内容简介
本文介绍了群组分析(同期群分析)的方法以及Python实现过程,并继续对一家零售公司的交易数据进行用户留存分析和可视化。
本系列的文章:
- 《零售行业交易数据分析(1)——客户终身价值(CLTV)计算和回归预测模型》
- 《零售行业交易数据分析(2)——RFM模型分类及可视化(Python实现)》
一、什么是群组分析
群组分析,根据特征类型将样本分组,然后比较不同群组之间的差异和相同性。比如对于不同地域、年龄、性别的用户之间的相似特征、以及差异区别,方便使用者针对用户群的特征去设计和优化产品。
常见的分组类型有:
- 用户特征:地区、年龄、性别、职业等等。
- 用户类型/规模:根据用户的规模、大小来区分,比如企业用户/个人用户,VIP和非VIP。
- 产品/业务类型:不同的产品类型,业务类型。
- 行为:用户的行为划分,注册、购买、关注、分享等等。
同期群分析
其中,按时间维度,根据用户的行为特征来划分群组,是最常用的一个群组分析方法。
比如用户首次注册时间,将用户分成21年1月份注册的用户群,21年2月注册的用户群……以此类推,这种一时间维度来区分的,这种方式也称之为同期群分析(Cohort Analysis)。
在留存率分析中,同期群就是最广泛使用的方法之一。
二、代码实现过程
1)数据导入及清洗
import pandas as pd # for dataframes
import matplotlib.pyplot as plt # for plotting graphs
import seaborn as sns # for plotting graphs
import datetime as dt
import numpy as np
data=pd.read_excel('data.xlsx', parse_dates=['InvoiceDate'])
#剔除掉异常值
data = data[(data['Quantity']>0)&(data['UnitPrice']>0)]
#选择UK的数据
uk_data=data[data.Country=='United Kingdom']
#复制transaction_df,保留原数据不变
transaction_df=uk_data
transaction_df.head()

清洗详情见《零售行业交易数据分析(1)——客户终身价值(CLTV)计算和回归预测模型》
2)时间信息提取
1. 提取交易月份
首先定义一个函数过程,用于提取交易时间的年、月,并设定为初始日期为每月1号。然后提取每次交易时间的交易年月,作为新的一列transaction_df['TransactionMonth']
#定义函数
def get_month(x): return dt.datetime(x.year, x.month, 1)
#提取交易月份
transaction_df['TransactionMonth'] = transaction_df['InvoiceDate'].apply(get_month)
transaction_df.head()
2. 提取首次交易月份
找出每个用户的首次交易月份,作为同期群分组的特征标签transaction_df['CohortMonth']
#提取首次交易月份
transaction_df['CohortMonth']=transaction_df.groupby('CustomerID')['TransactionMonth'].transform('min')
代码过程分步解释:
#1. 先根据CustomerID对TransactionMonth分组
grouping = transaction_df.groupby('CustomerID')['TransactionMonth']
# 2. 使用Transform()返回一个与自身长度相同的数据
transaction_df['CohortMonth'] = grouping.transform('min')
##组合1和2步:
transaction_df['CohortMonth']=transaction_df.groupby('CustomerID')['TransactionMonth'].transform('min')
3. 计算月份差
分别计算相差年份和相差月份,然后合计总的月份差异, 等式transaction_df['CohortIndex'] = years_diff * 12 + months_diff + 1 最后加1,使首月标签为1而非0。
#定义提取年月日过程函数
def get_date_int(df, column):
year = df[column].dt.year
month = df[column].dt.month
day = df[column].dt.day
return year, month, day
# 提取交易月份的年、月
transcation_year, transaction_month, _ = get_date_int(transaction_df, 'TransactionMonth')
# 提取首次交易月份的年、月
cohort_year, cohort_month, _ = get_date_int(transaction_df, 'CohortMonth')
# 计算相差年份
# Get the difference in years
years_diff = transcation_year - cohort_year
# 计算相差月份
months_diff = transaction_month - cohort_month
# 计算总的月份差异
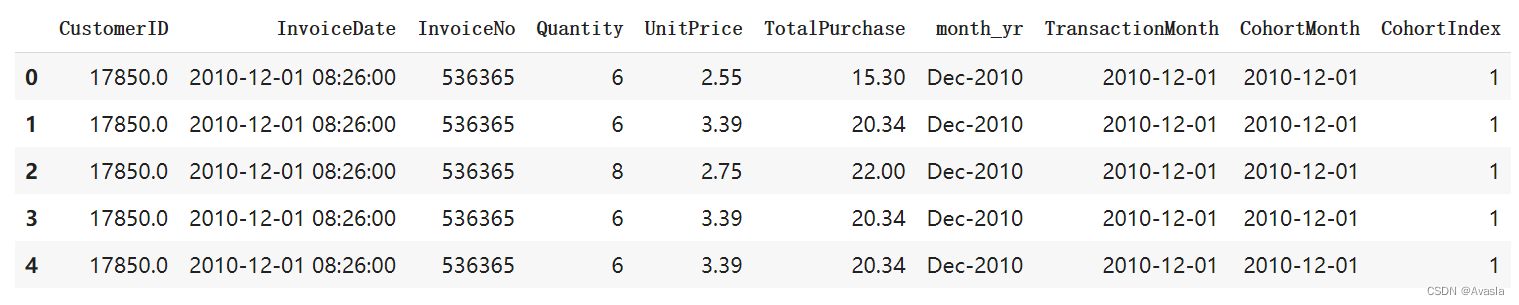
transaction_df['CohortIndex'] = years_diff * 12 + months_diff + 1
transaction_df.head(5)
4. 计算留存率
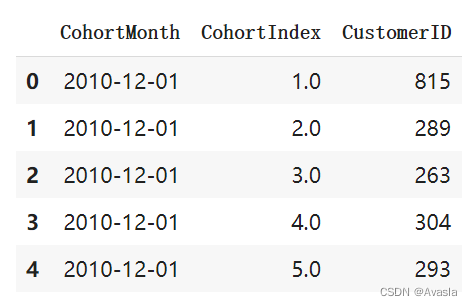
- 分组计算用户数量
# 按照'CohortMonth'和'CohortIndex'分组
grouping = transaction_df.groupby(['CohortMonth', 'CohortIndex'])
# 计算每个组里的唯一CustomerID数量
cohort_data = grouping['CustomerID'].apply(pd.Series.nunique)
#重新定义索引值
cohort_data = cohort_data.reset_index()
# 结果查看
cohort_data.head()
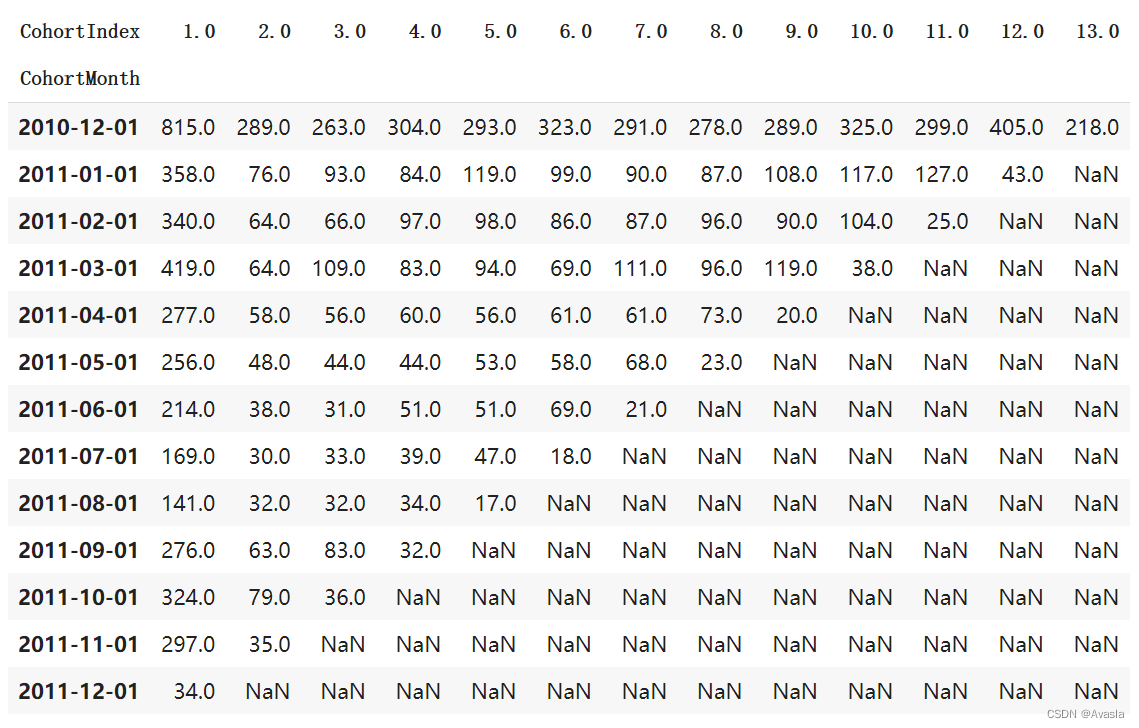
- 数据透视表查看每月留存用户数
cohort_counts = cohort_data.pivot(index='CohortMonth',columns ='CohortIndex',values = 'CustomerID')
- 留存率计算结果
#留存率计算
cohort_sizes = cohort_counts.iloc[:,0]
retention = cohort_counts.divide(cohort_sizes, axis=0)
#重新定义索引
retention.index = retention.index.strftime('%Y-%m')
#结果格式转换
retention.round(3)*100
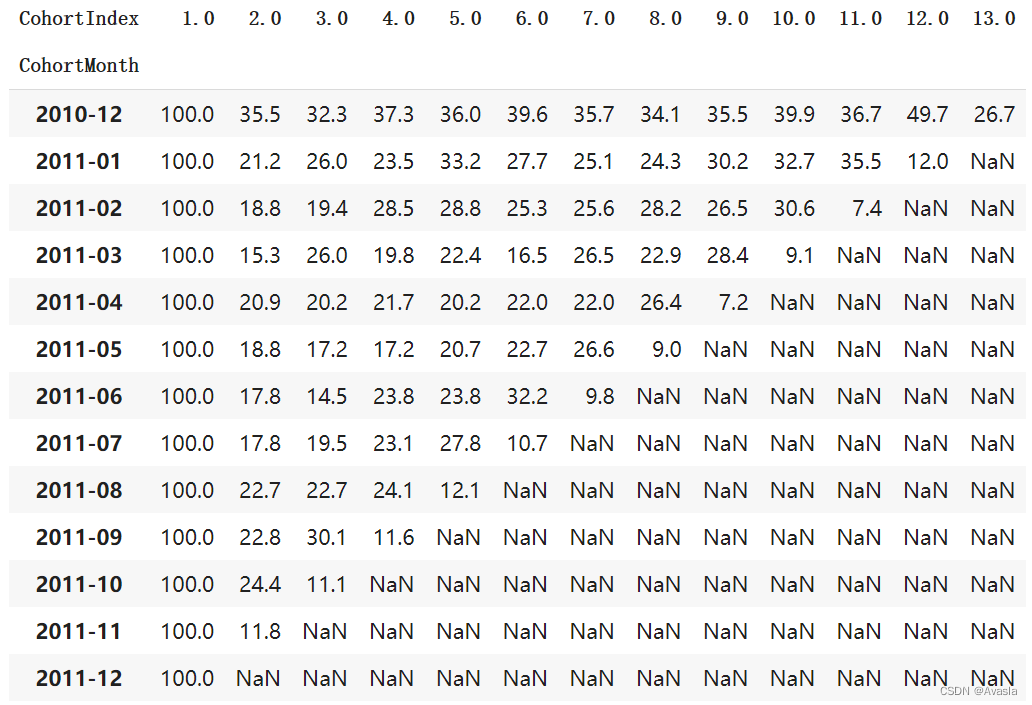
5. 热力图可视化
plt.figure(figsize=(16, 10))
plt.title('Retention Rate in percentage:- Monthly Cohorts', fontsize = 14)
sns.heatmap(retention, annot=True, fmt= '.0%',cmap='YlGnBu', vmin = 0.0 , vmax = 0.6)
plt.ylabel('Cohort Month')
plt.xlabel('Cohort Index')
plt.yticks( rotation='360')
plt.show()
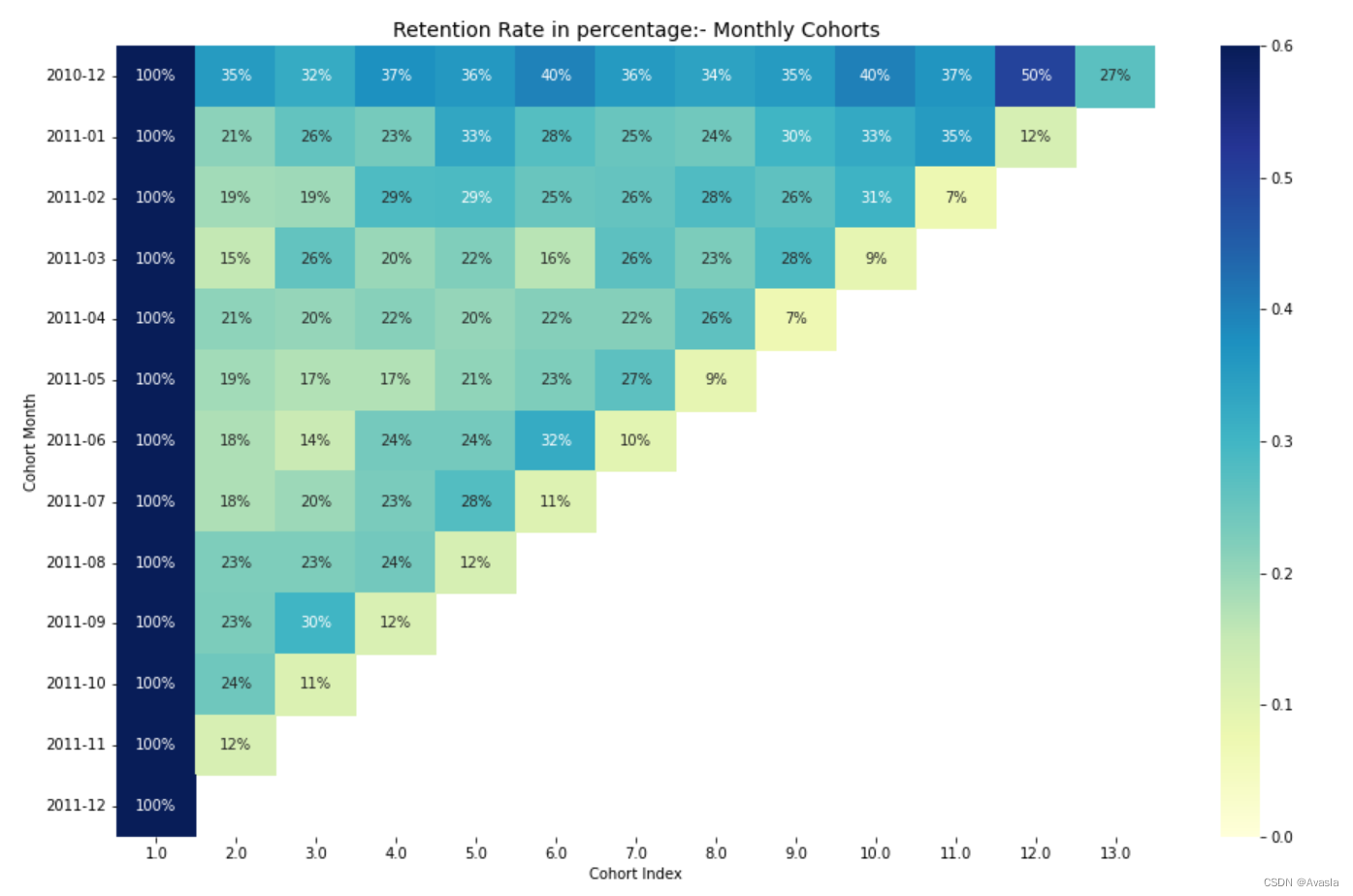
从热力图结果可见,商店最近8月-10月的留存率有所提高,纵向和横向分析都可见颜色有明显由浅变深;但是12月的留存率异常低,这是因为数据集的时间范围是 01/12/2010 到09/12/2011,12月份只有9天的数据,所以这个异常点也是可解释的。从整体上看, 该公司的用户留存数有所提高,近期召回了许多的老用户。
参考资料
参考文章: https://www.analyticsvidhya.com/blog/2021/06/cohort-analysis-using-python-for-beginners-a-hands-on-tutorial/
数据集:https://archive.ics.uci.edu/ml/datasets/Online+Retail#