1. 背景
近几年,随着“大模型”概念的提出,深度学习模型越来越大,如何训练这些大模型成为一个亟待解决的工程问题。最初的视觉模型只有几百兆的参数量,而现在的语言模型中,动则百亿,千亿的参数量,甚至万亿的大模型也是见怪不怪。如此巨大的参数量将会消耗巨大的存储空间。如下表所示为当前大模型的参数量(以Float32计算)以及对应的存储空间。

而当前最好的nvidia GPU显卡也只有40G的显存容量,显然将大模型塞进一张显卡是不现实的。本质上,所有大模型的训练,都使用了分布式的方式。当前分布式训练中,常用的有数据并行,模型并行和流水线并行,从计算效率上来说,数据并行要远远优于模型并行和流水线并线。但是数据并行对显存的占用是最高的,因为它需要将整个网络都运行在一张GPU上面。而在模型训练过程中,除了参数以外,还有很多地方需要占用存储空间,这就使得训练大模型时候的显存消耗进一步提升。因此你是否好奇,如何训练如此庞大的深度学习模型呢?
2. 深度学习中的显存占用
在探讨如何进行大规模训练之前,我们先来详细看看网络中的显存占用。通常在深度学习训练过程中,涉及到的显存占用包括:网络的参数,梯度,激活值,激活值的梯度,优化器的状态信息,如果使用了混合精度[6]训练,那么还有备份参数(master_weight)等。这里需要指出的是,激活值的梯度在古老的caffe框架中是没有做过优化的,其占用空间和激活值相同。但是在tensorflow,pytorch等框架中,已经做了很好的优化,因此激活值的梯度实际上并没有占据很大的显存空间。另外,可能很多朋友对前面几种类型的显存占用(网络的参数,梯度,激活值,激活值的梯度)比较清楚,但是对于优化器的状态信息以及混合精度[6]训练的备份参数(master_weight)不是很清楚,这里稍加说明。
2.1 SGD优化器
在简单的SGD优化器中,更新参数使用如下公式:

2.2 Moment SGD优化器
但是通常我们不会直接使用SGD来更新参数,而会对梯度进行滑动平均后,再进行更新,即使用Moment SGD优化器,其计算公式如下:
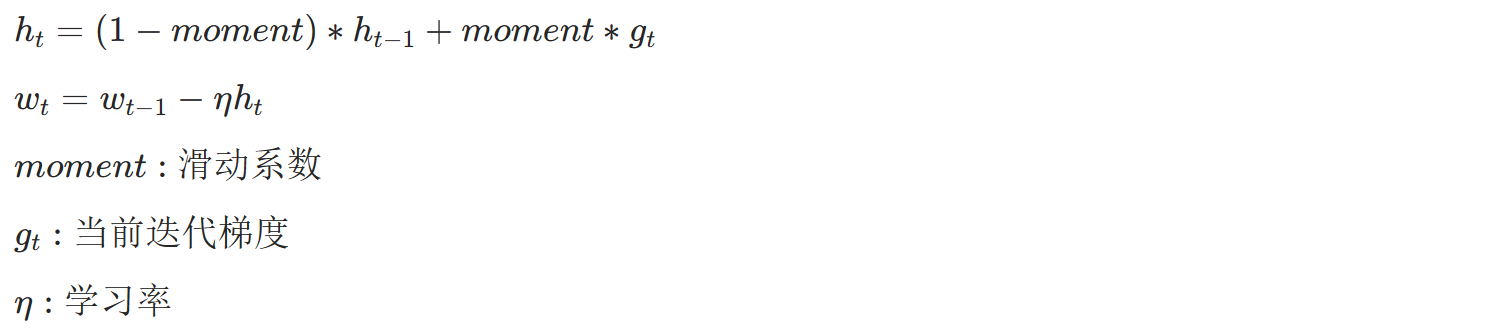
由于计算需要用到,因此需要一直保存在显存中。就是优化器的状态信息,其大小和梯度一致,因此和参数大小一致。例如参数规模是100亿,那么优化器缓存信息也是100亿的规模。
2.3 ADAM优化器
在很多时候,我们也会使用ADAM优化器进行参数更新,而ADAM会用到梯度的一阶矩估计和二阶矩估计,公式如下:

同理,由于计算需要用到,计算需要用到,因此和两个变量也需要一直保存在显存中,他们大小也和梯度一致,因此也和参数一致。例如参数规模是100亿,那么和一共就是需要200亿的规模。
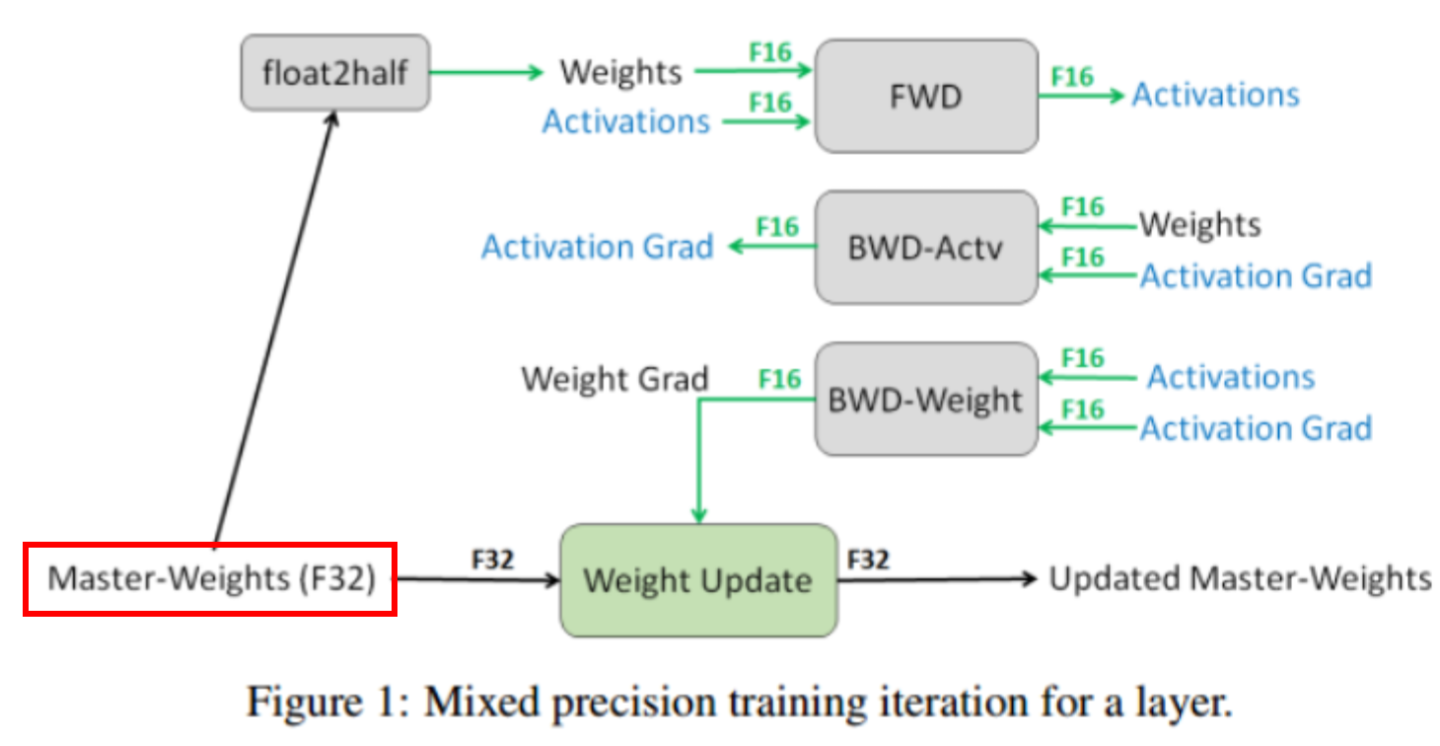
2.4 混合精度[6]
有时候我们为了提升效率,会使用混合精度[6]进行训练,而混合精度[6]训练为了抵消float16在参数更新时候的舍入误差,会额外保存一份FP32的参数用于参数更新,称作master-weights,因此会多出一份显存占用空间。
2.5 激活值优化与参数优化
上面分析了深度学习网络的显存占用,而不同的架构中,各个部分的显存占比是不同。在CNN中,通常是激活值占据了大部分的显存空间。而MLP/Transformer等结构则是模型的参数与参数的梯度,优化器的状态信息占据了更大的比例。因此对于不同的网络结构,其优化策略是不相同的。对于CNN网络,通常优化的重点是激活值。而MLP/Transformer则更关注于网络参数相关的显存优化。因此对于两种不同类型的网络,分别需要用到激活值优化策略与参数优化策略。
3. 激活值优化策略
3.1 时间换空间
前面分析过,cnn网络的显存消耗主要是激活值以及激活值的梯度。随着输入分辨率的提升,以及batch size的扩大,激活值以及激活值梯度的显存占用会呈现平方倍的增加。因此对于CNN的大模型训练,主要集中在对激活值的优化上。这里介绍一种以增加计算时间来降低显存空间占用的方式:“亚线性内存优化[5]”。首先来看一下常规深度学习的流程,如下图所示。前向计算后,保存所有的激活值,如图中的a1,a2,a3与a4。反向计算的时候,根据之前的激活值,计算每一层layer的梯度,包括激活值梯度与参数梯度。
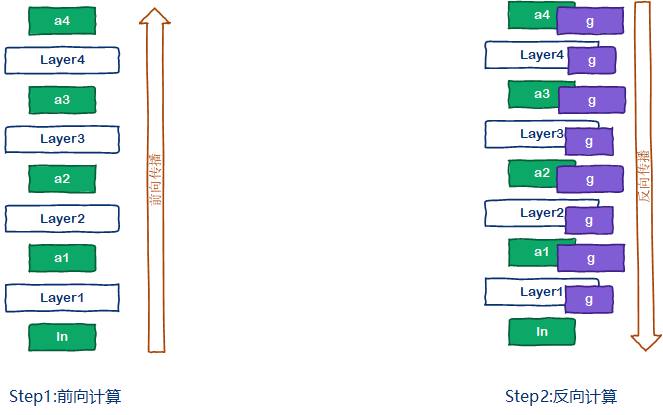
而“亚线性内存优化[5]”的深度学习流程则与传统的深度学习流程有些差异,如下图所示。在前向计算中,为了降低显存消耗,会选择性的丢弃部分激活值,例如a2。反向计算的时候,按照常规的方法进行计算,当遇到激活值缺失的时候,例如计算layer3的参数梯度时,需要用到激活值a2,但是a2已经被丢弃,此时会暂停反向传播,重新进行一次最短路径的前向计算,根据a1计算出a2(如果a1也被丢弃,那么继续向前找)。然后再继续原来的反向传播。
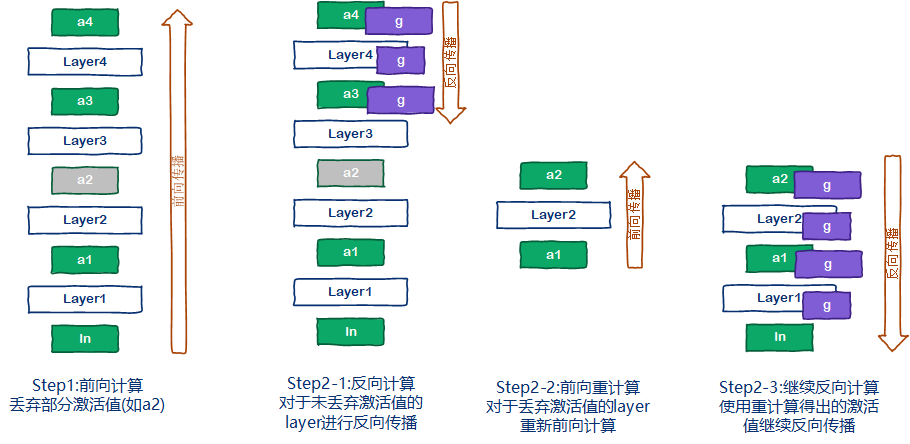
由此可见,“亚线性内存优化[5]”彻彻底底的使用了时间换空间的策略。那么你是否好奇,为什么它会取一个这样的名字呢?其实理解起来也很简单,假设每一层的激活值大小相同,那么整个网络的激活值大小就和layer的数目成线性关系,layer的深度扩大几倍,激活值的占用就扩大几倍。而使用了“亚线性内存优化[5]”策略之后,显存的占用与layer的增加不再是线性关系,而是亚线性的,因此叫做“亚线性内存优化[5]”,实际上,如何选择丢弃的激活值,将会极大的影响最终的网络性能。被丢弃的激活值需要满足前向计算简单(降低重计算的耗时),激活值占用空间大的特点。例如BN层,其计算非常简单,重计算基本不耗时(相对卷积),因此比较适合丢弃。
3.2 低精度训练
除此之外,还可以使用低精度训练的方式。这样激活值以及激活值的梯度都使用更小的数据格式存储。能够极大的降低激活值的存储空间。例如在使用混合精度[6]训练的时候,所有激活值使用float16的格式,相对于原始的float32,显存占用直接缩小了一半。
4. 参数优化策略
上面介绍的激活值优化策略适合于CNN这样的结构。而当前的一些大模型,其显存占用主要集中在参数以及参数相关的显存占用上。例如参数的梯度,优化器的状态信息等。因此如何优化参数相关的显存占用对于大模型的训练显得更加重要。
4.1 ZeRO[4]数据并行原理
微软开源的DeepSpeed训练框架中,使用了一种称为ZeRO[4]的显存优化技术,称为零冗余优化技术。本质上,它是一种数据并行的分布式训练策略,重点优化了数据并行中的显存占用问题。在ZeRO[4]数据并行中,每个GPU上虽然拥有完整的网络,但是每个GPU只保存一部分的参数,梯度和优化器状态信息,这样就就可以将参数,梯度,优化器状态信息平均分配到多个GPU上。这对于参数观规模较大的网络,显存的降低将是巨大的。但是由于分布式存储参数,也会导致通信的增加。
4.2 传统数据并行流程
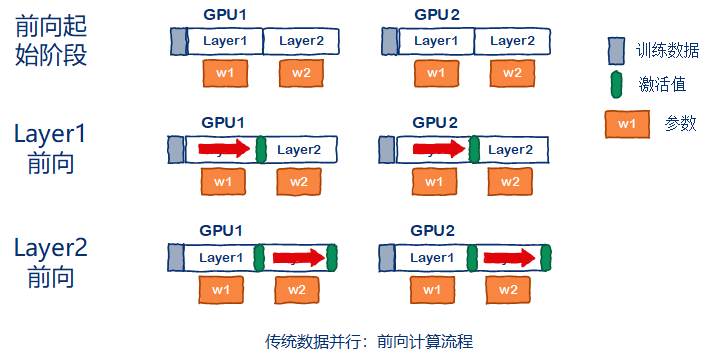
首先来简单回顾一下传统的数据并行流程,包括前向计算,反向计算,参数更新三个流程。假设一共有两张GPU参与训练,前向流程如下图所示,起始阶段,每张GPU初始化为相同的参数,并划分互斥的训练子集。每站GPU独立完成所有layer的前向计算。
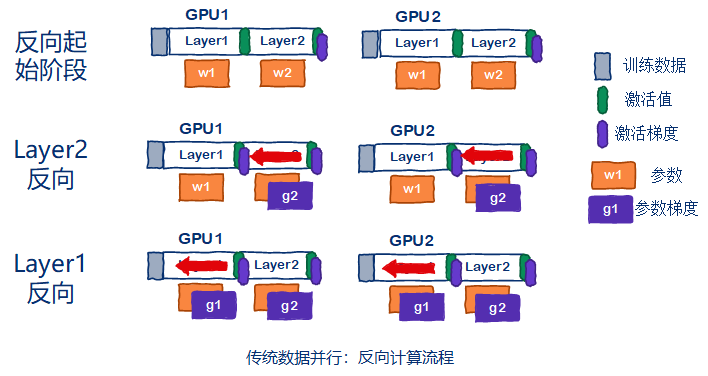
反向流程如下图所示。起始阶段,最后一个激活值已经通过loss求导得到了激活值的梯度。然后每张GPU独立的进行所有layer的反向计算。
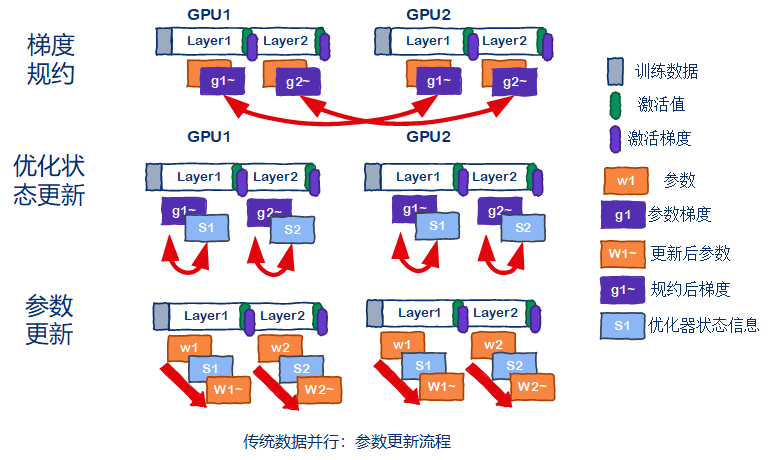
参数更新流程如下图所示。先对所有GPU的梯度进行规约操作(求平均值),然后每张GPU独立的更新参数。(由于初始参数值相同,梯度规约后也相同,因此最后每张GPU上更新后的参数也相同)
4.3 ZeRO[4]数据并行流程
ZeRO[4]数据并行有多个级别,分别是os级别(只对优化器状态做优化),os+g级别(对优化器状态+梯度做优化),以及os+g+p级别(对优化器状态+梯度+参数都做优化)。我们直接分析优化程度最高的os+g+p流程。首先看前向计算流程,在起始阶段,每张GPU只保存W/GPU_NUM的参数。这里假设网络有2个layer,一共两张GPU参与并行,因此GPU1只保存layer1的参数w1,GPU2只保存layer2的参数w2。在layer1的前向计算之前,由于GPU2没有layer1的参数,因此需要做一次w1的参数分发。然后进行layer1的前向计算。同样在进行layer2的前向计算之前,需要将layer2的参数w2进行一次分发,再完成layer2的前向计算。整体示意图如下图所示。
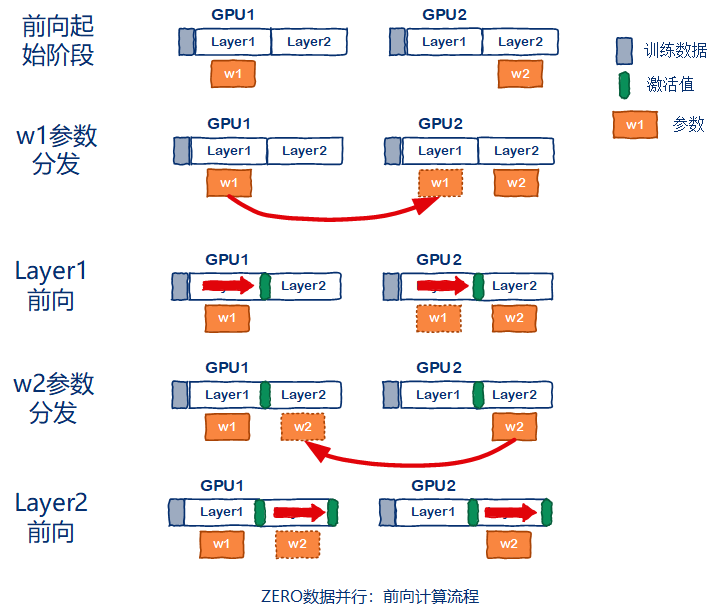
再来分析ZeRO[4]数据并行的反向传播流程。同样的,当layer反向计算前,都需要对参数进行分发。然后再进行反向传播计算。完成反向传播之后,会有一个梯度搜集的过程,例如GPU2需要保存w2对应的梯度g2,因此所有其他GPU将g2梯度发送给GPU2。GPU2上面得到各个GPU的g2梯度后,做规约操作并保存,得到g2~。其他GPU将会删除w2,g2。然后重复该流程,直到所有layer都完成反向传播计算。示意图如下图所示。
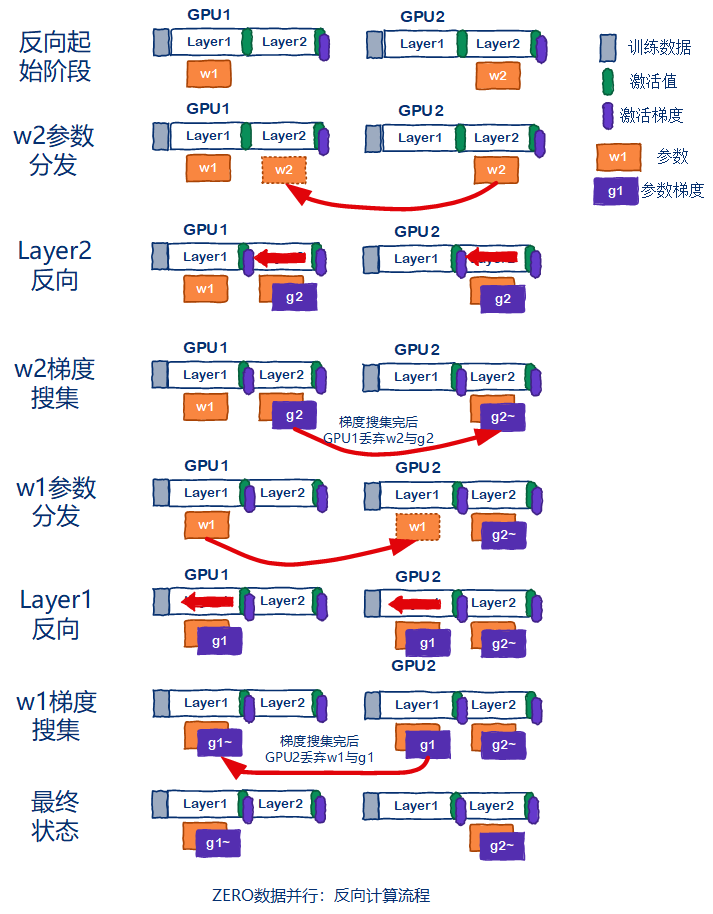
最后来分析一下ZeRO[4]数据并行的参数更新流程。由于梯度的规约操作在反向传播的时候已经做了,因此ZeRO[4]数据并行可以直接更新优化器的状态信息,然后更新参数,示意图如下图所示。
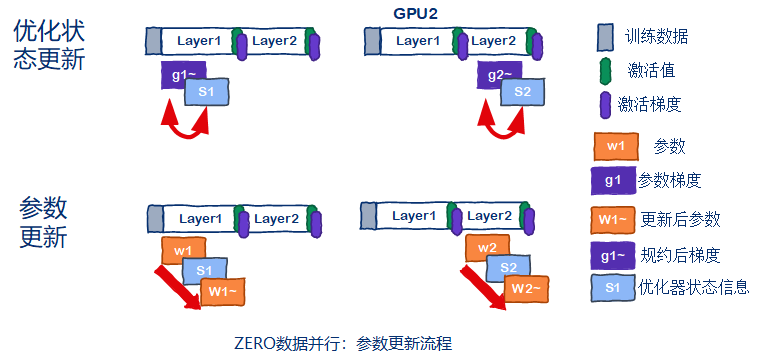
4.4 ZeRO[4]数据并行通信开销
从前面的ZeRO[4]数据并行流程可以看出,ZeRO[4]数据并行在os+g+p级别(对优化器状态+梯度+参数都做优化)优化时,会有两次参数的分发(前向计算一次,反向计算一次)和一次梯度的搜集。而传统的数据并行只需要做一次梯度的规约。所以ZeRO[4]数据并行的通信消耗将是传统数据并行的3倍?其实不然,传统数据并行中,虽然只需要做梯度的规约操作,但是由于每张GPU都需要得到规约后的梯度,因此使用的时all-reduce的通信原语。而ZeRO[4]数据并行中,虽然有3此数据传输,但是只需要一对多分发参数或者多对一的梯度搜集,使用的是broadcast和gather的通信原语。而broadcast和gather的通信消耗基本相当,约为all-reduce的一半,因此最终ZeRO[4]数据并行在os+g+p级别上的通信开始时原始数据并行的1.5倍,而不是3倍。当使用os+g级别的优化或者os级别的优化,通信消耗与原始数据并行相当。关于分布式数据并行中的通信原语,通信消耗我将另外编写文章分析。
4.5 ZeRO[4]论文原图分析
最后我们来分析一下ZeRO[4]论文中最最最niubility的这副图。如何将传统数据并行中需要120G显存的模型变成了只需要1.9G。不看不知道,一看还真吓一跳!分析这张图片前需要知道一个前提,那就是全部基于混合精度[6]训练,并且采用adam的优化策略。
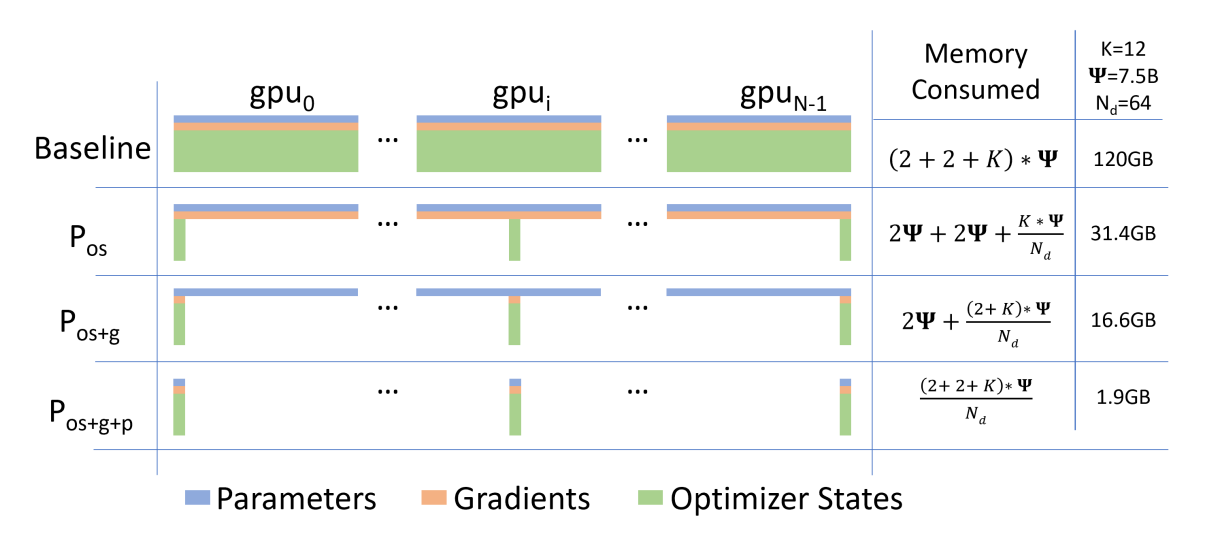
首先表示模型参数规模为7.5B,即75亿个参数量。由于所有训练均基于混合精度训练,因此参数和梯度都使用float16存储,一个参数占用两个字节,参数和梯度的显存占用都是的2倍。K表达的梯度状态信息以及混合精度master_weight的显存占用是的多少倍。由于梯度状态信息和混合精度master_weight必须使用float32来存储,即一个参数占用4个字节的存储空间,并且adam中有两个状态信息,分别是梯度的一阶矩估计和二阶矩估计,所以K = (2 + 1)*4 = 12倍的。Nd=64表示使用64张GPU进行zero数据并行训练。首先看第一行的Baseline,传统的数据并行,那么每张GPU的显存消耗就是:(2+2+K)\= 120G。接着看第二行,使用os级别的优化,那么参数和梯度的大小没变,优化器状态+master_weight被平均分配到了所有GPU上,因此每张GPU的显存消耗就是31.4G;同理分析第三行,使用os+g的级别的优化,由于梯度数据也被均分到了所有的GPU上面,因此每张GPU的显存消耗就是16.6G;最后分析使用os+g+p级别的优化,参数也被均分到所有GPU上面,因此最后每张GPU的显存消耗就是1.9G。从上面的分析中可以看出,在使用os+g+p级别的优化中,每张GPU的显存消耗就是传统数据并行的Nd分之1,大白话说就是用多少张GPU,显存消耗就能降低多少倍。
5. 总结
上面就是关于大模型训练训练中显存占用的一些优化措施。包括针对激活值优化的策略和针对参数优化的策略。正是有了这些工程上强有力的措施,才能让大模型的训练成为可能。不过由于作者水平有限,时间仓促,难免会有纰漏,还望各位读者不吝指正。感谢。
6. 参考资料
[1]DeepSpeed之ZeRO系列:将显存优化进行到底
https://zhuanlan.zhihu.com/p/513571706
[2]2022,大模型还能走多远
https://www.51cto.com/article/697186.html
[3]ZeRO+DeepSpeed:微软发布的高效大规模训练套件(含详细分布式训练流程)
https://zhuanlan.zhihu.com/p/108571246
[4] Rajbhandari S , Rasley J , Ruwase O , et al. ZeRO: Memory optimizations Toward Training Trillion Parameter Models[C]// SC20: International Conference for High Performance Computing, Networking, Storage and Analysis. 2020.
[5] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training Deep Nets with Sublinear Memory Cost. arXiv preprint arXiv:1604.06174, 2016.
[6] Micikevicius, P. , Narang, S. , Alben, J. , Diamos, G. , Elsen, E. , & Garcia, D. , et al. (2017). Mixed precision training.
![[golang工作日记] for range 踩坑](https://img-blog.csdnimg.cn/59075971b33047fe8a7b6990f15e2d5b.png)