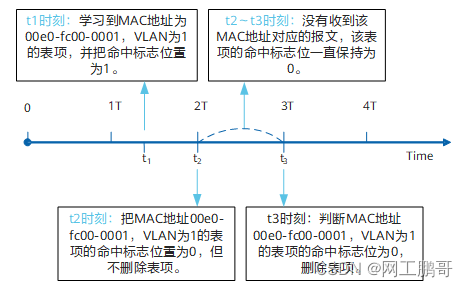
词嵌入(Word Embedding)是一种在自然语言处理中广泛使用的表示方法,它将离散的词汇表中的每个词转换为一个连续向量空间中的稠密向量。这种低维度实数向量能够捕捉词语之间的语义和句法关系。
通过训练神经网络模型(如word2vec、GloVe或FastText等),可以在大规模文本语料库上学习到这些词嵌入。经过预训练后,每个单词会被映射到一个固定长度的向量上,这个向量可以反映该单词在整个语料库中的上下文信息和潜在语义特征。
词嵌入技术极大地改善了机器学习模型对自然语言的理解能力,通常作为下游任务(如情感分析、文本分类、命名实体识别等)的基础特征输入。

1.词嵌入(Word Embedding)的特点
词嵌入(Word Embedding)是自然语言处理中的一种重要技术,它将词汇表中的每个单词转换成一个低维度、连续的向量表示。这种向量通常被称为词向量,具有以下特点:
-
稠密性:与传统的基于one-hot编码的方式不同,词嵌入使用的是稠密向量,即每个单词不再是一个高维空间中几乎全为零、只有一个位置为一的稀疏向量,而是长度固定且所有元素都是实数值的密集向量。
-
语义和句法信息:词嵌入旨在捕获单词之间的语义相似性和句法关系。例如,通过训练好的词嵌入模型,"猫"和"狗"这两个词的向量在向量空间中的距离会比较接近,因为它们在语义上都是宠物;而"猫"和"飞机"的距离则较远,因为它们的语义差异较大。
-
预训练方法:常见的词嵌入生成方法有word2vec(包括CBOW和Skip-gram两种模式)、GloVe(Global Vectors for Word Representation)以及FastText等。这些方法都是基于大规模无标注文本数据进行训练,学习过程中不需要人工标注的信息。
- word2vec通过预测上下文词来学习中心词的向量表示。
- GloVe结合了全局统计共现矩阵的信息,并优化目标使得共现概率可以由词向量的内积近似。
- FastText在此基础上还考虑了单词内部的字符n-grams信息,对未登录词有更好的处理能力。
-
下游任务应用:训练得到的词嵌入向量可以直接作为输入特征用于多种自然语言处理任务,如文本分类、情感分析、命名实体识别、机器翻译等,也可以进一步微调以适应特定任务的需求。
总之,词嵌入技术有效地解决了自然语言处理中离散符号表示的问题,将词汇转化为计算机易于理解和操作的数值形式,极大地推动了NLP领域的研究和发展。
2.词嵌入解决了NLP中离散符号表示的问题
词嵌入技术确实解决了自然语言处理(NLP)中离散符号表示的问题。在传统的NLP方法中,词语通常通过one-hot编码进行表示,即每个单词被转化为一个高维向量,其中只有一个维度为1(对应该词的位置),其余所有维度均为0。这种表示方式有两个主要缺点:
-
稀疏性:由于词汇量通常非常大,导致表示空间极度稀疏,不利于捕捉语义和句法上的相似性或关联。
-
忽视了语义信息:one-hot编码没有考虑词语之间的内在联系和语义关系,不同的单词即使在含义上有密切关联,在这种编码下也表现为完全正交的状态。
词嵌入则通过训练模型学习到一种低维度、连续的向量表示,使得具有相似语义或上下文共现模式的词语在新的向量空间中的距离更近。这样不仅压缩了数据维度,降低了计算复杂度,而且有效地保留并编码了词汇间的语义结构和语法特性,从而提升了后续NLP任务(如分类、聚类、翻译等)的性能和效果。
3.词嵌入将词汇转化为计算机易于理解和操作的数值形式
词嵌入技术是自然语言处理领域中的关键组成部分,它通过数学方法将词汇表征为连续的、低维度的向量空间中的点。这种转化过程克服了传统离散表示(如one-hot编码)的局限性,极大地提高了计算机理解和操作词汇的能力。
在词嵌入中,每个单词不再是简单的独热编码,而是被映射到一个具有特定含义和语义信息的数值向量上。这些向量通常被称为“词向量”或“词嵌入”,它们的空间位置反映了词汇之间的语义相似度和关联性:语义相似或相关的词语在向量空间中的距离较近,而意义迥异的词语则相距较远。
例如,在预训练模型如word2vec、GloVe和FastText中,模型通过学习大规模无标注文本数据集中的上下文信息,自动捕捉并编码词汇的语义关系。这样生成的词嵌入能够作为深度学习模型的输入特征,有效地支持后续的分类、聚类、翻译等多种自然语言处理任务,并显著提升了模型性能和泛化能力。
4.词嵌入向量有效捕获词汇在大规模语料库中的语义和上下文信息
经过预训练得到的词嵌入向量之所以能够有效捕获词汇在大规模语料库中的语义和上下文信息,主要是因为预训练过程设计的目标函数及模型架构能够在训练过程中学习到词汇间的内在联系和它们在实际使用中的语境含义。
例如,在Word2Vec这样的词嵌入模型中,通过两种经典的训练方法:
-
CBOW(Continuous Bag-of-Words):基于一个中心词预测其周围的上下文词,这种方法鼓励模型学习到那些经常出现在相同上下文环境中的词在向量空间中有相似的表示。
-
Skip-gram:则是根据给定的一个词来预测它周围的上下文词,这使得模型能够学习到单个词作为中心词时能与其他哪些词共同出现的模式,从而反映出这个词的多种语义特征。
另外,更复杂的模型如Transformer架构中的词嵌入(如BERT、GPT等),采用了自注意力机制和双向训练策略,不仅考虑了词的局部上下文,还考虑了全局上下文信息。这些模型在预训练阶段通常会进行遮蔽语言模型任务或下一个单词预测任务,强制模型学会从整个句子的上下文中推断出特定位置词语的意义。
总之,预训练词嵌入模型通过对大规模无标签文本数据集进行训练,利用统计学原理捕捉到了词汇之间的共现概率以及上下文依赖关系,并将这些复杂的关系编码成固定维度的向量,从而使得相近语义和上下文关系的词汇在高维空间中距离接近,实现了对语义和上下文信息的有效捕获。
5.词嵌入极大地推动了NLP领域的研究和发展
词嵌入技术为自然语言处理(NLP)领域带来了革命性的变化和巨大的推动作用。以下是它如何促进NLP研究和发展的一些关键方面:
-
语义捕获:词嵌入通过将每个单词映射到一个低维向量空间,能够捕捉词汇间的语义关系和相似性。例如,在这个连续向量空间中,诸如“国王”、“王后”与“王子”的词向量之间的距离较小,反映它们在概念上的关联。
-
上下文敏感:更先进的词嵌入模型如Transformer中的词嵌入层(如BERT的Token Embeddings、Positional Embeddings和Segment Embeddings)能够考虑到上下文信息,使得同一个词在不同的上下文中拥有不同的表示,增强了模型对文本理解的深度和广度。
-
计算效率:词嵌入消除了传统NLP中使用的one-hot编码带来的维度灾难问题,极大地减少了模型输入数据的稀疏性和维度,提高了模型训练和预测的效率。
-
迁移学习:预训练的词嵌入模型允许其他任务直接利用大规模无标注数据集训练得到的词嵌入,作为下游任务的初始特征,促进了迁移学习的应用,并显著提升了多种NLP任务的表现。
-
模型创新:基于词嵌入的许多NLP模型得以构建和发展,如循环神经网络(RNNs)、长短时记忆网络(LSTMs)、门控循环单元(GRUs),以及后来的Transformer架构等,这些模型在各种NLP任务上取得了突破性成果。
-
消除偏见:尽管词嵌入可能携带社会偏见,但随着对该问题认识的加深,研究者也开始探索去偏词嵌入的方法,努力使模型更加公正和包容。
综上所述,词嵌入技术不仅提供了一种有效表征自然语言词汇的方式,还成为了现代NLP系统的核心组件之一,极大地推动了整个领域的研究边界和技术进步。
6.各种词嵌入生成方法的介绍
词嵌入生成方法是自然语言处理中用于将词汇表征为数值向量的关键技术,这样可以更好地捕获词语之间的语义和语法关系。以下是几种著名的词嵌入生成方法的详细介绍:
-
word2vec:
-
CBOW(Continuous Bag of Words):该模型以一个单词的上下文作为输入,预测中心词。具体来说,它通过计算给定窗口内上下文词的一组one-hot编码表示的平均值来预测当前中心词。训练过程中,模型学习到的权重矩阵就是词嵌入矩阵。
-
Skip-gram:与CBOW相反,Skip-gram模型的目标是根据给定的中心词来预测其周围的上下文词。对于每个中心词,模型试图最大化正确预测其上下文窗口内所有单词的概率。这个过程使得每个单词的嵌入能够反映与其共现的其他单词的信息。
-
-
GloVe (Global Vectors for Word Representation):
GloVe方法结合了全局统计信息和局部上下文窗口的优势。它通过优化一个全局词频矩阵中的概率分布与词向量点积之间的相关性,从而找到一种能直接从全局统计信息中捕捉词汇间关系的词嵌入表示。 -
FastText:
FastText由Facebook的研究团队提出,它在词嵌入的基础上增加了对词内部结构的关注,特别是对组成复合词的子词或字符n-grams的考虑。通过对这些子单元的学习,FastText能够在保留词序信息的同时提高对未见词的泛化能力。 -
WordRank:
WordRank借鉴了PageRank算法的思想,通过构建词语间的共现网络,并在网络中传播权重,最终得到各词语的排名分数,将其转换为词嵌入。 -
PPMI + SVD (Positive Pointwise Mutual Information + Singular Value Decomposition):
这种方法首先计算词对的PPMI矩阵,然后使用奇异值分解(SVD)压缩矩阵,从而获得低维的词嵌入。这种方法基于统计学原理,捕捉共现频率较高的词对之间的关联。 -
BERT (Bidirectional Encoder Representations from Transformers) 和 Transformer-based Models:
BERT和其他Transformer架构模型不是直接生成词嵌入,而是通过深度双向Transformer层在整个句子上下文中学习词的上下文敏感的表示,即“上下文嵌入”。这种嵌入包含了丰富的句法和语义信息,通常被称为“词片段”或“Token Embeddings”。
每种方法都有其特点和适用场景,随着深度学习技术的发展,词嵌入的生成方式也在不断演进和改进,旨在更高效、准确地捕获自然语言数据中的复杂关系。