用 Python selenium爬取实时股票新闻并存入mysql数据库中
- 1.分析需求
- 2.创建表
- 3.分析需要爬取的网页内容
- 4.python里面selenium进行爬虫操作
- 1.添加包
- 2.连接数据库
- 3.selenium爬虫前配置
- 4.对股票新闻内容爬取并存入mysql中
- 5.翻页功能
- 6.运行程序
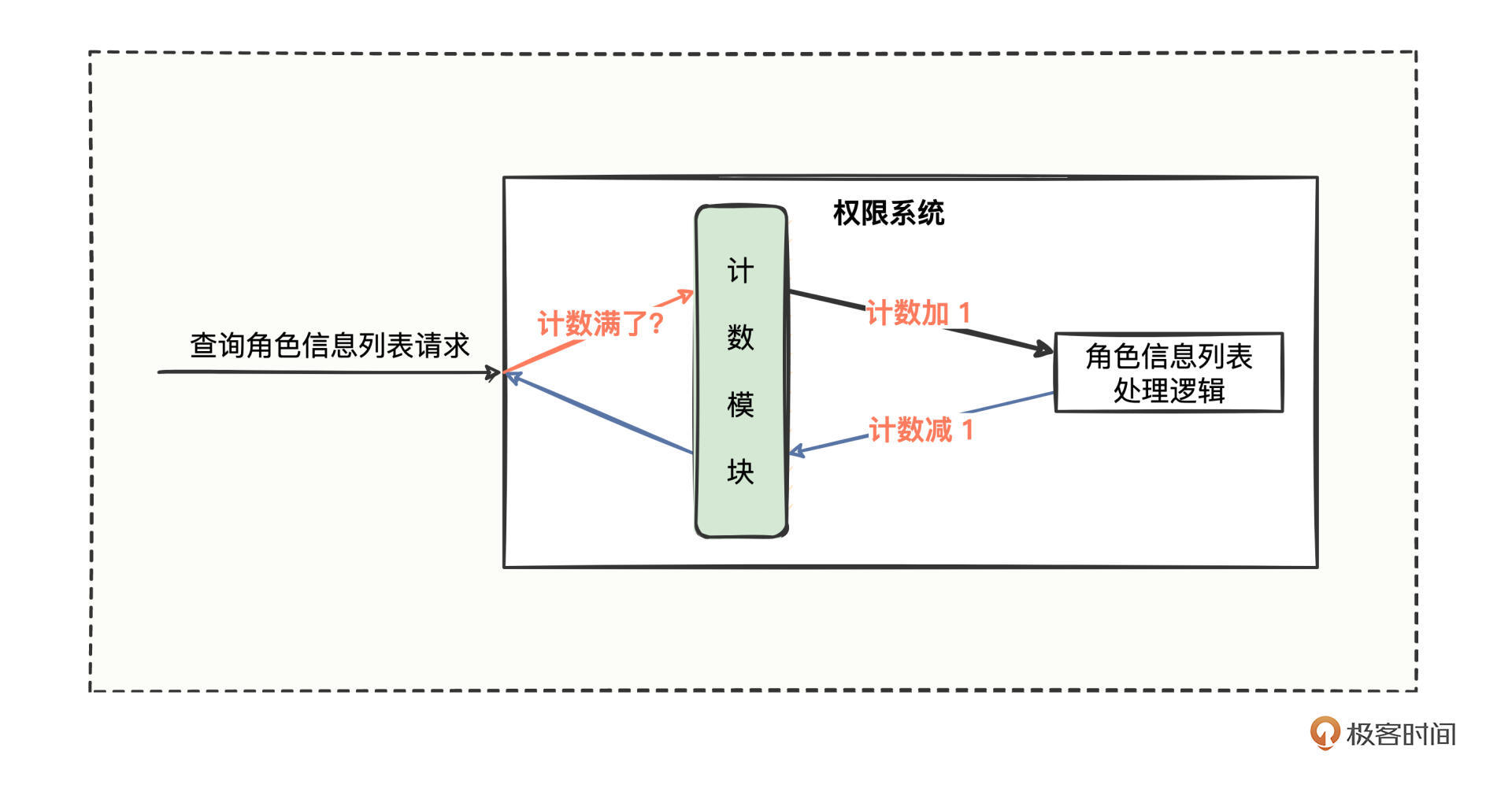
首先我们先明确我们的主要目标就是要爬取网站的股票新闻,并将爬取到的内容存入到mysql里面去具体流程就如下图所示
如果需要完整的代码可以直接到这些下载,觉得文章不错的话欢迎点赞,收藏,打赏
Python爬取股票新闻并存入mysql数据库
1.分析需求
我们主要就是针对于7x24小时股票新闻的新闻进行爬取,里面的新闻内容较多,由于我们需要存入mysql数据库里面所以我们先搞定数据库先,当然csv格式进行存储也是可以,不过由于我需要在我自己的django项目中显示出来需要就需要用到mysql数据库

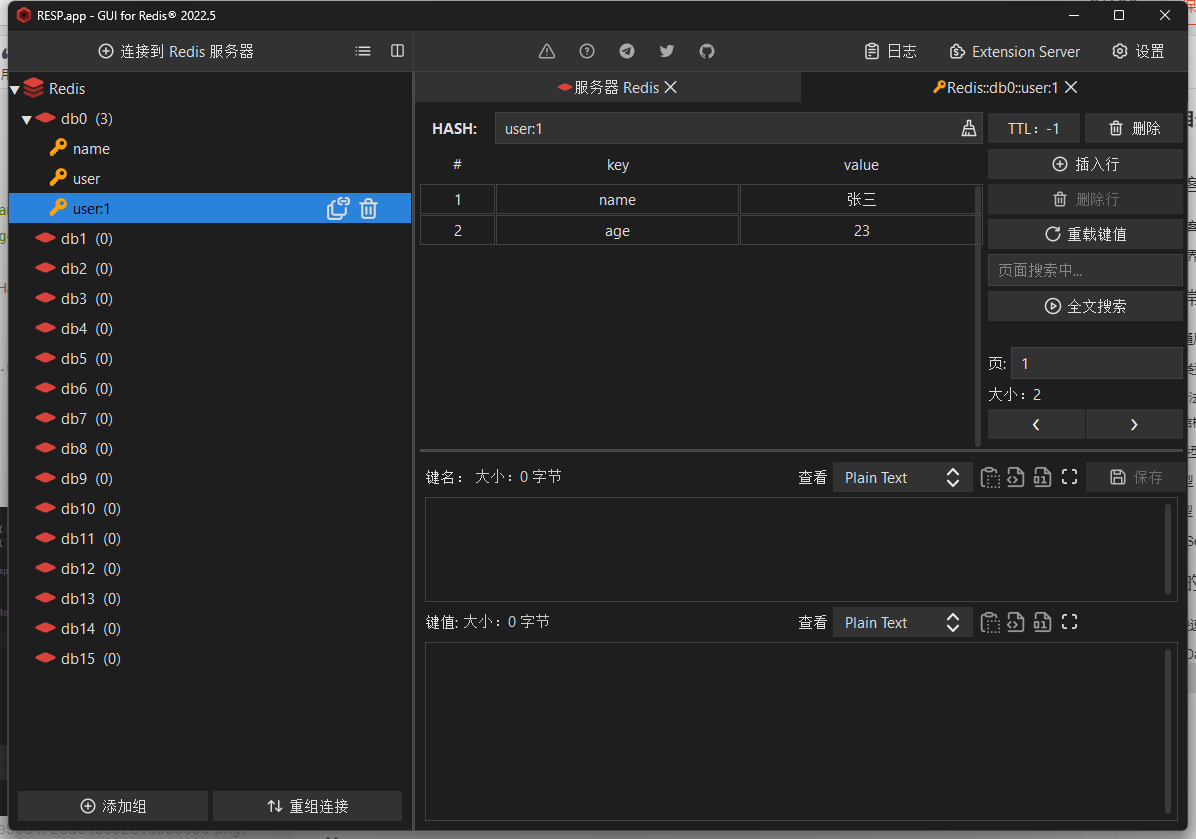
2.创建表
首先我们需要爬取的主要内容有三个,第一个就是新闻时间,第二个就是新闻的网页地址,第三个就是新闻的内容所以我们的表就创建三个即可,如果你自己想要创建更多复杂的内容的话就可以自己新增字段然后再爬取进去也是可以的
CREATE TABLE abc (
id int NOT NULL AUTO_INCREMENT,
new_time datetime(6) NOT NULL,#新闻时间
new_sources varchar(100) NOT NULL,#新闻的网页地址
new_content varchar(500) NOT NULL,#新闻的内容
PRIMARY KEY (id)
) ENGINE=InnoDB AUTO_INCREMENT=263 DEFAULT CHARSET=utf8mb3;
3.分析需要爬取的网页内容
首先找到开发人员工具选项或者右键审查元素也可以这里根据你用的浏览器灵活进行更改
然后再用这个小箭头点击你要审查的元素,点击新闻内容就可以显示里面的元素
找到我们需要的新闻内容

再点击外框可以发现我们所有需要的内容都是在livenews-media这个标签里面

再点进去我们可以看到time就是我们想要的新闻时间不过这个时间只是一个小时和分时,我们需要带年月日不然后期数据存入数据库里面会非常乱,这里就要改。

再从media-title-box font_0点进去我们可以看到一个href后带有超链接和a标签里面有我们需要的新闻内容
目前为止我们就可以大致梳理清楚我们要爬取的内容就是time标签内的内容,a标签内href里面的超链接,a标签里面的新闻内容。
4.python里面selenium进行爬虫操作
1.添加包
这里面我们需要time包用来将时间更改存入mysql中,pymysql进行Python和mysql的连接,selenium进行内容爬取
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.keys import Keys
from apscheduler.schedulers.blocking import BlockingScheduler
from selenium.webdriver import Chrome, ChromeOptions
2.连接数据库
# //连接数据库
conn = pymysql.connect(host='localhost', # host属性
port=3306, # 端口号
user='', # 用户名
pasrd='', # 此处填登录数据库的密码(由于无法在文章内显示密码为英文的密码单词,请自行修改)
db='' , # 数据库名
charset='utf8'
)
3.selenium爬虫前配置
如果不了解selenium可以去看这一篇文章
selenium用法详解【从入门到实战】【Python爬虫】【4万字】
由于我本人不需要selenium去进行爬虫界面显示,所以将爬虫界面给关闭,如果你需要看爬虫在浏览器内干的活那么你就需要把opt这两段注释掉即可,这里我用的Chrome浏览器的内核
opt = ChromeOptions() # 创建Chrome参数对象
opt.headless = True # 把Chrome设置成可视化无界面模式,windows/Linux 皆可
# Chrome浏览器
driver = webdriver.Chrome()
driver.get("")#爬取的网页地址
4.对股票新闻内容爬取并存入mysql中
def index():
# 设置等待5秒,避免爬虫时被封禁
driver.implicitly_wait(5)
# 找到外框的获取里面所有的li标签
lis = driver.find_elements_by_xpath("//*[@class='livenews-media']")
for i,li in enumerate(lis):
# debug后发现lis里面len获取最大值是50,所以直接for循环给他控制在50次就退出操作
if i < 50:
# 获取url
line = li.find_element_by_css_selector("a.media-title").get_attribute('href')
# 获取时间,第一次获取text内容实用get_attribute发现获取的内容是空值,所以改用.text获取到值
# time24 = li.find_element_by_css_selector('span.time').get_attribute('text')
time24 = li.find_element_by_css_selector('span.time').text
# 获取本地时间
b = time.strftime('%Y-%m-%d ', time.localtime(time.time()))
# 与获取到的时间进行拼接获取可以进入数据库里面时间格式
d = b + time24
newtext = li.find_element_by_css_selector("a.media-title").get_attribute('text')
print(d,line,newtext)
# 获取一个光标
cursor = conn.cursor()
# 插入数据,insert into mysql表名(列名,列名,列名)values(值,值,值)这个值主要就是对应的你获取到的值
sql = 'insert into abc(new_time,new_sources,new_content) values(%s,%s,%s);'
# 对获取到的数据进行排序如果有重复的则进行筛除
data_list=[d,line,newtext]
list2 = sorted(list(set(data_list)), key=data_list.index)
try:
# 插入数据
cursor.execute(sql,list2)
# 连接数据
conn.commit()
print('插入数据成功')
except Exception as e:
print('插入数据失败')
conn.rollback()
time.sleep(5)
else:
driver.quit()
# 关闭数据库
conn.close()
5.翻页功能
如果有些网站可以对li标签内进行点击翻页那就不用模拟键盘翻页操作,这里range()里面的内容就代表页数可自行修改
# 翻页功能,selenium模拟键盘自动翻页
for j in range(1):
index()
driver.implicitly_wait(5)
# driver.switch_to.window(driver.window_handles[-1])
#页面点击跳转下一页,因为无法识别到li里面的标签所以就用键盘右键换页的方法替代
ActionChains(driver).key_down(Keys.CONTROL).send_keys(Keys.RIGHT).key_up(Keys.CONTROL).perform()
time.sleep(5)
还有就是翻页之后由于selenium无法识别新的页面就需要告知selenium当前页面为新页面,需要用以下代码
driver.switch_to.window(driver.window_handles[-1])
如果翻页之后没有出现新的窗口那就不需要对新的窗口进行关闭,如果翻页之后出现新的窗口就需要对新的窗口进行关闭操作也就是driver.close()
6.运行程序
成功将内容插入到mysql数据库当中