DML操作表记录-增删改【重点】
-
准备工作: 创建一张商品表(商品id,商品名称,商品价格,商品数量.)
create table product(
pid int primary key auto_increment,
pname varchar(40),
price double,
num int
);1.1 插入记录
1.1.1 语法
-
方式一: 插入指定列, 如果没有把这个列进行列出来, 以null进行自动赋值了.
eg: 只想插入pname, price , insert into t_product(pname, price) values('mac',18000);
insert into 表名(列,列..) values(值,值..);注意: 如果没有插入了列设置了非空约束, 会报错的
-
方式二: 插入所有的列,如果哪列不想插入值,则需要赋值为null
insert into 表名 values(值,值....);
eg:
insert into product values(null,'苹果电脑',18000.0,10);
insert into product values(null,'华为5G手机',30000,20);
insert into product values(null,'小米手机',1800,30);
insert into product values(null,'iPhonex',8000,10);
insert into product values(null,'iPhone7',6000,200);
insert into product values(null,'iPhone6s',4000,1000);
insert into product values(null,'iPhone6',3500,100);
insert into product values(null,'iPhone5s',3000,100);
insert into product values(null,'方便面',4.5,1000);
insert into product values(null,'咖啡',11,200);
insert into product values(null,'矿泉水',3,500);1.2 更新记录
1.2.1语法
update 表名 set 列 =值, 列 =值 [where 条件]1.2.2练习
-
将所有商品的价格修改为5000元
update product set price = 5000;-
将商品名是苹果电脑的价格修改为18000元
UPDATE product set price = 18000 WHERE pname = '苹果电脑';-
将商品名是苹果电脑的价格修改为17000,数量修改为5
UPDATE product set price = 17000,num = 5 WHERE pname = '苹果电脑';-
将商品名是方便面的商品的价格在原有基础上增加2元
UPDATE product set price = price+2 WHERE pname = '方便面';1.3 删除记录
1.3.1 delete
根据条件,一条一条数据进行删除
-
语法
delete from 表名 [where 条件] 注意: 删除数据用delete,不用truncate-
类型
删除表中名称为’苹果电脑’的记录
delete from product where pname = '苹果电脑';删除价格小于5001的商品记录
delete from product where price < 5001;删除表中的所有记录
delete from product;1.3.2 truncate
把表直接DROP掉,然后再创建一个同样的新表。删除的数据不能找回。执行速度比DELETE快
truncate table 表;1.3.3 工作中删除数据
-
物理删除: 真正的删除了, 数据不在, 使用delete就属于物理删除
-
逻辑删除: 没有真正的删除, 数据还在. 搞一个标记, 其实逻辑删除是更新 eg: state 1 启用 0禁用
DQL操作表记录-查询【重点】
1.1 基本查询语法
select 要查询的字段名 from 表名 [where 条件] 1.2 简单查询
1.2.1 查询所有行和所有列的记录
-
语法
select * form 表-
查询商品表里面的所有的列
select * from product;1.2.2 查询某张表特定列的记录
-
语法
select 列名,列名,列名... from 表-
查询商品名字和价格
select pname, price from product;1.2.3 去重查询 distinct
-
语法
SELECT DISTINCT 字段名 FROM 表名; //要数据一模一样才能去重-
去重查询商品的名字
SELECT DISTINCT pname,price FROM product注意点: 去重针对某列, distinct前面不能先出现列名
1.2.4 别名查询
-
语法
select 列名 as 别名 ,列名 from 表 //列别名 as可以不写
select 别名.* from 表 as 别名 //表别名(多表查询, 明天会具体讲)-
查询商品信息,使用别名
SELECT pid ,pname AS '商品名',price AS '商品价格',num AS '商品库存' FROM product1.2.5 运算查询(+,-,*,/,%等)
-
把商品名,和商品价格+10查询出来:我们既可以将某个字段加上一个固定值,又可以对多个字段进行运算查询
select pname ,price+10 as price from product;
select name,chinese+math+english as total from student注意
运算查询字段,字段之间是可以的
字符串等类型可以做运算查询,但结果没有意义
1.3 条件查询(很重要)
1.3.1语法
select ... from 表 where 条件
//取出表中的每条数据,满足条件的记录就返回,不满足条件的记录不返回1.3.2 运算符
1、比较运算符
大于:> 小于:< 大于等于:>= 小于等于:<= 等于:= 不能用于null判断 不等于:!= 或 <> 安全等于: <=> 可以用于null值判断
2、逻辑运算符(建议用单词,可读性来说)
逻辑与:&& 或 and 逻辑或:|| 或 or 逻辑非:! 或 not 逻辑异或:^ 或 xor
3、范围
区间范围:between x and y
not between x and y
集合范围:in (x,x,x)
not in (x,x,x)
4、模糊查询和正则匹配(只针对字符串类型,日期类型)
like 'xxx' 模糊查询是处理字符串的时候进行部分匹配 如果想要表示0~n个字符,用% 如果想要表示确定的1个字符,用_regexp '正则'
5、特殊的null值处理
#(1)判断时 xx is null xx is not null xx <=> null
1.3.3 练习
-
查询商品价格>3000的商品
select * from product where price > 3000;-
查询pid=1的商品
select * from product where pid = 1;-
查询pid<>1的商品
select * from product where pid <> 1;-
查询价格在3000到6000之间的商品
select * from product where price between 3000 and 6000;-
查询pid在1,5,7,15范围内的商品
select * from product where id = 1;
select * from product where id = 5;
select * from product where id = 7;
select * from product where id = 15;
select * from product where id in (1,5,7,15);-
查询商品名以iPho开头的商品(iPhone系列)
select * from product where pname like 'iPho%';-
查询商品价格大于3000并且数量大于20的商品 (条件 and 条件 and...)
select * from product where price > 3000 and num > 20;-
查询id=1或者价格小于3000的商品
select * from product where pid = 1 or price < 3000;1.4 排序查询
排序是写在查询的后面,代表把数据查询出来之后再排序
1.4.1 环境的准备
# 创建学生表(有sid,学生姓名,学生性别,学生年龄,分数列,其中sid为主键自动增长)
CREATE TABLE student(
sid INT PRIMARY KEY auto_increment,
sname VARCHAR(40),
sex VARCHAR(10),
age INT,
score DOUBLE
);
INSERT INTO student VALUES(null,'zs','男',18,98.5);
INSERT INTO student VALUES(null,'ls','女',18,96.5);
INSERT INTO student VALUES(null,'ww','男',15,50.5);
INSERT INTO student VALUES(null,'zl','女',20,98.5);
INSERT INTO student VALUES(null,'tq','男',18,60.5);
INSERT INTO student VALUES(null,'wb','男',38,98.5);
INSERT INTO student VALUES(null,'小丽','男',18,100);
INSERT INTO student VALUES(null,'小红','女',28,28);
INSERT INTO student VALUES(null,'小强','男',21,95);1.4.2 单列排序
-
语法: 只按某一个字段进行排序,单列排序
SELECT 字段名 FROM 表名 [WHERE 条件] ORDER BY 字段名 [ASC|DESC];
//ASC: 升序,默认值; DESC: 降序-
练习: 以分数降序查询所有的学生
SELECT * FROM student ORDER BY score DESC1.4.3 组合排序
-
语法: 同时对多个字段进行排序,如果第1个字段相等,则按第2个字段排序,依次类推
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名1 [ASC|DESC], 字段名2 [ASC|DESC];-
练习: 以分数降序查询所有的学生, 如果分数一致,再以age降序
SELECT * FROM student ORDER BY score DESC, age DESC1.5 聚合函数
聚合函数通常会和分组查询一起使用,用于统计每组的数据
1.5.1 聚合函数列表
| 聚合函数 | 作用 |
|---|---|
| max(列名) | 求这一列的最大值 |
| min(列名) | 求这一列的最小值 |
| avg(列名) | 求这一列的平均值 |
| count(列名) | 统计这一列有多少条记录 |
| sum(列名) | 对这一列求总和 |
-
语法
SELECT 聚合函数(列名) FROM 表名 [where 条件];-
练习
-- 求出学生表里面的最高分数
SELECT MAX(score) FROM student
-- 求出学生表里面的最低分数
SELECT MIN(score) FROM student
-- 求出学生表里面的分数的总和(忽略null值)
SELECT SUM(score) FROM student
-- 求出学生表里面的平均分
SELECT AVG(score) FROM student
-- 统计学生的总人数 (忽略null)
SELECT COUNT(sid) FROM student
SELECT COUNT(*) FROM student注意: 聚合函数会忽略空值NULL
我们发现对于NULL的记录不会统计,建议如果统计个数则不要使用有可能为null的列,但如果需要把NULL也统计进去呢?我们可以通过 IFNULL(列名,默认值) 函数来解决这个问题. 如果列不为空,返回这列的值。如果为NULL,则返回默认值。
SELECT AVG(IFNULL(score,0)) FROM student;1.6 分组查询
GROUP BY将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用
1.6.1分组
-
语法
SELECT 字段1,字段2... FROM 表名 [where 条件] GROUP BY 列 [HAVING 条件];-
练习:根据性别分组, 统计每一组学生的总人数
-- 根据性别分组, 统计每一组学生的总人数
SELECT sex '性别',COUNT(sid) '总人数' FROM student GROUP BY sex
-- 根据性别分组,统计每组学生的平均分
SELECT sex '性别',AVG(score) '平均分' FROM student GROUP BY sex
-- 根据性别分组,统计每组学生的总分
SELECT sex '性别',SUM(score) '总分' FROM student GROUP BY sex1.6.2 分组后筛选 having
-
练习根据性别分组, 统计每一组学生的总人数> 5的(分组后筛选)
SELECT sex, count(*) FROM student GROUP BY sex HAVING count(*) > 5-
练习根据性别分组,只统计年龄大于等于18的,并且要求组里的人数大于4
SELECT sex '性别',COUNT(sid) '总人数'
FROM student WHERE age >= 18
GROUP BY sex HAVING COUNT(sid) > 41.6.3 where和having的区别【面试】
| 子名 | 作用 |
|---|---|
| where 子句 | 1) 对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,即先过滤再分组。2) where后面不可以使用聚合函数 |
| having字句 | 1) having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。2) having后面可以使用聚合函数 |
1.7 分页查询
1.7.1 语法
select ... from .... limit a ,b| LIMIT a,b; |
|---|
| a 表示的是跳过的数据条数 |
| b 表示的是要查询的数据条数 |
1.7.2 练习
-- 分页查询
-- limit 关键字是使用在查询的后边,如果有排序的话则使用在排序的后边
-- limit的语法: limit offset,length 其中offset表示跳过多少条数据,length表示查询多少条数据
SELECT * FROM product LIMIT 0,3
-- 查询product表中的前三条数据(0表示跳过0条,3表示查询3条)
SELECT * FROM product LIMIT 3,3
-- 查询product表的第四到六条数据(3表示跳过3条,3表示查询3条)
-- 分页的时候,只会告诉你我需要第几页的数据,并且每页有多少条数据
-- 假如,每页需要3条数据,我想要第一页数据: limit 0,3
-- 假如,每页需要3条数据,我想要第二页数据: limit 3,3
-- 假如,每页需要3条数据,我想要第三页数据: limit 6,3
-- 结论: length = 每页的数据条数,offset = (当前页数 - 1)*每页数据条数
-- limit (当前页数 - 1)*每页数据条数, 每页数据条数1.8 查询的语法小结
select...from...where...group by...order by...limit
select...from...where...
select...from...where...order by...
select...from...where...limit...
select...from...where...order by...imit二 导入和导出数据(了解)
2.1 单个数据库备份
mysql5.5
C:\Windows\System32> mysqldump -h主机地址 -P端口号 -u用户名 -p密码 --database 数据库名 > 文件路径/文件名.sql例如:
C:\Windows\System32>mysqldump -hlocalhost -P3306 -uroot -p123456 --database test > d:/test.sql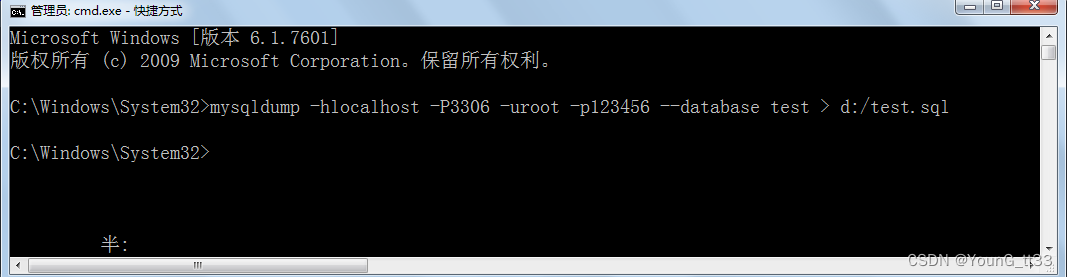
mysql5.7版
C:\Windows\System32> mysqldump -h主机地址 -P端口号 -u用户名 -p密码 数据名 > 文件路径/文件名.sql不要再写--database
2.2 导入执行备份的sql脚本
先登录mysql,然后执行如下命令:
mysql> source sql脚本路径名.sql例如:
mysql>source d:/test.sql;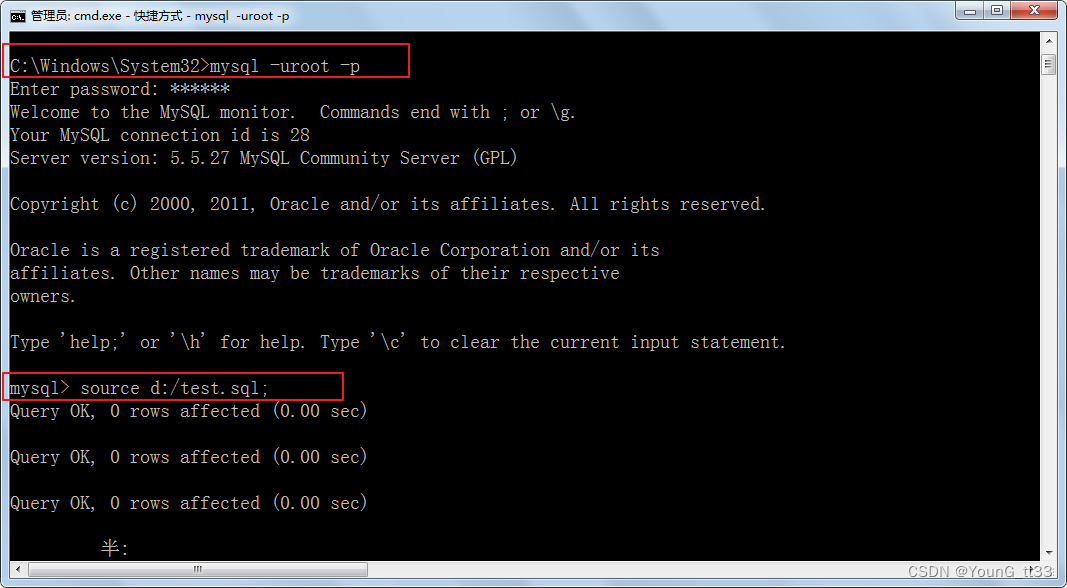
上述操作比较麻烦,且不常用
Navicat可视化sql软件内
备份数据库: 选择当前数据库右键 ---> 转储为sql文件
读取数据库: 选择当前连接右键 ---> 运行sql文件
-- 操作MySQL服务器需要使用MySQL的命令语句(SQL语句)操作
# 这也是注释
/*
多行注释
*/
-- 第一章: 操作数据库的DDL
-- 1. 创建数据库
-- 创建一个名字为day01的数据库,使用默认的字符集和校对规则
CREATE DATABASE day01;
-- 创建一个名字为day01_2的数据库,并且使用字符集为gbk
CREATE DATABASE day01_2 CHARACTER SET gbk;
-- 我们也可以使用可视化工具直接创建数据库
-- 2. 删除数据库
DROP DATABASE day01_3;
-- 3. 查询整个MYSQL服务器中的所有数据库
SHOW DATABASES;
-- 4. 查看某个数据库的结构
SHOW CREATE DATABASE day01_2;
-- 一般情况下创建数据库,指定字符集为UTF8,校对规则为UTF8默认的校对规则
-- 5. 修改某个数据库的字符集
ALTER DATABASE day01 CHARACTER SET UTF8;
-- 6. 指定使用哪个数据库
-- 因为我们以后要建表、操作表,需要先指定是操作哪个数据库中的表
USE day01;
-- 7. 查看当前正在使用哪个数据库
SELECT DATABASE();
-- 第二章: 操作表的DDL
-- 1. 创建表
-- 创建一张学生表(含有id字段,姓名字段不能重复,性别字段不能为空. id为主键自动增长)
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键自增长
NAME VARCHAR(30) UNIQUE, -- 唯一约束
gender CHAR(1) NOT NULL
);
-- 字段的类型: timestamp 表示时间戳为了解决时差问题而产生的
-- 2. 查看某个数据库中的所有表
SHOW TABLES;
-- 3. 查看某张表的结构
DESC student;
-- 4. 修改表结构的SQL语句
-- 4.1 添加一个字段
-- 给学生表增加一个grade字段,类型为varchar(20),不能为空
ALTER TABLE student ADD grade VARCHAR(20) NOT NULL;
-- 4.2 修改某个字段的类型和约束
-- 给学生表的gender字段改成int类型,不能为空,默认值为1
ALTER TABLE student MODIFY gender INT NOT NULL DEFAULT 1;
-- 4.3 修改某个字段的名字
-- 给学生表的grade字段修改成class字段
ALTER TABLE student CHANGE grade class VARCHAR(20) NOT NULL;
-- 4.4 删除某个字段
-- 把class字段删除
ALTER TABLE student DROP class;
-- 4.5 修改表的名字
-- 把学生表修改成老师表(了解)
RENAME TABLE student TO teacher;
-- 5. 删除表
DROP TABLE teacher;
-- 第三章: DML操作数据的增删改
-- 准备工作
CREATE TABLE product(
pid INT PRIMARY KEY AUTO_INCREMENT,
pname VARCHAR(40),
price DOUBLE,
num INT
);
-- 插入测试数据
insert into product values(null,'苹果电脑',18000.0,10);
insert into product values(null,'华为5G手机',30000,20);
insert into product values(null,'小米手机',1800,30);
insert into product values(null,'iPhonex',8000,10);
insert into product values(null,'iPhone7',6000,200);
insert into product values(null,'iPhone6s',4000,1000);
insert into product values(null,'iPhone6',3500,100);
insert into product values(null,'iPhone5s',3000,100);
insert into product values(null,'方便面',4.5,1000);
insert into product values(null,'咖啡',11,200);
insert into product values(null,'矿泉水',3,500);
-- 1. 往商品表中插入数据
-- 1.1 第一种形式: 指定插入哪些列的数据,没有指定的列那个就插入null
INSERT INTO product (pname,price,num) VALUES ('华为手机',6980.0,1500);
-- 1.2 第二种形式: 不指定插入哪些列的数据,也就是说要对所有列都插入数据,就算某一列你不想插入数据,也要写null
INSERT INTO product VALUES (NULL,'苹果手机',8999.0,2000)
-- 2. 更新数据
-- update 表名 set 字段名=新值,字段名=新值 where 条件
-- 如果没有修改条件的话,那么会将整张表的该字段的值都改掉
-- 2.1 将所有商品的价格修改为5000元
UPDATE product SET price=5000;
-- 2.2 将商品名是苹果电脑的价格修改为18000元
UPDATE product SET price=18000 WHERE pname='苹果电脑';
-- 2.3 将商品名是苹果电脑的价格修改为17000,数量修改为5
UPDATE product SET price=17000,num=5 WHERE pname='苹果电脑';
-- 2.4 将商品名是方便面的商品的价格在原有基础上增加2元
UPDATE product SET price=price+2 WHERE pname='方便面';
-- 3. 删除数据
-- 3.1 delete根据条件进行删除
-- delete from 表名 where 条件
-- 删除表中名称为’苹果电脑’的记录
DELETE FROM product WHERE pname='苹果电脑';
-- 删除价格小于5001的商品记录
DELETE FROM product WHERE price < 5001;
-- 删除所有数据,就是不加条件
DELETE FROM product;
-- 3.2 要删除所有数据,不太建议使用delete语句进行删除,因为delete语句是根据条件一行一行删除
-- truncate进行删除,将整张表整体干掉,然后自动创建一张结构一模一样的新表
TRUNCATE TABLE product;
-- 实际工作中怎么删除数据? 采用逻辑删除
-- 第四章: 数据查询
-- 1. 查询所有行和所有列的数据
-- select 要查询哪些列 from 表名 where 条件
SELECT * FROM product
-- 2. 查询指定列的数据, select 和 from之间写的就是要查询的列名,列名之间使用逗号分隔
SELECT pid,pname,price,num FROM product
-- 3. 去重查询: 在查询结果中去掉重复的数据,使用关键字distinct
-- select distinct 要查询的字段 from 表名 where 条件
SELECT DISTINCT pname,price FROM product
-- 4. 别名查询: 给查询的字段或者表进行别名设置
-- 给字段取别名的时候,最好使用'别名'
-- 语法: 列名 as 别名,当然as可以省略
SELECT pid ,pname AS '商品名',price AS '商品价格',num AS '商品库存' FROM product
-- 5. 运算查询
SELECT pid,pname,price + 10 'price',num FROM product
-- 6. 条件查询
-- 6.1 查询商品价格>3000的商品
SELECT * FROM product WHERE price > 3000;
-- 6.2 查询pid=1的商品
SELECT * FROM product WHERE pid=1;
-- 6.3 查询pid<>1的商品
SELECT * FROM product WHERE pid<>1;
-- 6.4 查询价格在3000到6000之间的商品
SELECT * FROM product WHERE price BETWEEN 3000 AND 6000;
-- 6.5 查询pid在1,5,7,15范围内的商品
SELECT * FROM product WHERE pid IN (1,5,7,15);
-- 6.6 查询商品名以iPho开头的商品(iPhone系列) like模糊查询
SELECT * FROM product WHERE pname LIKE 'Ipho%';
-- 6.7. 查询商品价格大于3000并且数量大于20的商品 (条件 and 条件 and...)
SELECT * FROM product WHERE price > 3000 AND num > 20;
-- 6.8 查询id=1或者价格小于3000的商品
SELECT * FROM product WHERE pid=1 OR price < 3000;
-- 7. 排序查询
-- 升序 asc(默认) , 降序 desc
-- 7.1 单列排序, 按照某一列进行排序
-- 以分数降序查询所有的学生
SELECT * FROM student ORDER BY score DESC;
-- 7.2多列排序
-- 先按照第一个字段进行排序,如果第一个字段相同,那么就按照第二个字段进行排序
-- 以分数降序查询所有的学生, 如果分数一致,再以age降序
SELECT * FROM student ORDER BY score DESC,age DESC;
-- 8. 聚合函数: 用于统计的,通常和分组查询一起使用,用于统计每组的数据
-- 8.1 max函数,查询最大值
-- 求出学生表里面的最高分数
SELECT MAX(score) FROM student;
-- 8.2 min函数,查询最小值
-- 求出学生表里面的最低分数
SELECT MIN(score) FROM student;
-- 8.3 avg函数,查询平均值
-- 求出学生表里面的平均分 -- 如果该字段为null,则不会将其加入到计算平均值
SELECT AVG(score) FROM student;
-- 如果我的想法是你缺考了就当成0分处理
SELECT AVG(IFNULL(score,0)) FROM student;
-- 8.4 count函数,统计数据条数
-- 统计学生总数
SELECT COUNT(sid) FROM student
-- 8.5 sum函数,求和
-- 求出学生表里面的分数的总和(忽略null值)
SELECT SUM(score) FROM student;
-- 9. 分组查询:分组的目的是为了做统计,所以要结合聚合函数一起使用
-- 语法: group by 用于分组的字段
-- 根据性别分组, 统计每一组学生的总人数
SELECT sex '性别',COUNT(sid) '总人数' FROM student GROUP BY sex
-- 根据性别分组,统计每组学生的平均分
SELECT sex '性别',AVG(score) '平均分' FROM student GROUP BY sex
-- 根据性别分组,统计每组学生的总分
SELECT sex '性别',SUM(score) '总分' FROM student GROUP BY sex
-- 10. 分组后的筛选
-- 分组后的条件,不能卸载where之后,where关键字要写在group by之前
-- 练习根据性别分组, 统计每一组学生的总人数> 5的(分组后筛选)
SELECT sex '性别',COUNT(sid) '总人数' FROM student GROUP BY sex HAVING COUNT(sid)>5
-- 练习根据性别分组,只统计年龄大于等于18的,并且要求组里的人数大于4
SELECT sex '性别',COUNT(sid) '总人数' FROM student WHERE age >= 18 GROUP BY sex HAVING COUNT(sid) > 4

![LeetCode[剑指offer 40]最小的k个数](https://img-blog.csdnimg.cn/img_convert/fc4126d762ee9f82d66a93b9b722ad6a.png)





![【系列01】java运算符及运算符优先级[附带目录 按需服用]](https://img-blog.csdnimg.cn/9dd9dbad81184af6a8f191f7ee27e8eb.png)