stdio.h
C 标准库 – <stdio.h> | 菜鸟教程 (runoob.com)
下面是头文件 stdio.h 中定义的变量类型:
序号 变量 & 描述 1 size_t
这是无符号整数类型,它是 sizeof 关键字的结果。2 FILE
这是一个适合存储文件流信息的对象类型。3 fpos_t
这是一个适合存储文件中任何位置的对象类型。其中的FILE比较常见,那么这个FILE到底是什么?
描述中声称FILE是一个适合存储文件流信息的对象类型。
在C语言中,用一个指针变量指向一个文件,这个指针称为文件指针。通过文件指针就可对它所指的文件进行各种操作。
定义文件指针的一般形式为:
FILE *fp;这里的FILE,实际上是在stdio.h中定义的一个结构体,该结构体中含有文件名、文件状态和文件当前位置等信息,fopen 返回的就是FILE类型的指针。
注意:FILE是文件缓冲区的结构,fp也是指向文件缓冲区的指针。
不同编译器stdio.h 头文件中对 FILE 的定义略有差异,这里以标准C举例说明:
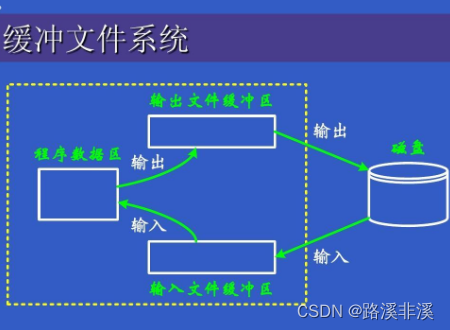
下面说一下如何控制缓冲区。
我们知道,当我们从键盘输入数据的时候,数据并不是直接被我们得到,而是放在了缓冲区中,然后我们从缓冲区中得到我们想要的数据 。如果我们通过setbuf()或setvbuf()函数将缓冲区设置10个字节的大小,而我们从键盘输入了20个字节大小的数据,这样我们输入的前10个数据会放在缓冲区中,因为我们设置的缓冲区的大小只能够装下10个字节大小的数据,装不下20个字节大小的数据。那么剩下的那10个字节大小的数据怎么办呢?暂时放在了输入流中。请看下图:
上面的箭头表示的区域就相当是一个输入流,红色的地方相当于一个开关,这个开关可以控制往深绿色区域(标注的是缓冲区)里放进去的数据,输入20个字节的数据只往缓冲区中放进去了10个字节,剩下的10个字节的数据就被停留在了输入流里!等待之后往缓冲区中放入!那么系统是如何来控制这个缓冲区呢?
再说一下 FILE 结构体中几个相关成员的含义:
cnt // 剩余的字符,如果是输入缓冲区,那么就表示缓冲区中还有多少个字符未被读取
ptr // 下一个要被读取的字符的地址
base // 缓冲区基地址在上面我们向缓冲区中放入了10个字节大小的数据,FILE结构体中的 cnt 变为了10 ,说明此时缓冲区中有10个字节大小的数据可以读,同时我们假设缓冲区的基地址也就是 base 是0x00428e60 ,它是不变的 ,而此时 ptr 的值也为0x00428e60 ,表示从0x00428e60这个位置开始读取数据,当我们从缓冲区中读取5个数据的时候,cnt 变为了5 ,表示缓冲区还有5个数据可以读,ptr 则变为了0x0042e865表示下次应该从这个位置开始读取缓冲区中的数据 ,如果接下来我们再读取5个数据的时候,cnt 则变为了0 ,表示缓冲区中已经没有任何数据了,ptr 变为了0x0042869表示下次应该从这个位置开始从缓冲区中读取数据,但是此时缓冲区中已经没有任何数据了,所以要将输入流中的剩下的那10个数据放进来,这样缓冲区中又有了10个数据,此时 cnt 变为了10 ,注意了刚才我们讲到 ptr 的值是0x00428e69 ,而当缓冲区中重新放进来数据的时候这个 ptr 的值变为了0x00428e60 ,这是因为当缓冲区中没有任何数据的时候要将 ptr 这个值进行一下刷新,使其指向缓冲区的基地址也就是0x0042e860这个值!因为下次要从这个位置开始读取数据!
在这里有点需要说明:当我们从键盘输入字符串的时候需要敲一下回车键才能够将这个字符串送入到缓冲区中,那么敲入的这个回车键(\r)会被转换为一个换行符\n,这个换行符\n也会被存储在缓冲区中并且被当成一个字符来计算!比如我们在键盘上敲下了123456这个字符串,然后敲一下回车键(\r)将这个字符串送入了缓冲区中,那么此时缓冲区中的字节个数是7 ,而不是6。
缓冲区的刷新就是将指针 ptr 变为缓冲区的基地址 ,同时 cnt 的值变为0 ,缓冲区刷新后里面就没有数据了!


| 1 | int fclose(FILE *stream) 关闭流 stream。刷新所有的缓冲区。 |
C 库函数 int fclose(FILE *stream) 关闭流 stream。刷新所有的缓冲区。
直接传入一个文件类型指针即可。
如果流成功关闭,则该方法返回零。如果失败,则返回 EOF。
EOF
这个宏是一个表示已经到达文件结束的负整数。
| 3 | int feof(FILE *stream) 测试给定流 stream 的文件结束标识符。 |
当设置了与流关联的文件结束标识符时,该函数返回一个非零值,否则返回零。
注意,这句话的意思是,如果到了结束符,就返回一个非零值,要是还没读到结束符,就返回0。
| 5 | int fflush(FILE *stream) 刷新流 stream 的输出缓冲区。 |
| 7 | FILE *fopen(const char *filename, const char *mode) 使用给定的模式 mode 打开 filename 所指向的文件。 |
- filename -- 字符串,表示要打开的文件名称(全路径)
- mode -- 字符串,表示文件的访问模式,可以是以下表格中的值:
模式 描述 "r" 打开一个用于读取的文件。该文件必须存在。 "w" 创建一个用于写入的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。 "a" 追加到一个文件。写操作向文件末尾追加数据。如果文件不存在,则创建文件。 "r+" 打开一个用于更新的文件,可读取也可写入。该文件必须存在。 "w+" 创建一个用于读写的空文件。如果文件名称与已存在的文件相同,则会删除已有文件的内容,文件被视为一个新的空文件。 "a+" 打开一个用于读取和追加的文件。 fopen() 会获取文件信息,包括文件名、文件状态、当前读写位置等,并将这些信息保存到一个 FILE 类型的结构体变量中,然后将该变量的地址返回。
该函数返回一个 FILE 指针。否则返回 NULL,且设置全局变量 errno 来标识错误。
在C语言中,操作文件之前必须先打开文件;所谓“打开文件”,就是让程序和文件建立连接的过程。
打开文件之后,程序可以得到文件的相关信息,例如大小、类型、权限、创建者、更新时间等。在后续读写文件的过程中,程序还可以记录当前读写到了哪个位置,下次可以在此基础上继续操作。
标准输入文件 stdin(表示键盘)、标准输出文件 stdout(表示显示器)、标准错误文件 stderr(表示显示器)是由系统打开的,其本质也是个FILE类型指针,可直接使用。我们通常自定义的是我们自己的文件位置,而这三个位置是系统已经定义好的,标准化的。
10 stderr、stdin 和 stdout
这些宏是指向 FILE 类型的指针,分别对应于标准错误、标准输入和标准输出流。
| 8 | size_t fread(void *ptr, size_t size, size_t nmemb, FILE *stream) 从给定流 stream 读取数据到 ptr 所指向的数组中。 |
参数
- ptr -- 这是指向带有最小尺寸 size*nmemb 字节的内存块的指针。
- size -- 这是要读取的每个元素的大小,以字节为单位。
- nmemb -- 这是元素的个数,每个元素的大小为 size 字节。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输入流。
返回值
成功读取的元素总数会以 size_t 对象返回,size_t 对象是一个整型数据类型。如果总数与 nmemb 参数不同,则可能发生了一个错误或者到达了文件末尾。
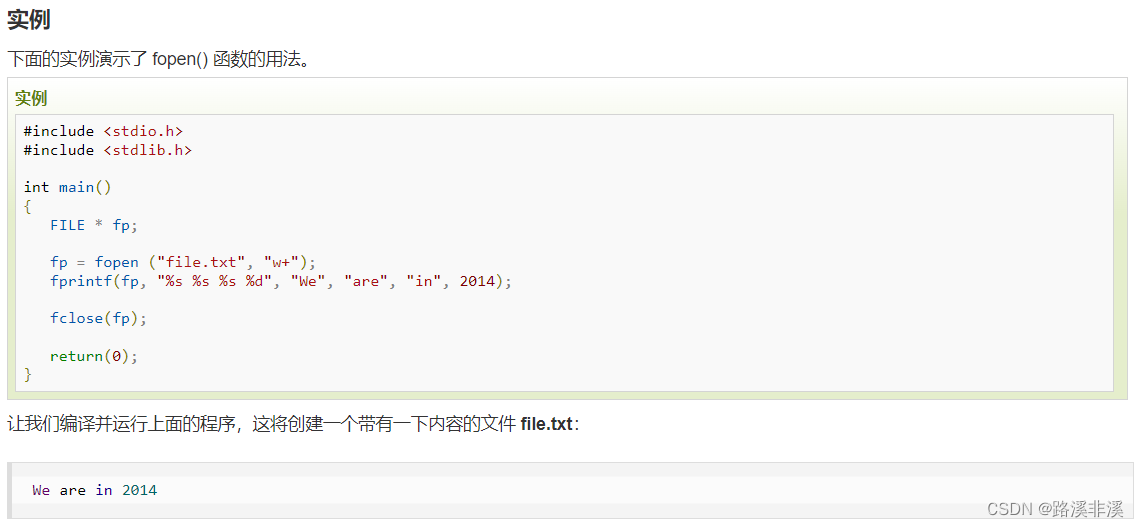
使用示例:
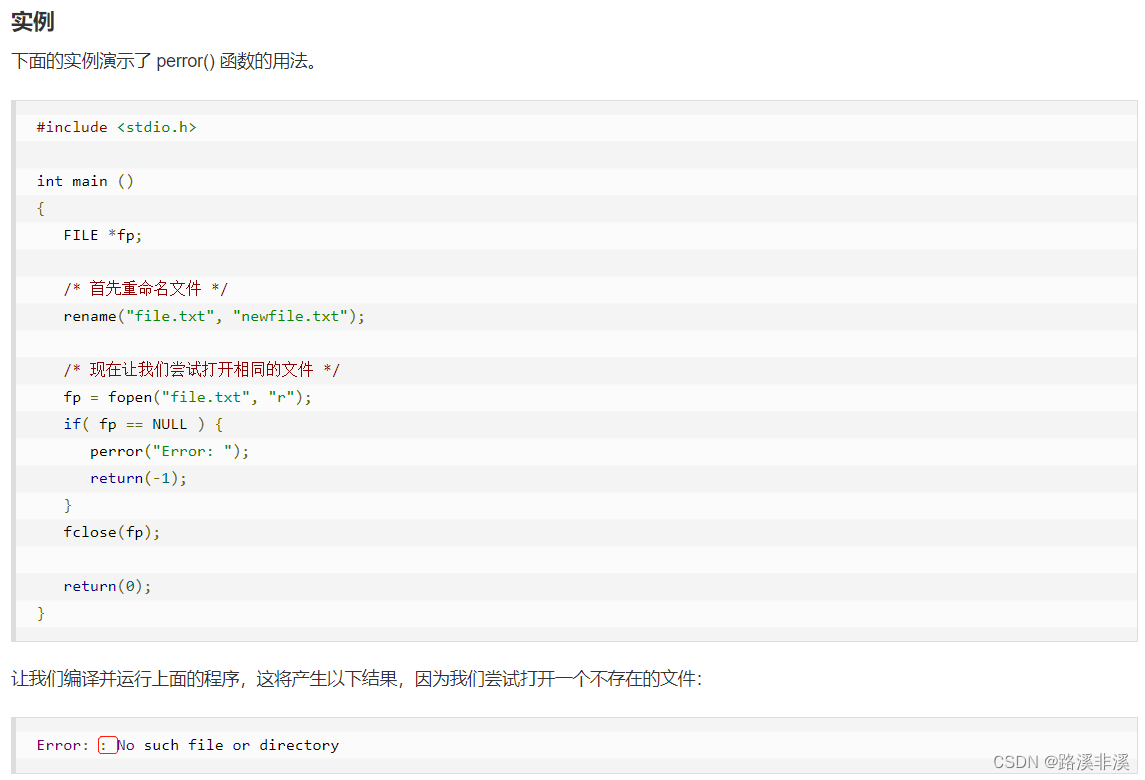
#include <stdio.h> #include <string.h> int main() { FILE *fp; char c[] = "This is runoo"; char buffer[20]; /* 打开文件用于读写 */ fp = fopen("file.txt", "w+"); /* 写入数据到文件 */ fwrite(c, strlen(c) + 1, 1, fp); /* 查找文件的开头 */ fseek(fp, 0, SEEK_SET); /* 读取并显示数据 */ fread(buffer, strlen(c)+1, 1, fp); printf("%s\n", buffer); fclose(fp); return(0); }运行结果:
这个程序是菜鸟教程中给的示例程序,但是有个疑惑。
fread中,第二个参数为啥是strlen() + 1,这也不像是要读取的元素的大小呀,第三个参数为啥是1,而不是所有字符的总个数?
教程中给的例子应该不会有问题,那么就是我的理解问题了。
我理解的元素是字符,即一个字符一个字符地去读取,显然,这里不是这个意思。
那么,上述中提到的“元素”指的是什么?
这个函数,很容易理解错误。以为是一个字符一个字符地去读取。
count是要读取的字符个数,size是每个字符的字节数。
我觉得上述官方的描述很有问题。
下面查阅资料,给到真正的理解。
参数
- ptr -- 这是指向带有最小尺寸 size*nmemb 字节的内存块的指针。
- size -- 这是每次要读取的字节数。
- nmemb -- 这是要分多少次来读取目标数据。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象指定了一个输入流。
fread是一个分段读取文件的函数,count就是分多少段,举例来说,同样在文件中读100个字节:
int a = fread(buf, 1, 100, fp); // a = 100
int b = fread(buf, 100, 1, fp); // b = 1
其实count影响的是返回值,fread返回的是成功读取多少段,所以一般情况下,如果需要准确的知道到底读取了多少个字节,把size设为1,把count设为你需要读取的字节数,这样fread的返回值就是读取的字节数了。
性能方面不用担心,fread底层并不是一段一段调用系统调用去读的,是优化过的。(1) 调用格式:fread(buf, sizeof(buf), 1, fp);
读取成功时:当读取的数据量正好是sizeof(buf)个Byte时,返回值为1(即count)
(2)调用格式:fread(buf, 1, sizeof(buf), fp);
读取成功返回值为实际读回的数据个数(单位为Byte)这样一来,就理解了该函数,如果是这样,那么在上述案例中,如果将strlen(c)+1换成sizeof(c),应该是一样的效果。经过测试,确实如此。

| 10 | int fseek(FILE *stream, long int offset, int whence) 设置流 stream 的文件位置为给定的偏移 offset,参数 offset 意味着从给定的 whence 位置查找的字节数。 |
参数
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- offset -- 这是相对 whence 的偏移量,以字节为单位。
- whence -- 这是表示开始添加偏移 offset 的位置。它一般指定为下列常量之一:
常量 描述 SEEK_SET 文件的开头 SEEK_CUR 文件指针的当前位置 SEEK_END 文件的末尾 返回值
如果成功,则该函数返回零,否则返回非零值。
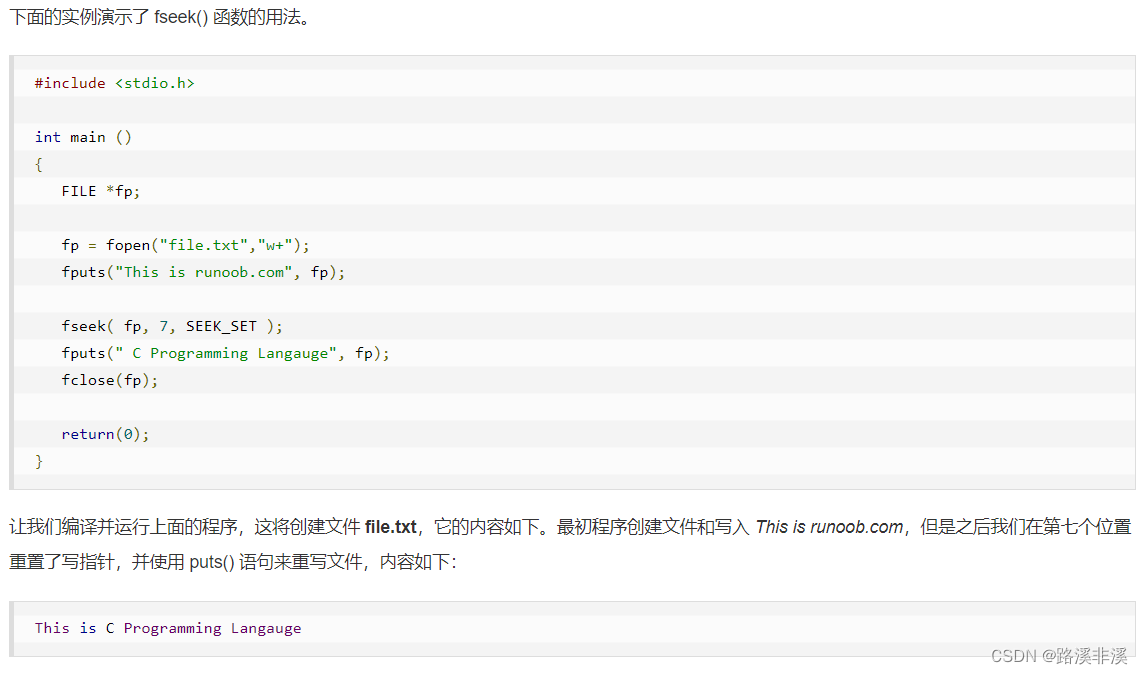
示例如下:
注意,偏移量是不算第一个字符的。
也就是说文件的开头指的是第一个字符。
| 13 | size_t fwrite(const void *ptr, size_t size, size_t nmemb, FILE *stream) 把 ptr 所指向的数组中的数据写入到给定流 stream 中。 |
fwrite()函数常用于将一块内存区域中的数据写入到本地文本。
fwrite是fread的逆操作,参数是一样的。返回值也是一样的。只不过传输的方向不同。
| 14 | int remove(const char *filename) 删除给定的文件名 filename,以便它不再被访问。 |
如果成功,则返回零。如果错误,则返回 -1,并设置 errno。
| 15 | int rename(const char *old_filename, const char *new_filename) 把 old_filename 所指向的文件名改为 new_filename。 |
如果成功,则返回零。如果错误,则返回 -1,并设置 errno。
| 16 | void rewind(FILE *stream) 设置文件位置为给定流 stream 的文件的开头。 |
| 17 | void setbuf(FILE *stream, char *buffer) 定义流 stream 应如何缓冲。 |
该函数应在与流 stream 相关的文件被打开时,且还未发生任何输入或输出操作之前被调用一次。
参数
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了一个打开的流。
- buffer -- 这是分配给用户的缓冲,它的长度至少为 BUFSIZ 字节,BUFSIZ 是一个宏常量,表示数组的长度。
BUFSIZ
这个宏是一个整数,该整数代表了 setbuf 函数使用的缓冲区大小。返回值
该函数不返回任何值。
示例如下:

| 18 | int setvbuf(FILE *stream, char *buffer, int mode, size_t size) 另一个定义流 stream 应如何缓冲的函数。 |
参数
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了一个打开的流。
- buffer -- 这是分配给用户的缓冲。如果设置为 NULL,该函数会自动分配一个指定大小的缓冲。
- mode -- 这指定了文件缓冲的模式:
模式 描述 _IOFBF 全缓冲:对于输出,数据在缓冲填满时被一次性写入。对于输入,缓冲会在请求输入且缓冲为空时被填充。 _IOLBF 行缓冲:对于输出,数据在遇到换行符或者在缓冲填满时被写入,具体视情况而定。对于输入,缓冲会在请求输入且缓冲为空时被填充,直到遇到下一个换行符。 _IONBF 无缓冲:不使用缓冲。每个 I/O 操作都被即时写入。buffer 和 size 参数被忽略。
- size --这是缓冲的大小,以字节为单位。
返回值
如果成功,则该函数返回 0,否则返回非零值。
实例演示:
和setbuf相比,主要多了可以选择缓冲模式。

| 21 | int fprintf(FILE *stream, const char *format, ...) 发送格式化输出到流 stream 中。 |
参数
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了流。
- format -- 这是 C 字符串,包含了要被写入到流 stream 中的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
specifier(说明符) 输出 c 字符 d 或 i 有符号十进制整数 e 使用 e 字符的科学科学记数法(尾数和指数) E 使用 E 字符的科学科学记数法(尾数和指数) f 十进制浮点数 g 自动选择 %e 或 %f 中合适的表示法 G 自动选择 %E 或 %f 中合适的表示法 o 有符号八进制 s 字符的字符串 u 无符号十进制整数 x 无符号十六进制整数 X 无符号十六进制整数(大写字母) p 指针地址 n 无输出 % 字符
flags(标识) 描述 - 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 + 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 (space) 如果没有写入任何符号,则在该值前面插入一个空格。 # 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。
与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。
与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。0 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 思考:为什么我们在日常使用时,很多时候明明没有“-”号也是左对齐?
答:左对齐还是右对齐是在有对齐需要的时候才有意义的。由于你并没有指定每个int值输出的长度,因此int 值有多长就会输出多长,此时没有讨论左对齐或者右对齐的意义。
你只有加上%10d(10 只是我举的例子),这时候限定了int 值输出长度为10,而12345这个int值的长度为5,这时候就有左对齐还是右对齐的分别了。
注意,这里的number是指定的数字。
width(宽度) 描述 (number) 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 * 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。
.precision(精度) 描述 .number 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。
对于 e、E 和 f 说明符:要在小数点后输出的小数位数。
对于 g 和 G 说明符:要输出的最大有效位数。
对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。
对于 c 类型:没有任何影响。
当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。.* 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。
length(长度) 描述 h 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 l 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 L 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。
- 附加参数 -- 根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同。
返回值
如果成功,则返回写入的字符总数,否则返回一个负数。
下面的实例演示了 fprintf() 函数的用法。
和printf类似,只是fprintf指定了一个输出的目标。


| 22 | int printf(const char *format, ...) 发送格式化输出到标准输出 stdout。 |
format -- 这是字符串,包含了要被写入到标准输出 stdout 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。format 标签属性是 %[flags][width][.precision][length]specifier,具体讲解如下:
格式字符 意义 a, A 以十六进制形式输出浮点数(C99 新增)。
实例 printf("pi=%a\n", 3.14); 输出 pi=0x1.91eb86p+1。
d 以十进制形式输出带符号整数(正数不输出符号) o 以八进制形式输出无符号整数(不输出前缀0) x,X 以十六进制形式输出无符号整数(不输出前缀Ox) u 以十进制形式输出无符号整数 f 以小数形式输出单、双精度实数 e,E 以指数形式输出单、双精度实数 g,G 以%f或%e中较短的输出宽度输出单、双精度实数 c 输出单个字符 s 输出字符串 p 输出指针地址 lu 32位无符号整数 llu 64位无符号整数
| 27 | int fscanf(FILE *stream, const char *format, ...) 从流 stream 读取格式化输入。 |
we are in 2014,输入时,遇到空格就视作是一个输入的结束。
比如,我将这里改成:
输出就变成了:


| 28 | int scanf(const char *format, ...) 从标准输入 stdin 读取格式化输入。 |
&a、&b、&c 中的 & 是地址运算符,分别获得这三个变量的内存地址。
所以说,输入时,实际是存入变量对应的内存地址的。
注意:
1、输入时,格式符之间是什么样的分隔,输入时就要是什么样的分隔。
2、在用 %c 输入时,空格和"转义字符"均作为有效字符。
3、接收字符串:


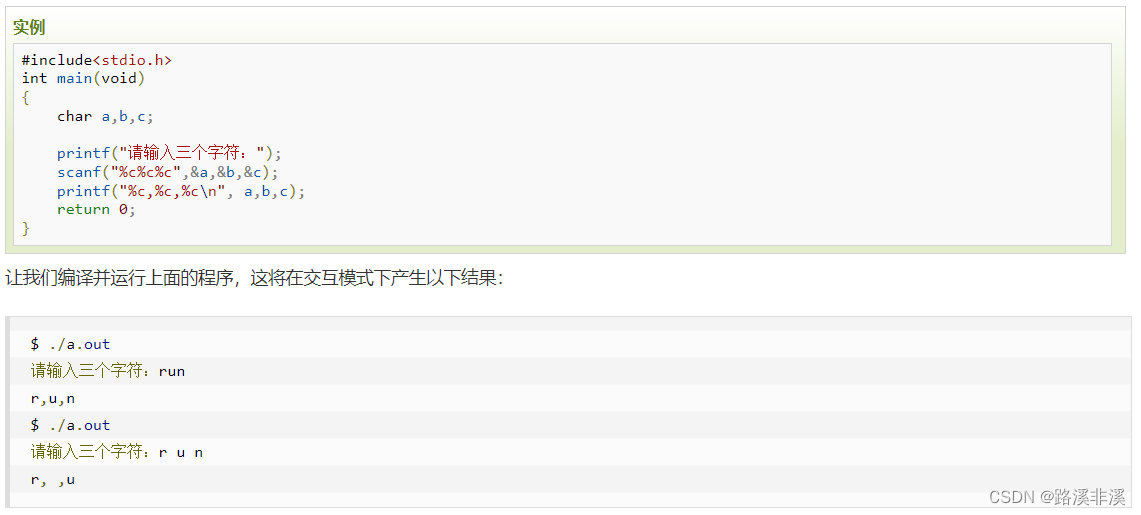

| 30 | int fgetc(FILE *stream) 从指定的流 stream 获取下一个字符(一个无符号字符),并把位置标识符往前移动。 |
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF。

| 31 | char *fgets(char *str, int n, FILE *stream) 从指定的流 stream 读取一行,并把它存储在 str 所指向的字符串内。当读取 (n-1) 个字符时,或者读取到换行符时,或者到达文件末尾时,它会停止,具体视情况而定。 |
参数
- str -- 这是指向一个字符数组的指针,该数组存储了要读取的字符串。
- n -- 这是要读取的最大字符数(包括最后的空字符)。通常是使用以 str 传递的数组长度。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要从中读取字符的流。
返回值
如果成功,该函数返回相同的 str 参数。如果到达文件末尾或者没有读取到任何字符,str 的内容保持不变,并返回一个空指针。
如果发生错误,返回一个空指针。
也就是说,只要读取不成功,就会返回NULL。
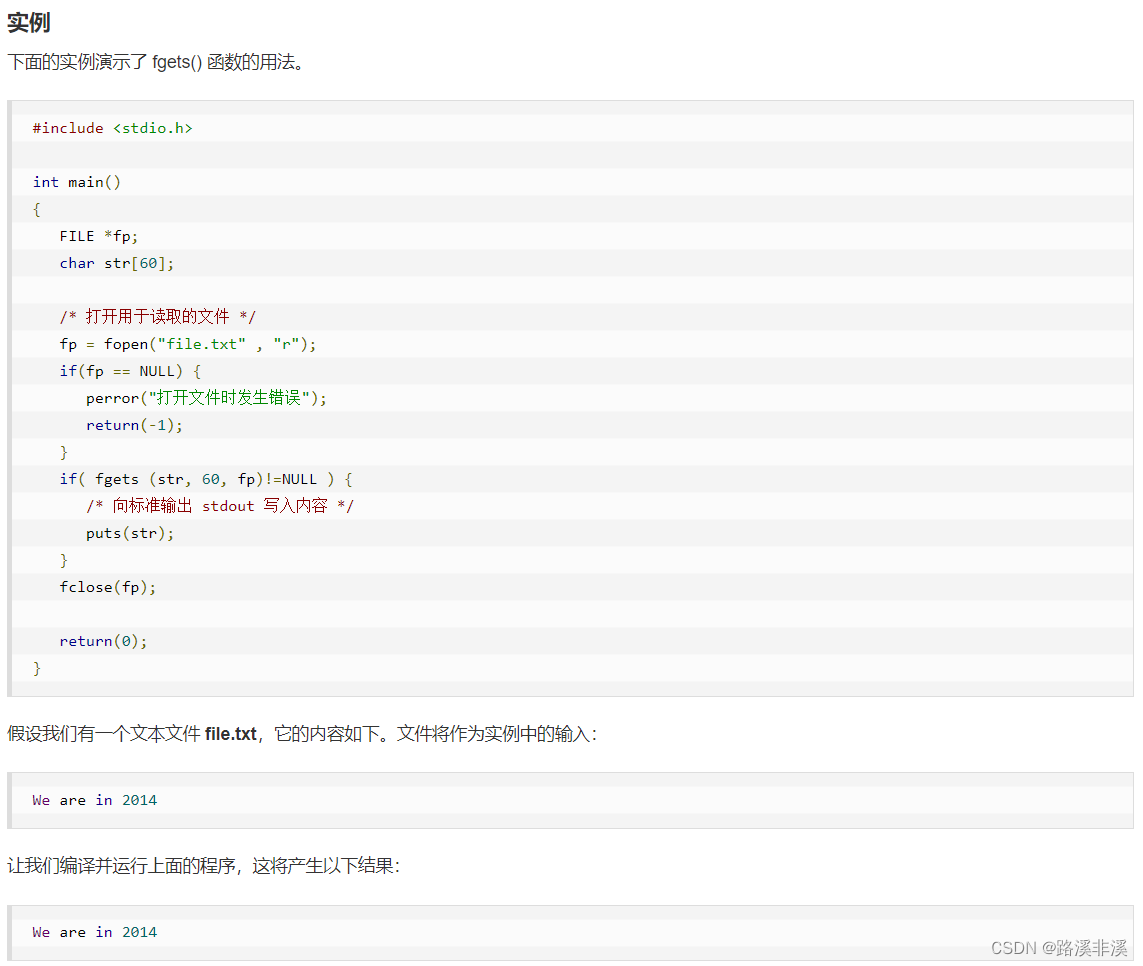
| 32 | int fputc(int char, FILE *stream) 把参数 char 指定的字符(一个无符号字符)写入到指定的流 stream 中,并把位置标识符往前移动。 |
参数
- char -- 这是要被写入的字符。该字符以其对应的 int 值进行传递。
- stream -- 这是指向 FILE 对象的指针,该 FILE 对象标识了要被写入字符的流。
返回值
如果没有发生错误,则返回被写入的字符。如果发生错误,则返回 EOF,并设置错误标识符。
实例演示:

| 33 | int fputs(const char *str, FILE *stream) 把字符串写入到指定的流 stream 中,但不包括空字符。 |
该函数返回一个非负值,如果发生错误则返回 EOF。

| 34 | int getc(FILE *stream) 从指定的流 stream 获取下一个字符(一个无符号字符),并把位置标识符往前移动。 |
fgetc和getc最大的区别在前者是函数,后者是宏,其中fget前面的字母f即为function函数的意思。使用这两个函数时,需要注意如下几点。
1、getc的参数不应当是具有副作用的表达式。有副作用的表达式,指的是表达式执行后,会改变表达式中某些变量的值。比如++i * ++i。
2、因为fgetc一定是一个函数,所以可以得到其地址。这就允许将fgetc的地址作为一个参数传送给另一个函数。
3、调用fgetc所需时间很可能长于调用getc,因为调用函数通常所需的时间长于调用宏。
| 35 | int getchar(void) 从标准输入 stdin 获取一个字符(一个无符号字符)。 |
该函数以无符号 char 强制转换为 int 的形式返回读取的字符,如果到达文件末尾或发生读错误,则返回 EOF。

| 36 | char *gets(char *str) 从标准输入 stdin 读取一行,并把它存储在 str 所指向的字符串中。当读取到换行符时,或者到达文件末尾时,它会停止,具体视情况而定。 |
如果成功,该函数返回 str。如果发生错误或者到达文件末尾时还未读取任何字符,则返回 NULL。

| 37 | int putc(int char, FILE *stream) 把参数 char 指定的字符(一个无符号字符)写入到指定的流 stream 中,并把位置标识符往前移动。 |
| 38 | int putchar(int char) 把参数 char 指定的字符(一个无符号字符)写入到标准输出 stdout 中。 |
| 39 | int puts(const char *str) 把一个字符串写入到标准输出 stdout,直到空字符,但不包括空字符。换行符会被追加到输出中。 |
| 41 | void perror(const char *str) 把一个描述性错误消息输出到标准错误 stderr。首先输出字符串 str,后跟一个冒号,然后是一个空格。 |
该函数不返回任何值。