SpringCloud——>SpringBoot——>JavaWeb
微服务技术栈导学1
哔站up黑马程序员主讲老师,一上来就给介绍了SpringCloud出现的背景:微服务是分布式架构的一种,分布式架构就是要把服务做拆分,而SpringCloud只是解决了服务拆分式的治理问题,至于其他的一些问题并没有给出解决方案,所以一个完整的微服务技术,包含的不仅仅是SC(SpringCloud)。
SC第一件要做的事情就是分:
将一个单体项目拆分为多个独立的项目,把独立的项目成为服务
一个业务往往需要服务集群(多个服务)来构建:

至此,当一个请求来的时候,各服务之间会进行相互调用,当业务越来越复杂的时候,调用也越来越复杂
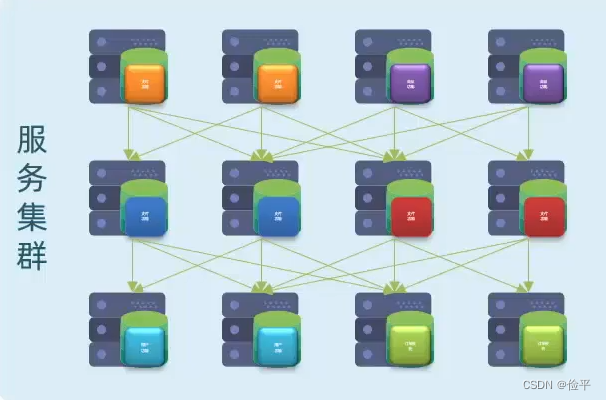
此时,他们之间的调用关系让程序员来记录和维护是不可能的,所以需要一个注册中心来存储每一个服务的IP和端口,当一个服务需要调用另一个服务时,直接向注册中心拉取或注册服务信息。
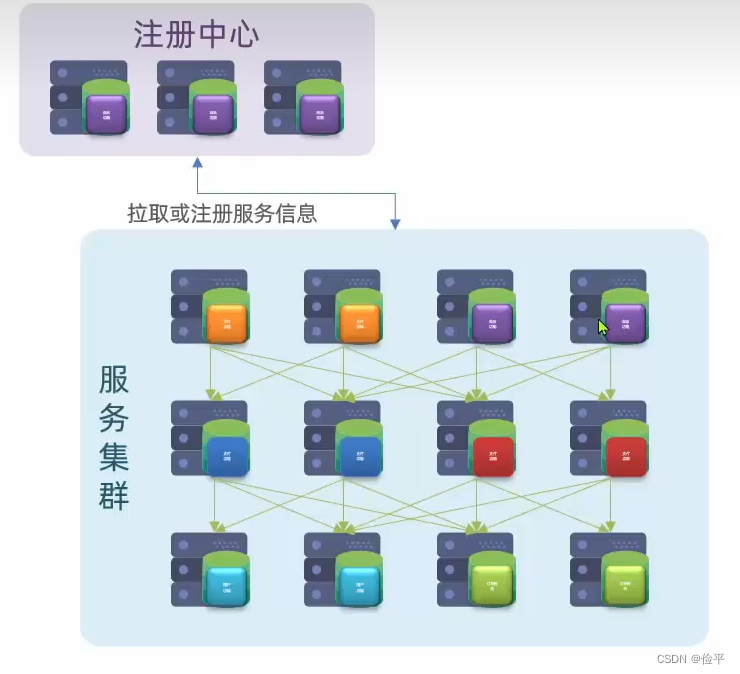
有时我们需要对服务的配置进行修改,为了提高修改效率,便有了统一的配置中心,它可以通知个服务进行相应的修改,如果将来你需要配置一些服务的细节,直接找配置中心就好。
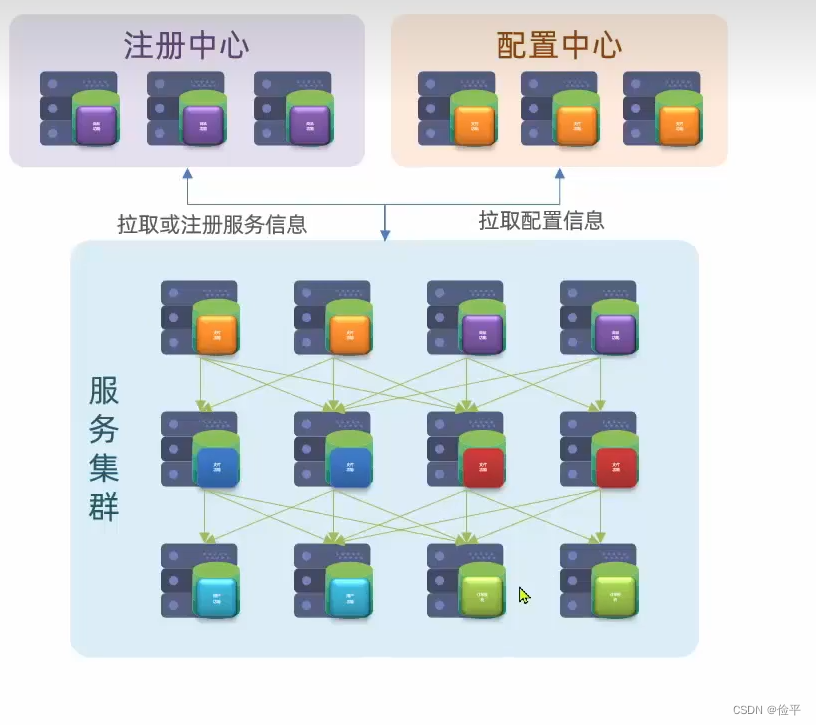
之前我们说每一个服务都有IP和端口,但是用户在访问时,如何将对应的服务返回给用户,换句话说用户想要的服务怎么跟服务集群中的服务相对应起来,那便是设置服务网关,这个网关既可以可以将用户路由到对应的服务,也可以在此过程中做一些负载均衡。
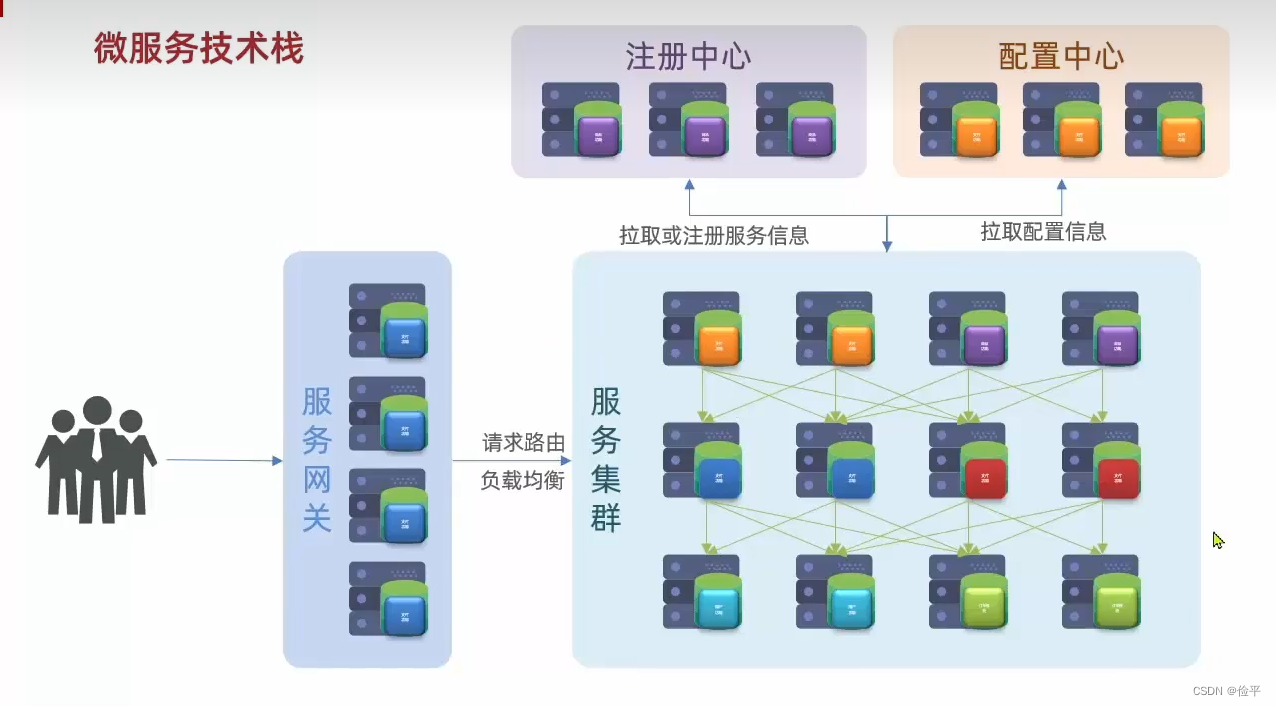
数据库虽然集群,但是总归没人多,所以数据库扛不住那么多的高并发,所以加入了分布式缓存,就是把数据库数据放到内存当中(数据库数据一般存储在硬盘中)以此来缓解数据库的压力,用户请求先到缓存,未命中再访问数据库,但是一些海量数据的搜索与统计分析缓存做不了,这时候我们需要用到分布式搜索,那数据库将来的职责就是,其实就是做一种数据的写操作,还有一些事务类型对数据安全要求比较高的数据存储,
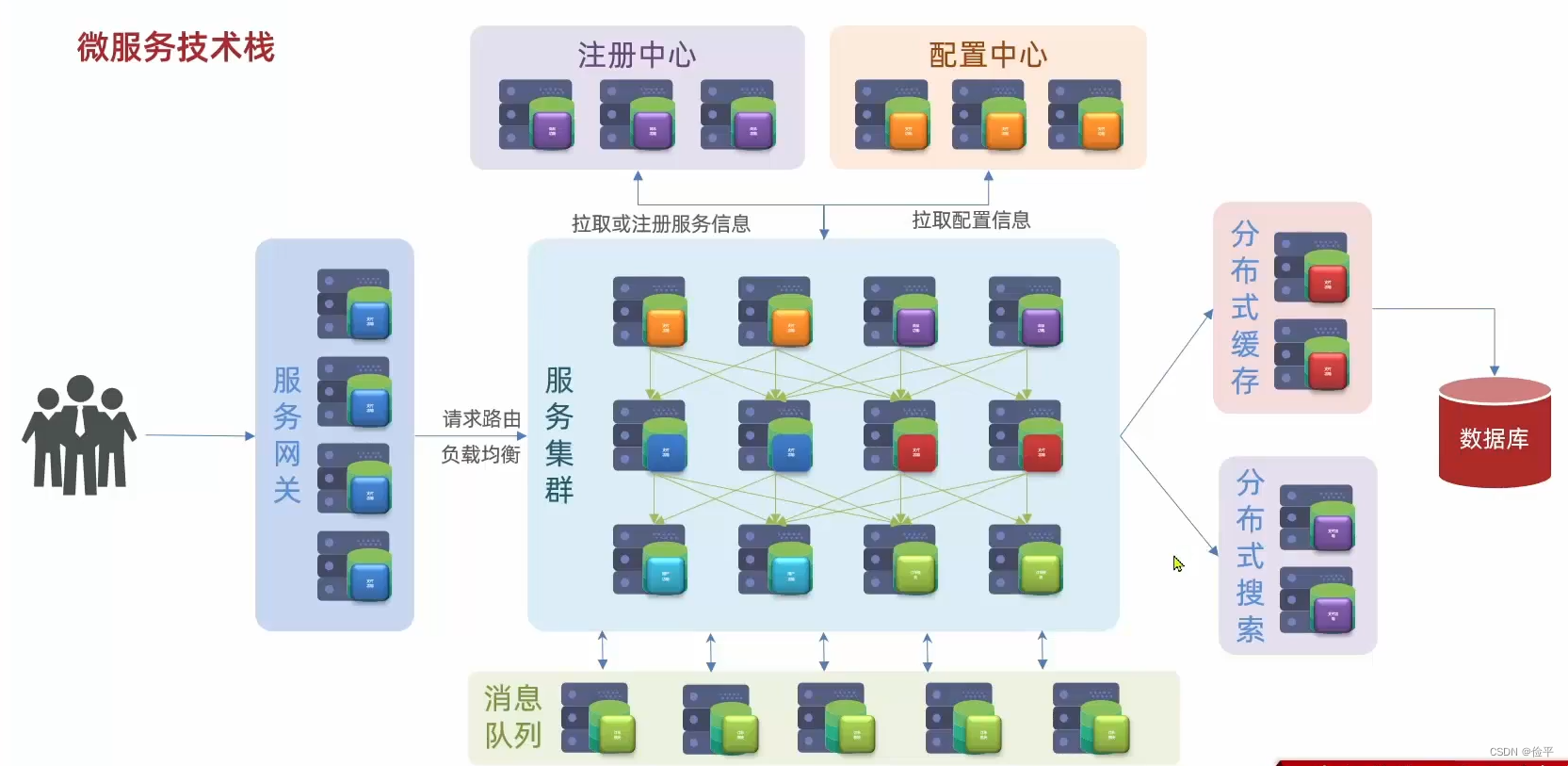
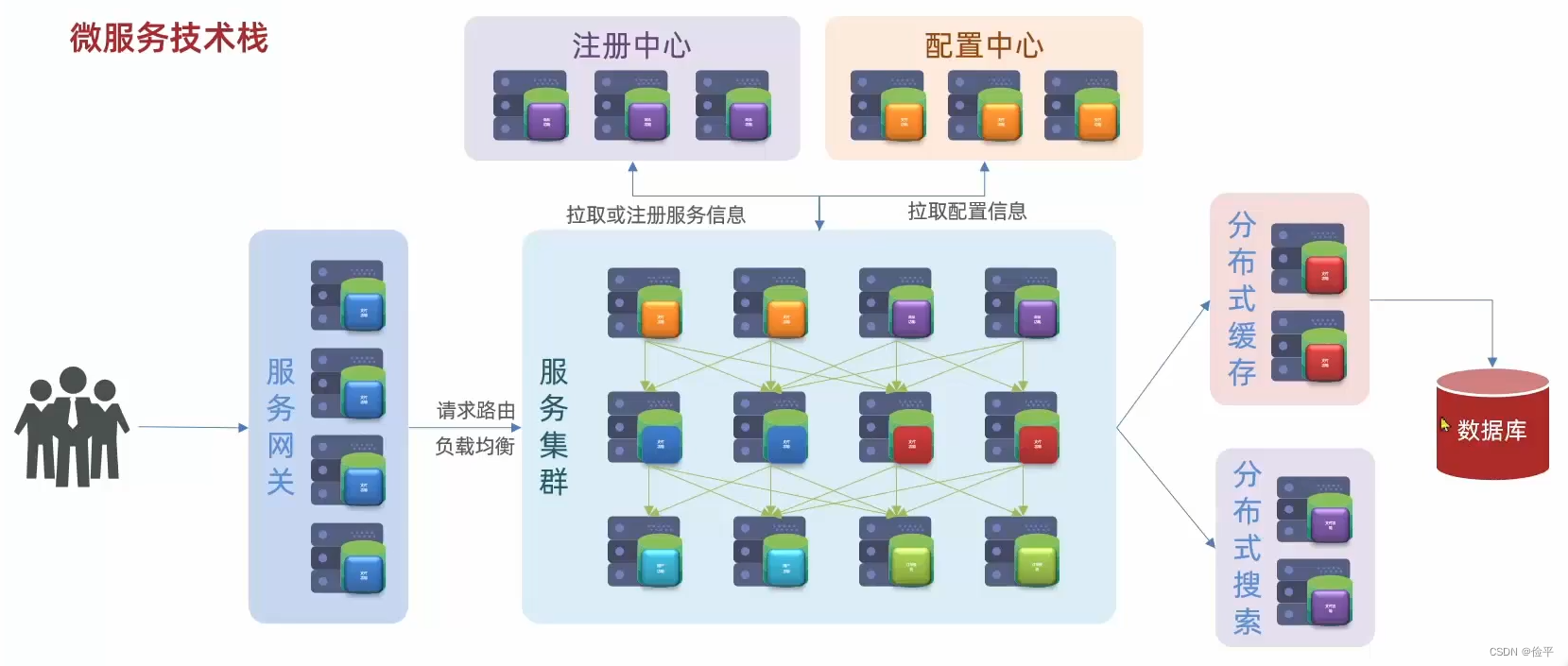 最后在微服务里面还需要一种异步通信的消息队列组件,为什么呢?因为一条请求之后,要调用多个服务,比如A服务调用B服务,B服务调用C服务,这个调用时长啊就等于每个服务执行时长之和,所以性能是有一定下降的,而异步通信的意思就是,请求来了,我调用了服务A,A不再调用BC,而是发条消息通知他们,带干活了,这样A干完就可以直接结束,执行时间也就缩短了,吞吐能力也就变强了,所以异步通信可以提高并发能力,所以在一些秒杀的高并发场景下就可以应用了。
最后在微服务里面还需要一种异步通信的消息队列组件,为什么呢?因为一条请求之后,要调用多个服务,比如A服务调用B服务,B服务调用C服务,这个调用时长啊就等于每个服务执行时长之和,所以性能是有一定下降的,而异步通信的意思就是,请求来了,我调用了服务A,A不再调用BC,而是发条消息通知他们,带干活了,这样A干完就可以直接结束,执行时间也就缩短了,吞吐能力也就变强了,所以异步通信可以提高并发能力,所以在一些秒杀的高并发场景下就可以应用了。
那么这如此庞大的服务在运行的过程当中,如果出现了什么问题,人工排查起来那将是一场灾难,所以我们要给出一些解决方案,有两个,分布式日志服务和系统监控链路追踪,其中分布式日志服务可以统计成百上千服务的日志,统一地做一个存储,统计和分析,到时候出现问题就比较好定位;系统监控链路追踪它可以实时监控每一个服务结点的CPU负载,内存的占用等等情况,这两个解决方案都可以帮助我们快速定位问题所在的位置。
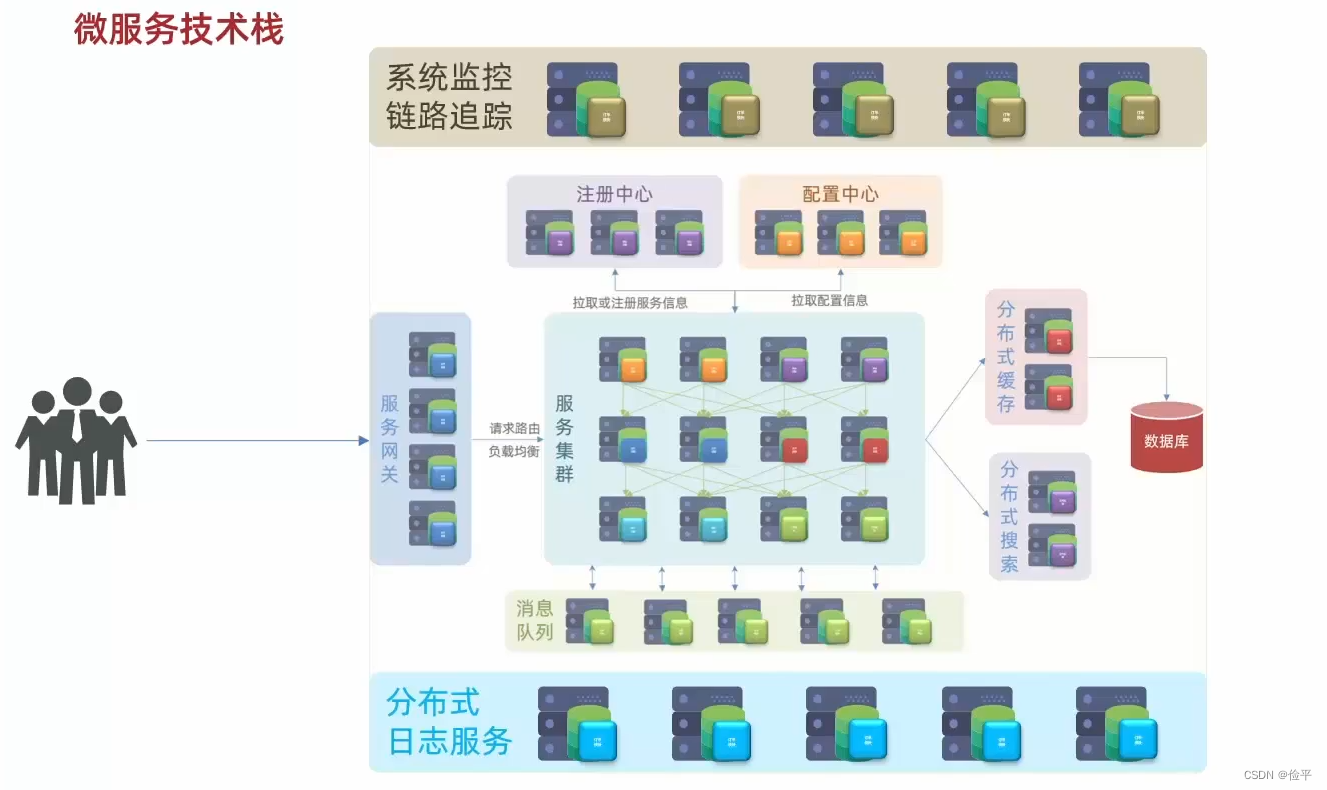
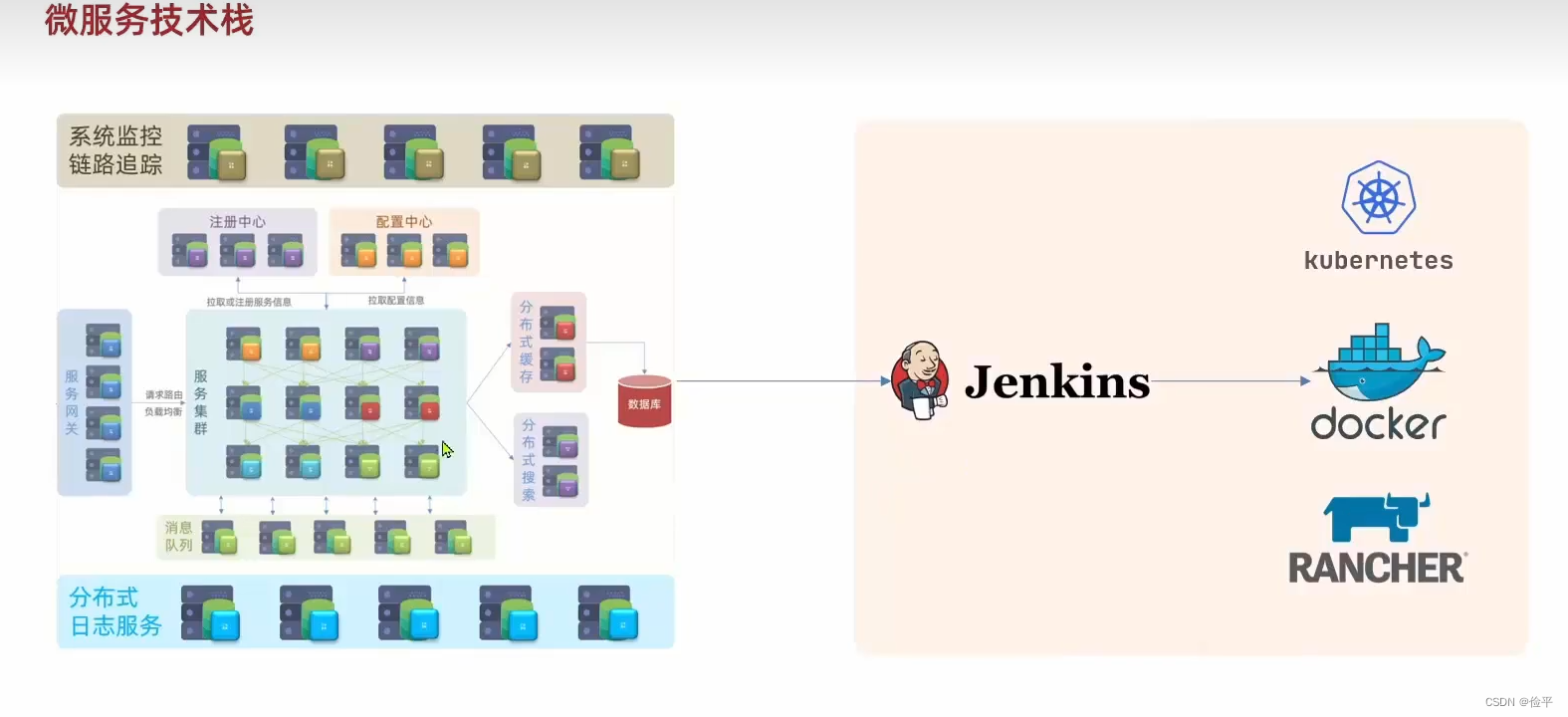
这样一个有成百上千个服务的微服务,我们部署要怎么部署呢?答案是采用自动化的部署,利用Jenkins可以将你的服务项目进行自动化的编译再基于docker打包形成镜像,再基于kubernetes和RANCHER去实现自动化的部署。
微服务技术栈导学2
学习内容大致分为五个部分
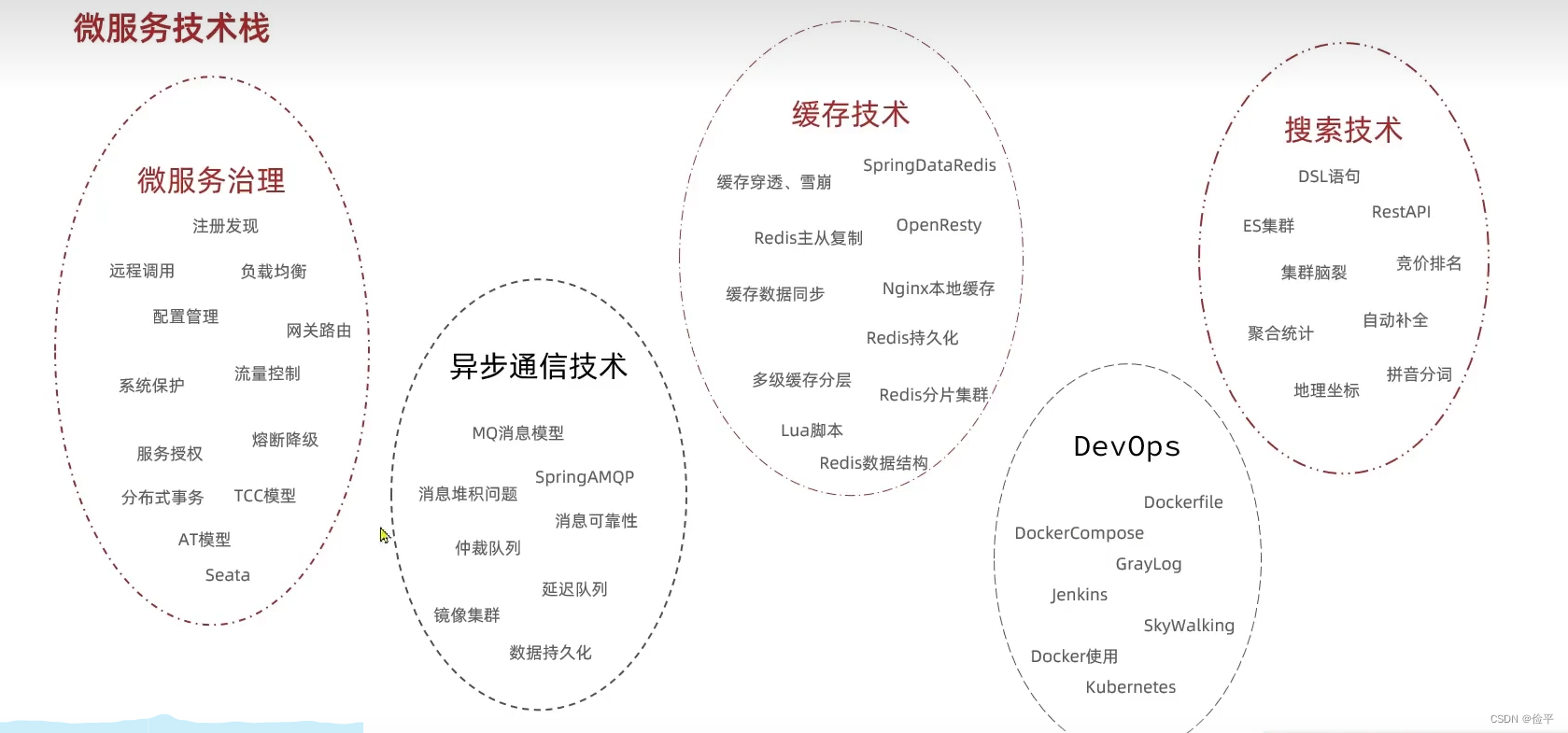
主讲师说,我们平时学的百分之二十的内容足以应对百分之八十的工作内容(没找到过工作,不知道真假,不过参考一个梗,面试造火箭,工作拧螺丝,应该不是空穴来风?)
为了提高学习效率,分为三个层级一一讲解,难度递增,从实用到高级再到面试。

这一整套跟下来,我们最后会有一个项目供大家参考学习
今日课程介绍1

内容简介:
- 单体架构和微服务架构的区别,以及为什么要用微服务架构
- 单体架构和分布式服务架构的具体代码上的区别
- 学习一个名为eureka的注册中心来实现服务治理
- 学习一个由阿里巴巴最新研发的nacos注册中心,以及这两个注册中心的区别是什么
认知微服务
服务架构演变与SC
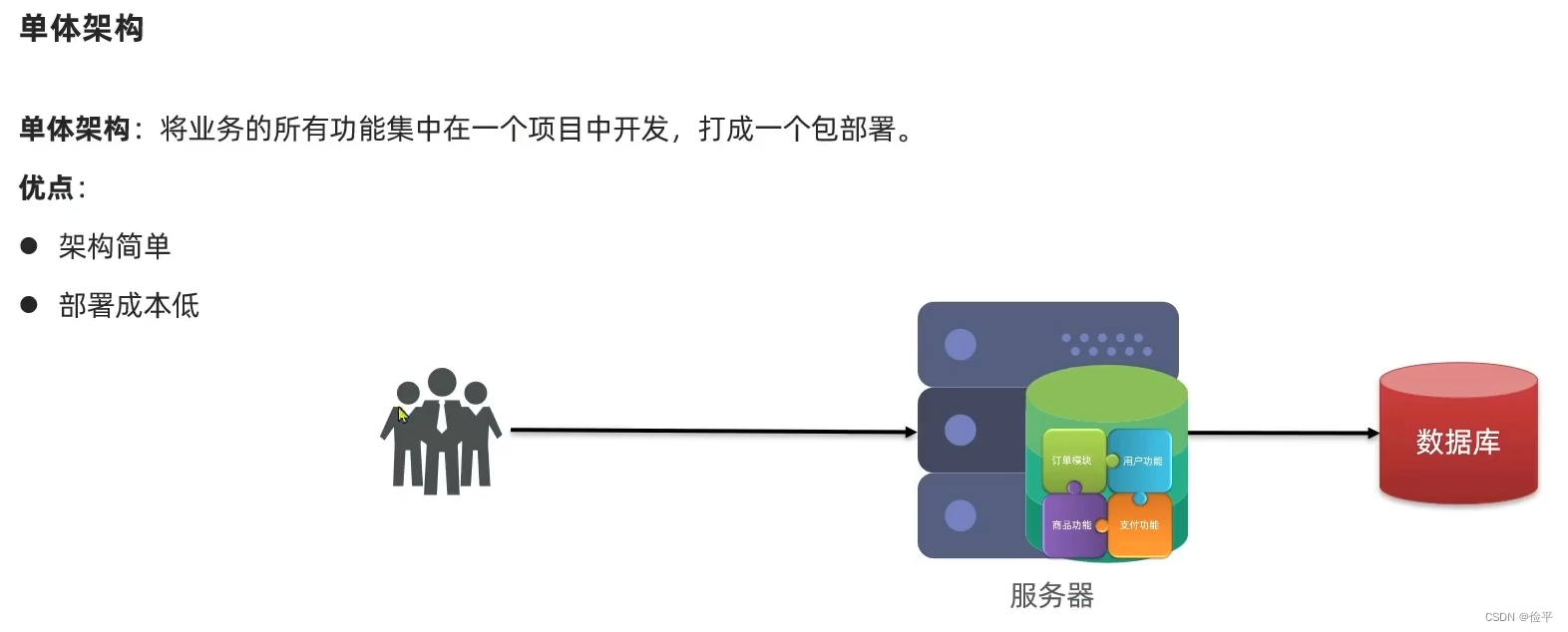
单体架构也会有负载均衡哦,但是单体架构最致命的缺点就是耦合度高,像大型互联网公司,例如某宝,某东,某夕夕,他们的项目有成千上万的功能,那代码就是几十万行,光是编译和打包估计就得花十几分钟,这效率多低啊,而且所有的功能堆在一起,代码业务你中有我我中有你,他们之间的边界也越来越模糊 ,将来你改了一个地方的代码,其他地方的代码也收到影响,可以说是牵一发而动全身,所以大型项目一定会用分布式架构。
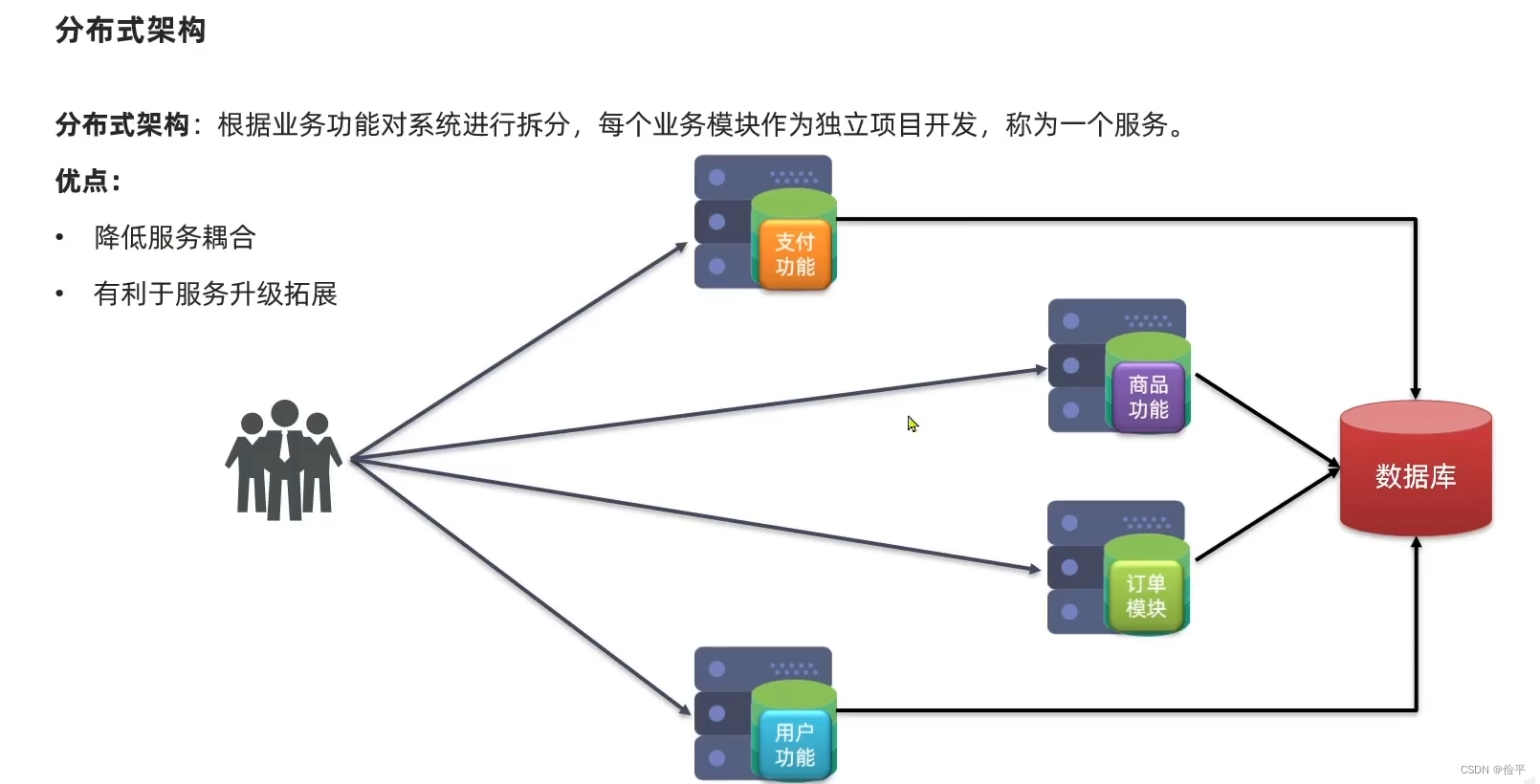
那么在拆分的过程中也会有一些问题,服务拆分是一方面,拆分好的服务要保证高可用,所以得有集群
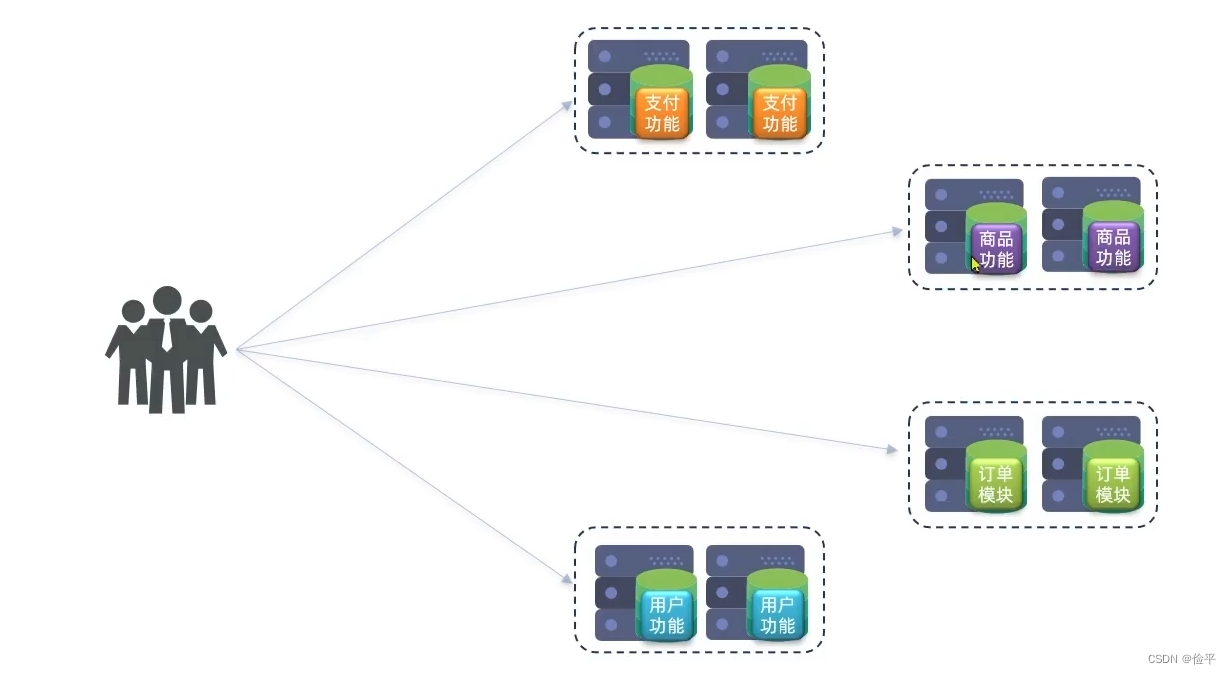
还有一个问题,在单体项目中,如果我们的商品功能要调用订单模块,我们直接调用就可以,它是在一个项目中的,但是分布式架构,服务是部署在独立的机器上的,这时就不能再调用它的代码了,所以要考虑服务之间的远程调用,还要考虑一些其他的问题:
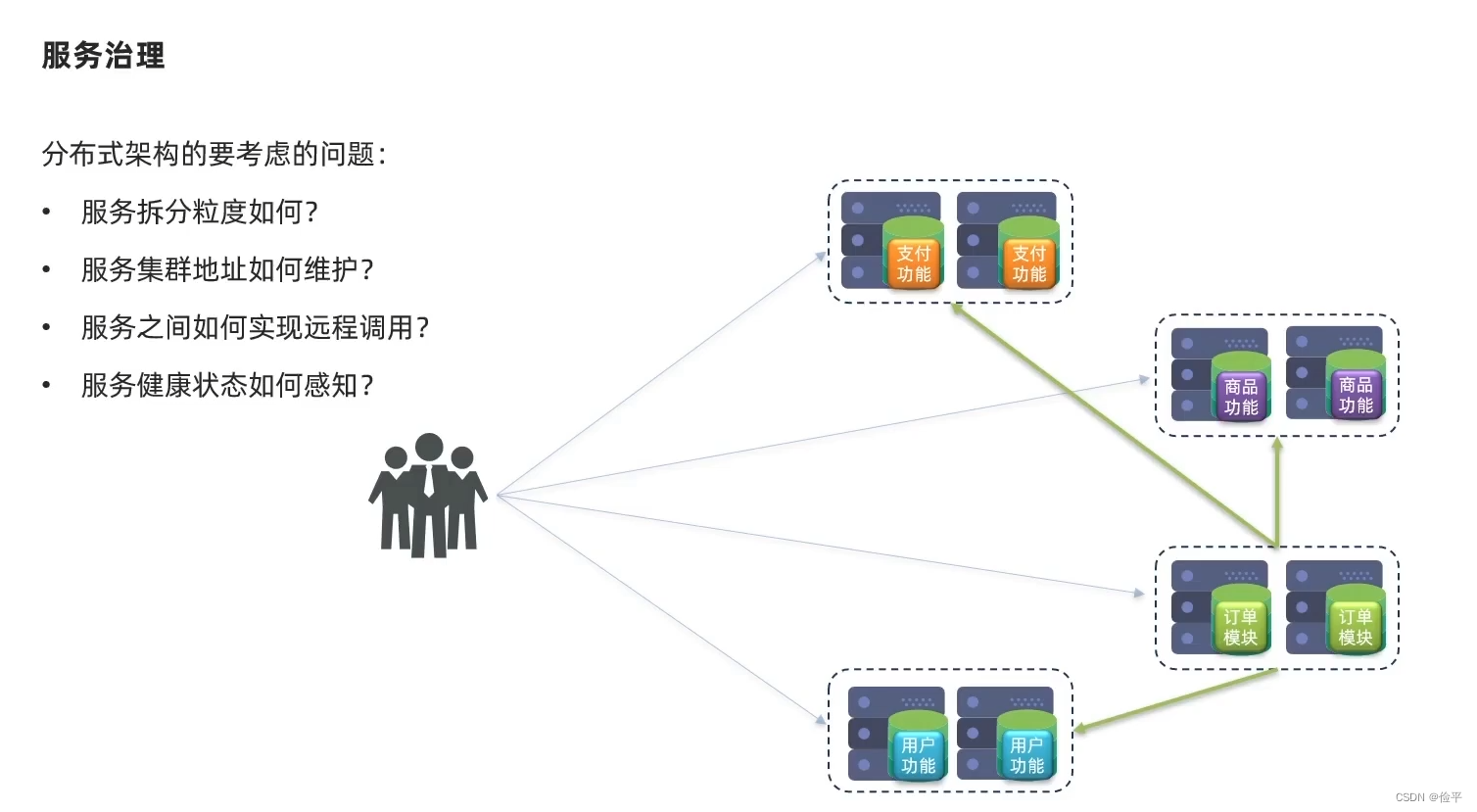
- 服务粒度,这个服务具体要拆分到什么程度?
- 服务集群,到时候肯定一个服务要集群到上百台机器,那我要调用你的服务,我怎么知道你上百台机器的地址,肯定不能写死,万一上线之后又变了呢?所以地址一定要方便维护
- 服务健康状况,我要调用你的服务,我怎么知道你的服务是好的?万一你的服务挂了,我来调用你,导致我这也出问题了,这叫级联式反应
为了解决这些问题,衍生了各种解决方案例如webservice、ESB、Dubbo、SC,但是近几年最火的解决方案无疑是是微服务方案了。
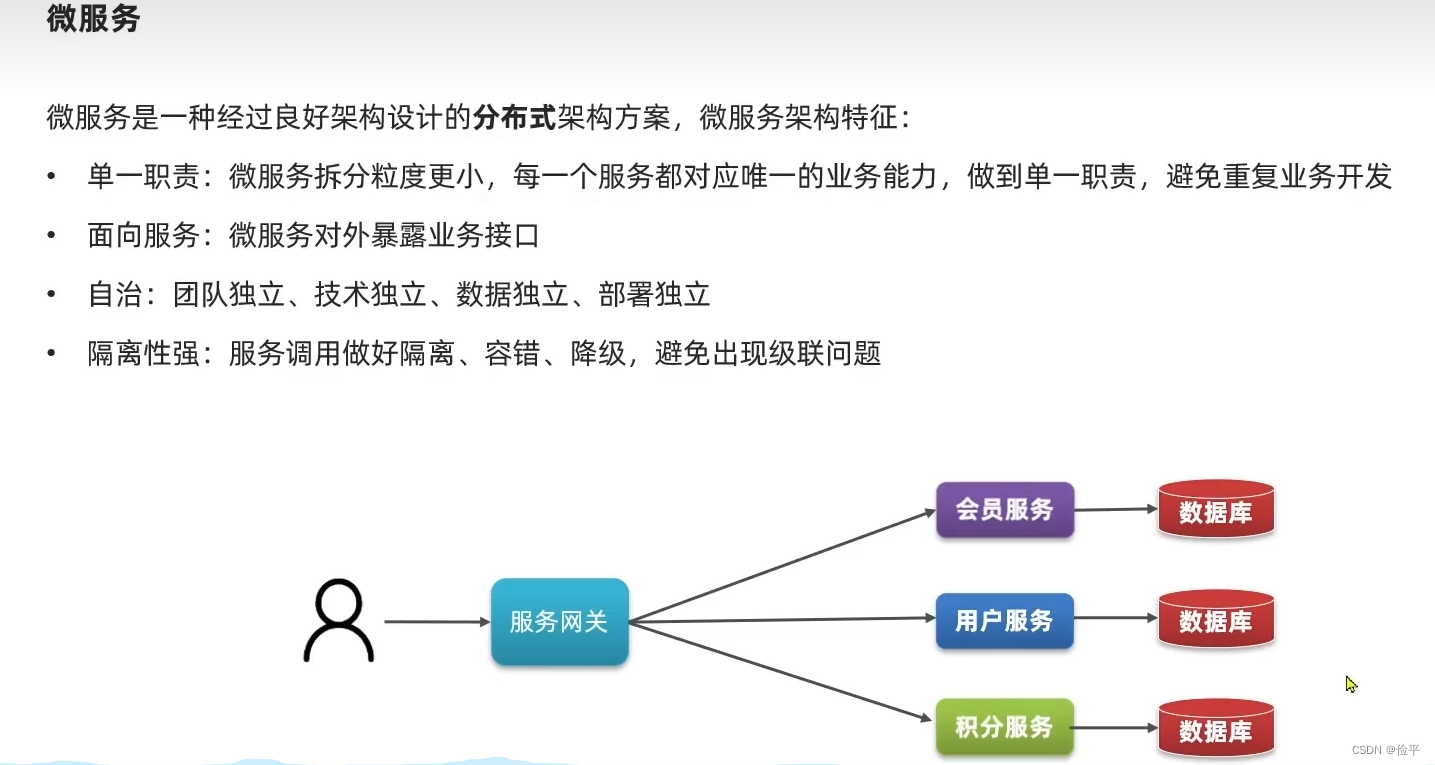
核心思想就是,高内聚低耦合,降低服务之间的联系,最后总结一下:
注意:分布式架构具有松耦合的特点,而微服务是分布式架构的一种,它是一种良好的分布式架构方案,且微服务把这种松耦合的特点发挥到极致,它拆分的粒度更小了,所以带来的代价便是架构复杂,运维、监控和部署的难度提高。
微服务结构:
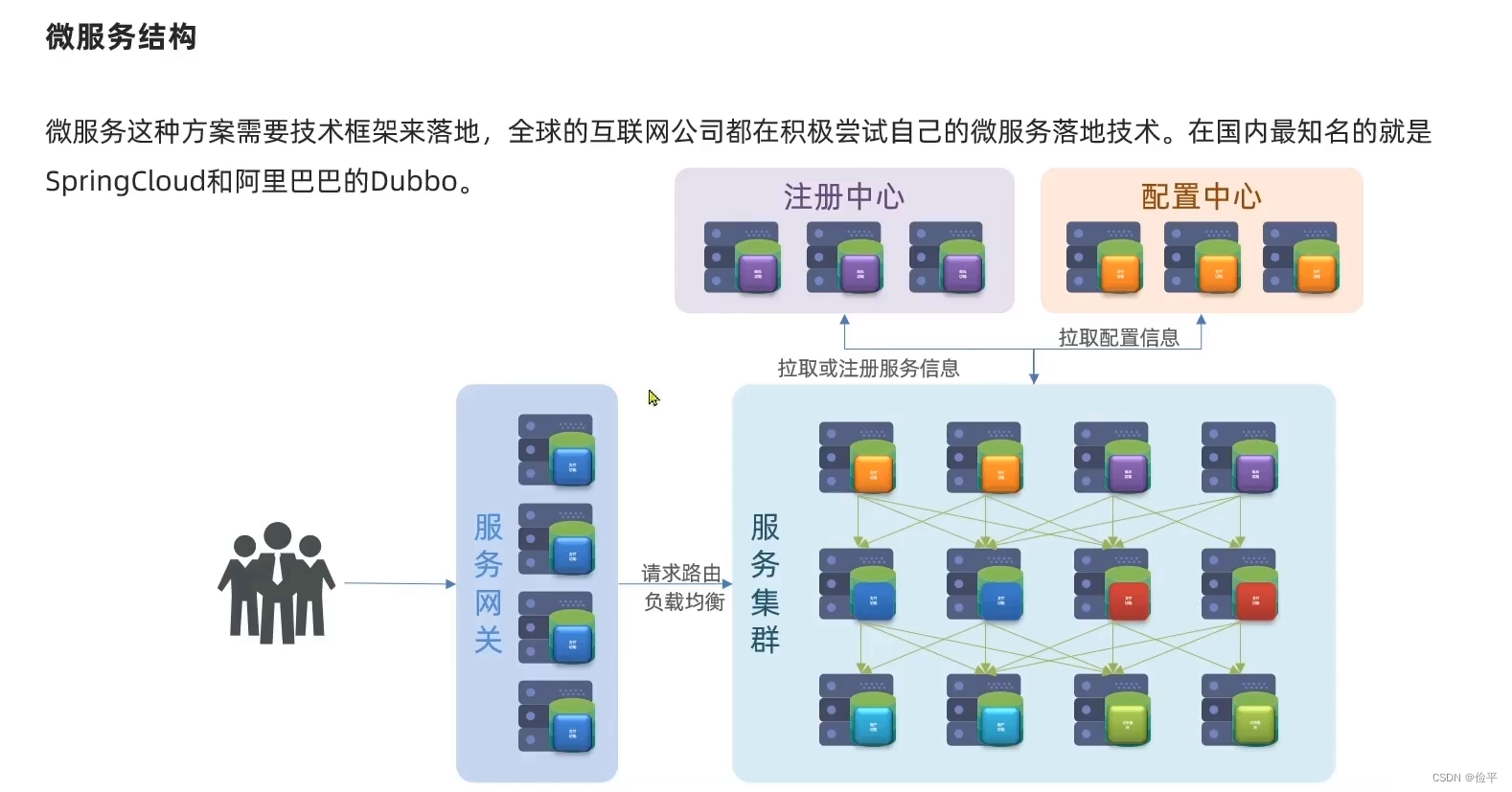
对于微服务要实现的内容大概就是四个部分:服务网关、注册中心、配置中心和服务集群。常见的实现方式就是SC和Dubbo,但是这两个在一些实现细节上有所差异:

阿里巴巴之所以成为大厂不是没有原因的呀,其早在2012年就研究起了基于远程调用服务的技术Dubbo,可以说是走在了技术的前列,SC并不是一下子发明出来的,而是融合了全球各个优秀的开源项目,将他们整合在一起形成了一种完整额微服务体系。
由上图我们知道,SCalibaba它既有springcloud又有alibaba早期自己的组件,可以说即满足了用springcloud开发的企业,又满足了早期使用dubbo技术开发的企业。
目前大部分企业的技术栈基于以下四种类型:
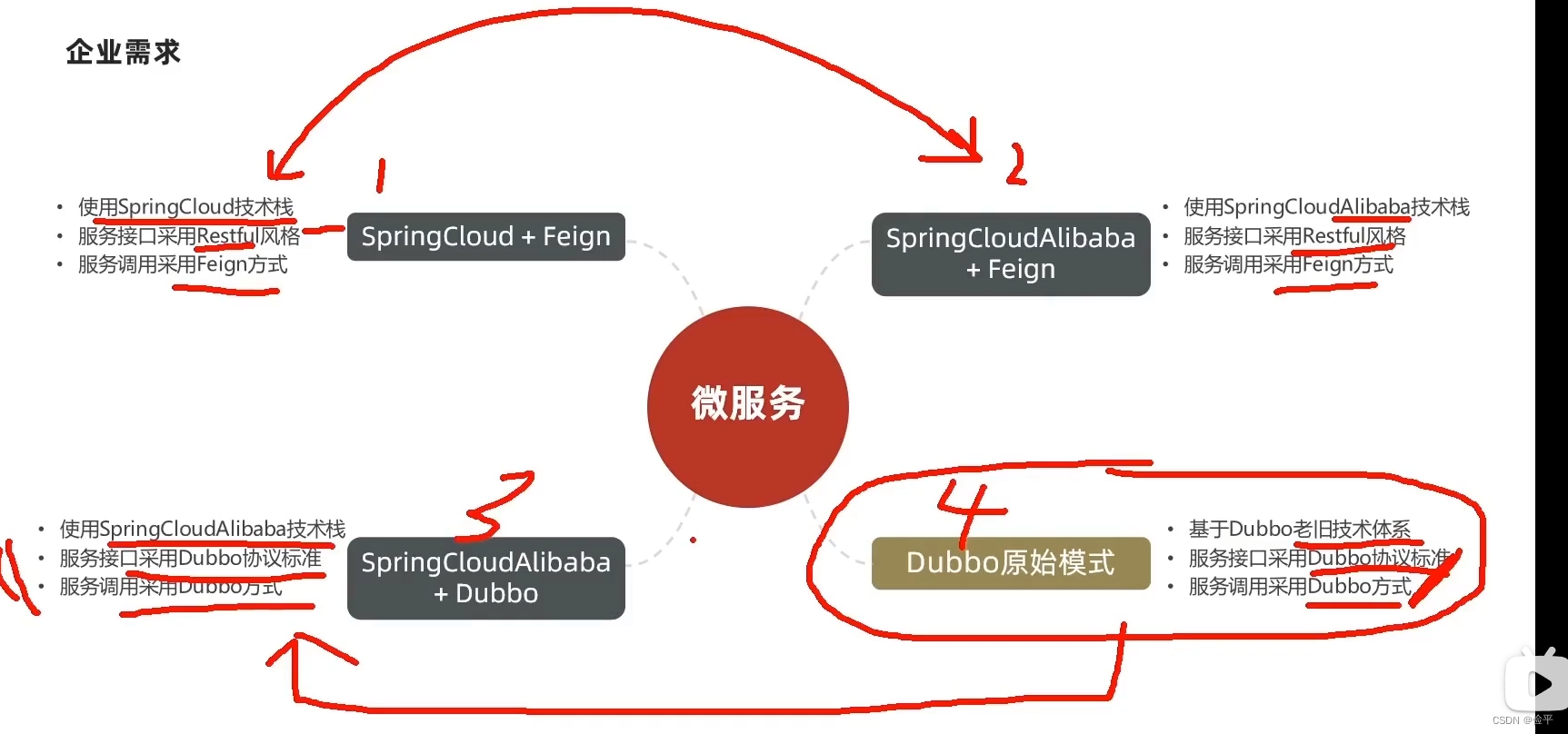
其中上面两种属于一类,因为服务接口和调用都采用Restful风格和Feign方式。
而下面两种属于一类,因为服务接口和调用都采用Dubbo
认识微服务-SC
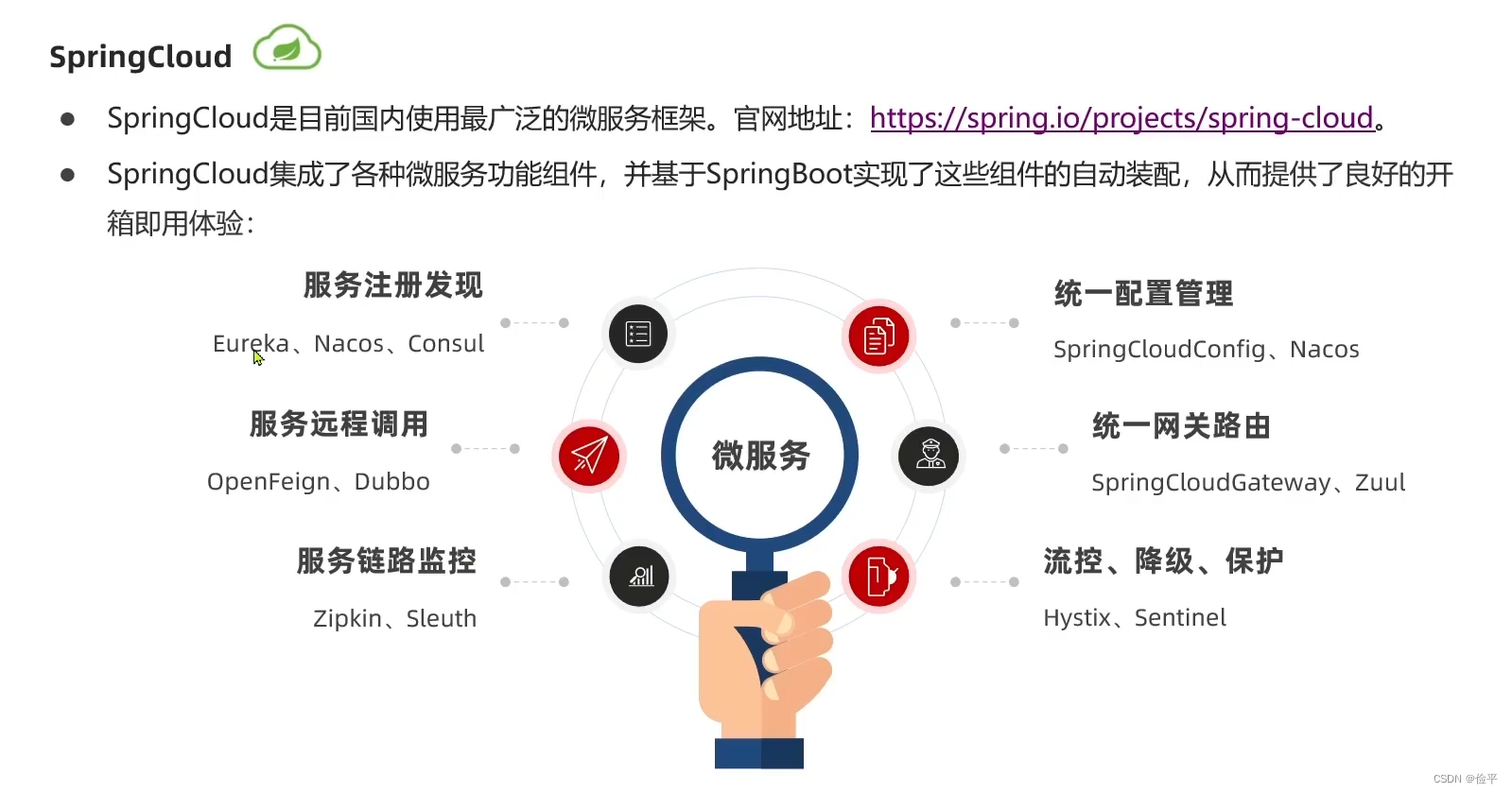
下图,SC和SB的版本一定要一一对应,否则可能会报错

服务拆分
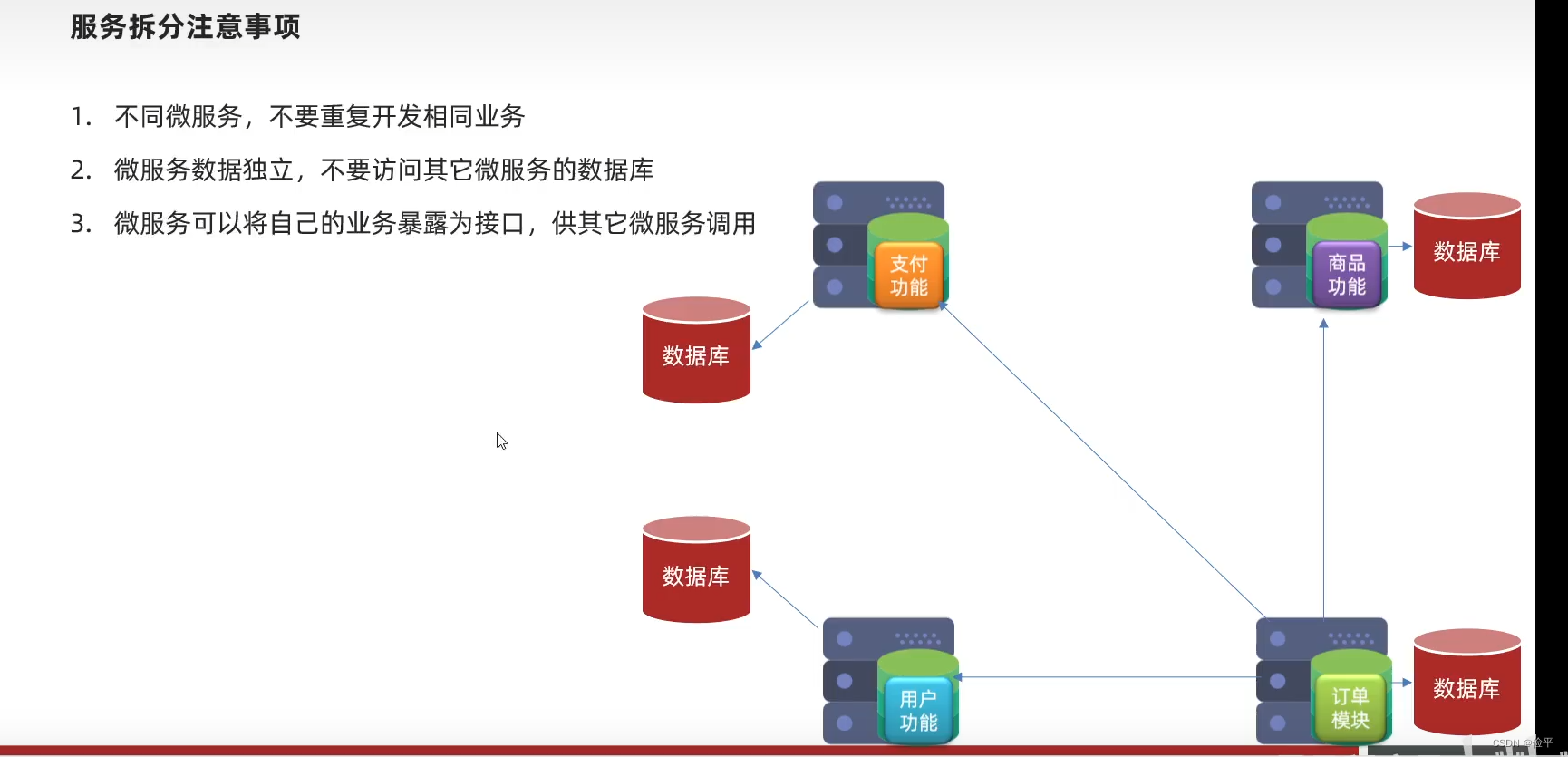
比如说我们现在有一个需求,查询订单的同时把订单中关联的用户信息,商品信息都要查,那么如果在单体架构中,我肯定是写一个方法是查订单,在查询过程中得到了用户ID,我再去数据库里把用户查出来,得到商品ID,我再去数据库里把商品查出来,那么这些功能全部写在了订单模块里,这种做法是完全违背了微服务的原则的,而且用户功能和商品功能都可以查询,那么这个业务也是不是重复开发了呢?
所以微服务一定要遵守单一原则。
每个微服务都有自己的数据库,是的数据库存储谁相应的信息,用户微服务的数据库就存储用户相关的数据,而不存储其他订单,商品等数据。
但同时要实现业务需求,我们要查询订单的同时获取用户信息,怎么办呢?那就是各服务要暴露相关的接口。
持续更新中…