ES使用聚合aggregations实战
- 聚合模板
- 桶聚合:Bucket Aggregations
- 指标聚合:Metrics Aggregations
- 管道聚合:Pipeline Aggregations
- 嵌套聚合
- 日期直方图:date-histogram
- 接口实战
- 接口一:根据stu_id分组统计时间段内的各个签到率出勤率迟到率等
- 接口二:某一stu_id去统计时间段内的课程签到情况
- 接口三:根据课程分组筛选获取满勤数和非满勤数
- 接口四:根据stu_id分组筛选获取满勤数和非满勤数
- 接口五:根据学院分组筛选获取top5和各学院学生平均出勤率
- 接口六:时间端筛选统计时间段内每一天的学生签到率
聚合模板
一般思路是先写出对应的es语句,再写java代码,首先介绍一下聚合的模板,具体细节可看
开源社区-伯乐马科技 ---- 第九章:聚合搜索(Aggregations)
桶聚合:Bucket Aggregations
GET <index_name>/_search
{
"aggs": {
"<aggs_name>": { // 聚合名称需要自己定义
"<agg_type>": {
"field": "<field_name>"
}
}
}
}
aggs_name:聚合函数的名称
agg_type:聚合种类,比如是桶聚合(terms)或者是指标聚合(avg、sum、min、max等)
field_name:字段名称或者叫域名。
多字段聚合Multi Terms
GET /<index_name>/_search
{
"aggs": {
"agg_name": {
"multi_terms": {
"terms": [
{
"field": "field_1"
},
{
"field": "field_2"
}
]
}
}
}
}
指标聚合:Metrics Aggregations
将上述的trems换成指标聚合的函数,有下:
平均值:Avg
最大值:Max
最小值:Min
求和:Sum
详细信息:Stats
数量:Value count
管道聚合:Pipeline Aggregations
GET <index_name>/_search
{
"aggs": {
"my_aggs": {
"<function>": {
...
},
"aggs": {
"my_price_bucket": {
...
}
}
},
"my_min_bucket":{
"<pip_function>": {
"buckets_path": "my_aggs>price_bucket"
}
}
}
}
注:buckets_path:路径相对于管道聚合的位置,不是绝对路径,路径不能返回“向上”的路径
Min bucket:最小桶
Max bucket:最大桶
Avg bucket:桶平均值
Sum bucket:桶求和
Stats bucket:桶信息
注意:buckets_path 为管道聚合的关键字,其值从当前聚合统计的聚合函数开始计算为第一级。比如下面例子中,my_aggs 和 my_min_bucket 同级,my_aggs 就是buckets_path 值的起始值。
嵌套聚合
GET <index_name>/_search
{
"aggs": {
"<agg_name>": {
"<agg_type>": {
"field": "<field_name>"
},
"aggs": {
"<agg_name_child>": {
"<agg_type>": {
"field": "<field_name>"
}
}
}
}
}
}
用途:用于在某种聚合的计算结果之上再次聚合,如统计不同类型商品的平均价格,就是在按照商品类型桶聚合之后,在其结果之上计算平均价格
日期直方图:date-histogram
GET product/_search?size=0
{
"aggs": {
"my_date_histogram": {
"date_histogram": {
"field": "createtime", #字段需为date类型
"<interval_type>": "month", #时间间隔的参数可选项
"format": "yyyy-MM", #日期的格式化输出
"extended_bounds": { #输出空桶
"min": "2020-01",
"max": "2020-12"
}
}
}
}
}
interval_type:时间间隔的参数可选项
fixed_interval:ms(毫秒)、s(秒)、 m(分钟)、h(小时)、d(天),注意单位需要带上具体的数值,如2d为两天。需要当心当单位过小,会导致输出桶过多而导致服务崩溃。
calendar_interval:year、quarter、month、week、day、hour、minute
在 8.x 版本中 interval 已弃用
missing:指定在日期字段缺失时,如何处理该时间段。
min_doc_count:指定在时间段内至少需要满足的文档数量才会包含在结果中。默认值为0,表示即使时间段内没有文档,也会返回结果。
time_zone:指定聚合操作中使用的时区。默认情况下,Elasticsearch使用服务器的时区设置。如:“time_zone”: “Asia/Shanghai”,
offset:指定聚合结果中时间段的偏移量。可以通过提供时间单位和数量来指定偏移量。例如,"+1h"表示时间段向后偏移1小时。
keyed:指定是否将结果按时间段的键值对形式返回。如果设置为true,每个时间段的结果将以键值对的形式返回,默认为false。
extended_bounds:指定自定义的时间范围。可以通过提供"min"和"max"参数来限制聚合操作的时间范围。
接口实战
**前提:**本文环境-
elasticsearch-7.16.3
kibana-7.16.3
elasticsearch-analysis-ik-7.16.3
logstash-7.16.3
pom.xml文件引入
<!-- Java Low Level REST Client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-client</artifactId>
<version>7.16.3</version>
</dependency>
<!-- Java High Level REST Client -->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.16.3</version>
</dependency>
同步表数据stu_sign学生签到记录表结构为
CREATE TABLE `stu_sign` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`create_date` datetime DEFAULT NULL,
`modify_date` datetime DEFAULT NULL,
`class_num_begin` varchar(32) DEFAULT NULL,
`class_num_end` varchar(32) DEFAULT NULL,
`classroom` varchar(128) DEFAULT NULL,
`classroom_id` int(11) DEFAULT NULL,
`course_id` int(11) DEFAULT NULL,
`course_name` varchar(256) DEFAULT NULL,
`course_sched_id` int(11) DEFAULT NULL,
`roll_call_date` datetime DEFAULT NULL,
`semester_id` int(11) DEFAULT NULL,
`sign_status` int(11) DEFAULT NULL,
`sing_date` datetime DEFAULT NULL,
`stu_id` int(11) DEFAULT NULL,
`stu_name` varchar(256) DEFAULT NULL,
`teach_time` datetime DEFAULT NULL,
`teach_time_str` varchar(32) DEFAULT NULL,
`teacher_id` int(11) DEFAULT NULL,
`teacher_name` varchar(256) DEFAULT NULL,
`roll_call_status` int(11) DEFAULT NULL,
`stu_num` varchar(64) DEFAULT NULL,
`stu_sign_status` int(11) DEFAULT NULL,
`academy_id` int(11) DEFAULT NULL,
`academy_superior_id` int(11) DEFAULT NULL,
`class_id` int(11) DEFAULT NULL,
`grade_id` varchar(50) DEFAULT NULL,
`class_begin_time` varchar(100) DEFAULT '',
`class_end_time` varchar(100) DEFAULT '',
`sign_type` int(11) DEFAULT NULL,
`appeal_msg` varchar(255) DEFAULT NULL,
`appeal_status` int(11) DEFAULT NULL,
`appeal_time` varchar(255) DEFAULT NULL,
`late_status` int(11) DEFAULT NULL,
`leave_status` int(11) DEFAULT NULL,
`absence_status` int(11) DEFAULT NULL COMMENT '1、事假 2、病假 3、公假',
`modify_userId` varchar(255) DEFAULT NULL COMMENT '修改人id',
`modify_userName` varchar(256) DEFAULT NULL COMMENT '修改人姓名',
`modify_time` varchar(100) DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
KEY `schedIdIndex` (`course_sched_id`) USING BTREE,
KEY `index_course_id` (`course_id`) USING BTREE,
KEY `index_course_sched_id` (`course_sched_id`) USING BTREE,
KEY `index_semester_id` (`semester_id`) USING BTREE,
KEY `index_sign_status` (`sign_status`) USING BTREE,
KEY `index_stu_id` (`stu_id`) USING BTREE,
KEY `index_teacher_id` (`teacher_id`) USING BTREE,
KEY `index_stu_num` (`stu_num`) USING BTREE,
KEY `index_class_num_begin` (`class_num_begin`) USING BTREE,
KEY `index_class_num_end` (`class_num_end`) USING BTREE,
KEY `class_begin_time_index` (`class_begin_time`),
KEY `class_end_time_index` (`class_end_time`),
KEY `class_id_index` (`class_id`),
KEY `teach_time_index` (`teach_time`),
KEY `class_begin_end_time_index` (`class_begin_time`,`class_end_time`,`teach_time`),
KEY `course_sched_id_stu_id_index` (`course_sched_id`,`stu_id`),
KEY `idx_stu_sign_class_begin_time_course_id_stu_id` (`class_begin_time`,`course_id`,`stu_id`)
) ENGINE=InnoDB AUTO_INCREMENT=7923 DEFAULT CHARSET=utf8;
在es中的kibana执行创建索引对应mapping,由于很多查询基于class_begin_time字段去做,但是在表结构中该字段存储为varchar,特殊的设置其mapping的type为date和format时间格式
稍微解释一下下面的配置文件:根据追踪日志的文件last_run_stu_login.txt中记录的时间,并根据字段modify_date去增量同步stu_sign表中的数据,并设置每五分钟同步一次
input {
jdbc {
# 配置数据库信息
jdbc_connection_string => "jdbc:mysql://188.18.66.185:3306/eschool?useUnicode=true&characterEncoding=UTF-8&serverTimezone=Asia/Shanghai"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_user => "root"
jdbc_password => "JYD.2015.internet"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
jdbc_default_timezone => "UTC"
# mysql驱动所在位置
jdbc_driver_library => "D:\environment\apache-maven-3.8.8\maven_repository\mysql\mysql-connector-java\8.0.27\mysql-connector-java-8.0.27.jar"
#sql执行语句
statement => "SELECT * FROM `stu_sign` WHERE modify_date > :sql_last_value AND modify_date < NOW() "
use_column_value => true
tracking_column => "modify_date"
tracking_column_type => "timestamp"
last_run_metadata_path => "E:\software\logstash\logstash-7.16.3\conf\metadata\last_run_stu_login.txt"
schedule => "*/5 * * * *"
lowercase_column_names => false
}
}
output {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "stu_sign"
document_id => "%{id}"
}
stdout {
codec => json_lines
}
}
在logstash文件下bin目录下启动命令
logstash.bat -f E:\software\logstash\logstash-7.16.3\conf\stu_sign.conf
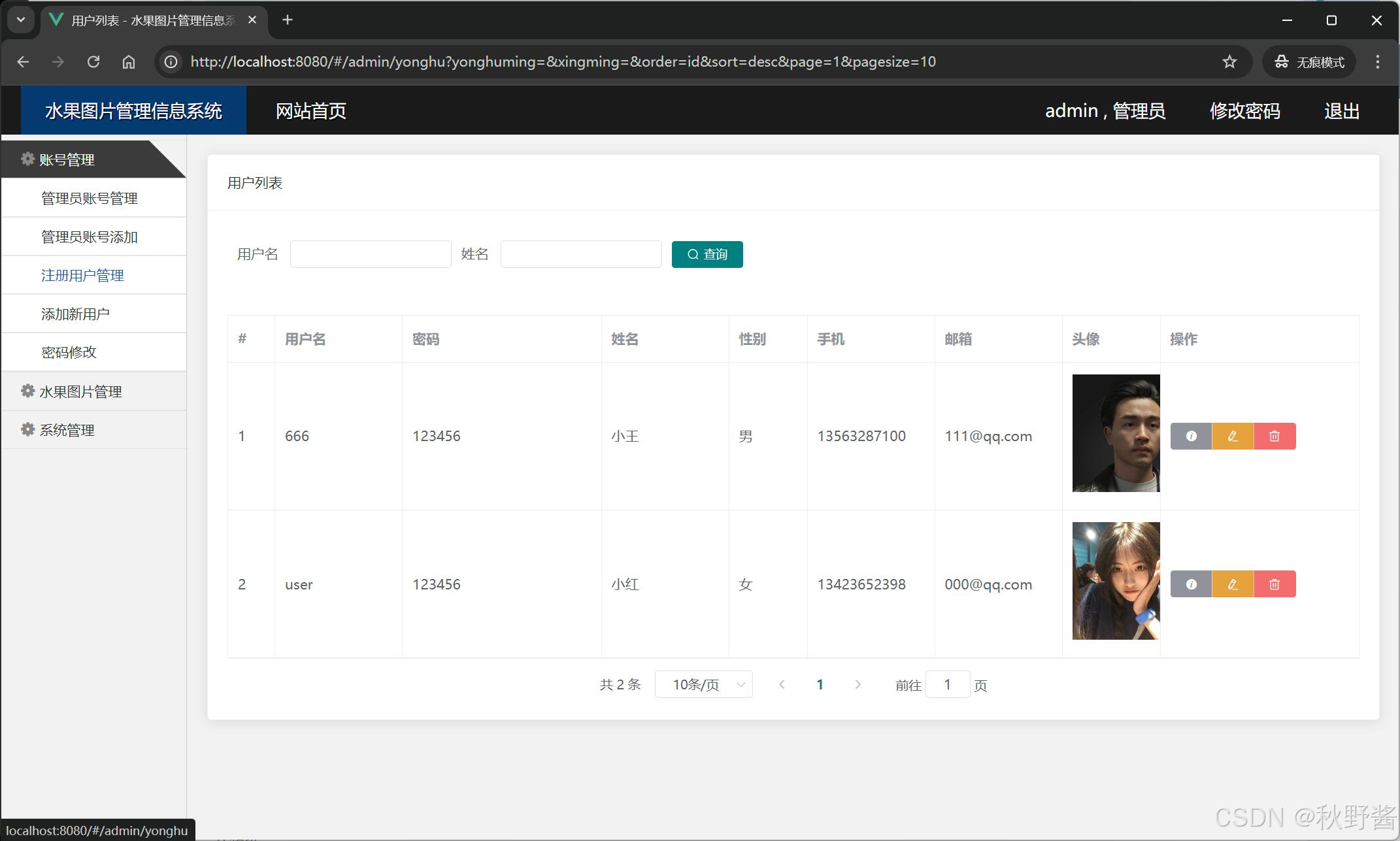
接口一:根据stu_id分组统计时间段内的各个签到率出勤率迟到率等
需求:根据stu_id分组统计时间段内的各个签到率出勤率迟到率等
完成分页操作和统计结果按照缺勤率降序排序

对应mapper.xml方法中的sql代码为
<select id="getStuAttendanceListJson" resultType="java.util.Map">
SELECT
ifnull(a.NAME,'') AS college_name,
s.stu_id,
s.stu_num,
s.stu_name,
count( s.id ) AS total_num,(
ifnull( sum( sign_status ), 0 )- ifnull( sum( late_status ), 0 )) AS yes_num,
ifnull( sum( late_status ), 0 ) AS late_num,(
count( s.id )- ifnull( sum( sign_status ), 0 )) AS no_num,
FORMAT((( ifnull( sum( sign_status ), 0 )- ifnull( sum( late_status ), 0 ))/ count( s.id )* 100 ), 1 ) AS
yes_lv,
FORMAT(( ifnull( sum( late_status ), 0 )/ count( s.id )* 100 ), 1 ) AS late_lv,
FORMAT((( count( s.id )- ifnull( sum( sign_status ), 0 ))/ count( s.id )* 100 ), 1 ) AS no_lv
FROM
eschool.stu_sign s
LEFT JOIN eschool.USER u ON s.stu_id = u.id
LEFT JOIN eschool.academy a ON a.id = u.academy_id
WHERE
s.class_begin_time < now()
<if test="t.collegeId!=null and t.collegeId!=''">
and u.academy_id = #{t.collegeId}
</if>
<if test="t.beginDate!=null and t.beginDate!=''">
and s.class_begin_time > CONCAT(#{t.beginDate},' 00:00:01')
</if>
<if test="t.endDate!=null and t.endDate!=''">
and s.class_begin_time < CONCAT(#{t.endDate},' 23:59:59')
</if>
<if test="t.keyWord!=null and t.keyWord!=''">
and (s.stu_num like concat('%',#{t.keyWord},'%') or s.stu_name like concat('%',#{t.keyWord},'%'))
</if>
GROUP BY s.stu_id ORDER BY (( ifnull(sum(sign_status), 0) - ifnull(sum(late_status), 0)) / count(s.id)) DESC
</select>
java实现代码如下:(待优化:使用bucket_sort进行桶排序然后再from size)
public BaseResponse getStuAttendanceListJson(UserSignRequest requestParam) {
Map<String, Object> result = new HashMap<>();
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lt("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
timeRangeQuery.gte(requestParam.getBeginDate()+" 00:00:00")
.lte(requestParam.getEndDate()+" 23:59:59");
}
boolQueryBuilder.must(timeRangeQuery);
if (requestParam.getCollegeId() != null) {
boolQueryBuilder.must(QueryBuilders.termQuery("academy_id", requestParam.getCollegeId()));
}
// 关键词查询
if (StringUtils.isNotBlank(requestParam.getKeyWord())) {
BoolQueryBuilder keywordQuery = QueryBuilders.boolQuery()
.should(QueryBuilders.wildcardQuery("stu_name.keyword", "*"+requestParam.getKeyWord()+"*"))
.should(QueryBuilders.wildcardQuery("stu_num.keyword", "*"+requestParam.getKeyWord()+"*"))
.minimumShouldMatch(1);
boolQueryBuilder.must(keywordQuery);
}
searchSourceBuilder.query(boolQueryBuilder);
TopHitsAggregationBuilder topHits = AggregationBuilders.topHits("student_info")
.size(1)
.fetchField("stu_num")
.fetchField("stu_name")
.fetchField("academy_id");
// 构建聚合
TermsAggregationBuilder aggregation = AggregationBuilders.terms("group_by_stu_id")
.field("stu_id")
.size(10000) // 根据实际情况调整
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(topHits);
searchSourceBuilder.aggregation(aggregation);
searchSourceBuilder.size(0);
// 执行查询
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
// 处理聚合结果
Map<String, Object> academyNameMap = getAcademyNameMap();
List<Map<String, Object>> attendanceList = new ArrayList<>();
Terms terms = response.getAggregations().get("group_by_stu_id");
for (Terms.Bucket bucket : terms.getBuckets()) {
Map<String, Object> item = new HashMap<>();
item.put("stu_id", bucket.getKeyAsString());
SearchHit student_info = ((ParsedTopHits) bucket.getAggregations().get("student_info")).getHits().getHits()[0];
item.put("stu_num", student_info.getDocumentFields().get("stu_num").getValue());
item.put("stu_name", student_info.getDocumentFields().get("stu_name").getValue());
if(student_info.getDocumentFields().get("academy_id") != null){
String academyId = student_info.getDocumentFields().get("academy_id").getValue().toString();
item.put("college_id", academyId);
item.put("college_name",academyNameMap.getOrDefault(academyId,""));
}
item.put("total_num", bucket.getDocCount());
Sum sumSign = bucket.getAggregations().get("sum_sign");
Sum sumLate = bucket.getAggregations().get("sum_late");
double sign = sumSign.getValue();
double late = sumLate.getValue();
item.put("yes_num", (int) (sign - late));
item.put("late_num", (int) late);
item.put("no_num", (int) (bucket.getDocCount() - sign));
BigDecimal yesLv = new BigDecimal((sign - late) / bucket.getDocCount() * 100);
BigDecimal lateLv = new BigDecimal(late / bucket.getDocCount() * 100);
BigDecimal noLv = new BigDecimal((bucket.getDocCount() - sign) / bucket.getDocCount() * 100);
DecimalFormat df = new DecimalFormat("#.0");
item.put("yes_lv", yesLv.compareTo(BigDecimal.ZERO) == 0 ? "0.0" : df.format(yesLv));
item.put("late_lv", lateLv.compareTo(BigDecimal.ZERO) == 0 ? "0.0" : df.format(lateLv));
item.put("no_lv", noLv.compareTo(BigDecimal.ZERO) == 0 ? "0.0" : df.format(noLv));
attendanceList.add(item);
}
// 按正常签到率排序,如果正常签到率一样,按照stu_id升序
attendanceList = attendanceList.stream()
.sorted((o1, o2) -> {
double yesLv1 = Double.parseDouble(o1.get("yes_lv").toString());
double yesLv2 = Double.parseDouble(o2.get("yes_lv").toString());
if (yesLv1 != yesLv2) {
return Double.compare(yesLv2, yesLv1);
} else {
return ((String) o1.get("stu_id")).compareTo((String) o2.get("stu_id"));
}
})
.collect(Collectors.toList());
result.put("total_count", attendanceList.size());
int pages = (int) Math.ceil((double) attendanceList.size() / requestParam.getPageSize());
result.put("total_pages",pages);
result.put("size",requestParam.getPageSize());
//截取list
attendanceList = attendanceList.subList((requestParam.getPage() - 1) * requestParam.getPageSize(), Math.min(requestParam.getPage() * requestParam.getPageSize(), attendanceList.size()));
result.put("list", attendanceList);
return BaseResponseBuilder.success(result);
} catch (Exception e) {
return BaseResponseBuilder.failure("查询失败",e.getMessage());
}
}
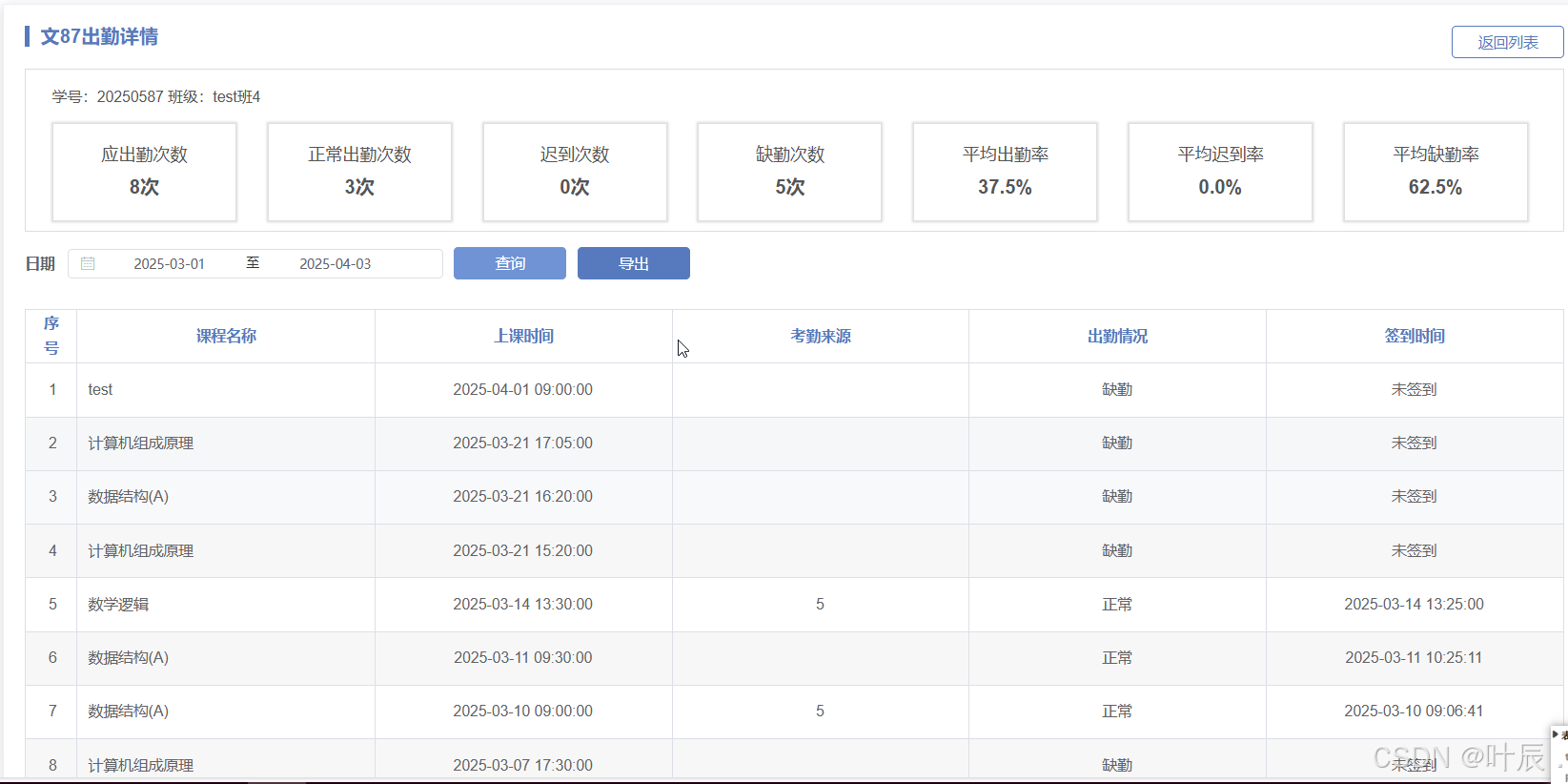
接口二:某一stu_id去统计时间段内的课程签到情况
相比1已经简单许多了
SELECT
count( 1 ) AS total_num,(
ifnull( sum( sign_status ), 0 )- ifnull( sum( late_status ), 0 )) AS yes_num,
ifnull( sum( late_status ), 0 ) AS late_num,
(
count( s.id )- ifnull( sum( sign_status ), 0 )) AS no_num,
FORMAT((( ifnull( sum( sign_status ), 0 )- ifnull( sum( late_status ), 0 ))/ count( s.id )* 100 ), 1 ) AS
yes_lv,
FORMAT(( ifnull( sum( late_status ), 0 )/ count( s.id )* 100 ), 1 ) AS late_lv,
FORMAT((( count( s.id )- ifnull( sum( sign_status ), 0 ))/ count( s.id )* 100 ), 1 ) AS no_lv
FROM
eschool.stu_sign s
WHERE
s.stu_id = #{t.userId}
AND s.class_begin_time < now()
<if test="t.beginDate!=null and t.beginDate!=''">
and s.class_begin_time > CONCAT(#{t.beginDate},' 00:00:01')
</if>
<if test="t.endDate!=null and t.endDate!=''">
and s.class_begin_time < CONCAT(#{t.endDate},' 23:59:59')
</if>
java代码如下
public BaseResponse getStuAttendanceDeatilsByStudentId(UserSignDetailRequest requestParam) {
Map<String, Object> result = new HashMap<>();
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
CountRequest countRequest = new CountRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
boolQueryBuilder.must(QueryBuilders.termQuery("stu_id", requestParam.getUserId()));
searchSourceBuilder.query(boolQueryBuilder);
countRequest.source(searchSourceBuilder);
CountResponse countResponse = restHighLevelClient.count(countRequest, RequestOptions.DEFAULT);
long total = countResponse.getCount();
// 指定返回字段
searchSourceBuilder.fetchSource(new String[]{
"course_name", "class_begin_time", "class_end_time", "sign_status", "late_status", "sign_type" ,"sing_date"
}, null);
// 分页参数
if (requestParam.getPage() != 0 && requestParam.getPageSize() != 0) {
searchSourceBuilder.from((requestParam.getPage() - 1) * requestParam.getPageSize());
searchSourceBuilder.size(requestParam.getPageSize());
}
searchSourceBuilder.sort("class_begin_time", SortOrder.DESC);
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
List<Map<String, Object>> details = new ArrayList<>();
for (SearchHit hit : response.getHits().getHits()) {
Map<String, Object> item = new HashMap<>();
item.put("course_name", hit.getSourceAsMap().get("course_name"));
item.put("class_begin_time", hit.getSourceAsMap().get("class_begin_time"));
item.put("class_end_time", hit.getSourceAsMap().get("class_end_time"));
//完善sing_date、sing_status、sign_type
if(hit.getSourceAsMap().get("sign_status")!=null && hit.getSourceAsMap().get("sign_status").equals("1")){
item.put("sing_date", hit.getSourceAsMap().get("sing_date"));
}
if(hit.getSourceAsMap().get("late_status")!=null && hit.getSourceAsMap().get("late_status").equals("1")){
item.put("sing_status", 2+"");
}else{
item.put("sing_status", hit.getSourceAsMap().get("sing_status"));
}
item.put("sign_type", hit.getSourceAsMap().get("sign_type")==null?"":hit.getSourceAsMap().get("sign_type"));
details.add(item);
}
result.put("total_count", response.getHits().getTotalHits().value);//注:这个值最大为10000
int pages = (int) Math.ceil((double) response.getHits().getTotalHits().value / requestParam.getPageSize());
result.put("total_pages",pages);
result.put("size",requestParam.getPageSize());
result.put("list", details);
Map<String, Object> stuAttendanceListJsonByStuIdMap = getStuAttendanceListJsonByStuIdMap(requestParam);
result.put("stu_id", stuAttendanceListJsonByStuIdMap.get("stu_id"));
result.put("total_num", stuAttendanceListJsonByStuIdMap.get("total_num"));
result.put("yes_num", stuAttendanceListJsonByStuIdMap.get("yes_num"));
result.put("late_num", stuAttendanceListJsonByStuIdMap.get("late_num"));
result.put("no_num", stuAttendanceListJsonByStuIdMap.get("no_num"));
result.put("yes_lv", stuAttendanceListJsonByStuIdMap.get("yes_lv"));
result.put("late_lv", stuAttendanceListJsonByStuIdMap.get("late_lv"));
result.put("no_lv", stuAttendanceListJsonByStuIdMap.get("no_lv"));
return BaseResponseBuilder.success(result);
} catch (Exception e) {
return BaseResponseBuilder.failure("查询失败", e.getMessage());
}
}
接口三:根据课程分组筛选获取满勤数和非满勤数
对应的sql(满勤数)(也可以使用case操作用一条sql统计出两个数)
SELECT
count( 1 ) AS course_yes_num
FROM
(
SELECT
FORMAT( ifnull((( ifnull( sum( sign_status ), 0 ))/ count( s.id )* 100 ), 0 ), 1 ) AS yes_lv
FROM
eschool.stu_sign s
<where>
AND s.class_begin_time < now()
<if test="t.beginDate!=null and t.beginDate!=''">
and s.class_begin_time > CONCAT(#{t.beginDate},' 00:00:01')
</if>
<if test="t.endDate!=null and t.endDate!=''">
and s.class_begin_time < CONCAT(#{t.endDate},' 23:59:59')
</if>
<if test="t.dormId!=null and t.dormId!=''">
and s.classroom_id in (select id from eschool.class_room where uuid in(${t.dormId}))
</if>
</where>
GROUP BY s.course_id ) t
where t.yes_lv='100.0'
java代码
public Long getCourseYesNumByES(SchoolReportRequest requestParam){
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
if(StringUtils.isNotBlank(requestParam.getDormId())){
List<String> classroomIds = attendanceMapper.getClassroomIdByDormId(requestParam.getDormId());
boolQueryBuilder.must(QueryBuilders.termsQuery("classroom_id.keyword", classroomIds));
}
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(0);
// 聚合:统计课程出勤百分比
Map<String, String> bucketsPathsMap = new HashMap<>();
bucketsPathsMap.put("sum_sign", "sum_sign");
bucketsPathsMap.put("count_total", "count_total");
TermsAggregationBuilder courseAgg = AggregationBuilders.terms("perfect_courses")
.field("course_id")
.size(10000) // 根据实际课程数量调整
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(AggregationBuilders.count("count_total").field("id"))
.subAggregation(PipelineAggregatorBuilders.bucketScript("attendance_percentage",bucketsPathsMap,
new Script(" params.sum_sign / params.count_total * 100")
));
Map<String, String> pipelineBucketsPathsMap = new HashMap<>();
pipelineBucketsPathsMap.put("attendance_percent", "attendance_percentage");
//管道聚合筛选
courseAgg.subAggregation(PipelineAggregatorBuilders.bucketSelector("attendance_percentage_100_filter",pipelineBucketsPathsMap,
new Script("params.attendance_percent == 100.0")));
searchSourceBuilder.aggregation(courseAgg);
//管道聚合(最大值、平均值、最小值。。。)
searchSourceBuilder.aggregation(PipelineAggregatorBuilders
.statsBucket("attendance_percentage_100_count","perfect_courses._count"));
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
ParsedStatsBucket attendancePercentage100Count = aggregations.get("attendance_percentage_100_count");
return attendancePercentage100Count.getCount();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
public Long getCourseNoNumByES(SchoolReportRequest requestParam){
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
if(StringUtils.isNotBlank(requestParam.getDormId())){
List<String> classroomIds = attendanceMapper.getClassroomIdByDormId(requestParam.getDormId());
boolQueryBuilder.must(QueryBuilders.termsQuery("classroom_id", classroomIds));
}
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(0);
// 聚合:统计课程出勤百分比
Map<String, String> bucketsPathsMap = new HashMap<>();
bucketsPathsMap.put("sum_sign", "sum_sign");
bucketsPathsMap.put("count_total", "count_total");
TermsAggregationBuilder courseAgg = AggregationBuilders.terms("perfect_courses")
.field("course_id")
.size(10000) // 根据实际课程数量调整
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(AggregationBuilders.count("count_total").field("id"))
.subAggregation(PipelineAggregatorBuilders.bucketScript("attendance_percentage",bucketsPathsMap,
new Script(" params.sum_sign / params.count_total * 100")
));
//管道聚合筛选
Map<String, String> pipelineBucketsPathsMap = new HashMap<>();
pipelineBucketsPathsMap.put("attendance_percent", "attendance_percentage");
//管道聚合筛选
courseAgg.subAggregation(PipelineAggregatorBuilders.bucketSelector("attendance_percentage_100_filter",pipelineBucketsPathsMap,
new Script("params.attendance_percent < 100.0")));
searchSourceBuilder.aggregation(courseAgg);
//管道聚合(最大值、平均值、最小值。。。)
searchSourceBuilder.aggregation(PipelineAggregatorBuilders
.statsBucket("attendance_percentage_no_100_count","perfect_courses._count"));
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
ParsedStatsBucket attendancePercentageNo100Count = aggregations.get("attendance_percentage_no_100_count");
return attendancePercentageNo100Count.getCount();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
接口四:根据stu_id分组筛选获取满勤数和非满勤数
sql如下:
SELECT
count( 1 ) AS stu_yes_num
FROM
(
SELECT
FORMAT( ifnull((( ifnull( sum( sign_status ), 0 ))/ count( s.id )* 100 ), 0 ), 1 ) AS yes_lv
FROM
eschool.stu_sign s
<where>
AND s.class_begin_time < now()
<if test="t.beginDate!=null and t.beginDate!=''">
and s.class_begin_time > CONCAT(#{t.beginDate},' 00:00:01')
</if>
<if test="t.endDate!=null and t.endDate!=''">
and s.class_begin_time < CONCAT(#{t.endDate},' 23:59:59')
</if>
<if test="t.dormId!=null and t.dormId!=''">
and s.classroom_id in (select id from eschool.class_room where uuid in(${t.dormId}))
</if>
</where>
GROUP BY s.stu_id ) t
where t.yes_lv ='100.0'
java代码
private Long getStuYesNumByES(SchoolReportRequest requestParam) {
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
if(StringUtils.isNotBlank(requestParam.getDormId())){
List<String> classroomIds = attendanceMapper.getClassroomIdByDormId(requestParam.getDormId());
boolQueryBuilder.must(QueryBuilders.termsQuery("classroom_id.keyword", classroomIds));
}
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(0);
// 聚合:统计课程出勤百分比
Map<String, String> bucketsPathsMap = new HashMap<>();
bucketsPathsMap.put("sum_sign", "sum_sign");
bucketsPathsMap.put("count_total", "count_total");
TermsAggregationBuilder stuAgg = AggregationBuilders.terms("perfect_stu")
.field("stu_id")
.size(10000) // 根据学生数量调整
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(AggregationBuilders.count("count_total").field("id"))
.subAggregation(PipelineAggregatorBuilders.bucketScript("attendance_percentage",bucketsPathsMap,
new Script(" params.sum_sign / params.count_total * 100")
));
//管道聚合筛选
Map<String, String> pipelineBucketsPathsMap = new HashMap<>();
pipelineBucketsPathsMap.put("attendance_percent", "attendance_percentage");
//管道聚合筛选
stuAgg.subAggregation(PipelineAggregatorBuilders.bucketSelector("attendance_percentage_100_filter",pipelineBucketsPathsMap,
new Script("params.attendance_percent == 100.0")));
searchSourceBuilder.aggregation(stuAgg);
//管道聚合(最大值、平均值、最小值。。。)
searchSourceBuilder.aggregation(PipelineAggregatorBuilders
.statsBucket("attendance_percentage_100_count","perfect_stu._count"));
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
ParsedStatsBucket attendancePercentage100Count = aggregations.get("attendance_percentage_100_count");
return attendancePercentage100Count.getCount();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
private Long getStuNoNumByES(SchoolReportRequest requestParam) {
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
if(StringUtils.isNotBlank(requestParam.getDormId())){
List<String> classroomIds = attendanceMapper.getClassroomIdByDormId(requestParam.getDormId());
boolQueryBuilder.must(QueryBuilders.termsQuery("classroom_id", classroomIds));
}
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(0);
// 聚合:统计课程出勤百分比
Map<String, String> bucketsPathsMap = new HashMap<>();
bucketsPathsMap.put("sum_sign", "sum_sign");
bucketsPathsMap.put("count_total", "count_total");
TermsAggregationBuilder stuAgg = AggregationBuilders.terms("perfect_stu")
.field("stu_id")
.size(10000) // 根据实际学生数量调整
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(AggregationBuilders.count("count_total").field("id"))
.subAggregation(PipelineAggregatorBuilders.bucketScript("attendance_percentage",bucketsPathsMap,
new Script(" params.sum_sign / params.count_total * 100")
));
//管道聚合筛选
Map<String, String> pipelineBucketsPathsMap = new HashMap<>();
pipelineBucketsPathsMap.put("attendance_percent", "attendance_percentage");
stuAgg.subAggregation(PipelineAggregatorBuilders.bucketSelector("attendance_percentage_no_100_filter",pipelineBucketsPathsMap,
new Script("params.attendance_percent < 100.0")));
searchSourceBuilder.aggregation(stuAgg);
//管道聚合(最大值、平均值、最小值。。。)
searchSourceBuilder.aggregation(PipelineAggregatorBuilders
.statsBucket("attendance_percentage_no_100_count","perfect_stu._count"));
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = response.getAggregations();
ParsedStatsBucket attendancePercentageNo100Count = aggregations.get("attendance_percentage_no_100_count");
return attendancePercentageNo100Count.getCount();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
接口五:根据学院分组筛选获取top5和各学院学生平均出勤率
获取top5的sql:
SELECT a.NAME, FORMAT( ifnull(( ifnull( sum( sign_status ), 0 )/ count( s.id )* 100 ), 0), 1) + 0 AS yes_lv
FROM
eschool.stu_sign s
LEFT JOIN eschool.USER u ON s.stu_id = u.id
LEFT JOIN eschool.academy a ON a.id = u.academy_id
<where>
AND s.class_begin_time < now()
AND a.NAME IS NOT NULL
<if test="t.beginDate!=null and t.beginDate!=''">
and s.class_begin_time > CONCAT(#{t.beginDate},' 00:00:01')
</if>
<if test="t.endDate!=null and t.endDate!=''">
and s.class_begin_time < CONCAT(#{t.endDate},' 23:59:59')
</if>
<if test="t.dormId!=null and t.dormId!=''">
and s.classroom_id in (select id from eschool.class_room where uuid in(${t.dormId}))
</if>
</where>
GROUP BY u.academy_id ORDER BY yes_lv desc LIMIT 5
各学院学生平均出勤率去掉ORDER BY yes_lv desc LIMIT 5
java代码
//学生出勤排名前五的学院
private List<Map<String, Object>> getStuTop5ListByES(SchoolReportRequest requestParam) {
ArrayList<Map<String, Object>> resultList = new ArrayList<>();
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
if(StringUtils.isNotBlank(requestParam.getDormId())){
List<String> classroomIds = attendanceMapper.getClassroomIdByDormId(requestParam.getDormId());
boolQueryBuilder.must(QueryBuilders.termsQuery("classroom_id.keyword", classroomIds));
}
//筛选academy_id不为null的
boolQueryBuilder.must(QueryBuilders.existsQuery("academy_id"));
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(0);
// 聚合:统计学院出勤百分比
Map<String, String> bucketsPathsMap = new HashMap<>();
bucketsPathsMap.put("sum_sign", "sum_sign");
bucketsPathsMap.put("count_total", "count_total");
TermsAggregationBuilder academyAgg = AggregationBuilders.terms("perfect_academy")
.field("academy_id")
.size(10000) // 根据实际学院的数量调整
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(AggregationBuilders.count("count_total").field("id"))
.subAggregation(PipelineAggregatorBuilders.bucketScript("attendance_percentage",bucketsPathsMap,
new Script(" params.sum_sign / params.count_total * 100")
));
//排序聚合:按照出勤百分比降序排列,并截取前五条记录
List<FieldSortBuilder> attendance_percentageSort = new ArrayList<>();
attendance_percentageSort.add(new FieldSortBuilder("attendance_percentage.value").order(SortOrder.DESC));
academyAgg.subAggregation(PipelineAggregatorBuilders.bucketSort("sorted_result",attendance_percentageSort).size(5));
searchSourceBuilder.aggregation(academyAgg);
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
ParsedLongTerms perfectAcademy = response.getAggregations().get("perfect_academy");
perfectAcademy.getBuckets().forEach(bucket -> {
Map<String, Object> result = new HashMap<>();
String academy_id = bucket.getKeyAsString();//学院ID
result.put("name", attendanceMapper.getAcademyNameById(academy_id));
ParsedSimpleValue attendance_percentage = bucket.getAggregations().get("attendance_percentage");
double value = attendance_percentage.value();
//四舍五入并保留一位小数
result.put("yes_lv", Math.round(value * 10) / 10.0);//出勤百分比
resultList.add(result);
});
return resultList;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
//各学院学生平均出勤率
private List<Map<String, Object>> getCollegeStuListByES(SchoolReportRequest requestParam) {
ArrayList<Map<String, Object>> resultList = new ArrayList<>();
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
if(StringUtils.isNotBlank(requestParam.getDormId())){
List<String> classroomIds = attendanceMapper.getClassroomIdByDormId(requestParam.getDormId());
boolQueryBuilder.must(QueryBuilders.termsQuery("classroom_id.keyword", classroomIds));
}
//筛选academy_id不为null的
boolQueryBuilder.must(QueryBuilders.existsQuery("academy_id"));
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(0);
// 聚合:统计学院出勤百分比
Map<String, String> bucketsPathsMap = new HashMap<>();
bucketsPathsMap.put("sum_sign", "sum_sign");
bucketsPathsMap.put("count_total", "count_total");
TermsAggregationBuilder academyAgg = AggregationBuilders.terms("perfect_academy")
.field("academy_id")
.size(10000) // 根据实际学院的数量调整
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(AggregationBuilders.count("count_total").field("id"))
.subAggregation(PipelineAggregatorBuilders.bucketScript("attendance_percentage",bucketsPathsMap,
new Script(" params.sum_sign / params.count_total * 100")
));
searchSourceBuilder.aggregation(academyAgg);
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
ParsedLongTerms perfectAcademy = response.getAggregations().get("perfect_academy");
perfectAcademy.getBuckets().forEach(bucket -> {
Map<String, Object> result = new HashMap<>();
String academy_id = bucket.getKeyAsString();//学院ID
result.put("name", attendanceMapper.getAcademyNameById(academy_id));
ParsedSimpleValue attendance_percentage = bucket.getAggregations().get("attendance_percentage");
double value = attendance_percentage.value();
//四舍五入并保留一位小数
result.put("yes_lv", Math.round(value * 10) / 10.0);//出勤百分比
resultList.add(result);
});
return resultList;
} catch (Exception e) {
throw new RuntimeException(e);
}
}
接口六:时间端筛选统计时间段内每一天的学生签到率
sql如下:
SELECT LEFT( s.class_begin_time, 10 ) AS date,
FORMAT( ifnull(( ifnull( sum( sign_status ), 0 )/ count( s.id )* 100 ), 0 ), 1 )+ 0 AS yes_lv
FROM eschool.stu_sign s
<where>
AND s.class_begin_time < now()
<if test="t.beginDate!=null and t.beginDate!=''">
and s.class_begin_time > CONCAT(#{t.beginDate},' 00:00:01')
</if>
<if test="t.endDate!=null and t.endDate!=''">
and s.class_begin_time < CONCAT(#{t.endDate},' 23:59:59')
</if>
<if test="t.dormId!=null and t.dormId!=''">
and s.classroom_id in (select id from eschool.class_room where uuid in(${t.dormId}))
</if>
</where>
GROUP BY date
java如下:
private List<Map<String, Object>> getDateStuListByES(SchoolReportRequest requestParam) {
ArrayList<Map<String, Object>> resultList = new ArrayList<>();
try {
SearchRequest searchRequest = new SearchRequest("stu_sign");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
RangeQueryBuilder timeRangeQuery = QueryBuilders.rangeQuery("class_begin_time").lte("now");
if (requestParam.getBeginDate() != null && requestParam.getEndDate() != null) {
// 添加日期格式化,匹配yyyy-MM-dd HH:mm:ss格式
String gte = requestParam.getBeginDate() + " 00:00:00";
String lte = requestParam.getEndDate() + " 23:59:59";
timeRangeQuery.gte(gte).lte(lte);
}
boolQueryBuilder.must(timeRangeQuery);
if(StringUtils.isNotBlank(requestParam.getDormId())){
List<String> classroomIds = attendanceMapper.getClassroomIdByDormId(requestParam.getDormId());
boolQueryBuilder.must(QueryBuilders.termsQuery("classroom_id.keyword", classroomIds));
}
searchSourceBuilder.query(boolQueryBuilder);
searchSourceBuilder.size(0);
// 聚合:统计学院出勤百分比
Map<String, String> bucketsPathsMap = new HashMap<>();
bucketsPathsMap.put("sum_sign", "sum_sign");
bucketsPathsMap.put("count_total", "count_total");
DateHistogramAggregationBuilder dateHistogramAgg = AggregationBuilders.dateHistogram("my_date_histogram")
.field("class_begin_time").calendarInterval(DateHistogramInterval.DAY).format("yyyy-MM-dd")
.subAggregation(AggregationBuilders.sum("sum_sign").field("sign_status"))
.subAggregation(AggregationBuilders.sum("sum_late").field("late_status"))
.subAggregation(AggregationBuilders.count("count_total").field("id"))
.subAggregation(PipelineAggregatorBuilders.bucketScript("attendance_percentage",bucketsPathsMap,
new Script(" params.sum_sign / params.count_total * 100")
));
searchSourceBuilder.aggregation(dateHistogramAgg);
searchRequest.source(searchSourceBuilder);
SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
ParsedDateHistogram dateHistogram = response.getAggregations().get("my_date_histogram");
dateHistogram.getBuckets().forEach(bucket -> {
Map<String, Object> result = new HashMap<>();
result.put("date", bucket.getKeyAsString());
ParsedSimpleValue attendance_percentage = bucket.getAggregations().get("attendance_percentage");
//出勤百分比
if (attendance_percentage != null){
double value = attendance_percentage.value();
//四舍五入并保留一位小数()
result.put("yes_lv", Math.round(value * 10) / 10.0);//出勤百分比
}else{
result.put("yes_lv", 0.0);
}
resultList.add(result);
});
return resultList;
} catch (Exception e) {
throw new RuntimeException(e);
}
}

![MySQL基础 [一] - 数据库基础](https://i-blog.csdnimg.cn/direct/b1888f03385e41948d55517a96693427.png)






![[ctfshow web入门] web5](https://i-blog.csdnimg.cn/direct/9b822163603247a691d62bdae0f93520.png)