Flink 系列教程传送门
第一章 Flink 简介
第二章 Flink 环境部署
第三章 Flink DataStream API
第四章 Flink 窗口和水位线
第五章 Flink Table API&SQL
第六章 新闻热搜实时分析系统
前言
流计算产品实时性有两个非常重要的实时性设计因素,一个是待计算的数据,一个是计算的时钟。低延时要求流计算框架尽可能早的输出计算结果,但是由于存在数据延时和现实业务数据更新的客观情况,就会导致你前一秒计算的结果,因为下一秒来了一个对上一秒已经参与计算的那条数据的更新,进而导致在下一秒时候上一秒的计算结果就是无效的了,那么流计算产品低延时需求导致流计算产品不可能无限制的等待延时数据的到来,这就一定会造成数据计算结果不精准的问题。如果流计算产品想让自己的计算结果更准确,那就需要忍受对延时数据进行更长时间的等待,那就意味着流计算产品的低延时无法达成,所以在流计算产品中鱼和熊掌兼得是不那么容易的。
一、Flink概述
在德语中,Flink 一词表示快速和灵巧,项目采用一只松鼠的彩色图案作为 logo。

Apache Flink是Apache软件基金会的一个顶级项目,是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架,并且可以同时支持实时计算和批量计算。
Flink起源于Stratosphere 项目,该项目是在2010年到2014年间由柏林工业大学、柏林洪堡大学和哈索普拉特纳研究所联合开展的,开始是做批处理,后面转向了流处理。
- 2014年4月,Stratosphere代码被贡献给Apache软件基金会,并改名为Flink,成为Apache软件基金会孵化器项目,并开始在开源大数据行业内崭露头角。
- 2014年8月,团队的大部分创始成员离开大学,共同创办了一家名为Data Artisans的公司。
- 2015年4月,Flink发布了里程碑式的重要版本0.9.0。
- 2019年1月,长期对Flink投入研发的阿里巴巴,以9000万欧元的价格收购了Data Artiscans公司。
- 2019年8月,阿里巴巴将内部版本Blink开源,合并入Flink1.9.0版本。
目前最新版本Flink为1.16.0版本,本系列课程我们采用Flink1.14.5进行讲解。
二、Flink编程模型
在自然环境中,数据的产生原本就是流式的。无论是来自 Web 服务器的事件数据,证券交易所的交易数据,还是来自工厂车间机器上的传感器数据,其数据都是流式的。但是当你分析数据时,可以围绕 有界流(bounded)或 无界流(unbounded)两种模型来组织处理数据,当然,选择不同的模型,程序的执行和处理方式也都会不同。

- 批处理是有界数据流处理的范例。在这种模式下,你可以选择在计算结果输出之前输入整个数据集,这也就意味着你可以对整个数据集的数据进行排序、统计或汇总计算后再输出结果。
- 流处理正相反,其涉及无界数据流。至少理论上来说,它的数据输入永远不会结束,因此程序必须持续不断地对到达的数据进行处理。
三、程序结构
在Hadoop中,实现一个MapReduce应用程序需要编写Map和Reduce两部分;实现一个Flink应用程序也需要同样的逻辑。一个Flink应用程序由3部分构成,或者说将Flink的操作算子可以分成3部分,分别为Source、Transformation和Sink,如图:
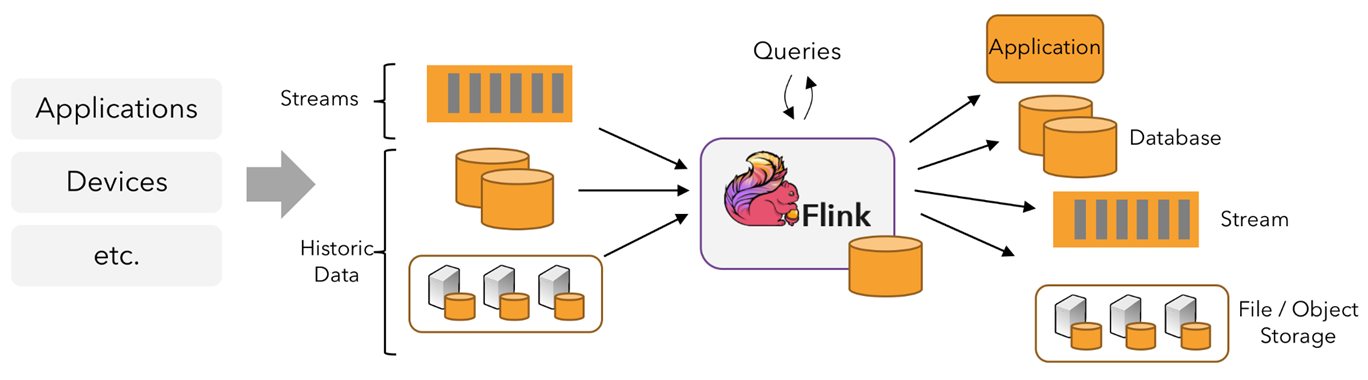
- 数据源:Flink 在流处理和批处理上的数据源大概有4类:基于本地集合的数据源(
fromCollection、fromElements)、基于文件的数据源(readTextFile)、基于网络套接字的数据源(socketTextStream)、自定义的数据源(KafkaSource)。常见的自定义数据源包括Kafka、RabbitMQ、NiFi等。 - 数据转换:数据转换的各种操作包括map、 flatMap、filter、keyBy、reduce、aggregation、window、union、select等,可以将原始数据转换成满足要求的数据。
- 数据输出:数据输出是指Flink将转换计算后的数据发送的目的地。常见的数据输出包括写入文件、打印到屏幕、写入Socket 、自定义Sink等 。
在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。
四、总图概览
Flink 应用程序可以消费来自消息队列或分布式日志这类流式数据源(例如 Apache Kafka 或 Kinesis)的实时数据,也可以从各种的数据源中消费有界的历史数据。同样,Flink 应用程序生成的结果流也可以发送到各种数据汇中。

在 Flink 中,应用程序由用户自定义算子转换而来的流式 dataflows 所组成。这些流式 dataflows 形成了有向图,以一个或多个源(source)开始,并以一个或多个汇(sink)结束。
从代码到逻辑视图。逻辑视图中圆圈表示算子,箭头表示数据流,可以在Flink Web UI中查看一个作业的逻辑视图,大数据框架的算子对计算做了抽象,方便用户进行并行计算、横向扩展和故障恢复。

通常,程序代码中的 transformation 和 dataflow 中的算子(operator)之间是一一对应的。但有时也会出现一个 transformation 包含多个算子的情况
五、入门案例
1、安装Maven整合IDEA开发工具
Maven 是一款基于 Java 平台的项目管理和整合工具,它将项目的开发和管理过程抽象成一个项目对象模型(POM)。开发人员只需要做一些简单的配置,Maven 就可以自动完成项目的编译、测试、打包、发布以及部署等工作。
约定优于配置(Convention Over Configuration)是 Maven 最核心的涉及理念之一 ,Maven对项目的目录结构、测试用例命名方式等内容都做了规定,凡是使用 Maven 管理的项目都必须遵守这些规则。
Maven 项目构建过程中,会自动创建默认项目结构,开发人员仅需要在相应目录结构下放置相应的文件即可。
官方下载地址,下载完成后,解压到合适的位置即可,建议放在D:/devtools目录下。
2、修改Maven的下载源地址和本地仓库地址
修改Maven安装目录下conf/settings.xml文件,具体修改项如下:
<localRepository>D:/devtools/apache-maven-3.6.1/localRepository</localRepository>
<mirrors>
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>*</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
<mirror>
<id>nexus-osc</id>
<mirrorOf>*</mirrorOf>
<name>Nexus osc</name>
<url>http://mirrors.163.com/maven/repository/maven-central/</url>
</mirror>
</mirrors>
<profiles>
<profile>
<id>jdk-1.8</id>
<activation>
<!--这个字段表示默认激活-->
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.encoding>UTF-8</maven.compiler.encoding>
</properties>
</profile>
</profiles>3、IDEA整合Maven
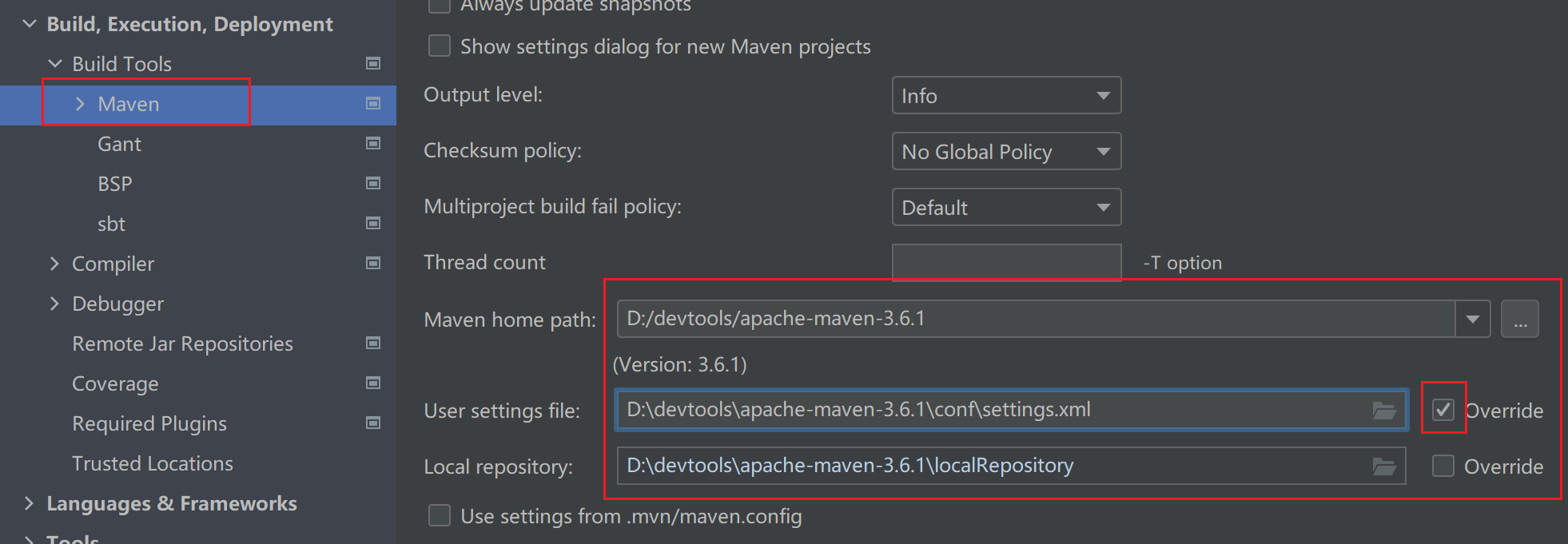
在IDEA的设置中,搜索maven,做如下修改,选择本地安装的Maven相关选项。
4、使用Flink实现批计算
使用Flink Scala完成批处理的词频统计案例,具体处理流程如下:

在pom.xml中添加flink所需依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.12</artifactId>
<version>1.14.5</version>
</dependency>
<!--No ExecutorFactory found to execute the application. 从 flink1.11.0 版本开始,需要多引入一个 flink-client 包-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_2.12</artifactId>
<version>1.14.5</version>
</dependency>详细代码示例如下:
import org.apache.flink.api.scala._
object WordCountBatchTest {
def main(args: Array[String]): Unit = {
// 创建Flink的执行环境(批处理的)
val env = ExecutionEnvironment.getExecutionEnvironment
// Source 读取数据源
val data = env.readTextFile("datasource/word.txt")
// Transformation 转换 计算
val result = data
.flatMap(line=>line.split(" "))
.map(word=>(word,1))
.groupBy(0)
.sum(1)
// Sink 把转换的结果输出
result.print()
}
}
从 flink1.11.0 版本开始,需要多引入一个 flink-client 包
5、使用Flink实现流计算
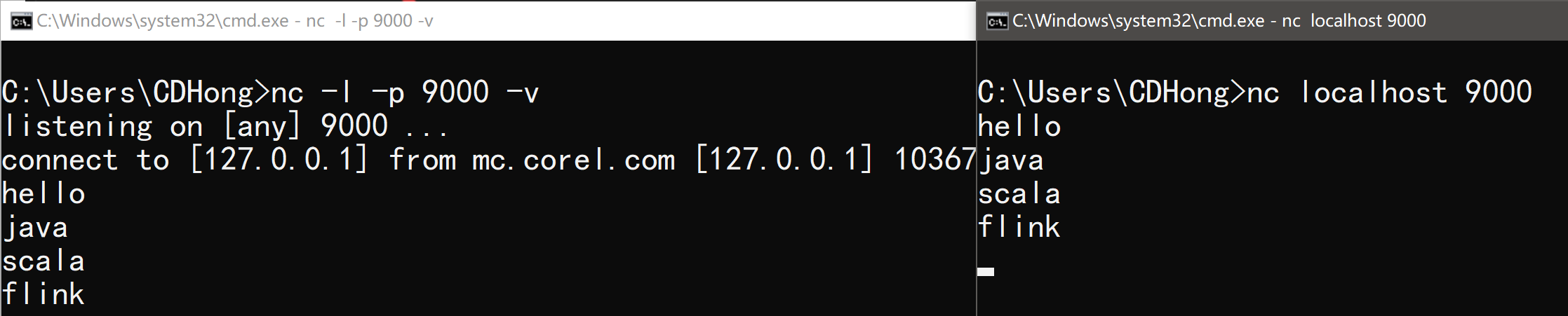
Flink流计算会借助NetCat工具进行流式数据进行数据录入,具体安装使用如下:
Netcat官网下载地址,下载netcat-win32-1.12.zip压缩包,解压到安装目录,并配置PATH环境变量。
- 输入
nc -l -p 9000 -v监控9000端口,接收数据 - 输入
nc localhost 9000进行连接,并发送数据
在cmd中输入命令:nc -l -p 666监控666端口,并输入测试数据
在pom.xml中添加flink流处理所需依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.12</artifactId>
<version>1.14.5</version>
<!--<scope>provided</scope>-->
</dependency>使用Flink Scala编写流式数据处理程序
import org.apache.flink.streaming.api.scala._
object StreamWordCount {
def main(args: Array[String]): Unit = {
// 获取Flink流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 数据源-监控Netcat数据端口666
val data = env.socketTextStream("localhost", 666)
// 数据转换
val result = data
.flatMap(_.split(" "))
.filter(_.nonEmpty)
.map((_,1))
.keyBy(_._1)
.sum(1)
// Sink 数据输出到控制台
result.print()
// 流处理环境执行
env.execute()
}
}