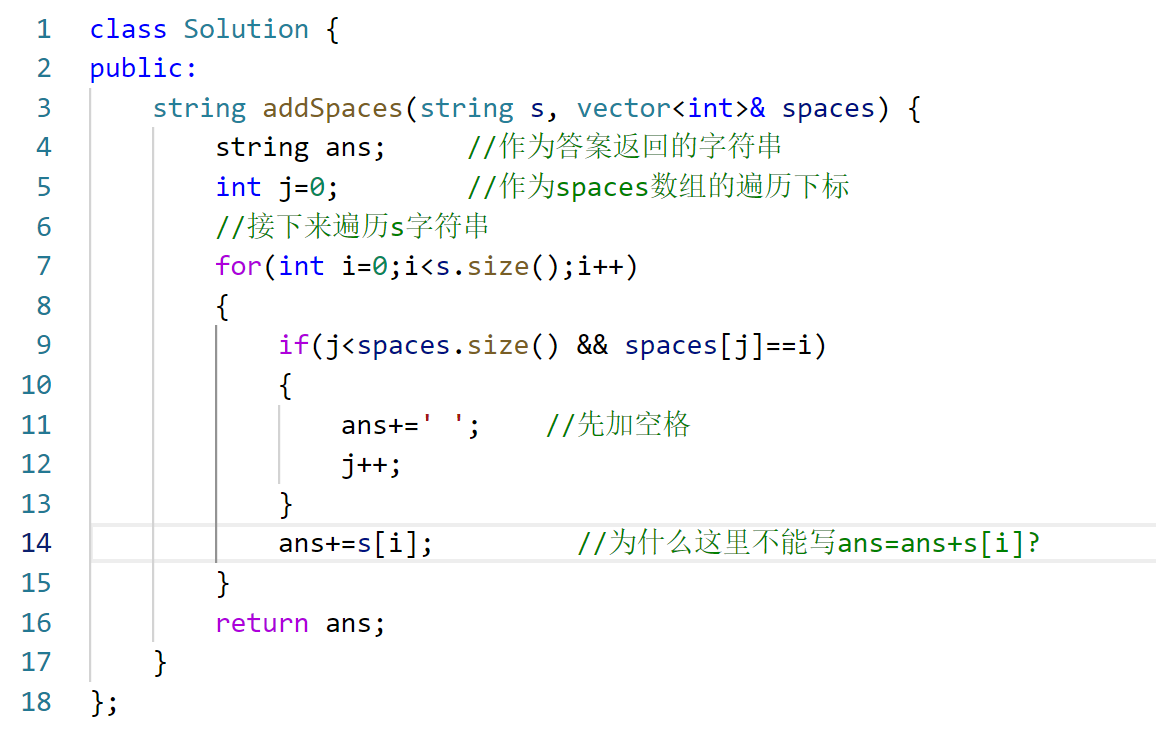
能通过训练或者微调,产生其它没有的组合的结构,比如有化学组成和空年组,想要生成指定化学成分+指定空间组的结构,以下是针对需求的详细分析与实现思路,同时给出相应的 Python 代码示例。
1. 训练或微调以生成新组合结构
要生成指定化学成分与指定空间组的结构,你可以对 mattergen 模型进行微调。微调的过程一般是在预训练模型的基础上,利用包含目标组合结构的数据集进一步训练模型。
2. 生成模型中未实现的词条
对于像“过电势”这类模型未实现的词条,你可以先进行预训练,再进行微调。预训练能够让模型学习到通用的语言特征,微调则可让模型聚焦于特定的任务。
3. 预训练过程
数据集创建
你需要构建一个包含目标词条与组合结构的数据集。数据集可以是文本文件,每行代表一个样本。
预训练步骤
- 加载预训练模型:加载 mattergen 模型。
- 数据处理:把数据集转换为模型能够接受的格式。
- 训练模型:运用处理后的数据对模型进行训练。
以下是一个简单的 Python 代码示例,用于说明预训练和微调的过程:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, TrainingArguments, Trainer
加载预训练模型和分词器
model_name = “your_mattergen_model_name” # 替换为实际的 mattergen 模型名称
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
数据集创建示例
data = [
“指定化学成分1 + 指定空间组1”,
“指定化学成分2 + 指定空间组2”,
“过电势相关描述1”,
“过电势相关描述2”
]
数据处理
def tokenize_function(examples):
return tokenizer(examples[“text”], padding=“max_length”, truncation=True)
tokenized_datasets = tokenize_function({“text”: data})
tokenized_datasets = {k: [v] for k, v in tokenized_datasets.items()}
训练参数设置
training_args = TrainingArguments(
output_dir=‘./results’, # 输出目录
num_train_epochs=3, # 训练轮数
per_device_train_batch_size=16, # 每个设备的训练批次大小
save_steps=10_000, # 每多少步保存一次模型
save_total_limit=2, # 最多保存的模型数量
prediction_loss_only=True,
)
训练器
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets,
)
预训练
trainer.train()
保存预训练后的模型
model.save_pretrained(“./pretrained_model”)
tokenizer.save_pretrained(“./pretrained_model”)
微调示例
假设你有一个微调数据集 fine_tuning_data
fine_tuning_data = [
“微调数据示例1”,
“微调数据示例2”
]
fine_tuning_tokenized_datasets = tokenize_function({“text”: fine_tuning_data})
fine_tuning_tokenized_datasets = {k: [v] for k, v in fine_tuning_tokenized_datasets.items()}
微调训练器
fine_tuning_trainer = Trainer(
model=model,
args=training_args,
train_dataset=fine_tuning_tokenized_datasets,
)
微调
fine_tuning_trainer.train()
保存微调后的模型
model.save_pretrained(“./fine_tuned_model”)
tokenizer.save_pretrained(“./fine_tuned_model”)
注意事项
- 要把
your_mattergen_model_name替换成实际的 mattergen 模型名称。 - 数据集需要依据实际情况进行扩充与优化。
- 训练参数可以根据具体任务和计算资源进行调整。