date) throws Exception {
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
Date d = sdf.parse(date);
System.out.println(d);
InputStream is = new FileInputStream("D:/snow.jpg");
}
}
异常处理的总结:
1.在开发中按照规范来说第三种方式是最好的:底层的异常抛出去给最外层,最外层集中捕获处理。
2.实际应用中,只要代码能够编译通过,并且功能能够完成,那么每一种异常处理方式似乎也都是可以的。
运行时异常的处理机制
运行时异常的处理形式
1.运行 时异常编译阶段不会出错,是运行时才可能出错的,所以编译阶段不处理也可以。
2.按照规范建议还是处理:建议在最外层调用处集中捕获处理即可。
package d8_exception_handle_runtime;
public class Test {
public static void main(String[] args) {
System.out.println("程序开始。。。。。。。");
try {
chu(10, 0);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("程序结束。。。。。。。");
}
public static void chu(int a,int b){ // throws RuntimeException 可以省略
System.out.println(a);
System.out.println(b);
int c = a / b;
System.out.println(c);
}
异常处理使代码更稳健的案例
需求:
键盘录入一个合理的价格为止(必须是数值,值必须大于0)。
分析:
定义一个死循环,让用户不断的输入价格。
package d8_exception_handle_runtime;
import java.util.Scanner;
public class Test1 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
while (true) {
try {
System.out.println("请您输入合法的价格:");
String priceStr = sc.nextLine();
// 转换成double类型的价格
double price = Double.valueOf(priceStr);
// 判断价格是否大于0
if(price > 0){
System.out.println("定价:"+price);
break;
}else {
System.out.println("价格必须是正数。。。");
}
} catch (Exception e) {
System.out.println("用户输入的数据有毛病,请您输入合法的数值,建议为正数。");
}
}
}
}
自定义异常
自定义异常的必要?
1.Java无法为这个世界上全部的问题提供异常类。
2.如果企业想通过异常的方式来管理自己的某个业务问题,就需要自定义异常类了。
自定义异常的好处:
1.可以使用异常的机制管理业务问题,如果提醒程序员注意。
2.同时一旦出现bug,可以用异常的形式清晰的指出出错的地方。
自定义异常的分类:
1.自定义编译时异常
首先定义一个异常类继承Exception。
然后重写构造器。
最后在出现异常的地方用throw new自定义对象抛出。
作用:编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!
snowAgeException.java自定义编译异常类
package d9_exception_custom;
/**
* 自定义的编译时异常
* 1.继承Exception
* 2.重写构造器
*/
public class snowAgeException extends Exception{
public snowAgeException() {
}
public snowAgeException(String message) {
super(message);
}
}
ExceptionDemo异常触发类
package d9_exception_custom;
public class ExceptionDemo {
public static void main(String[] args) {
try {
checkAge(34);
} catch (snowAgeException e) {
e.printStackTrace();
}
}
public static void checkAge(int age) throws snowAgeException {
if(age<0 || age>200){
// 提出去一个异常对象给调用者
// throw:在方法内部直接创建一个异常对象,并从此点抛出
// throws:用在方法申明上的,抛出方法内部的异常。
throw new snowAgeException(age+" is illeagal!");
}else {
System.out.println("年龄合法:推荐商品给其购买~~");
}
}
}
2.自定义运行时异常
首先定义一个异常类继承RuntimeExcetion。
然后重写构造器。
最后在出现异常的地方用throw new自定义对象抛出!
作用:提醒不强烈,编译阶段不错!!运行时才可能出现!!
snowAgeruntimeException.java自定义运行异常类
package d9_exception_custom;
/**
* 自定义的编译时异常
* 1.继承RuntimeException
* 2.重写构造器
*/
public class snowAgeruntimeException extends RuntimeException{
public snowAgeruntimeException() {
}
public snowAgeruntimeException(String message) {
super(message);
}
}
runExceptionDemo异常触发类:
package d9_exception_custom;
public class runExceptionDemo {
public static void main(String[] args) {
try {
checkAge(34);
} catch (snowAgeruntimeException e) {
e.printStackTrace();
}
}
public static void checkAge(int age){
if(age<0 || age>200){
// 提出去一个异常对象给调用者
// throw:在方法内部直接创建一个异常对象,并从此点抛出
// throws:用在方法申明上的,抛出方法内部的异常。
throw new snowAgeruntimeException(age+" is illeagal!");
}else {
System.out.println("年龄合法:推荐商品给其购买~~");
}
}
}
日志框架
日志技术的概述
日志:
1.生活中的日志:生活中的日志就好比日记,可以记录你生活的点点滴滴。
2.程序中的日志:程序中的日志可以用来记录程序运行过程中的信息,并可以进行永久存储。
以前记录日志的方式:

输出语句的弊端
1.信息只能展示在控制台。
2.不能将其记录到其他的位置(文件,数据库)。
3.想取消记录的信息需要修改代码才可以完成。
日志技术具备的优势:
1.可以将系统执行的信息选择性的记录到指定的位置(控制台、文件中、数据库中)。
2.可以随时以开关的形式控制是否记录日志,无需修改源代码。
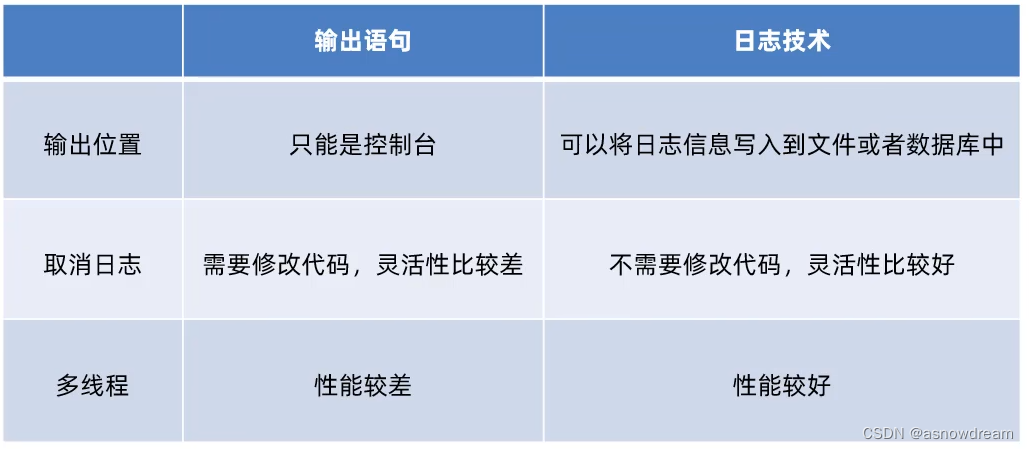
日志技术体系结构
体系结构:
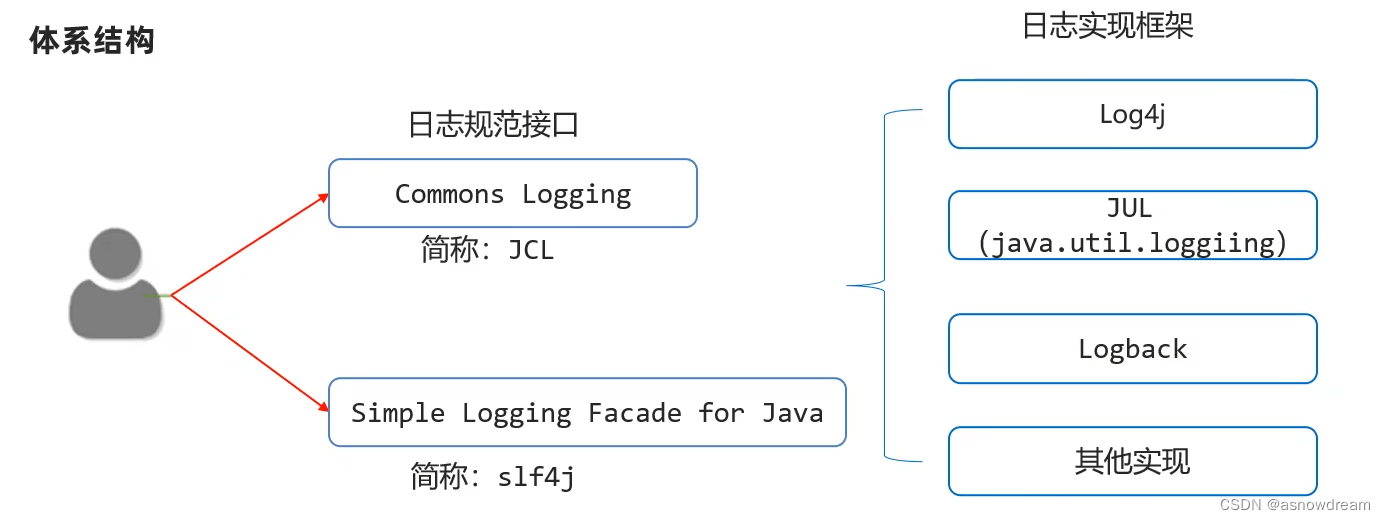
1.日志规范:一些接口,提供给日志的实现框架设计的标准。
2.日志框架:第三方公司已经做好的日志记录实现代码,后来者直接可以拿去使用。
3.因为对Commons Logging的接口不满意,有人就搞了SLF4J。因为对log4j的性能不满意,有人就搞了Logback。
Logback概述
Logback日志框架
1.Logback是由log4j创始人设计的另一个开源日志,性能比long4j要好。
2.官方网站:https://logback.qos.ch/index.html
3.logback是基于slf4j的日志规范实现的框架。
Logback主要分为三个技术模块:
1.logback-core:logback-core模块为其他两个模块奠定了基础,必须有。
2.logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API。
3.logback-access板块与Tomcat和Jetty等。Servlet容器集成,以提供HTTP访问日志功能。
Logback快速入门
需求:
导入Logback日志技术到项目中,用于记录系统的日志信息。
分析:
1:在项目中新建文件lib,导入Logback的相关jar包到该文件夹下,并添加到项目依赖库中去。

2:将Logback的核心配置文件logback.xml直接拷贝到src目录下(必须是src下)。
3:在代码中获取日志的对象。
public static final Logger LOGGER=LoggerFactory.getLogger("类对象");
4:使用日志对象输出日志信息
package snowlogback;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 目标:快速搭建logBack日志框架 记录程序的执行情况到控制台 到文件中
*/
public class Test {
// 创建Logger的日志对象,代表了日志技术
public static final Logger LOGGER = LoggerFactory.getLogger("Test.class");
public static void main(String[] args) {
try {
LOGGER.debug("main方法开始执行了~~~");
LOGGER.info("我开始记录第二行日志,我要开始做除法~~~");
int a = 10;
int b = 0;
LOGGER.trace("a=" + a);
LOGGER.trace("b=" + b);
System.out.println(a/b);
} catch (Exception e) {
e.printStackTrace();
LOGGER.error("功能出现异常,"+ e);
}
}
}
Logback配置详解-输出位置,格式设置
Logback日志系统的特性都是通过核心配置文件logbback.xml控制的。
Logback日志输出位置、格式设置:
1.通过logback.xml中的<append>标签可以设置输出位置和日志信息的详细格式。
2.通常可以设置2个日志输出位置:一个是控制台、一个是系统文件中。
输出到控制台的配置标志:
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
输出到系统文件的配置标志:
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFilleAppender">
Logback.xml配置文件:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<!--
CONSOLE :表示当前的日志信息是可以输出到控制台的。
-->
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<!--输出流对象 默认 System.out 改为 System.err-->
<target>System.out</target>
<encoder>
<!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度
%msg:日志消息,%n是换行符-->
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern>
</encoder>
</appender>
<!-- File是输出的方向通向文件的 -->
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
<!--日志输出路径-->
<file>D:/log/snow-data.log</file>
<!--指定日志文件拆分和压缩规则-->
<rollingPolicy
class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy">
<!--通过指定压缩文件名称,来确定分割文件方式-->
<fileNamePattern>D:/log/snow-data2-%d{yyyy-MMdd}.log%i.gz</fileNamePattern>
<!--文件拆分大小-->
<maxFileSize>1MB</maxFileSize>
</rollingPolicy>
</appender>
<!--
level:用来设置打印级别,大小写无关:TRACE, DEBUG, INFO, WARN, ERROR, ALL 和 OFF
, 默认debug
<root>可以包含零个或多个<appender-ref>元素,标识这个输出位置将会被本日志级别控制。
-->
<root level="ALL">
<!--注意,如果这里不配置关联打印位置,该位置将不会记录日志-->
<!--控制台输出-->
<appender-ref ref="CONSOLE"/>
<!--文件输出-->
<appender-ref ref="FILE" />
</root>
</configuration>
在核心配置文件Logback.xml中可以配置的日志方向有哪些。
1.输出控制台的配置标志。
<appender name=“CONSOLE” class=“ch.qos.logback.core.ConsoleAppender”>
2.输出到系统文件的配置标志。
<appender name=“FILE” class=“ch.qos.logback.core.rolling.RollingFileAppender”>
Logback配置详解-日志级别设置
1.如果系统上线后只想记录一些错误的日志信息或者不想记录日志了,怎么办?
可以通过设置日志的输出级别来控制哪些日志信息输出或者不输出。
日志级别:
1.级别程度依次是:TRACE<DEBUG<INFO<WARN<ERROR;默认级别是debug(忽略大小写),对应其方法。
2.作用:用于控制系统中哪些日志级别是可以输出的,只输出级别不低于设定级别的日志信息。
3.ALL和OFF分别是打开全部日志信息,及关闭全部日志信息。
具体在<root level = “INFO” >标签的level属性中设置日志级别。
<root level="INFO">
<appender-ref ref="CONSOLE"/>
<appender-ref ref="FILE"/>
</root>
![【寒假每日一题】洛谷 P6263 [COCI2014-2015#3] STROJOPIS](https://img-blog.csdnimg.cn/2449ed9d6755445594a83385ecdb51b2.png)