当你创建了成千上万个特征后,就该从中挑选出⼏个了。但是,我们绝不应该创建成百上千个⽆⽤的特征。特征过多会带来⼀个众所周知的问题,即 "维度诅咒"。如果你有很多特征,你也必须有很多训练样本来捕捉所有特征。什么是 "⼤量 "并没有正确的定义,这需要您通过正确验证您的模型和检查训练模型所需的时间来确定。
选择特征的最简单⽅法是
删除⽅差⾮常⼩的特征
。如果特征的⽅差⾮常⼩(即⾮常接近于 0),它们就接近于常量,因此根本不会给任何模型增加任何价值。最好的办法就是去掉它们,从⽽降低复杂度。请注意,⽅差也取决于数据的缩放。 Scikit-learn 的 VarianceThreshold 实现了这⼀点。
from sklearn.feature_selection import VarianceThreshold
data = .
var_thresh = VarianceThreshold(threshold=0.1)
transformed_data = var_thresh.fit_transform(data)
我们还可以删除相关性较⾼的特征。要计算不同数字特征之间的相关性,可以使⽤⽪尔逊相关性。
import pandas as pd
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]
df = pd.DataFrame(X, columns=col_names)
df.loc[:, "MedInc_Sqrt"] = df.MedInc.apply(np.sqrt)
df.corr()得出相关矩阵,如图 1 所⽰。
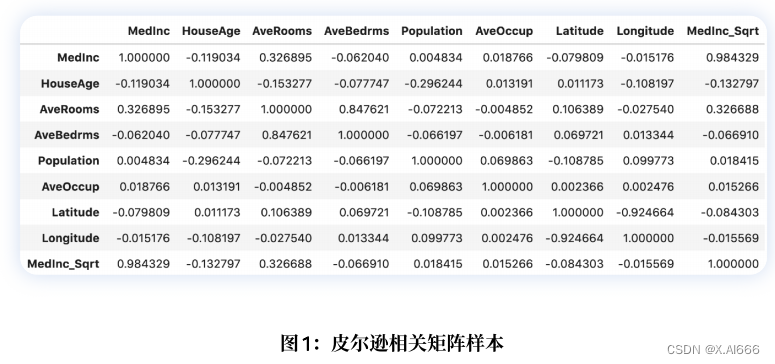
我们看到,MedInc_Sqrt 与 MedInc 的相关性⾮常⾼。因此,我们可以删除其中⼀个特征。
现在我们可以转向⼀些
单变量特征选择⽅法
。单变量特征选择只不过是针对给定⽬标对每个特征进⾏评分。
互信息
、
⽅差分析
F
检验和
chi2
是⼀些最常⽤的单变量特征选择⽅法。在 scikit-learn 中,有两种⽅法可以使⽤这些⽅法。
SelectKBest:保留得分最⾼的 k 个特征
SelectPercentile:保留⽤⼾指定百分⽐内的顶级特征。
必须注意的是,只有⾮负数据才能使⽤ chi2。在⾃然语⾔处理中,当我们有⼀些单词或基于 tf-idf 的特征时,这是⼀种特别有⽤的特征选择技术。最好为单变量特征选择创建⼀个包装器,⼏乎可以⽤于任何新问题。
from sklearn.feature_selection import chi2
from sklearn.feature_selection import f_classif
from sklearn.feature_selection import f_regression
from sklearn.feature_selection import mutual_info_classif
from sklearn.feature_selection import mutual_info_regression
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import SelectPercentile
class UnivariateFeatureSelction:
def __init__(self, n_features, problem_type, scoring):
if problem_type == "classification":
valid_scoring = {
"f_classif": f_classif,
"chi2": chi2,
"mutual_info_classif": mutual_info_classif
}
else:
valid_scoring = {
"f_regression": f_regression,
"mutual_info_regression": mutual_info_regression
}
if scoring not in valid_scoring:
raise Exception("Invalid scoring function")
if isinstance(n_features, int):
self.selection = SelectKBest(
valid_scoring[scoring],
k=n_features
)
elif isinstance(n_features, float):
self.selection = SelectPercentile(
valid_scoring[scoring],
percentile=int(n_features * 100)
)
else:
raise Exception("Invalid type of feature")
def fit(self, X, y):
return self.selection.fit(X, y)
def transform(self, X):
return self.selection.transform(X)
def fit_transform(self, X, y):
return self.selection.fit_transform(X, y)
使⽤该类⾮常简单。
# Example usage:
ufs = UnivariateFeatureSelction(
n_features=0.1,
problem_type="regression",
scoring="f_regression"
)
ufs.fit(X, y)
X_transformed = ufs.transform(X)
这样就能满⾜⼤部分单变量特征选择的需求。请注意,创建较少⽽重要的特征通常⽐创建数以百计的特征要好。单变量特征选择不⼀定总是表现良好。⼤多数情况下,⼈们更喜欢使⽤机器学习模型进⾏特征选择。让我们来看看如何做到这⼀点。
使⽤模型进⾏特征选择的最简单形式被称为贪婪特征选择。在贪婪特征选择中,第⼀步是选择⼀个模型。第⼆步是选择损失/评分函数。第三步也是最后⼀步是反复评估每个特征,如果能提⾼损失/评分,就将其添加到 "好 "特征列表中。没有⽐这更简单的了。但你必须记住,这被称为贪婪特征选择是有原因的。这种特征选择过程在每次评估特征时都会适合给定的模型。这种⽅法的计算成本⾮常⾼。完成这种特征选择也需要⼤量时间。如果不正确使⽤这种特征选择,甚⾄会导致模型过度拟合。让我们来看看它是如何实现的。
import pandas as pd
from sklearn import linear_model
from sklearn import metrics
from sklearn.datasets import make_classification
class GreedyFeatureSelection:
def evaluate_score(self, X, y):
model = linear_model.LogisticRegression()
model.fit(X, y)
predictions = model.predict_proba(X)[:, 1]
auc = metrics.roc_auc_score(y, predictions)
return auc
def _feature_selection(self, X, y):
good_features = []
best_scores = []
num_features = X.shape[1]
while True:
this_feature = None
best_score = 0
for feature in range(num_features):
if feature in good_features:
continue
selected_features = good_features + [feature]
xtrain = X[:, selected_features]
score = self.evaluate_score(xtrain, y)
if score > best_score:
this_feature = feature
best_score = score
if this_feature is None:
break
good_features.append(this_feature)
best_scores.append(best_score)
if len(best_scores) > 1:
if best_scores[-1] < best_scores[-2]:
break
return best_scores[:-1], good_features[:-1]
def __call__(self, X, y):
scores, features = self._feature_selection(X, y)
return X[:, features], scores
if __name__ == "__main__":
X, y = make_classification(n_samples=1000, n_features=100)
X_transformed, scores = GreedyFeatureSelection()(X, y)
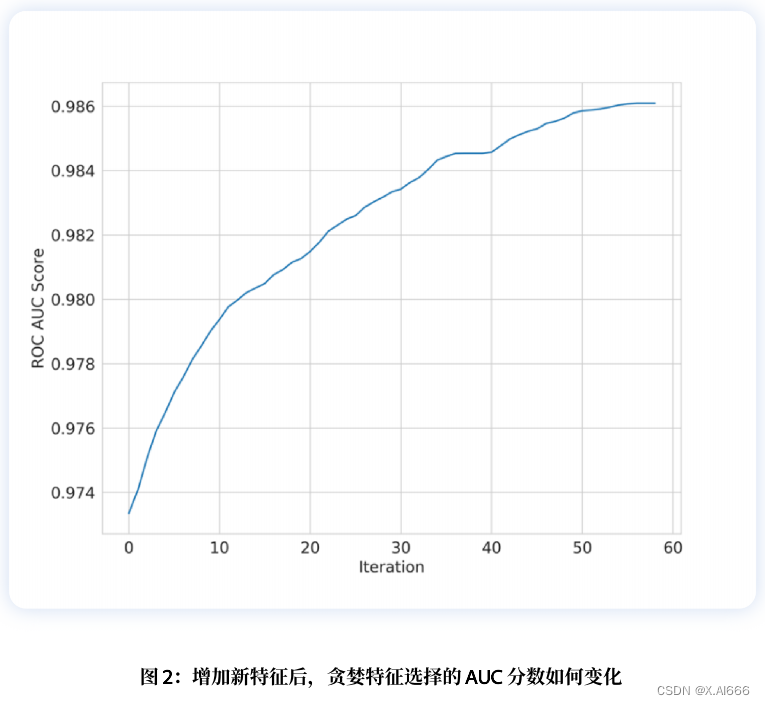
这种贪婪特征选择⽅法会返回分数和特征索引列表。图 2 显⽰了在每次迭代中增加⼀个新特征后,分数是如何提⾼的。我们可以看到,在某⼀点之后,我们就⽆法提⾼分数了,这就是我们停⽌的地⽅。
另⼀种贪婪的⽅法被称为递归特征消除法(RFE)。在前⼀种⽅法中,我们从⼀个特征开始,然后不断添加新的特征,但在 RFE 中,我们从所有特征开始,在每次迭代中不断去除⼀个对给定模型提供最⼩值的特征。但我们如何知道哪个特征的价值最⼩呢?如果我们使⽤线性⽀持(SVM)或逻辑回归等模型,我们会为每个特征得到⼀个系数,该系数决定了特征的重要性。⽽对于任何基于树的模型,我们得到的是特征重要性,⽽不是系数。在每次迭代中,我们都可以剔除最不重要的特征,直到达到所需的特征数量为⽌。因此,我们可以决定要保留多少特征。
当我们进⾏递归特征剔除时,在每次迭代中,我们都会剔除特征重要性较⾼的特征或系数接近 0 的特征。请记住,当你使⽤逻辑回归这样的模型进⾏⼆元分类时,如果特征对正分类很重要,其系数就会更正,⽽如果特征对负分类很重要,其系数就会更负。修改我们的贪婪特征选择类,创建⼀个新的递归特征消除类⾮常容易,但 scikit-learn 也提供了 RFE。下⾯的⽰例展⽰了⼀个简单的法。
import pandas as pd
from sklearn.feature_selection import RFE
from sklearn.linear_model import LinearRegression
from sklearn.datasets import fetch_california_housing
data = fetch_california_housing()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]
model = LinearRegression()
rfe = RFE(
estimator=model,
n_features_to_select=3
)
rfe.fit(X, y)
X_transformed = rfe.transform(X)
我们看到了从模型中选择特征的两种不同的贪婪⽅法。但也可以根据数据拟合模型,然后通过特征系数或特征的重要性从模型中选择特征。如果使⽤系数,则可以选择⼀个阈值,如果系数⾼于该阈值,则可以保留该特征,否则将其剔除。
让我们看看如何从随机森林这样的模型中获取特征重要性。
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
data = load_diabetes()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]
model = RandomForestRegressor()
model.fit(X, y)随机森林(或任何模型)的特征重要性可按如下⽅式绘制。
importances = model.feature_importances_
idxs = np.argsort(importances)
plt.title('Feature Importances')
plt.barh(range(len(idxs)), importances[idxs], align='center')
plt.yticks(range(len(idxs)), [col_names[i] for i in idxs])
plt.xlabel('Random Forest Feature Importance')
plt.show()结果如图 3 所⽰。
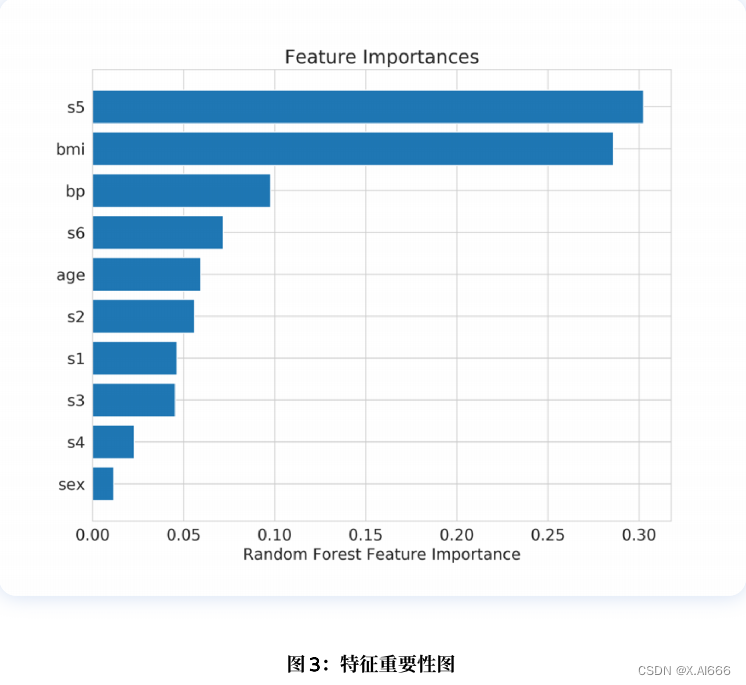
从模型中选择最佳特征并不是什么新鲜事。您可以从⼀个模型中选择特征,然后使⽤另⼀个模型进⾏训练。例如,你可以使⽤逻辑回归系数来选择特征,然后使⽤随机森林(Random Forest)对所选特征进⾏模型训练。Scikit-learn 还提供了 SelectFromModel 类,可以帮助你直接从给定的模型中选择特征。您还可以根据需要指定系数或特征重要性的阈值,以及要选择的特征的最⼤数量。
请看下⾯的代码段,我们使⽤ SelectFromModel 中的默认参数来选择特征。
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.ensemble import RandomForestRegressor
from sklearn.feature_selection import SelectFromModel
data = load_diabetes()
X = data["data"]
col_names = data["feature_names"]
y = data["target"]
model = RandomForestRegressor()
sfm = SelectFromModel(estimator=model)
X_transformed = sfm.fit_transform(X, y)
support = sfm.get_support()
print([x for x, y in zip(col_names, support) if y = True ])
上⾯程序打印结果: ['bmi','s5']。我们再看图 3,就会发现这是最重要的两个特征。因此,我们也可以直接从随机森林提供的特征重要性中进⾏选择。我们还缺少⼀件事,那就是使⽤ L1
(
Lasso
)惩罚模型
进⾏特征选择。当我们使⽤ L1 惩罚进⾏正则化时,⼤部分系数都将为 0(或接近 0),因此我们要选择系数不为 0 的特征。只需将模型选择⽚段中的随机森林替换为⽀持 L1 惩罚的模型(如 lasso 回归)即可。所有基于树的模型都提供特征重要性,因此本章中展⽰的所有基于模型的⽚段都可⽤于 XGBoost、LightGBM 或 CatBoost。特征重要性函数的名称可能不同,产⽣结果的格式也可能不同,但⽤法是⼀样的。最后,在进⾏特征选择时必须⼩⼼谨慎。在训练数据上选择特征,并在验证数据上验证模型,以便在不过度拟合模型的情况下正确选择特征。