1 介绍
本文主要依据《鲲鹏Bigdata pro之Hive集群部署》实验教程上的Hive操作例子讲解,方便大数据学员重用相应的操作语句。同时对实验过程中出现的问题给以解决方法,重现问题解决的过程。以让大家认识到,出现问题很正常;同时,解决问题的过程需要我们探索和付出努力。
2 Hive 基本操作
本小节进讲解了Hive表的创建、查询方面的操作,内容很有局限。后续我会写一个详细的Hive操作的博文。那么,我们是在哪个数据库上操作的呢?鲲鹏实验手册根本没有给以说明。可使用如下命令:
hive> SELECT current_database();
OK
default
Time taken: 1.162 seconds, Fetched: 1 row(s)
可以查询到当前我们使用的数据库为default。
2.1 Hive创建表
创建内部表
hive>create table cga_info1(name string, gender string, time int) row format delimited fields terminated by ',' stored as textfile;
OK
Time taken: 0.568 seconds
hive> show tables like 'cga_info1';
OK
cga_info1
Time taken: 0.027 seconds, Fetched: 1 row(s)
然后,我们可以再开一个MobaXterm 会话,使用命令查看:

从上面结果可以看出,当我们用Hive创建表后,实际上是在HDFS上面创建了一个目录。
创建外部表
hive> create external table cga_info2(name string, gender string,time int) row format delimited fields terminated by ',' stored as textfile;
OK
Time taken: 0.06 seconds
hive> show tables like 'cga_info2';
OK
cga_info2
Time taken: 0.021 seconds, Fetched: 1 row(s)
先创建一个表,然后载入本地数据
步骤1 :新打开一个MobaXterm会话,在节点1上新建文件:
vim /root/hive.txt
在其中添加内容:
xiaozhao,female,20
xiaoqian,male,21
xiaosun, male,25
xiaoli,female,40
xiaozhou,male,33
步骤2:建表“cga_info3”
在MobaXterm的带hive的会话上,执行:
hive> create table cga_info3(name string,gender string,time int) row format delimited fields terminated by ',' stored as textfile;
OK
Time taken: 0.055 seconds
hive> load data local inpath '/root/hive.txt' into table cga_info3;
Loading data to table default.cga_info3
OK
Time taken: 0.545 seconds
hive> select * from cga_info3;
OK
xiaozhao female 20
xiaoqian male 21
xiaosun male 25
xiaoli female 40
xiaozhou male 33
Time taken: 0.94 seconds, Fetched: 5 row(s)
载入HDFS上数据到Hive表
步骤1:在HDFS上创建文件夹(节点1的非hive的MobaXterm会话上)
hdfs dfs -mkdir -p /tmp/hivetest
hdfs dfs -put /root/hive.txt /tmp/hivetest
步骤2:查看是否上传成功
hdfs dfs -ls /tmp/hivetest
步骤3:在MobaXterm的hive会话上:
hive> create table cga_info4(name string, gender string, time int) row format delimited fields terminated by ',' stored as textfile;
OK
Time taken: 0.049 seconds
hive> load data inpath '/tmp/hivetest/hive.txt' into table cga_info4;
Loading data to table default.cga_info4
OK
Time taken: 0.426 seconds
hive> select * from cga_info4;
OK
xiaozhao female 20
xiaoqian male 21
xiaosun male 25
xiaoli female 40
xiaozhou male 33
Time taken: 0.1 seconds, Fetched: 5 row(s)
创建表时,指定载入数据位置
重新上传文本文件到hdfs:
hdfs dfs -put hive.txt /tmp/hivetest
上面hive.txt也可写成/root/hive.txt,因为当前路径为/root。然后:
hive> create external table cga_info5(name string, gender string, time int) row format delimited fields terminated by ',' stored as textfile location '/tmp/hivetest';
OK
Time taken: 0.036 seconds
hive> select * from cga_info5;
OK
xiaozhao female 20
xiaoqian male 21
xiaosun male 25
xiaoli female 40
xiaozhou male 33
Time taken: 0.106 seconds, Fetched: 5 row(s)
复制一个空表
hive> create table cga_info6 like cga_info1;
OK
Time taken: 0.079 seconds
hive> select * from cga_info6;
OK
Time taken: 0.094 seconds
hive> desc cga_info6;
OK
name string
gender string
time int
Time taken: 0.033 seconds, Fetched: 3 row(s)
可见,复制一个空表,指的是复制一个表的模式(表头),内容不复制。
2.2 Hive表的查询
模糊查询
hive> show tables like '*cga*';
OK
cga_info1
cga_info2
cga_info3
cga_info4
cga_info5
cga_info6
Time taken: 0.02 seconds, Fetched: 6 row(s)
条件查询
限制查询的为前两行:
hive> select * from cga_info3 limit 2;
OK
xiaozhao female 20
xiaoqian male 21
Time taken: 0.088 seconds, Fetched: 2 row(s)
查询所有性别为女性的信息:
hive> select * from cga_info3 where gender='female';
OK
xiaozhao female 20
xiaoli female 40
Time taken: 0.377 seconds, Fetched: 2 row(s)
使用order 按时间递减顺序查询“cga_info3”中所有女性的信息:
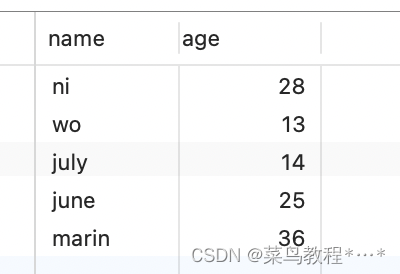
hive> select * from cga_info3 where gender='female' order by time desc;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20230107181909_c603e357-efc6-4a0c-8481-1dea83be1a6e
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1673053437829_0017, Tracking URL = http://cgznode-0001:8088/proxy/application_1673053437829_0017/
Kill Command = /home/modules/hadoop-2.8.3/bin/hadoop job -kill job_1673053437829_0017
【问题】执行到上述内容后,卡住不动了。我使用Ctrl+C,重新执行该复杂查询,仍然不起效果。上述查询表的操作,是我在部署了Hive组件后,紧接着执行的。
【解决方案】重新启动Hadoop集群(利用命令start-dfs.sh ; start-yarn.sh)。
具体出现该问题的原因,我不知道。但是,我们获得一个经验:部署好Hive组件后,应重启Hadoop集群。
重启集群后的运行效果:
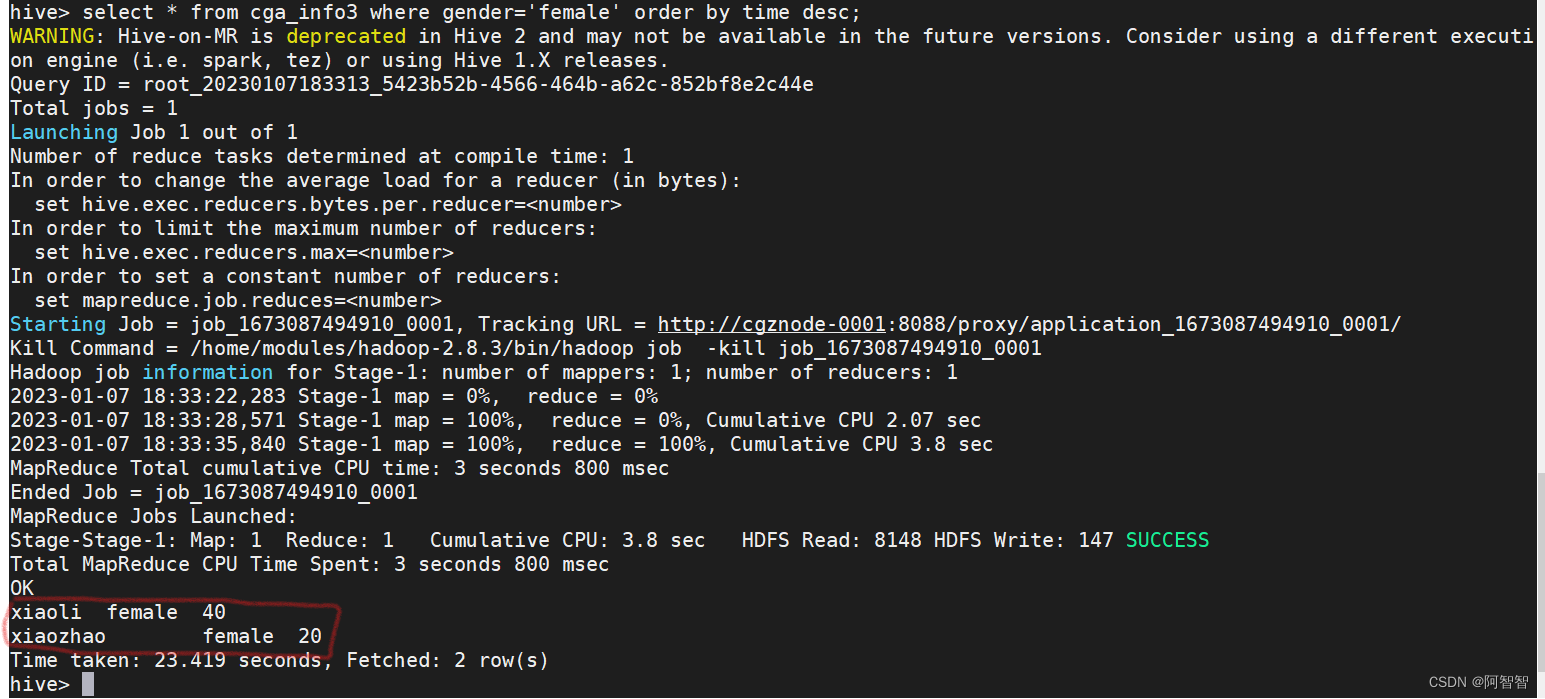
多条件查询
select name, sum(time) as all_time from cga_info3 group by name having all_time > 30;
结果截图:
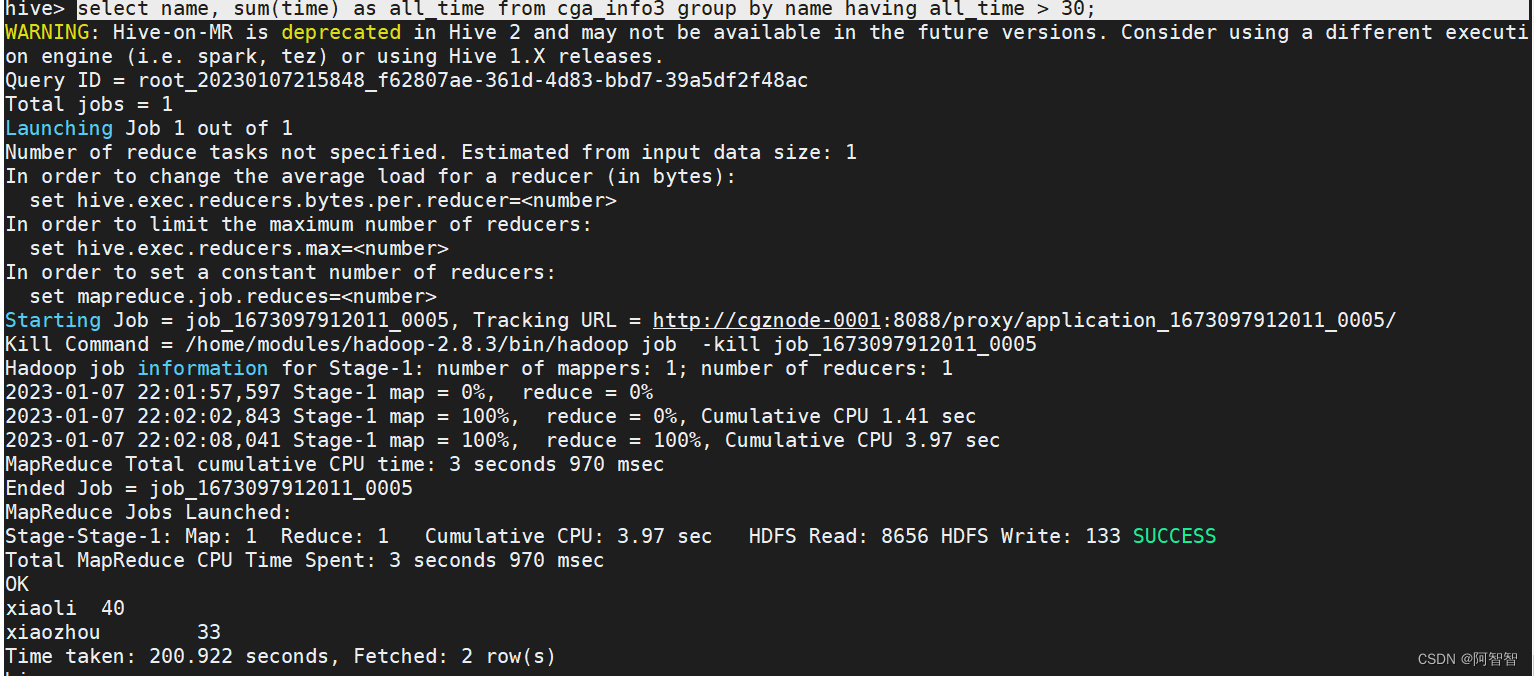
对表“cga_info3”进行查询,按性别分组,找出time 值最大的人:
select gender, max(time) from cga_info3 group by gender;
结果截图:
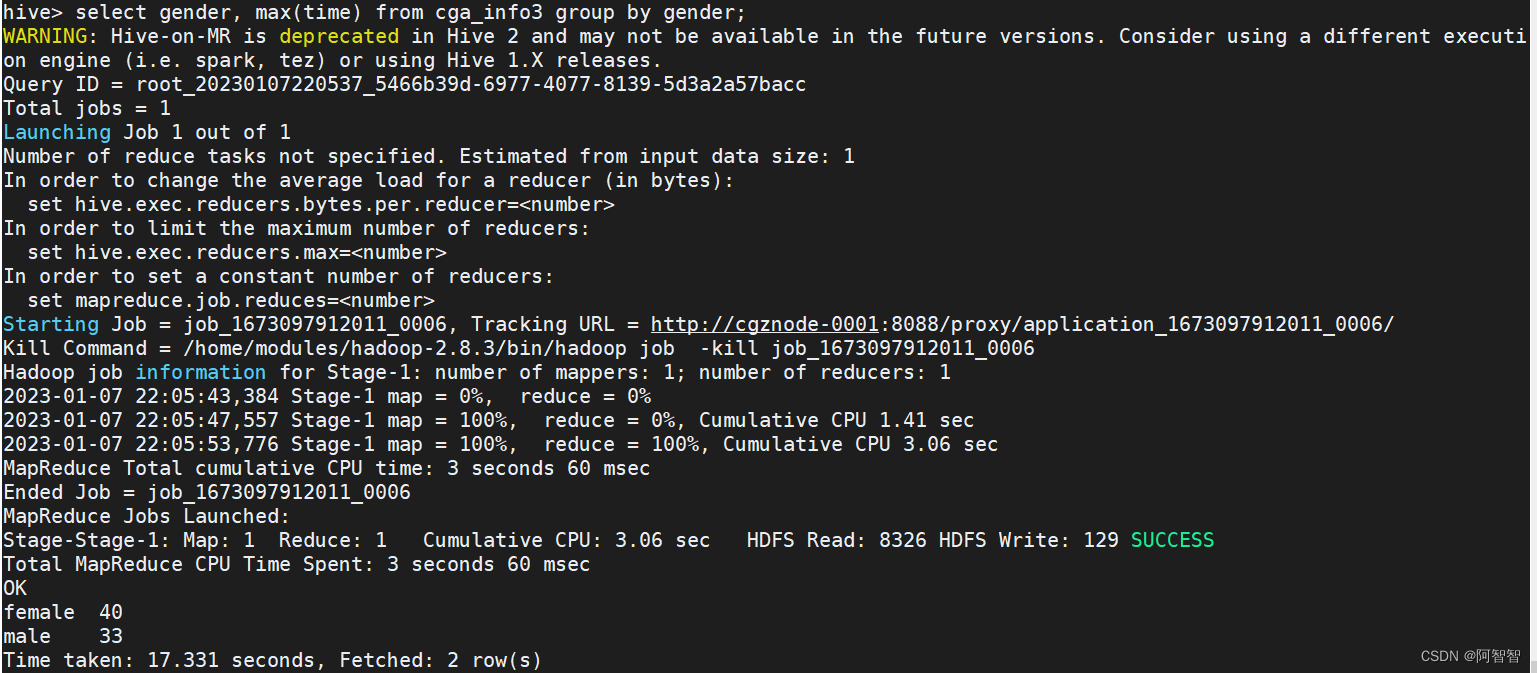
从上面的运行截图可以看出,本次查询运行时间为17.331秒,而上次的查询为200多秒(亦即出现了卡顿),那我是如下解决的呢?这次没有重启Hadoop集群。
【重复问题】执行到上述内容后,卡住不动了。我使用Ctrl+C,重新执行该复杂查询,仍然不起效果。上述查询表的操作,是我在部署了Hive组件后,紧接着执行的。
【终极解决方法】
将文件中/home/modules/hadoop-2.8.3/etc/hadoop/yarn-site.xml中的下面的value改为20480:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
<description>表示这个NodeManager 管理的内存大小</description>
</property>
然后重启Hadoop集群;重启msqld服务即可。
统计表“cga_info3”中,女性和男性的总数各是多少:
select gender, count(1) num from cga_info3 group by gender;
运行结果截图:
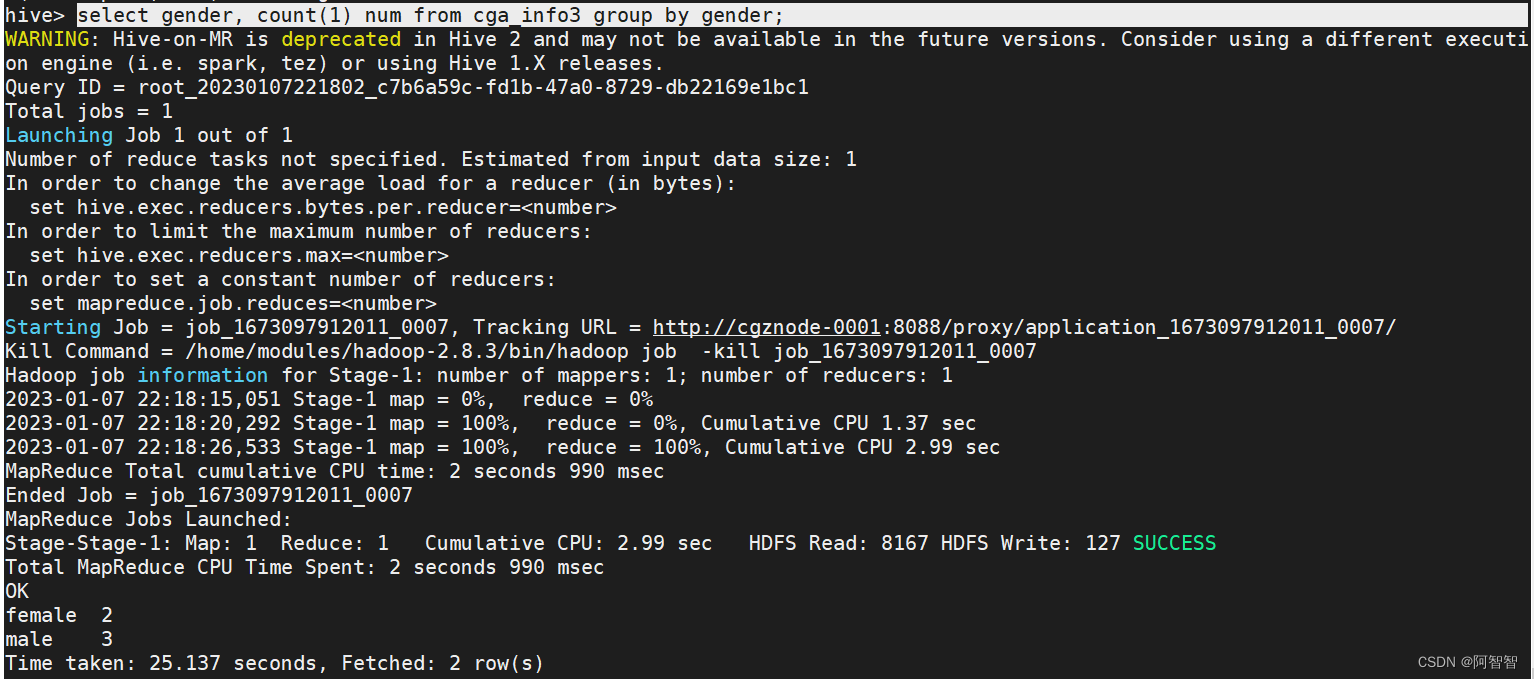
这一次执行用时为25.137秒,可以接受。
复杂条件查询
先在节点1的/root中创建本地文件:
vim hive2.txt
添加内容为:
xiaozhao,female,20
xiaochen,female,28
然后如下执行:
hive> create table cga_info7(name string,gender string,time int) row format delimited fields terminated by ',' stored as textfile;
OK
Time taken: 0.16 seconds
hive> load data local inpath '/root/hive2.txt' into table cga_info7;
Loading data to table default.cga_info7
OK
Time taken: 0.453 seconds
hive> select * from cga_info7;
OK
xiaozhao female 20
xiaochen female 28
Time taken: 0.106 seconds, Fetched: 2 row(s)
hive> insert into cga_info3 select * from cga_info7 where gender='female';
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20230107222441_d1e2bc08-3ebe-4938-bd74-79fce6d09a21
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1673097912011_0008, Tracking URL = http://cgznode-0001:8088/proxy/application_1673097912011_0008/
Kill Command = /home/modules/hadoop-2.8.3/bin/hadoop job -kill job_1673097912011_0008
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2023-01-07 22:24:45,898 Stage-1 map = 0%, reduce = 0%
2023-01-07 22:24:51,092 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.16 sec
MapReduce Total cumulative CPU time: 2 seconds 160 msec
Ended Job = job_1673097912011_0008
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to directory hdfs://cgznode-0001:8020/user/hive/warehouse/cga_info3/.hive-staging_hive_2023-01-07_22-24-41_113_2403847524838921190-1/-ext-10000
Loading data to table default.cga_info3
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 2.16 sec HDFS Read: 4484 HDFS Write: 111 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 160 msec
OK
Time taken: 11.399 seconds
hive> select * from cga_info3;
OK
xiaozhao female 20
xiaochen female 28
xiaozhao female 20
xiaoqian male 21
xiaosun male 25
xiaoli female 40
xiaozhou male 33
Time taken: 0.084 seconds, Fetched: 7 row(s)
hive>
按姓名和性别分组,查询表“cga_info3”中每个人time 值的总和:
hive> select name,gender,sum(time) as time from cga_info3 group by name, gender;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = root_20230107223117_cf7712c5-b5f9-4a3c-b0f3-4ba339ec49ff
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1673097912011_0009, Tracking URL = http://cgznode-0001:8088/proxy/application_1673097912011_0009/
Kill Command = /home/modules/hadoop-2.8.3/bin/hadoop job -kill job_1673097912011_0009
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2023-01-07 22:31:22,820 Stage-1 map = 0%, reduce = 0%
2023-01-07 22:31:28,006 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.41 sec
2023-01-07 22:31:32,150 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 3.03 sec
MapReduce Total cumulative CPU time: 3 seconds 30 msec
Ended Job = job_1673097912011_0009
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 3.03 sec HDFS Read: 8825 HDFS Write: 264 SUCCESS
Total MapReduce CPU Time Spent: 3 seconds 30 msec
OK
xiaochen female 28
xiaoli female 40
xiaoqian male 21
xiaosun male 25
xiaozhao female 40
xiaozhou male 33
Time taken: 16.0 seconds, Fetched: 6 row(s)
hive>
这次执行这个复杂查询只用了16秒,未出现卡顿现象。证明了我们【终极解决方法】的可行性。
3 总结
我们在操作过程中,会不断地对Linux的各种命令熟练,由刚开始的需要查找命令帮助到从脑中直接写出该命令。同时,也会达到这样状态,不去参考实验手册,利用Linux远程终端本身,加上自己熟悉的Linux命令,即能定位到相关的配置文件的存放位置。例如,经过我几次的ll,能定位到hadoop中的yarn-site.xml的位置:
/home/modules/hadoop-2.8.3/etc/hadoop/yarn-site.xml
我写上面路径的时候是直接写出的,没任何参考。这就是不断使用、熟练Linux系统的结果。当然,你也可以使用find命令、或者grep命令,也很方便。
我们还会发现,Hive的SQL语句与传统的SQL语句是非常相似的。例如:实验手册上这样的语句:
select name,gender,sum(time) time from cga_info3 group by name,gender;
根据我们对SQL语句的熟悉,上述Hive SQL是错误的。因为time作为sum(time)的别名,中间少了个as。应改为:
select name,gender,sum(time) as time from cga_info3 group by name,gender;
前面操作时,已改正。
所以,请大家享受学习的乐趣吧!