前言
视频embedding化也即表征有很多实际的应用场景,比如文本-视频 pair的检索等等。由于视频一般来说较长,所以对于给定的一段话,其中的某些sentence句子一般对应着视频中某几个clip片段,之前常规的做法都是去匹配所有的sentence-clip pairs对。
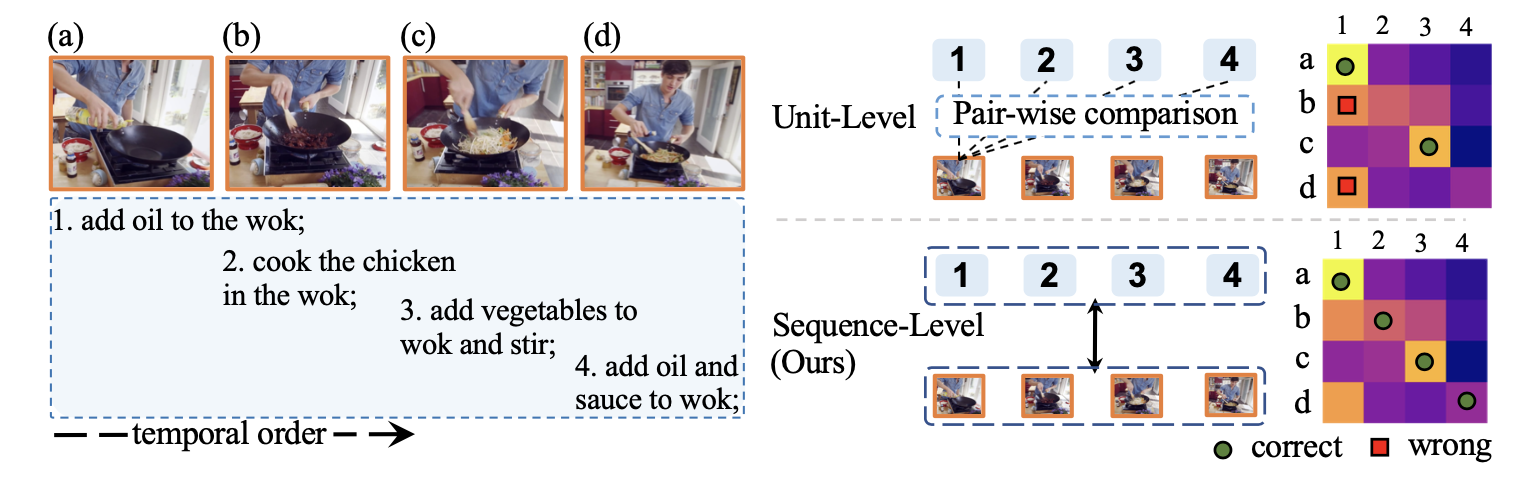
但是这种单元级别匹配的做法会天然的忽略掉全局的时间序列,这样就在一定程度上限制了泛化性,比如对于一些背景相似的视频,通常会出现一种匹配错误的情况(如下图(a)(b)在画面视觉上很相似,但是分别对应着文本(1)(2)),为此本文提出了一种序列对比学习用以解决这种问题。
如果有小伙伴对多模态方向有兴趣,可以选择性的翻看笔者之前的文章进行穿梭,比如:
《多模态预训练模型综述》:https://zhuanlan.zhihu.com/p/435697429
《第一个大规模中文视频多模态相似度数据集》:https://zhuanlan.zhihu.com/p/539833773
《多模态事件图谱》:https://zhuanlan.zhihu.com/p/530325352
《最新图文大一统多模态模型:FLAVA》:https://zhuanlan.zhihu.com/p/453581899
等等,感兴趣的小伙伴可以参考~
本次分享论文:https://arxiv.org/pdf/2212.13738.pdf
方法
-
任务定义
假设有一对样本(一段文本或者一个视频) ,由于文本或者视频通常来说比较长,网络比较难一次性提取表征,所以需要切片即 ,其中 就是 的第i个切片, 就是切片的总长度, 是表征后向量的维度;同理 的含义同上;在匹配的时候, 的某一个分片 可以对应 的连续几个分片 其中 是 对应 的那几个连续分片的开始和结束分片。
-
序列对比学习
对比学习,相信大家都不陌生,主要就是要找正负样本对,然后直接套用公式即可。
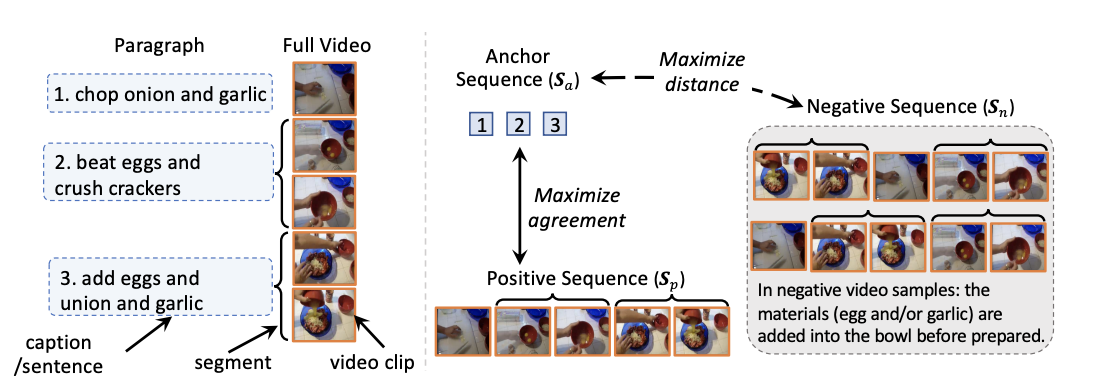
每一个Paragraph段落由多个sentence句子组成,每个句子对应一个视频segment,每个视频segment由多个视频clip分片组成。
假设有一个正样本对 ,其首先通过随机shuffle 乱 得到 ,这样就打破了 和 在时间序列上的一致性,同时为了考虑 segment-level 级别的匹配,所以作者在具体打乱的时候是先修改segment的顺序,然后再在每个egment中打乱各自的顺序。
在得到 后,就可以做对比学习了即S_{a}和 做对比学习:
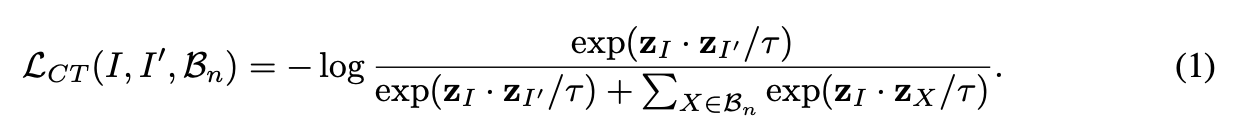
-
Sequence-level distance
为了更好的检索,作者这里借鉴了DTW(Dynamic Time Wrapping)算法,该算法可以计算两个时间序列的相似度,尤其适用于不同长度、不同节奏的时间序列。其本质上是一个动态规划问题(更细节的大家可以直接查询即可,很多资料):
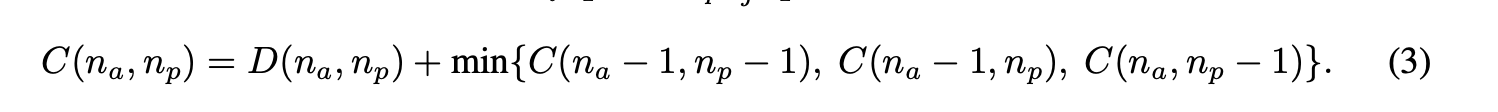
作者这里对应的设计了一个矩阵 ,首先 和 中至少得存在一个能够匹配上即 同时假设 和 匹配,那么 将不能和 中的任一个匹配也即 ;有了这个矩阵也即 ;最终两个序列的距离就是
同时作者还实验了DTW的一个变种算法OTAM。
实验
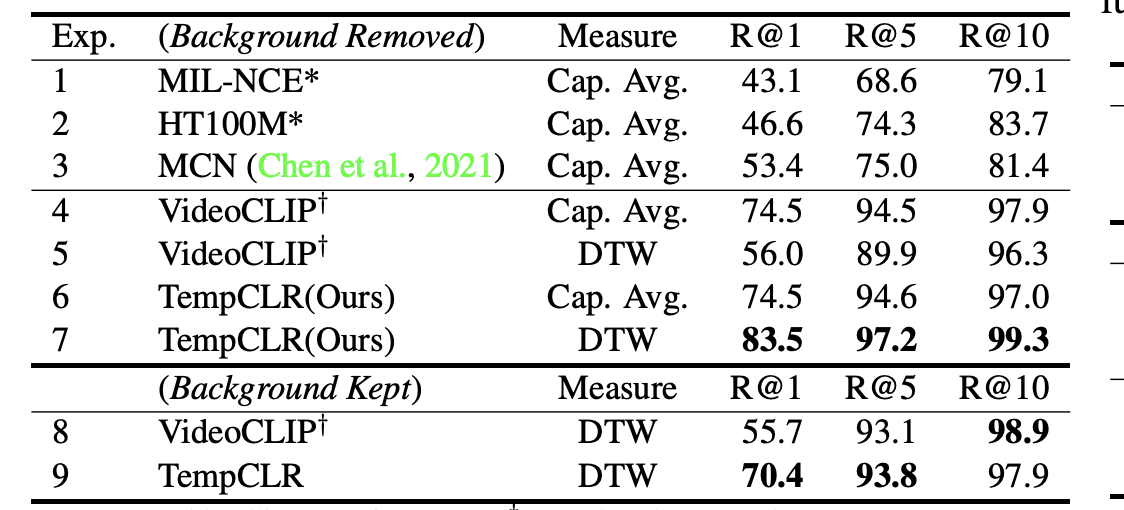
作者也进行了很多实验,这里贴一个检索任务的实验,可以看到相对于基线还是有一些提高的。
总结
大家可以学习一下怎么把序列信息应用到对比学习中以及了解一下DTW算法。
关注
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
本文由 mdnice 多平台发布