文章目录
- 前言
- LLVM Types 在 JIT中的使用
- LLVM Types 设计导致的 PG JIT 内存问题分析
- 解决?
前言
之前介绍 PG 的 JIT 实现 时提到 为了性能开启JIT 之后有一个比较严重的内存泄漏问题。现象就是在一个backend 内持续跑大量的 sqllogic 随机复杂查询,能够看到这个backend对应的物理内存会持续上涨。
确定是JIT导致的证据:
- 这一部分物理内存的增加并没有在 PG 本身的 MemoryContext
- 关闭JIT之后并没有这个问题
- valgrind + massif 带着postgres 运行时发现的内存分配栈都在 llvm load bitcode产生的。
细节可以看看之前的文章,有一个内存分配栈能直接看到。
再发现 upstream 的 live-issue 列表中也一直有这个问题的存在,而且持续了好几年了,这个问题一直不好解决,详见:https://www.postgresql.org/message-id/flat/20201001021609.GC8476@telsasoft.com
大体的问题根因在没有看代码的情况下是这样的(贴一下社区的回复):
原因是说llvm 加载 bitcode 中的数据到module中的时候会生成一堆types相关的数据,从上面的调用栈能看到是在分配 一个PointerType,实际后面的其他调用栈也都是在分配types 类型对应的存储空间,每一次执行表达式可能需要load不止一个bc文件,这个时候types会生成很多,但是LLVM 不会复用前面已有的一样的types 的内存数据,而是重新为当前module分配一个新的这个type要保存的空间,之前的这一些types 对应的内存空间其实都会被保存在 LLVMOrcLLJITRef中,运行了一段时间的 JIT 后会积累大量的这种 types 的无用数据。LLVM 之所以这么做 猜测:应该是为了性能,因为 每一个 modules 中的 types实在是太多了,想要在load 下一个module的时候复用上一个module中的types 类型,那就需要耗费CPU去查找,不如耗费一点内存去从磁盘上load,内存中按需分配。
用户想要释放这一部分内存的话,就 reset LLVMOrcLLJITRef,后面重新创建。
上文也遗留了一些遗憾,没有追溯问题的本质,刚好最近解决了 gp 开启jit之后的一个crash问题,这块有了更为深刻的理解,特地弥补一下遗憾。
本篇不会对 PG JIT的调度做过多的描述,只是希望从 LLVM 源代码(release/11.x) + PG (REL_15_STABLE) 部分JIT 代码结合分析这个问题的根因。
LLVM Types 在 JIT中的使用
Type 系统 可以理解为 IR(Intermediate Representation) 中间语言 的数据类型,它的作用就像是我们C语言/SQL 的数据类型 (int/float/int*/function/class),用来标识一个变量、一个函数、一个结构体等等。有了这一些类型/关键字,才能做词法/语法解析。
Type 就是 LLVM 从bitcode 代码中解析出来的 LLVM IR能够识别的数据类型,从而构造IR 需要的 Module,Function,BasicBlock 以及 Instruction。
所以 Type 的重要性不言而喻,是IR 过程非常重要的部分。
官方实现的几种type 类型如下:
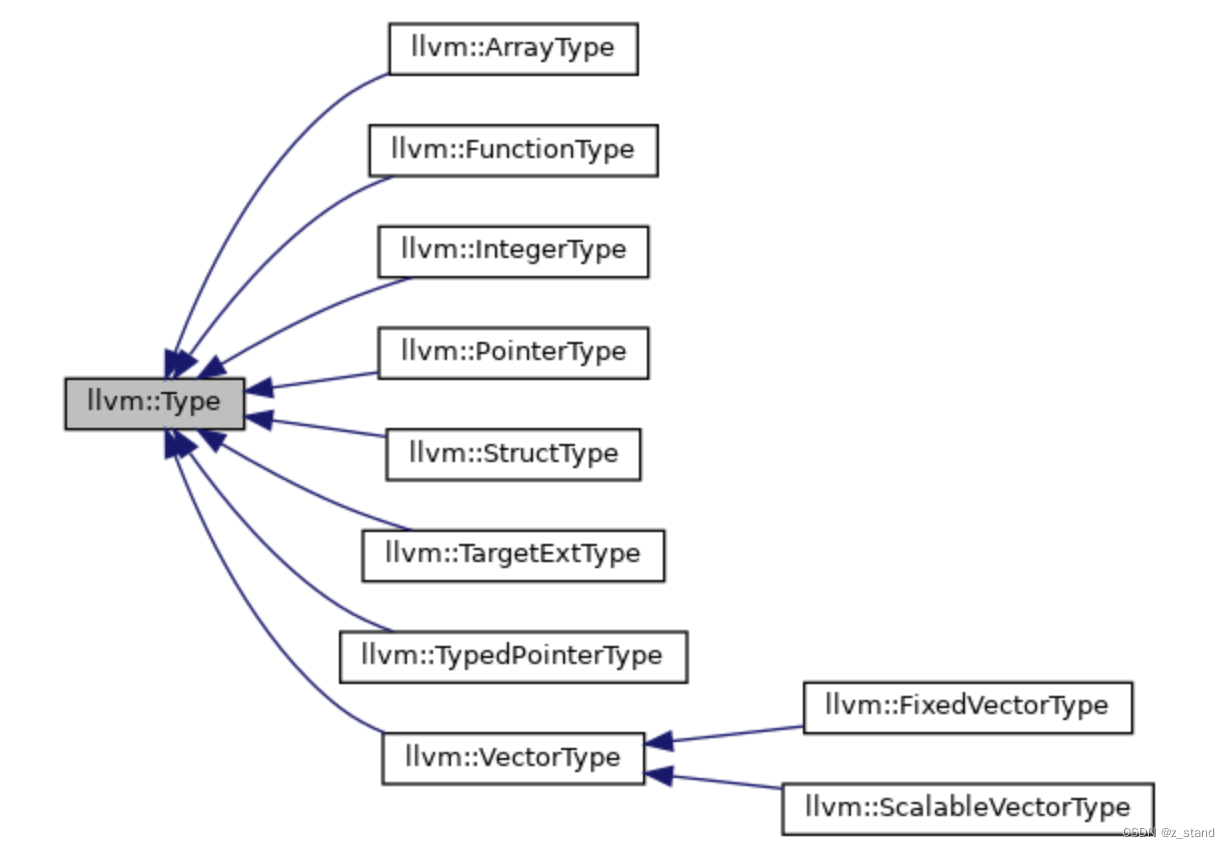
就这几种大分类 以及 每一种继承自 llvm::Type 的type 实现也都有各自的一些elementType,比如 IntegerType 就包括了 Int1Ty, Int8Ty, Int16Ty, Int32Ty, Int64Ty 这么多种range 的整数分类。
实际在 postgreSQL 编译生成 bitcode 代码中能够看到一些预定义好的要构造 IR 的类型,放在了 lib/llvmjit_types.bc中,由clang 对llvmjit_types.c 编译生成, 通过 llvm-dis 工具转为另一种可读格式之后就能看到如下内容:
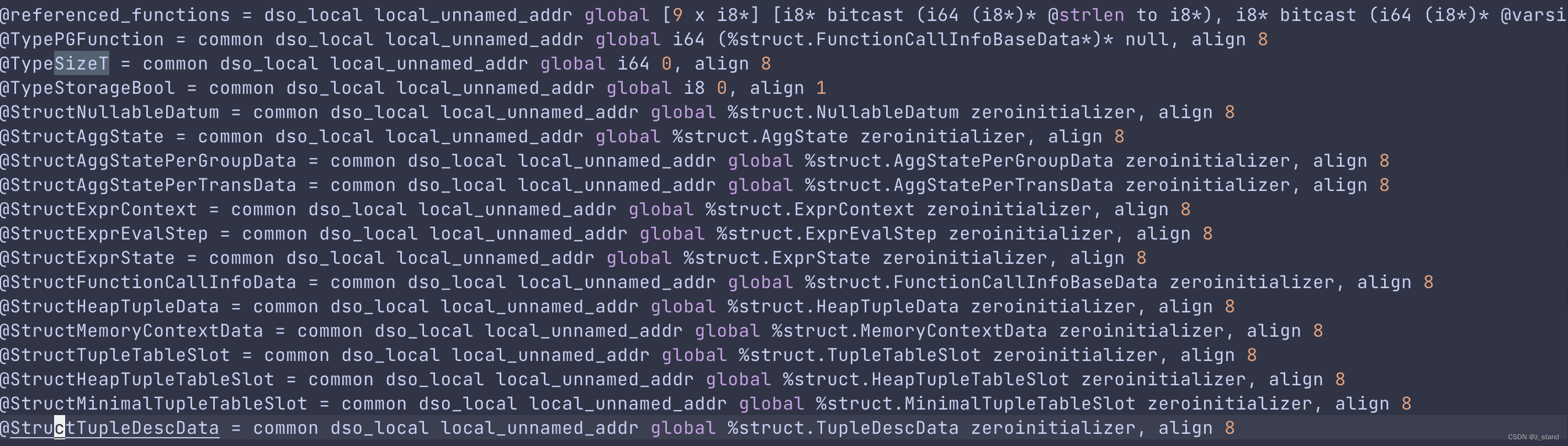
这一些types 在JIT 生成表达式的IR 表示过程中需要用,所以需要提前生成好,最后会在llvm_create_types 中直接加载,这样在 llvm_compile_expr时就能直接用这一些类型了。
使用已经定义好的类型方式如下,挑选llvm_compile_expr中一个处理op 类型的分支:
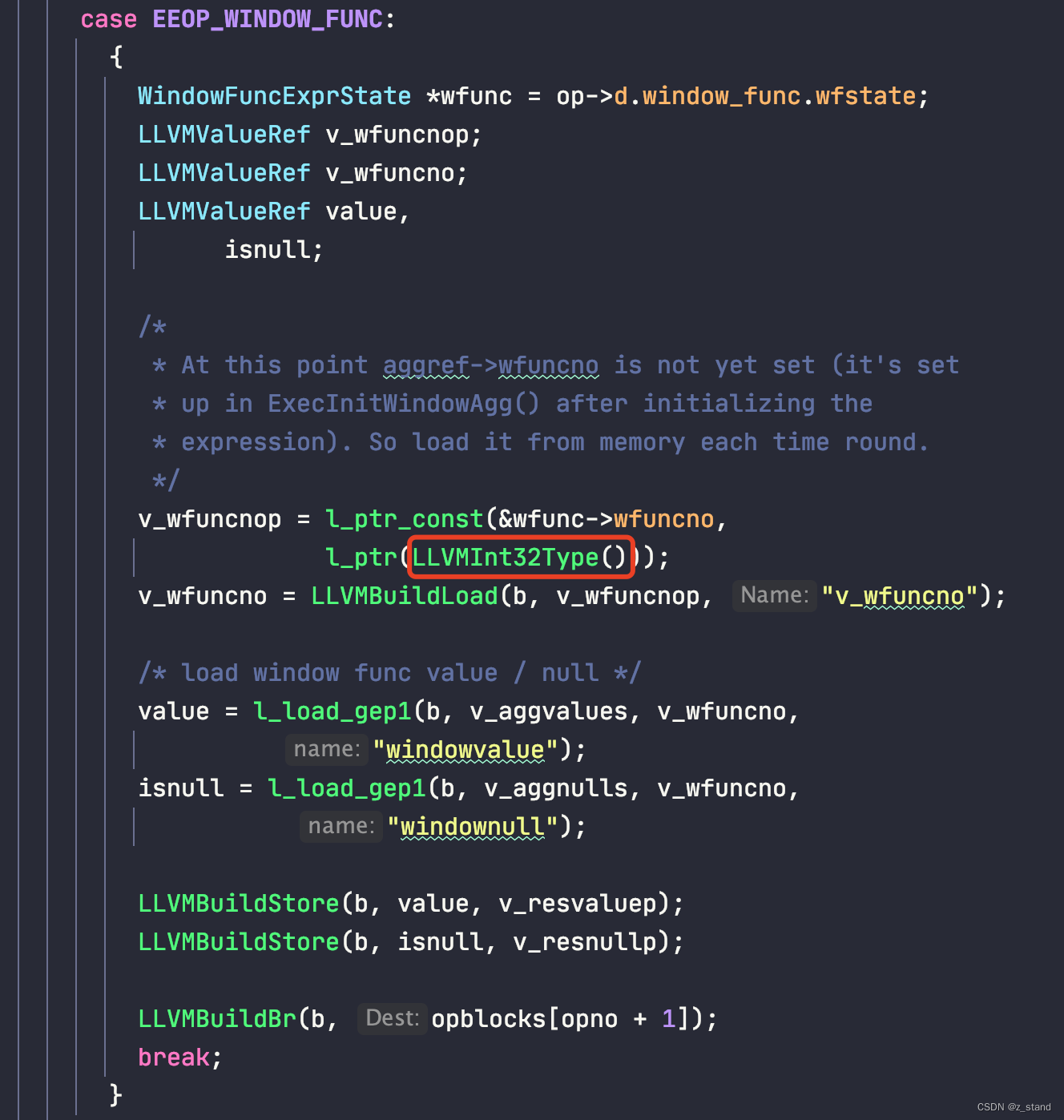
这是处理 查询表达式中包含窗口函数的类型,原本的处理这个op 的代码如下:
大体逻辑就是将 ExprConext econtext中保存的 窗口函数计算结果按照窗口函数的编号保存到当前op对应的返回值中,这个返回值会存储到 ExprState里面,原始代码看起来很简单,但是要转为IR的 Instruct 表示形式需要很多对Type的细节处理。
-
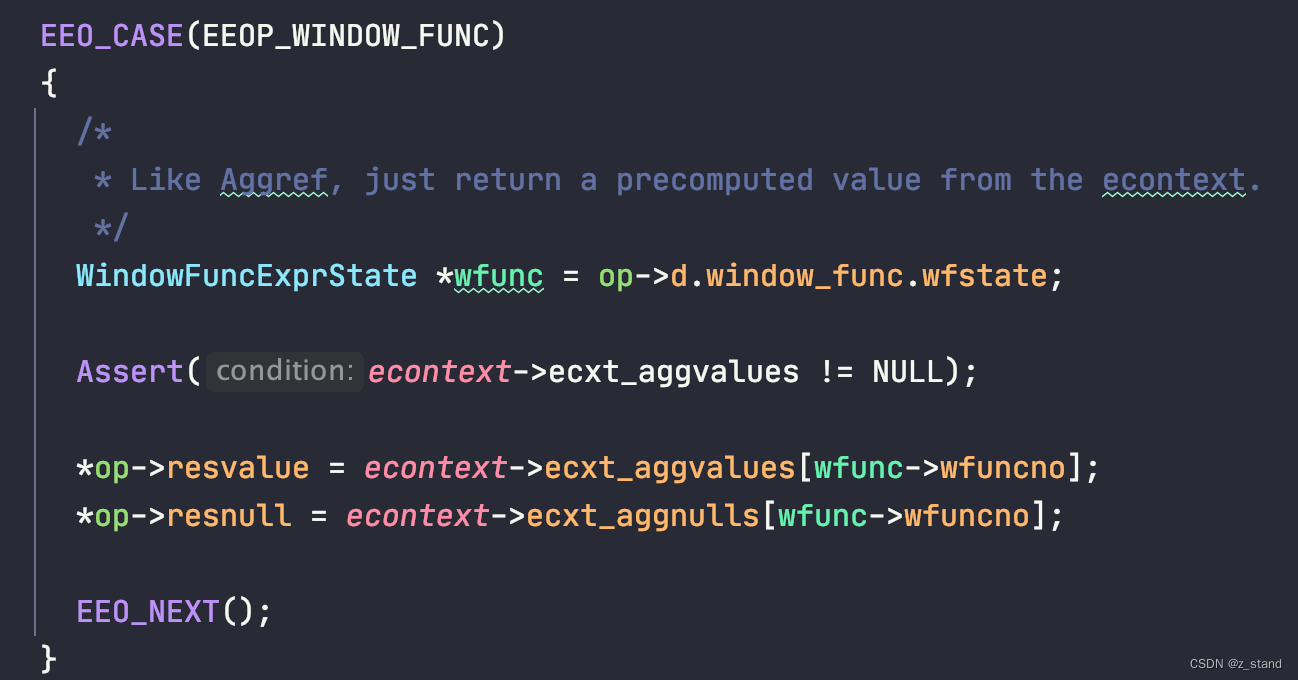
在JIT过程中,执行期间已经知道了
wfuncno的具体值,通过l_ptr_const从内存中拿出wfuncno的值。其中的wfuncno的类型为 int,所以需要指定 构造 PointerType 指针的元素类型为LLVMInt32Type。在l_ptr_const中构造LLVMConstInt的类型一定是TypeSizeT,前面展示bitcode中的TypeSizeT是 i64 + align8,所有平台都通用的,需要明确指定这个类型。 -
从内存拿到
wfuncno值且放在v_wfuncnop之后需要在 builder中创建一个 pointer<—>name 的type映射,或者说 建立Value <--> Type的联系,保证每一个 需要访问数值的 instruction 都有有效的可访问的类型。这个builder 会将构造的这个op的IR表示 存储到每一步的 opblocks数组(其实保存的就是执行步骤转换后的 BasicBlock,最后opblocks会存储到module中;放在ll文件中,就是我们经常看到的
b.op.xxx.start)。 -
接下来的 两个
l_load_gep1就是从提前构造好的结构体数组v_aggvalues,v_aggnulls中拿对应v_wfuncno下标的值。 -
LLVMBuildStore将拿到的v_aggvalues中的一个值存储到v_resvaluep中。 -
LLVMBuildBr(b, opblocks[opno + 1]);将构造好的 br 存储到 opblocks数组中,表示当前表达式的执行step。
第三、第四步是紧密关联的,很多人在使用 llvm 接口构造代码的IR表示的时候 types这里很容易出问题,包括 upstream 维护jit 代码的 committer Andres Freund 也承认这块很容易出错,需要很小心的处理type问题。
首先,v_resvaluep 保存的是表达式执行的返回值,在整个llvm_compile_expr 函数最开始的时候就已经明确了其 Type 为 TypeSizeT,在 LLVMBuildStore的实现中会做如下检查:
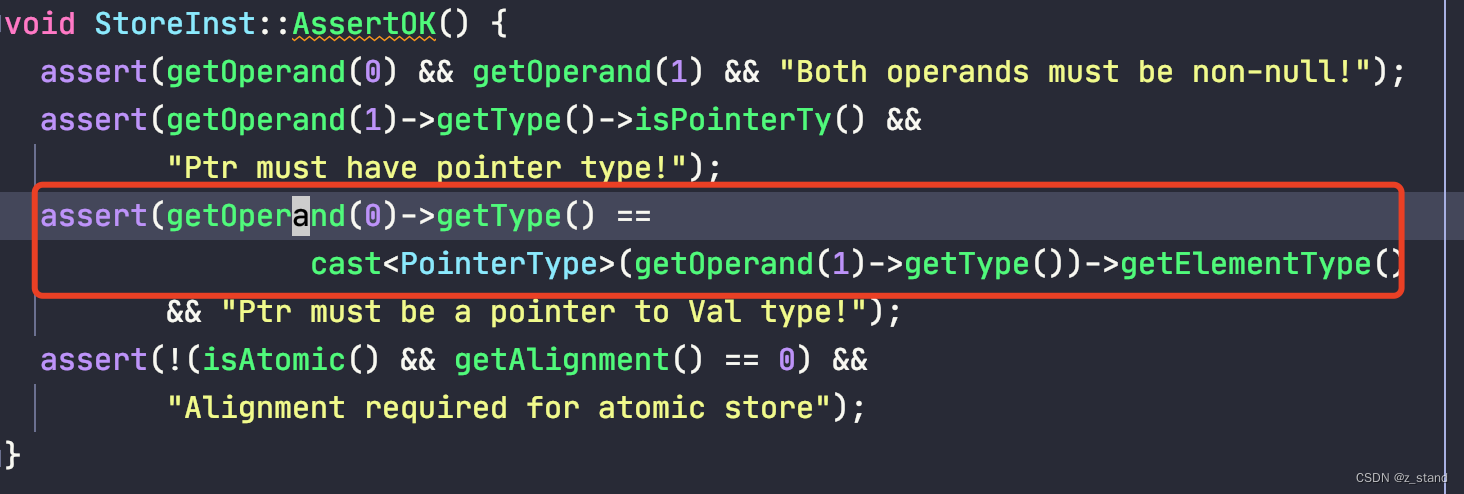
其中getOperand(0) 对应的是输入参数value,getOperand(1)对应的输入参数是v_resvaluep,要求value的类型和v_resvaluep的elementType类型相同, 所以后续所有想要存储到 v_resvaluep 中的 llvm::Value 类型都应该是 TypeSizeT,否则就会 crash。
当然,这里的约束也很容易理解,这并不是我们高级语言可以将 int32 的变量存储到 int64之中,这块的代码是编译器层级直接转为了IR 的 Instruction 部分,后续就直接和 llvm 的 backend交互了,instruction表示的这一些操作指令需要明确访问的边界,数值存储占用的bits到底是64还是32,不然从内存/寄存器中读取的数值位数是没有办法确定的。
LLVM Types 设计导致的 PG JIT 内存问题分析
前面用一个小的 案例描述了使用 llvm 的接口如何构造一个 basicblock的 IR表示,其中也描述了对 llvm::Types的基本使用。
接下来我们从 LLVM 代码角度看一下 llvm::Type 如何被存储到内存中的,选择一个清晰的入口,就是 llvmjit_types.bc的加载过程,它被用来生成我们JIT 过程需要的类型。
入口是:LLVMParseBitcode2,两个输入参数分别是 llvmjit_types.bc文件路径 以及 llvm_types_module变量。
先看一个从代码中梳理出来一个简单读取并解析bitcode 文件的流程链路:
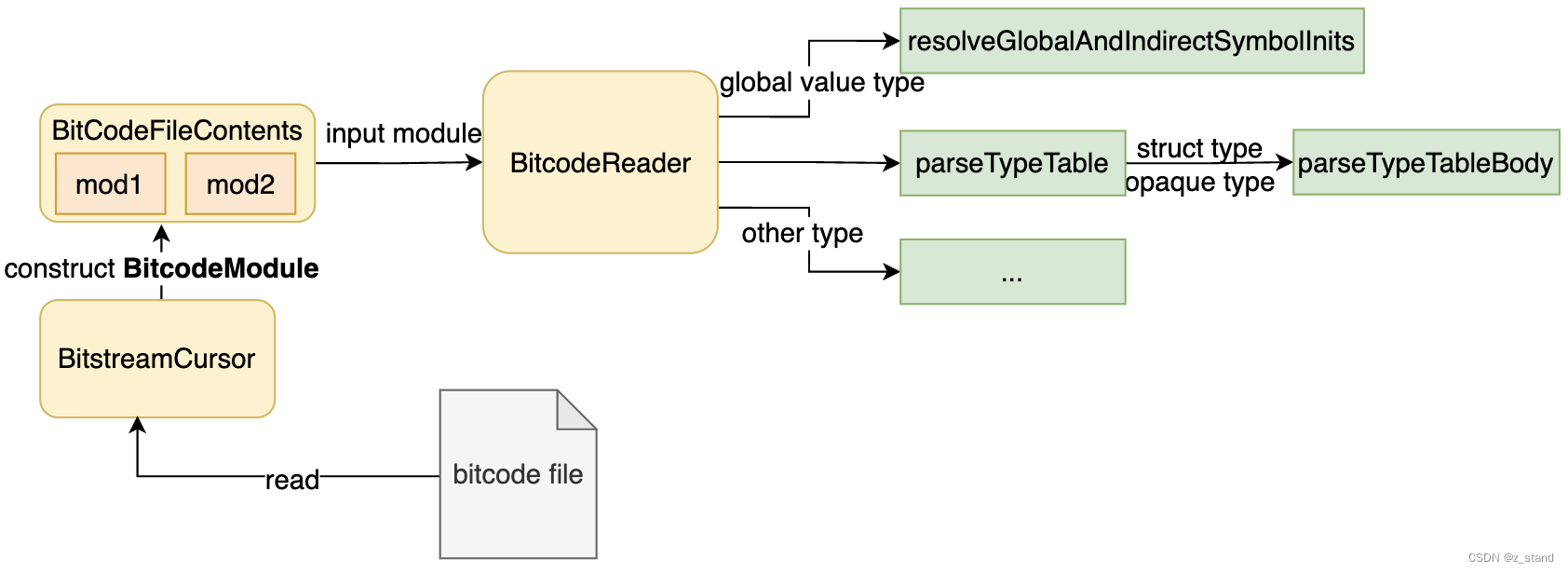
黄色的部分都对应类结构,绿色则是function。
通过 BitcodeWriter 生成bitcode 文件则是在clang编译期间完成的;读取过程暂且抛开代码的大体步骤如下:
- 利用
BitstreamCursor从bitcode 文件中读取数据流,并生成BitcodeModule对象填充给BitcodeFileContents中维护的 mod数组。 - 拿到了当前要解析的 bitcode file的所有mod,构造一个
BitcodeReader对BitcodeModule进行解析,按照其中BitstreamEntry的类型 以及 entry 对应的ID 做相应的解析。其中对于 bitcode file中的opaquetype 以及structtype 是通过上图中的对应函数来解析的,还有全局变量的解析。
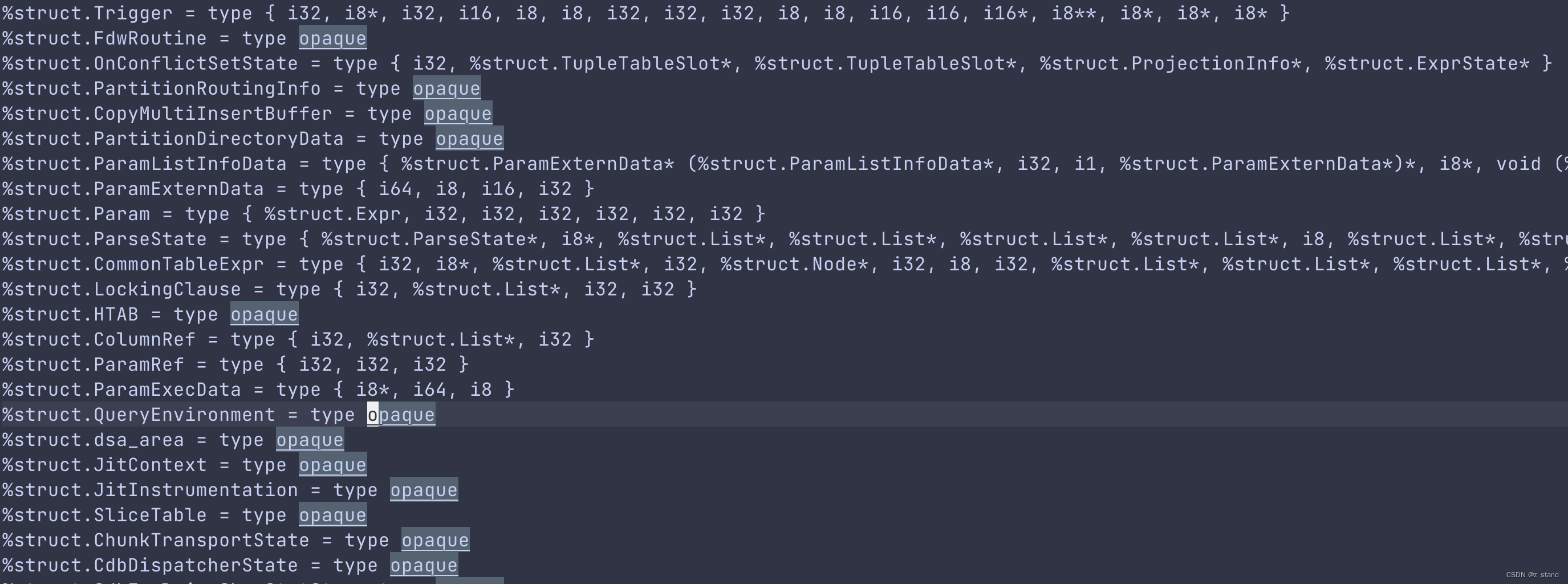
比如下图中的bitcode文件中就有标识 opaque type以及 struct type
 全局变量是在bc 文件的末尾:
全局变量是在bc 文件的末尾:

完成解析的信息会填充到 用户外部传入的 Module之中。
以上只是基本流程的概述,但是想要看到内存问题的本质必须从代码层面来看。
我们的函数入口是 LLVMParseBitcode2,它会调用 LLVMParseBitcodeInContext2函数。
这里有一个非常重要的细节,这个函数 LLVMGetGlobalContext() 作为上面函数的一个参数,这是一个全局静态变量 static ManagedStatic<LLVMContext> GlobalContext ,是一个 LLVM 内部极为重要的一个类: LLVMContext 。
它管理了 LLVM 内核中的核心的可以被全局使用的数据结构,其中就包括 各种types 的存储,allocator。
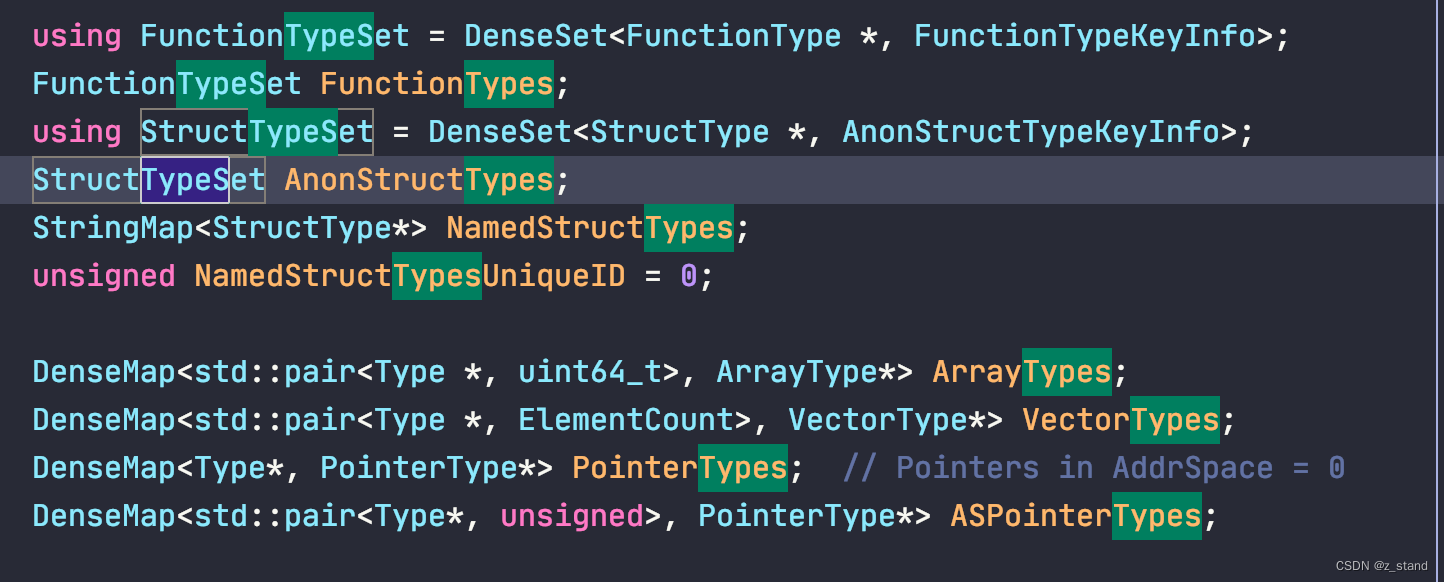
而且需要注意的是 GlobalContext 的声明是 static ManagedStatic<LLVMContext>,首先是整个进程只有一个这个实例,而且LLVMContext 并不是线程安全的,对其的访问和更改需要由使用者自己保障(如果大家要用的话)。此外,ManagedStatic的作用是对于声明的对象延迟初始化(使用时,非编译时,类似懒汉模式),并且保证进程退出时对象所管理的资源能够被正常释放。
接下来的代码分析中大家就能看到 LLVMContext 如何参与其中:
回到LLVMParseBitcodeInContext2 函数中,后续的基本调用栈就很简单了
LLVMParseBitcodeInContext2
llvm::parseBitcodeFile
getSingleModule # 解析文件,从中获取 BitcodeModule
| llvm::getBitcodeModuleList
| llvm::getBitcodeFileContents # 构造 BitstreamCursor 读取文件
| readBlobInRecord
|
BitcodeModule::parseModule #解析 BitcodeModue 到用户传入的 Module
BitcodeModule::getModuleImpl
BitcodeReader::parseBitcodeInto
BitcodeReader::parseBitcodeInto
BitcodeReader::parseModule
...
BitcodeReader::parseTypeTable # 处理包括struct type/opaque type的类型
...
BitcodeReader::resolveGlobalAndIndirectSymbolInits # global value type
...
因为构造 BitcodeReader的时候 将上层传入的 GlobalContext 的引用也传给了 Context成员,所以在BitcodeReader 内部对 Context的一些操作也相当于是对 GlobalContext的操作了。
我们重点看一下 BitcodeReader::parseTypeTable 这个函数内部对 opaque 以及 struct类型的处理,他们的处理方式就是我们要关注的内存问题。
在 向下调用了一个层级 到函数 BitcodeReader::parseTypeTableBody之后,会进入到如下分支进行 struct type的加载:
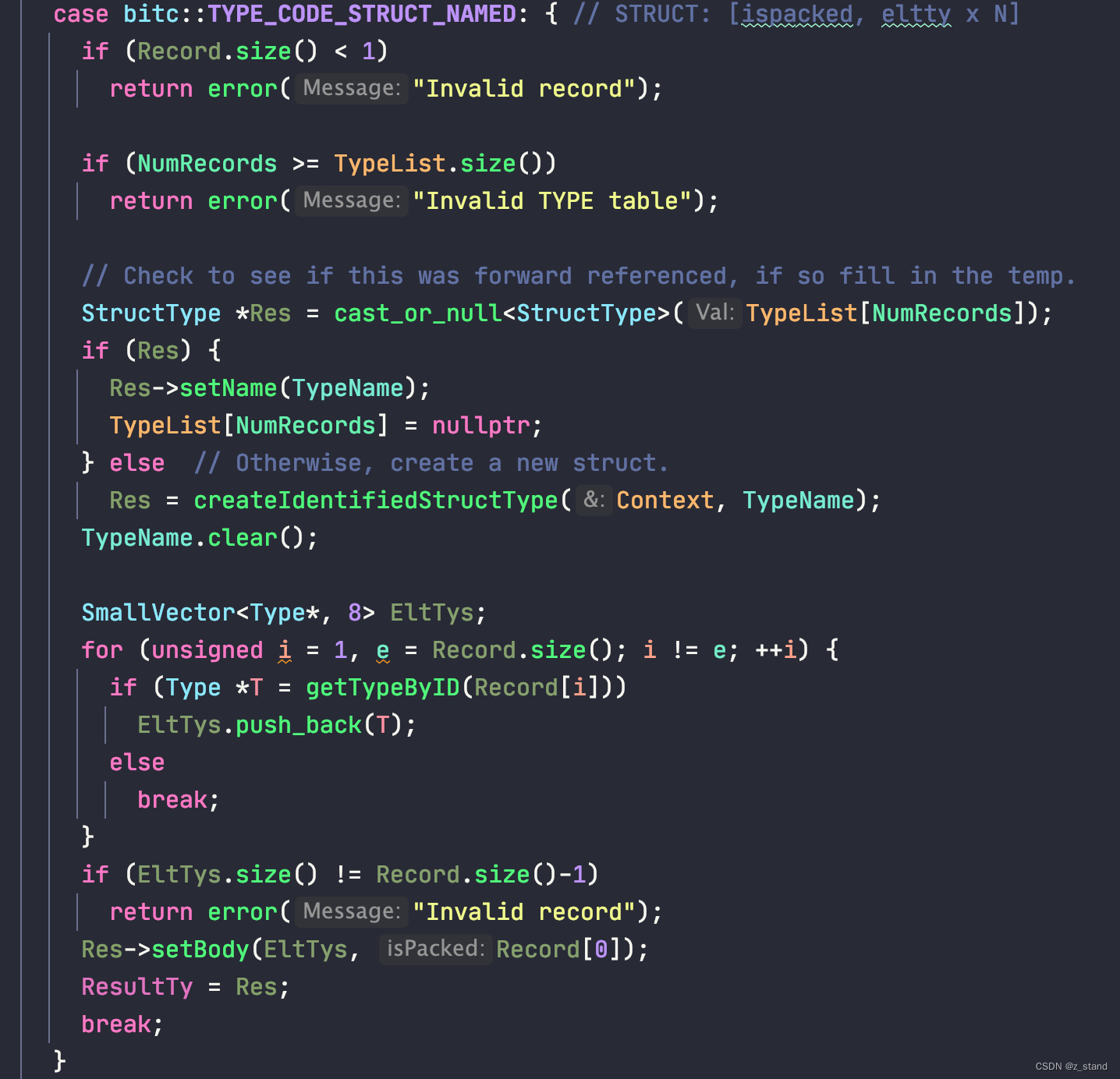
前面先加载这个类型到 StructType *Res中,后续再将这个结构体成员的表示存放到 EltTys数组。
如果 TypeList[NumRecords]是有效的,则直接调用 StructType::setName,否则重新创建一个 SturctType给Res。
1. 没有空间,重新创建
我们会带着 Context 进入到 createIdentifiedStructType函数中, 调用 StructType::create。
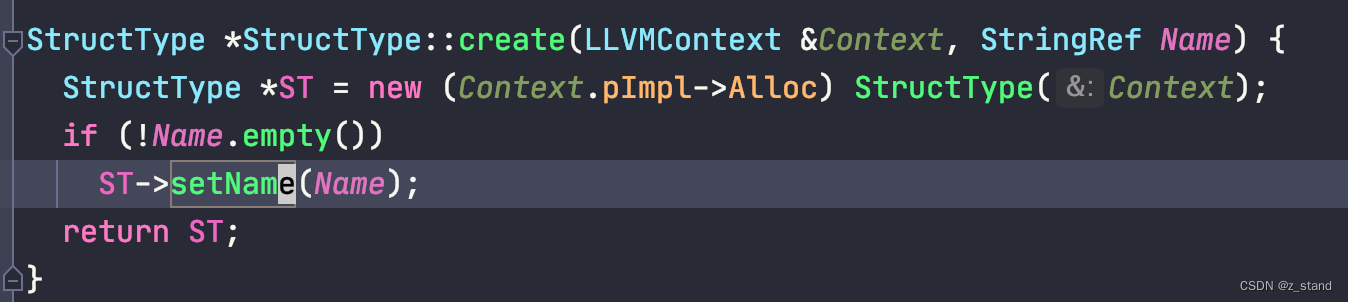
可以看到 当前 name 对应的 StructType 存储空间是从 Context的allocator中分配的,然后也通过 setName填充到一个地方。
2. 有空间,则直接通过 StructType::setName(StringRef Name) 填充。
两个过程的实现都需要 setName,它主要是将创建好的 StructType <--> Name 映射写入到 Context中 我们前面提到的保存types 的map中,但是其实现中下面的细节是直接导致内存问题的。
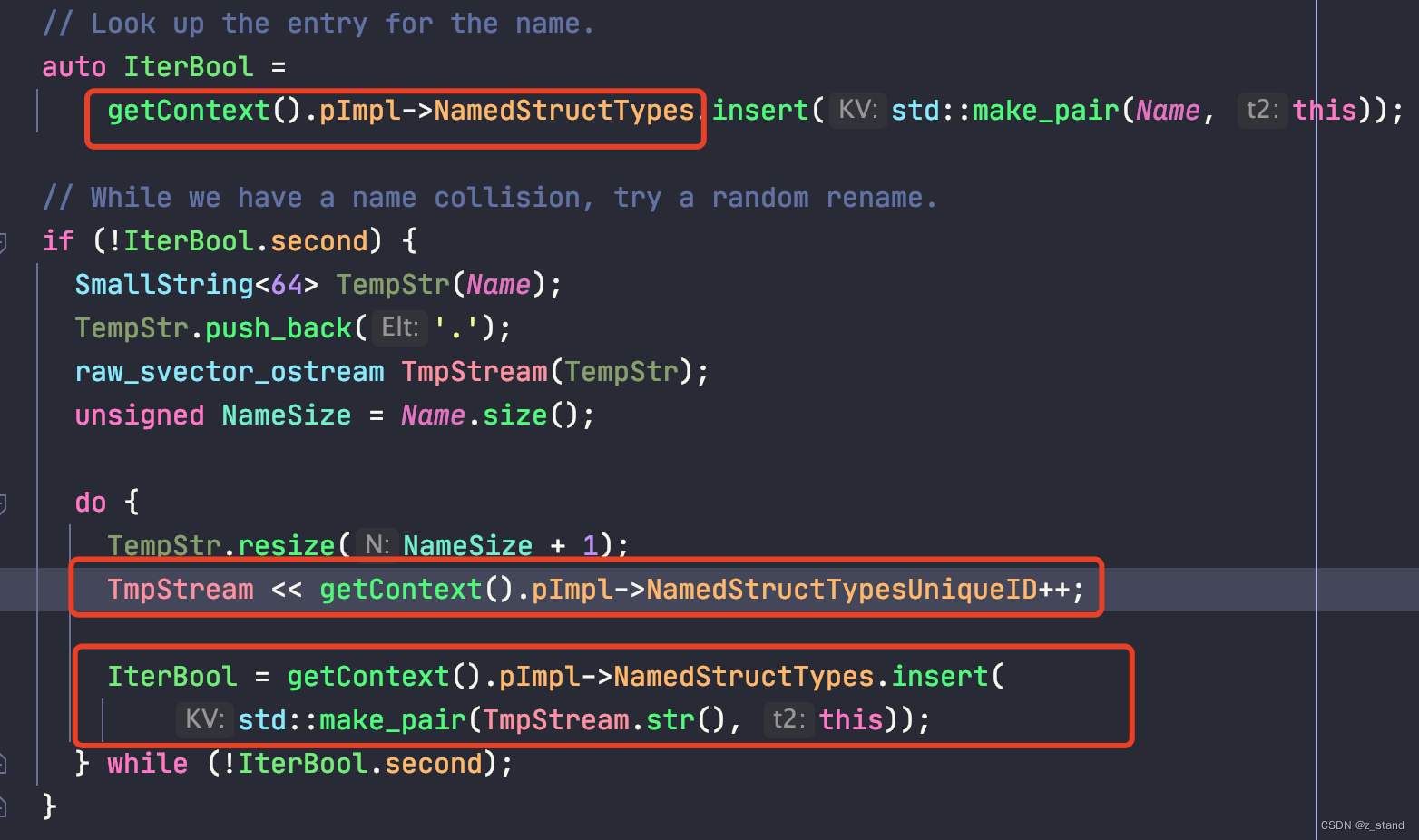
主要目的是想向 Context 也就是GlobalContext 中的 StringMap<StructType*> NamedStructTypes; 插入 <Name, this> pair。
插入之前会想尝试查找 StringMap 是否存在这个 Name,如果找到,则在原来的Name的基础上重新构造一个新的Name,再次尝试插入,直到插入成功。
到这里对于 types的加载就算完成了,但是内存问题可能很多人还没有完全理解。
- 当前PG JIT过程中 GlobalContext的声明周期是backend进程,进程不结束,
GlobalContext.pImpl->NamedStructTypes中占用的 types不会被释放。 - 对于重复的Types 并不会复用,而是直接生成新的。因为相同的name 代表的可能是不同的 this指针,比如不同的Module中调用了同一个function 中的某一个结构体类型,那因为Module不同,整个 parse链路生成的
StructType对象肯定也就不同,所以没有办法覆盖。 - 因为 Struct Types 不会被复用,意味着当我们一个backend进程调度了大量的query从而生成了大量的Module,PG JIT inline的过程就是对不同bitcode 文件中 function粒度的访问加载,一个query可能会有多个module,他们加载相同的function 生成的 types都不会被 GlobalContext释放,整个进程的内存只会持续缓慢上涨。
解决?
解决办法也是有的,请教了一下 LLVM社区 https://discourse.llvm.org/t/unexpected-memory-occupy-when-load-bitcode-module/66392/7 ,建议是自管理 LLVMContext ,并且每一个 module对应一个LLVMContext,就不会有内存问题了。然后 upstream 的也提到了,同样类似的方法,就是根据 inline执行的时间,间隔一段时间将 LLVMContext销毁,再重新创建一个新的。
但是这种解决办法与 JIT 加速的初衷就背道而驰了,如果JIT执行过程中或者每一个Module都有一个LLVMContext,我们在一个query内可能要多次销毁+创建 LLVMContext,意味着很多的全局变量types,function types 还有 LLVMContextImpl 中极多的其他资源都需要被析构并被重新创建加载,这个过程对性能的影响很大,肯定不会被采用。
upstream 提到的一个优雅的解决办法,就是 自己实现一个位于 bitcode 文件 以及 JIT IR 之间的缓存层,用来缓存被使用的types信息,包括 之前不同 Module之间无法统一的 types name以及 其StructType对象 ,让它们通过这个统一的缓存层能够 在整个 backend内部能够被统一起来,每一种type 只会被加载一次,然后就可以被所有的Module访问。
这个实现,客观来说还是需要对编译器的底层(Linker)部分有极为深入的理解,并且熟悉LLVM这块的实现。 Andres Freund 也说了,需要投入极多的时间在这块,相当于在 PostgreSQL 的JIT部分 实现了一个编译器中的Linker 组件,这样才能达到上面说的 types只会被访问一次的目的,到时候JIT这里的实现相比于现在可能会大变,主要是接口体系肯定会更为底层,逻辑也会更多。
就到这里吧 … 有时间再去学习一会 linker 的底层实现,到时候说不定能帮助 Andres Freund 修修bug 😃