少年何妨梦摘星
敢挽桑弓射玉衡
解决与链表相关的问题总是有大量的指针操作,而指针操作的代码总是容易出错的。很多面试官喜欢出与链表相关的问题,就是想通过指针操作来考察应聘者的编码功底。
题目链接来自于 AcWing 、Leetcode(LCR)
目录
从尾到头打印链表
题目描述
思路
代码测试
删除链表的节点
题目描述
思路
代码测试
链表中倒数第k个节点
题目描述
思路一
代码测试一
思路二
代码测试二
链表中环的入口结点
题目描述
思路
结论整理
代码测试
反转链表
题目描述
思路
代码测试
合并两个排序的链表
题目描述
思路一
代码测试一
思路二
代码测试二
删除链表中重复的节点
题目描述
思路
代码测试
两个链表的第一个公共结点
思路一
代码测试一
思路二
代码测试二
复杂链表的复刻
思路
代码测试


从尾到头打印链表
题目链接:从尾到头打印链表
题目描述
输入一个链表的头结点,按照 从尾到头 的顺序返回节点的值。
返回的结果用数组存储。
数据范围
0≤ 链表长度 ≤1000。
样例
输入:[2, 3, 5] 返回:[5, 3, 2]
思路
通常打印是一个只读的操作,我们不希望修改原链表的结构。接下来我们想到解决这个问题的肯定要遍历链表,遍历的顺序是从头到尾,而输出的顺序却是从尾到头。这就是典型的 后进先出 的问题。
我们可以使用 栈 实现这种顺序。每经过一个结点的时候,把该结点放到一个栈中。当遍历完整个链表后,再从栈顶开始逐个读取结点的值,并赋给一个新数组,这样我们就可以从尾到头打印链表了。
代码测试
class Solution { public: vector<int> printListReversingly(ListNode* head) { //创建栈 stack<int> a; ListNode* pur = head; //入栈 while(pur) { a.push(pur->val); pur = pur->next; } //创建新数组 vector<int> b; //出栈 while(!a.empty()) { //提取栈顶元素 b.push_back(a.top()); //弹出栈顶元素 a.pop(); } return b; } };
删除链表的节点
题目链接:删除链表的节点
题目描述
给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
示例 1:
输入: head = [4,5,1,9], val = 5 输出: [4,1,9] 解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.示例 2:
输入: head = [4,5,1,9], val = 1 输出: [4,5,9] 解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.说明:
- 题目保证链表中节点的值互不相同
- 若使用 C 或 C++ 语言,你不需要
free或delete被删除的节点
思路
<1>从链表的头节点开始循环遍历找到要删除节点的 前驱节点pur
<2>前驱节点与删除节点的后继节点链接(pur = pur->next->next)
注意
如果链表我们的 val 恰好为链表的头节点:我们直接返回剩余的链表即可(head->next)
代码测试
class Solution { public: ListNode* deleteNode(ListNode* head, int val) { //判断 val 是否为链表的头节点 if(head->val == val) { return head->next; } else { ListNode* pur = head; //循环遍历寻找 val 的前驱节点 while(pur->next->val != val) { pur = pur->next; } //删除 val 节点 pur->next = pur->next->next; return head; } } };


链表中倒数第k个节点
题目链接:链表中倒数第k个节点
题目描述
输入一个链表,输出该链表中倒数第 k 个结点。
注意:
k >= 1;- 如果 k 大于链表长度,则返回 NULL;
数据范围
链表长度 [0,30]。
样例
输入:链表:1->2->3->4->5 ,k=2 输出:4
思路一
两次遍历
假设整个链表有 n 个节点,那么倒数第 k 个节点就是从头节点开始的第 n-k+1 个节点。说明我们要遍历链表两次,第一次 统计 链表中节点的 个数 ,第二次就能找到倒数第 k 个节点。
代码测试一
class Solution { public: ListNode* findKthToTail(ListNode* pListHead, int k) { //判断链表和 k 是否合法 if(pListHead == NULL||k ==0) return NULL; ListNode* pur = pListHead; int count = 0; //统计链表中的节点个数 while(pur) { count++; pur = pur->next; } pur = pListHead; //判断 k 是否满足条件 if(k>count) return NULL; //遍历寻找 k 节点 for(int i = 1; i < count-k+1; i++) pur = pur->next; return pur; } };
但是如果是在面试中,考核官更期待只需要遍历链表一次的解法
思路二
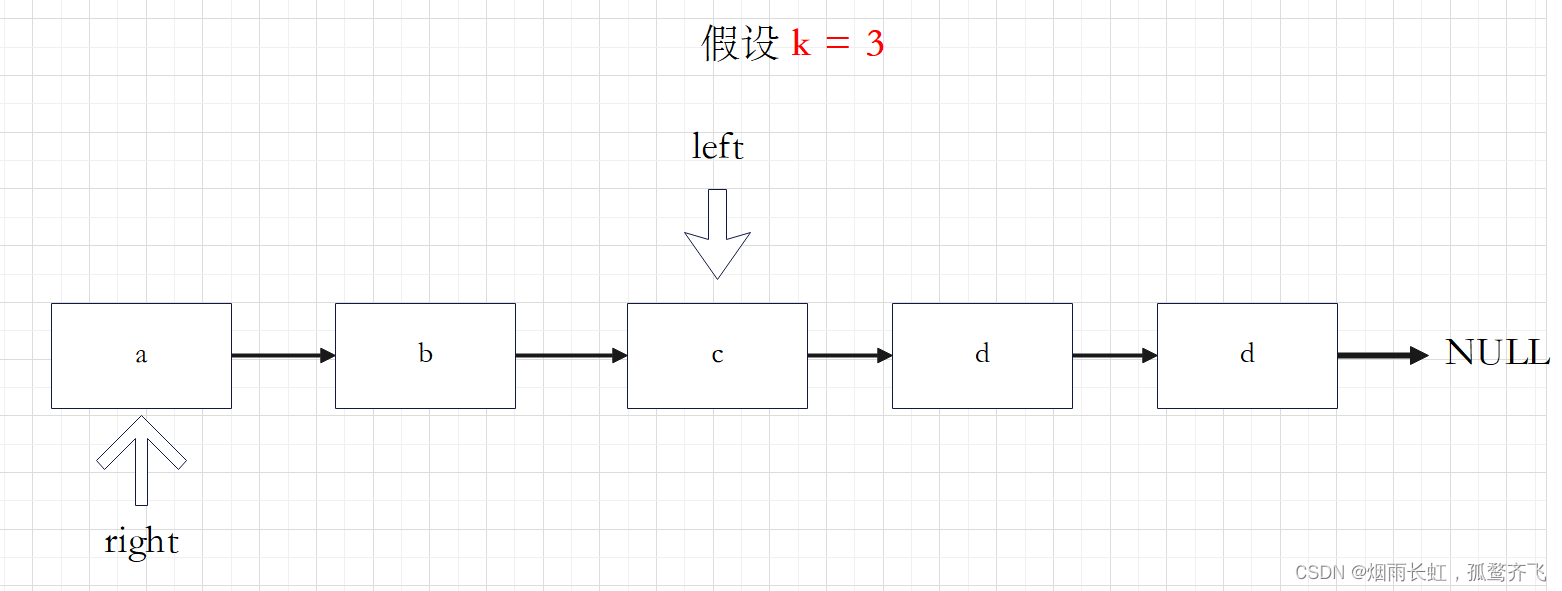
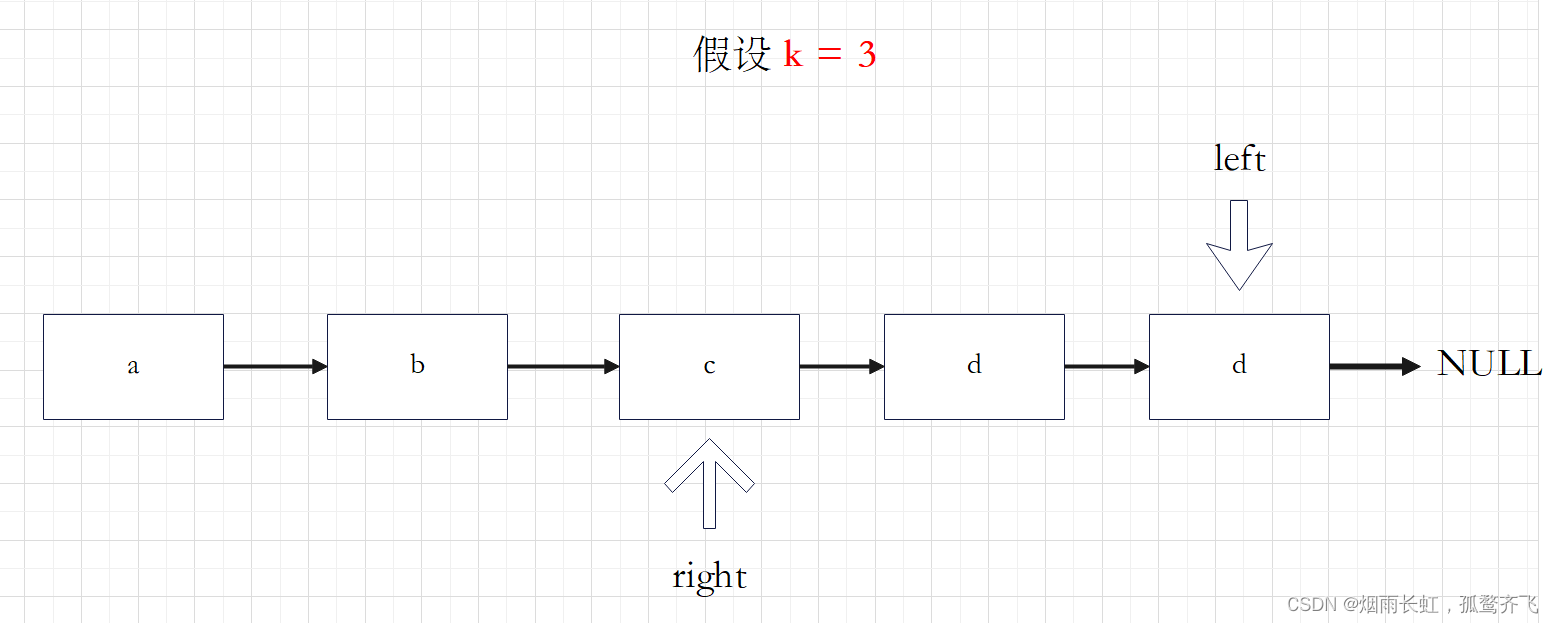
快慢双指针
我们可以定义两个指针 left 和 right ,快指针 left 先从链表的头指针开始遍历向前走 k-1 步,慢指针 right 保持不动;从第 k 步开始,第二个指针也开始从链表的头指针开始遍历。由于两个指针的距离保持在 k-1,当快指针 left 到达链表的尾节点时,慢指针指向的刚好是倒数的 k 个节点。
代码测试二
class Solution { public: ListNode* findKthToTail(ListNode* pListHead, int k) { //判断链表和 k 是否合法 if(pListHead == NULL||k ==0) return NULL; ListNode* left = pListHead; ListNode* right = pListHead; //快指针开始走 k-1 步 for(int i = 0;i<k-1;i++) { //如果left->next == NULL则说明链表长度小于 k if(left->next) left = left->next; else return NULL; } //共同遍历 while(left->next) { left = left->next; right = right->next; } return right; } };
链表中环的入口结点
题目链接:链表中环的入口结点
题目描述
给定一个链表,若其中包含环,则输出环的入口节点。
若其中不包含环,则输出
null。数据范围
节点 val 值取值范围 [1,1000]。
节点 val 值各不相同。
链表长度 [0,500]。样例
给定如上所示的链表: [1, 2, 3, 4, 5, 6] 2 注意,这里的2表示编号是2的节点,节点编号从0开始。所以编号是2的节点就是val等于3的节点。 则输出环的入口节点3.
思路
这道题的思路可以借鉴一下我之前做的博客会更详细:环形链表
<1>如何确定一个链表包含一个环?快慢双指针
定义两个快慢指针在链表上移动,left 跑得快,right 跑得慢。当 left 和 right 从链表上的同一个节点开始移动时,如果该链表中没有环,那么 left 将一直处于 right 的前方;如果该链表中有环,那么 left 会先于 right 进入环,并且一直在环内移动。等到 right 进入环时,由于 left 的速度快,它一定会在某个时刻与 right 相遇,则链表中存在环。否则快指针 left 率先走到链表的末尾。我们可以定义:慢指针一次走一步,快指针一次走两步。
<2>如何确定链表中环的入口节点?数学证明
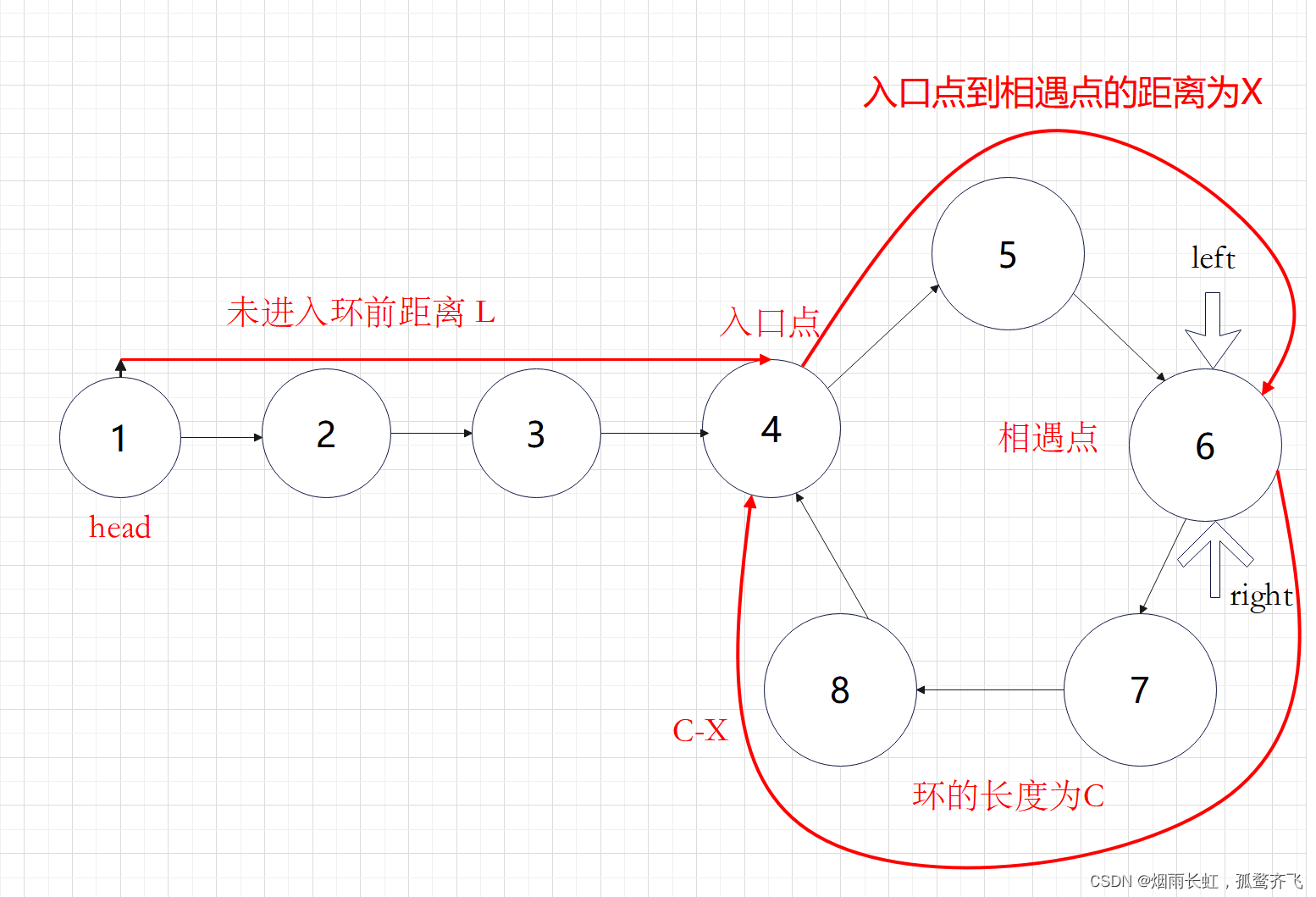
设为进入环前的链表长度为L,入口点到相遇点的距离为X,环的长度为C
right 走的距离为
设 left 追上 right 时,转了 n 圈(n>=1)
left 走的距离为
任意时刻,left 指针走过的距离都为指针 right 的 2 倍
即为
化简为:
为了更好的理解我们写成这样
(n-1) x C 是 left 转的圈数,转了 (n-1) 圈后回到相遇点
故可以推出:如将此时两指针分别放在 起始位置 和 相遇位置 ,并以 相同速度 前进,当一个指针走完距离 L 时,另一个指针恰好走出,绕环 n-1 圈加上 C-X 的距离。
故两指针会在环开始位置相遇。
结论整理
<1>设置快慢指针,假如有环,他们最后一定相遇在环中。
<2>两个指针相遇后,让两个指针分别从链表头和相遇点重新出发,每次走一步,最后一定相遇于环入口。
代码测试
class Solution { public: ListNode *entryNodeOfLoop(ListNode *head) { ListNode* left = head,*right = head; while(left&&left->next) { //寻找快慢指针相遇点 left = left->next->next; right = right->next; if(left == right) { //相遇点 ListNode* mid = left; while(mid != head) { head = head->next; mid = mid->next; } //入口点 return head; } } return NULL; } };

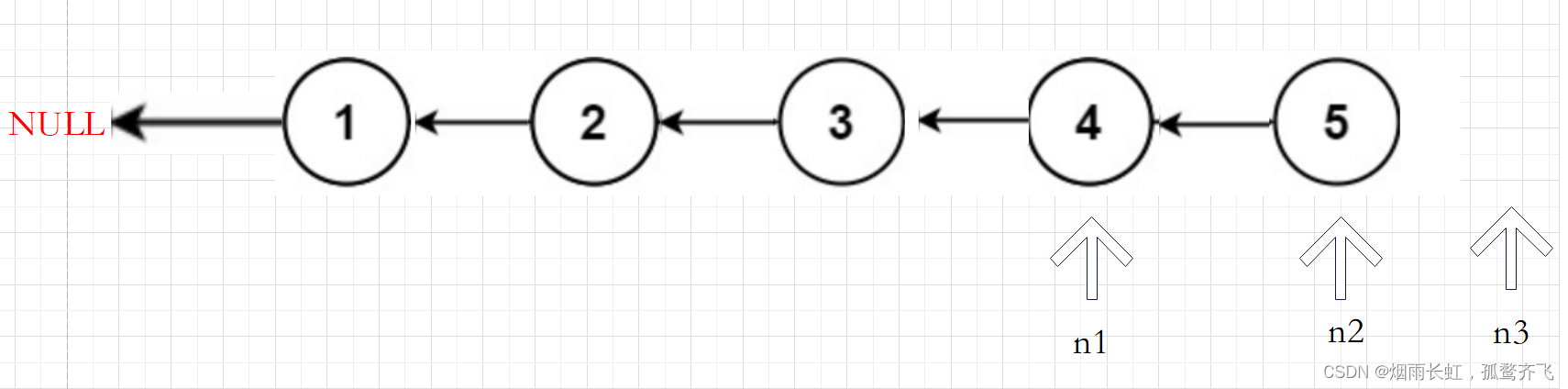
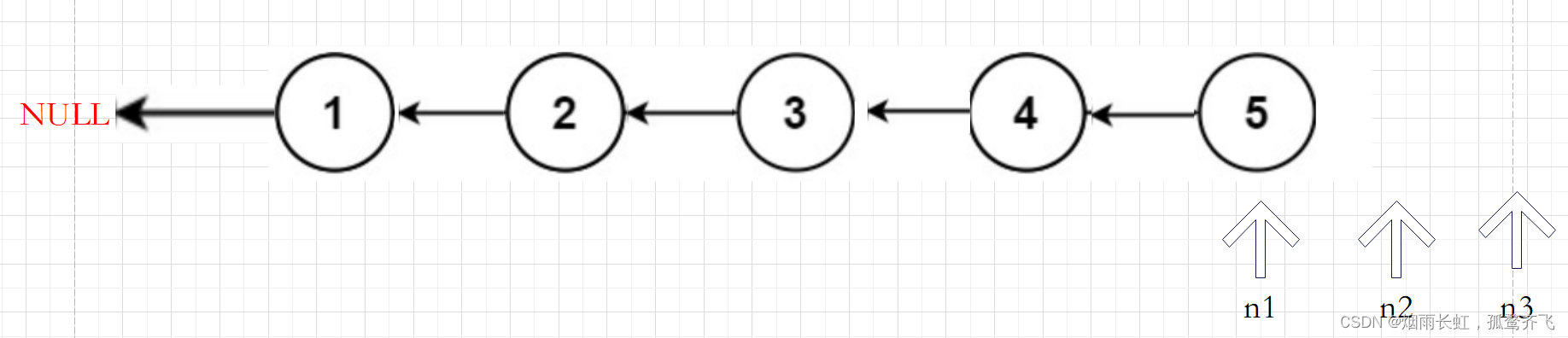
反转链表
题目链接:反转链表
题目描述
定义一个函数,输入一个链表的头结点,反转该链表并输出反转后链表的头结点。
数据范围
链表长度 [0,30]。
样例
输入:1->2->3->4->5->NULL 输出:5->4->3->2->1->NULL
思路
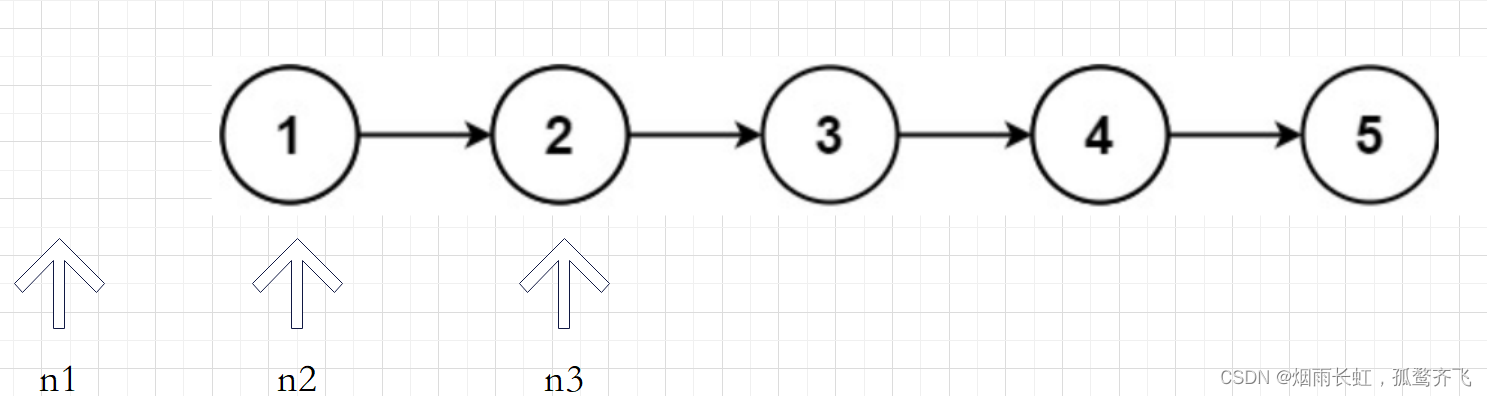
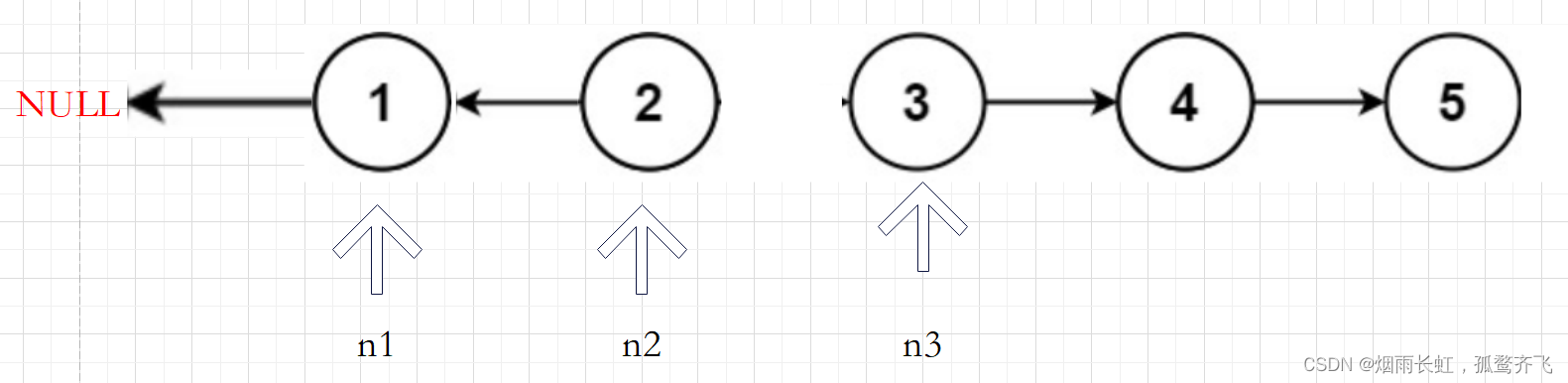
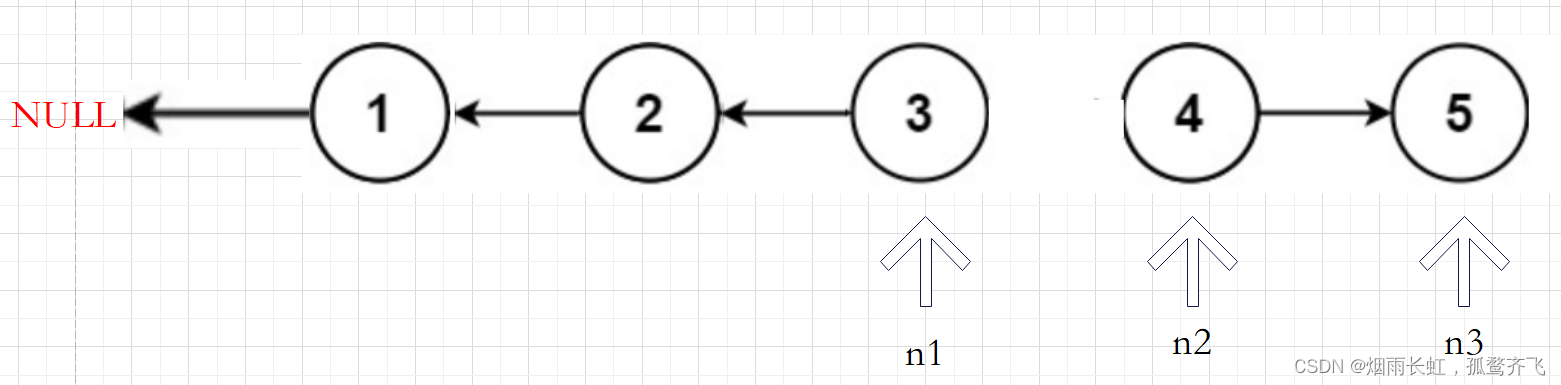
快慢指针+前驱指针
我们在调节当前节点的指针 n2 的时候除了需要知道当前节点的本身还需要知道前驱节点(我们用 n1 来存储前驱节点的位置),这样只需要调节当前节点 n2 指针的指向便可完成链表的反转,为了避免调节时链表的丢失,我们需要在定义一个指针 n3 来存储后继节点的位置,然后循环遍历即可。
代码测试
class Solution { public: ListNode* reverseList(ListNode* head) { if(head == NULL)//判断链表是否为空 { return head; } ListNode *n1,*n2,*n3; n1 = NULL,n2 = head,n3 = head->next; while(n2) //如果n2不为空就进入循环 { n2->next = n1; //修改n2的指向 n1 = n2; n2 = n3; if(n3) //判断n3是否为空 n3 = n3->next; } return n1; } };

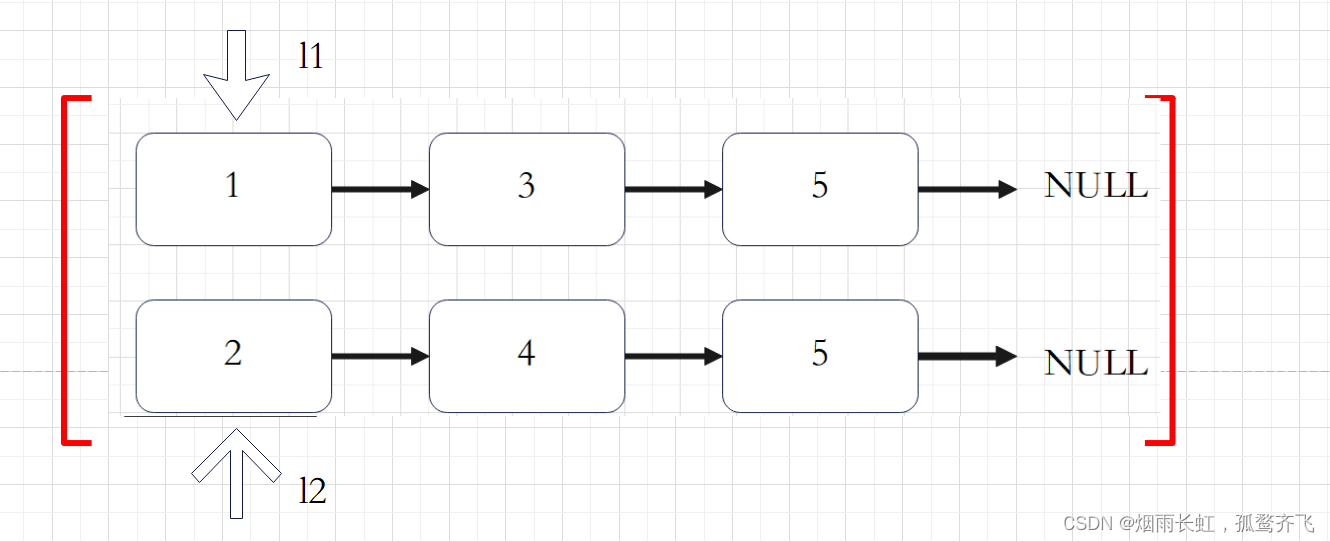
合并两个排序的链表
题目链接:合并两个排序的链表
题目描述
输入两个递增排序的链表,合并这两个链表并使新链表中的结点仍然是按照递增排序的。
数据范围
链表长度 [0,500]。
样例
输入:1->3->5 , 2->4->5 输出:1->2->3->4->5->5
思路一
递归
首先分析合并两个链表的过程:
<1>我们的分析从合并两个链表的头节点开始。链表 1 的头节点的值 小于 链表 2 的头节点的值,因此链表 1 的头节点就是我们合并新链表的头节点。
<2>我们继续合并两个链表中剩余的节点。在两个链表中剩下的节点依然是排序的,因此合并这两个链表的步骤和前面的步骤是一样的。我们还是比较两个头节点的值。此时链表 2 的头节点的值小于链表 1 的头节点的值,因此链表 2 的头节点的值将是合并剩余节点得到的链表的头节点。我们把这个节点和前面合并链表时得到的链表的尾节点 链接 起来。
当我们得到两个链表中值较小的头节点并把它链接到已经合并的链表之后,两个链表剩余的节点依然是排序的,因此合并的步骤和之前的步骤是样的。这就是典型的 递归 过程。
代码测试一
在面试中考核管会更加青睐递归的做法,但是如果对递归不熟的我们可以 简单暴力 一点class Solution { public: ListNode* merge(ListNode* l1, ListNode* l2) { //判断链表是否为空 if(l1 == NULL) return l2; else if(l2 == NULL) return l1; ListNode* head = NULL; //合并链表-比较两个链表的头节点 if(l1->val>l2->val) { head = l2; //递归 head->next = merge(l2->next,l1); } else { head = l1; head->next = merge(l1->next,l2); } return head; } };
思路二
迭代
当 l1 和 l2 都不是空链表时,判断 l1 和 l2 哪一个链表的头节点的值更小,将较小值的节点添加到结果里,当一个节点被添加到结果里之后,将对应链表中的节点向后移一位。
首先,我们设定一个哨兵节点 dummy ,这可以在最后让我们比较容易地返回合并后的链表。我们维护一个 cur 指针,我们需要做的是调整它的 next 指针。
然后,我们重复以上过程,直到 l1 或者 l2 指向了 NULL:如果 l1 当前节点的值小于等于 l2 ,我们就把 l1 当前的节点接在 cur 节点的后面同时将 l1 指针往后移一位。否则,我们对 l2 做同样的操作。不管我们将哪一个元素接在了后面,我们都需要把 cur 向后移一位。
在循环终止的时候, l1 和 l2 至多有一个是非空的。由于输入的两个链表都是有序的,所以不管哪个链表是非空的,它包含的所有元素都比前面已经合并链表中的所有元素都要大。这意味着我们只需要简单地将非空链表接在合并链表的后面,并返回合并链表即可。
代码测试二
class Solution { public: ListNode* merge(ListNode* l1, ListNode* l2) { //判断链表是否是空 if(l1 == NULL) return l2; else if(l2 == NULL) return l1; //创建哨兵位记录首节点的位置 ListNode* dummy = new ListNode(0); ListNode* cur = dummy; //合并链表 while(l1&&l2) { if(l1->val>l2->val) { cur->next = l2; l2 = l2->next; } else { cur->next = l1; l1 = l1->next; } cur = cur->next; } //将非空链表链接到cur的后面 cur->next = l1 == NULL?l2:l1; //返回合并链表 return dummy->next; } };
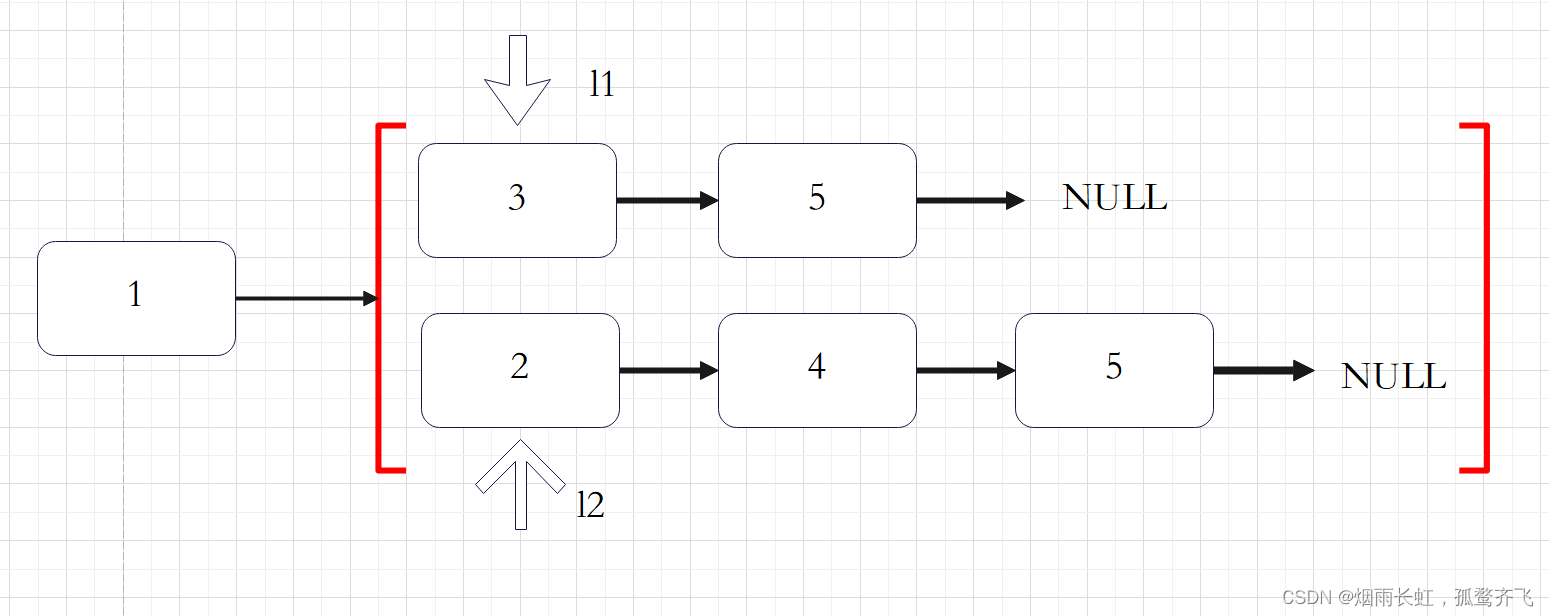
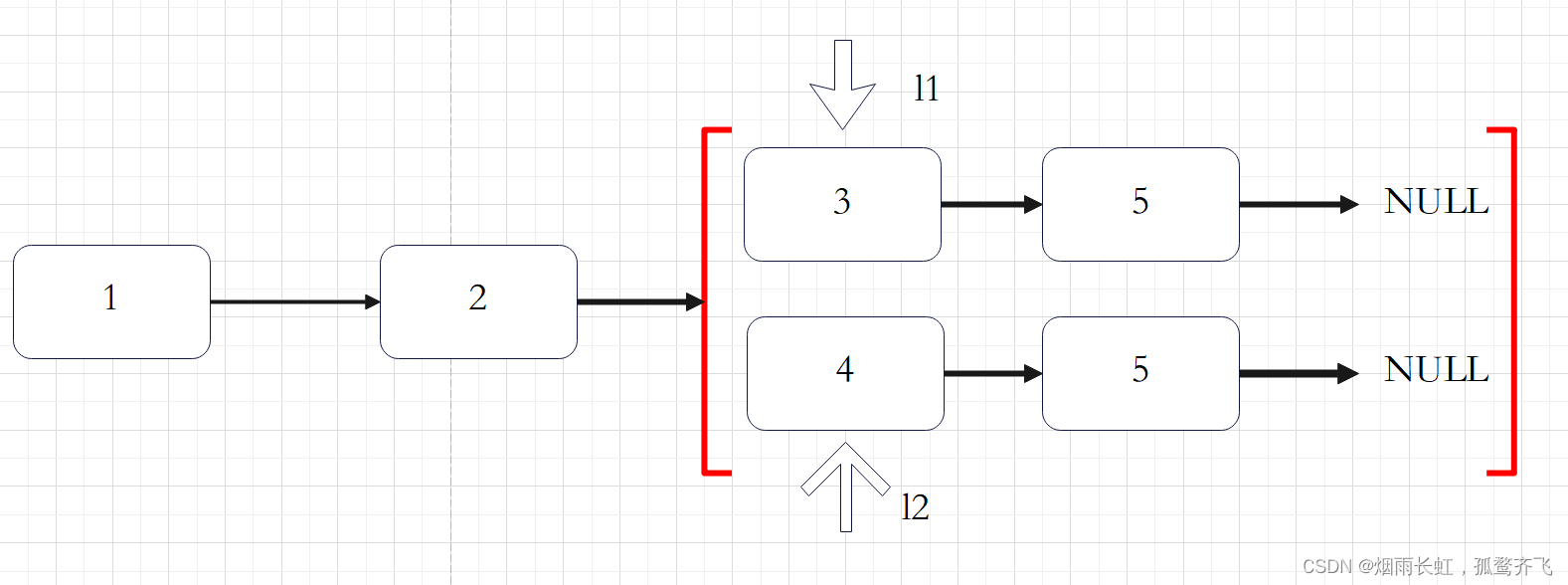
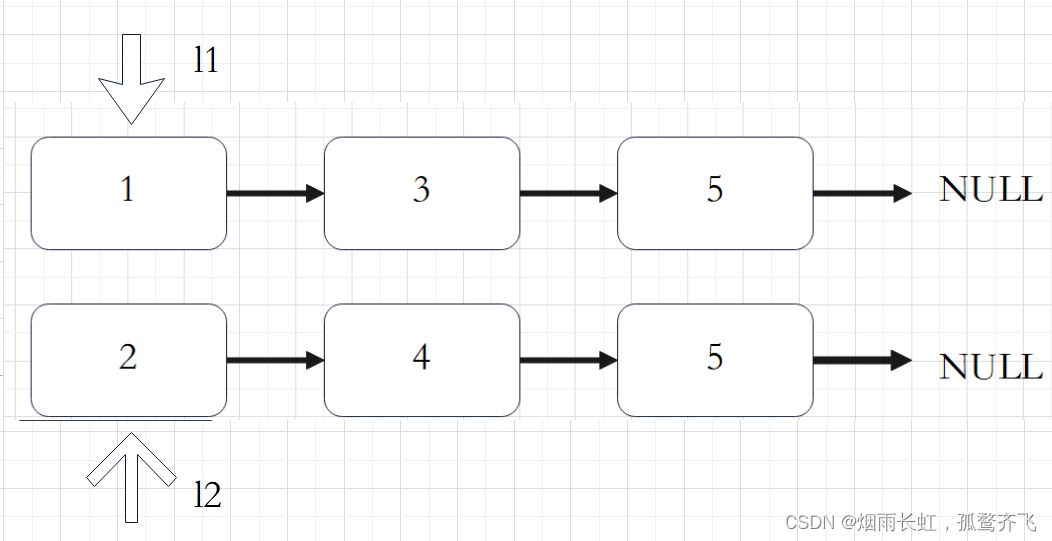
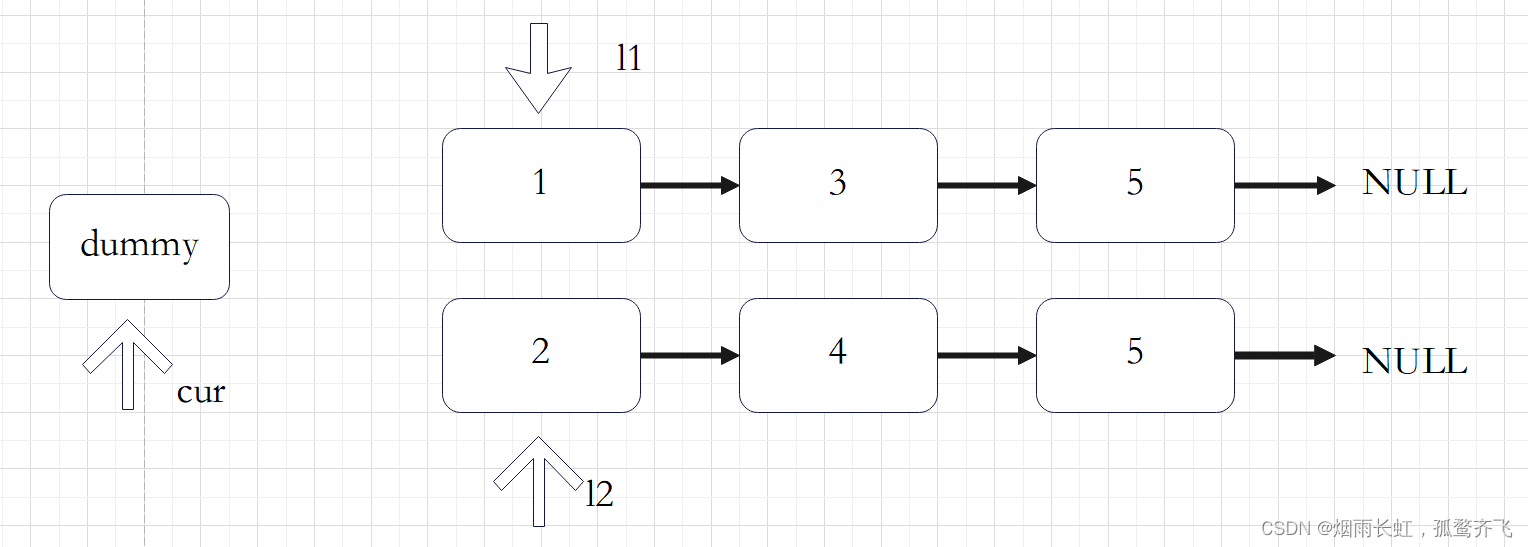
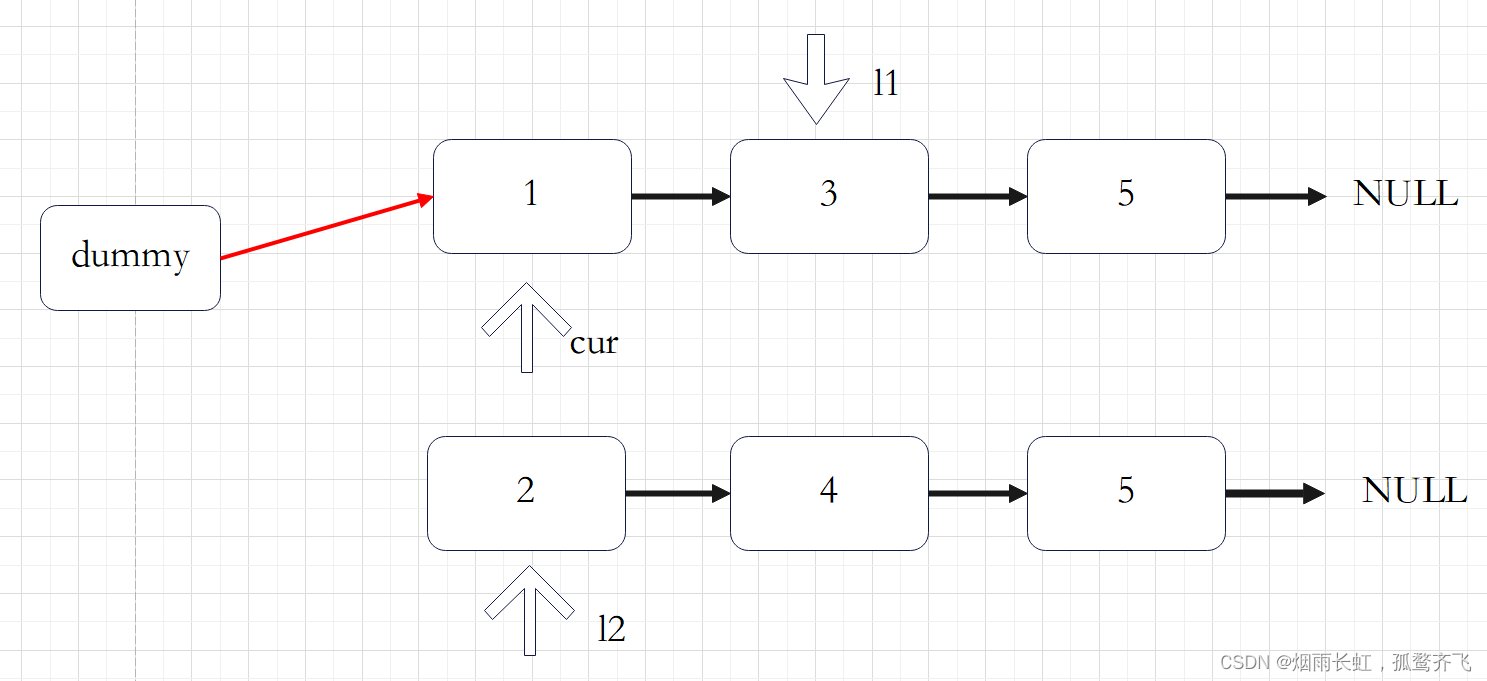

删除链表中重复的节点
题目链接:删除链表中重复的节点
题目描述
在一个排序的链表中,存在重复的节点,请删除该链表中重复的节点,重复的节点不保留。
数据范围
链表中节点 val 值取值范围 [0,100]。
链表长度 [0,100]。样例1
输入:1->2->3->3->4->4->5 输出:1->2->5样例2
输入:1->1->1->2->3 输出:2->3
思路
一次遍历

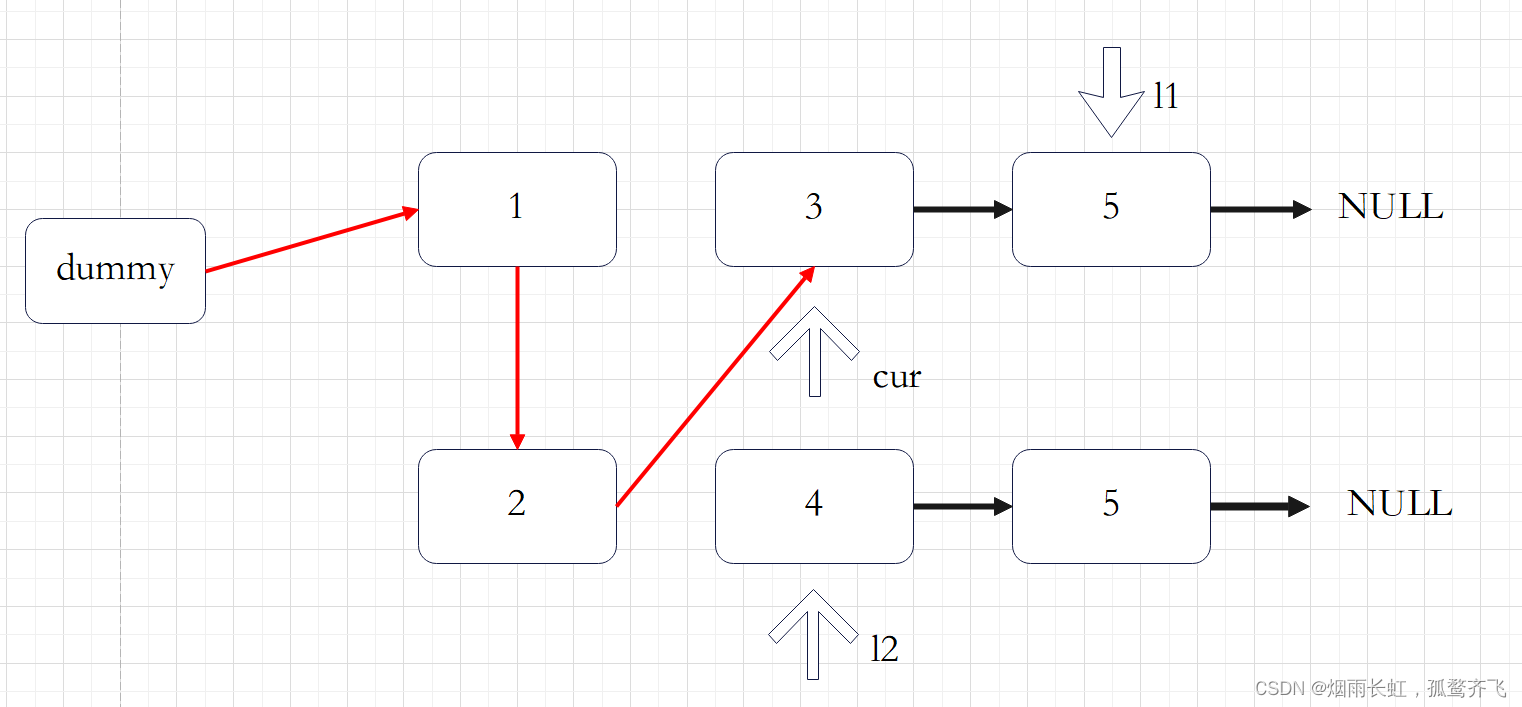
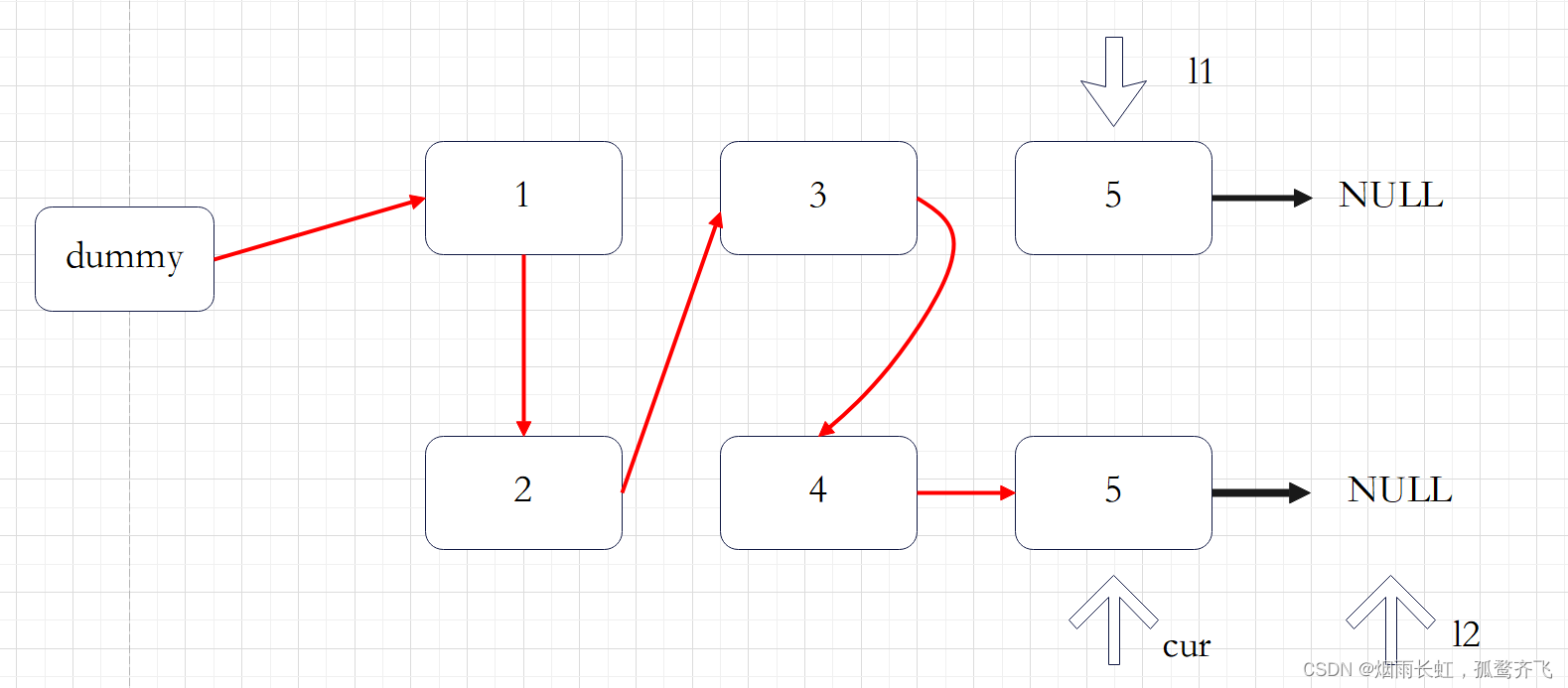
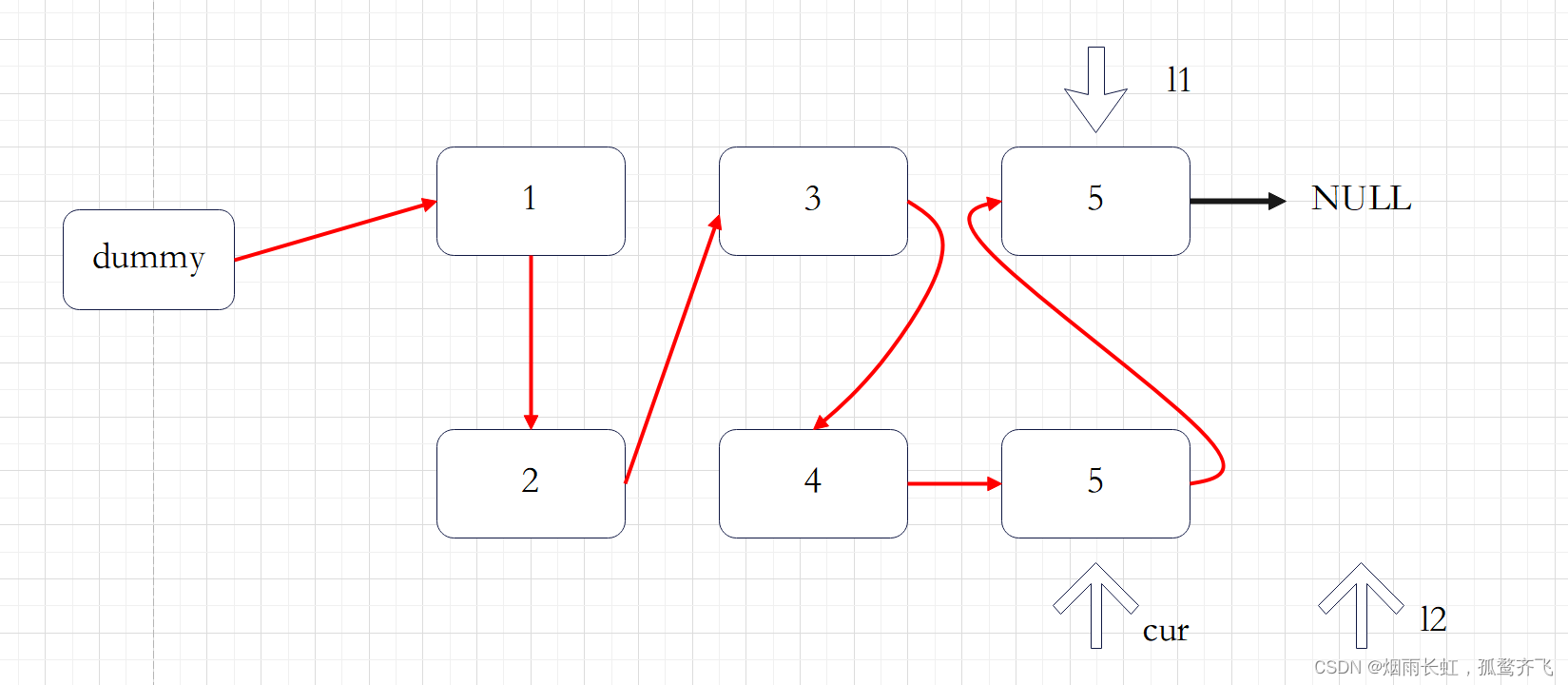
由于给定的链表是排好序的,因此重复的元素在链表中出现的位置是 连续 的,因此我们只需要对链表进行一次遍历,就可以删除重复的元素。由于链表的头节点可能会被删除,因此我们需要使用哨兵位 dummy 来保存首节点的位置。
我们用指针 cur 指向链表的哨兵位 dummy ,随后开始对链表进行遍历。
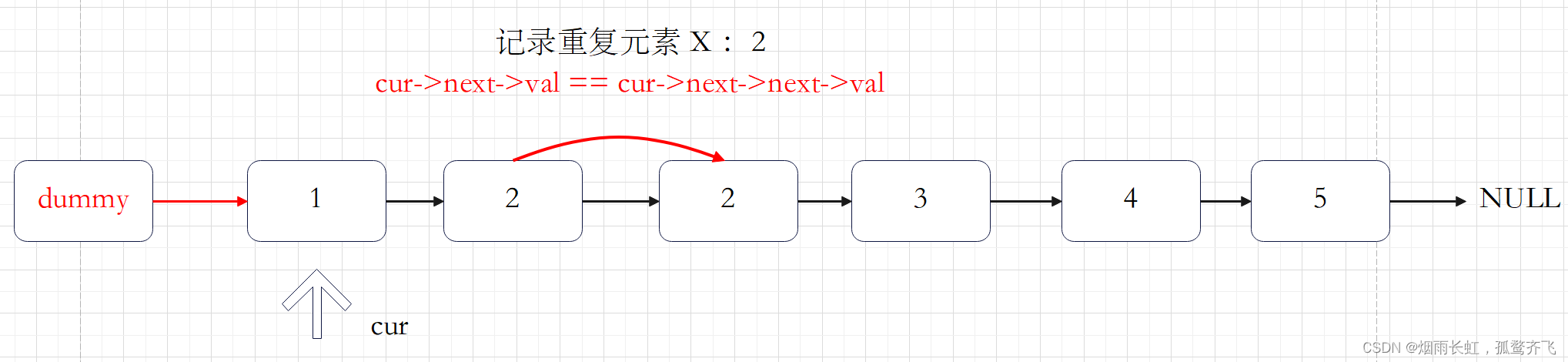
如果当前 cur->next 与 cur->next->next 对应的元素相同,我们就将 cur->next 以及所有后面拥有相同元素值的节点全部删除。我们记下这个元素值 x ,随后不断将 cur->next 从链表中移除,直到空节点或者其元素值不等于 x 为止。此时,我们将链表中所有元素值为 的节点全部删除。
如果当前 cur->next 与 cur->next->next 对应的元素不相同,那么说明链表中只有一个的这样元素,那么我们就可以将 cur 指向 cur->next
遍历完后我们返回 dummy->next 头节点即可。
代码测试
class Solution { public: ListNode* deleteDuplication(ListNode* head) { //判断链表是否为空 if (head == NULL) { return NULL; } //创建哨兵位,并让其指向头节点 ListNode* dummy = new ListNode(0); dummy->next = head; ListNode* cur = dummy; //循环遍历 while(cur->next&&cur->next->next) { //判断是否有相同元素的节点 if(cur->next->val == cur->next->next->val) { //记录重复元素 int x = cur->next->val; while(cur->next&&cur->next->val == x) { cur->next = cur->next->next; } } else { cur = cur->next; } } //返回链表的头节点 return dummy->next; } };

两个链表的第一个公共结点
题目链接:两个链表的第一个公共结点
输入两个链表,找出它们的第一个公共结点。
当不存在公共节点时,返回空节点。
数据范围
链表长度 [1,2000]。
保证两个链表不完全相同,即两链表的头结点不相同。样例
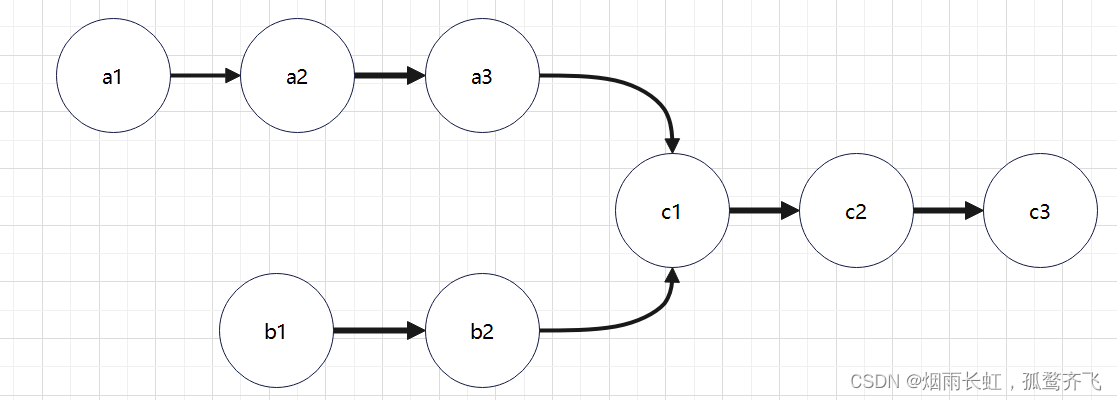
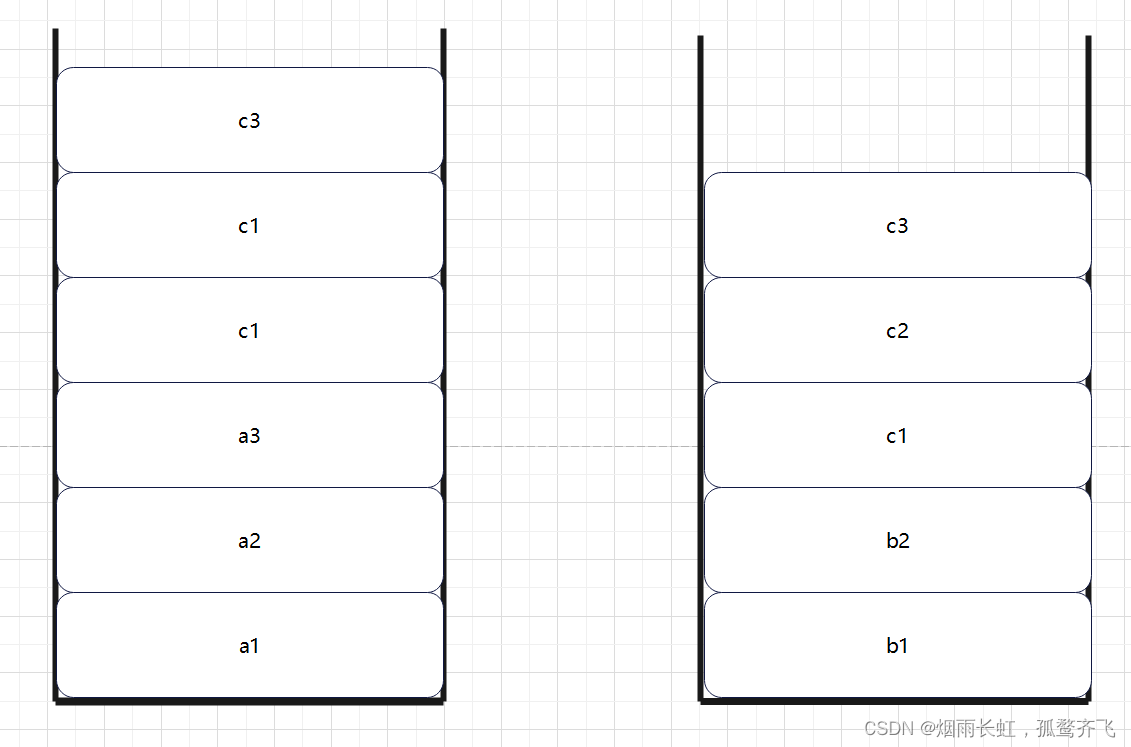
给出两个链表如下所示: A: a1 → a2 ↘ c1 → c2 → c3 ↗ B: b1 → b2 → b3 输出第一个公共节点c1
思路一
双指针
在第一个链表上 顺序遍历 每个节点,每遍历到一个节点,就到第二个链表上顺序遍历每个节点。如果在第二个链表上有一个节点与第一个链表上的节点一样,则说明两个链表在这个节点重合。这样我们就找到了链表的公共节点。
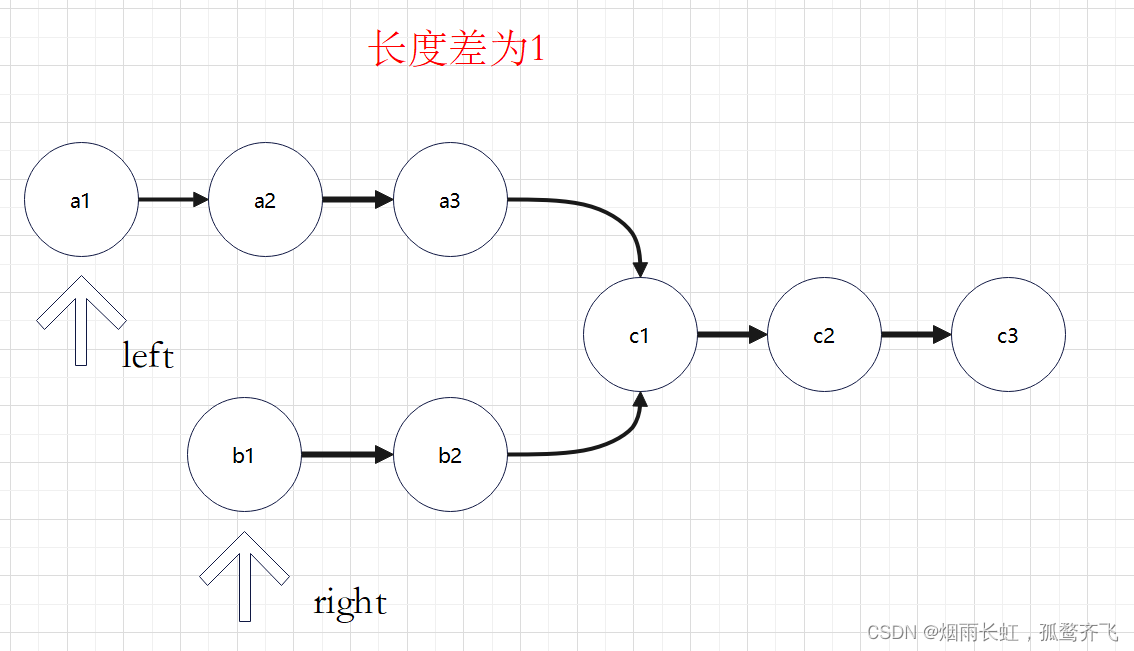
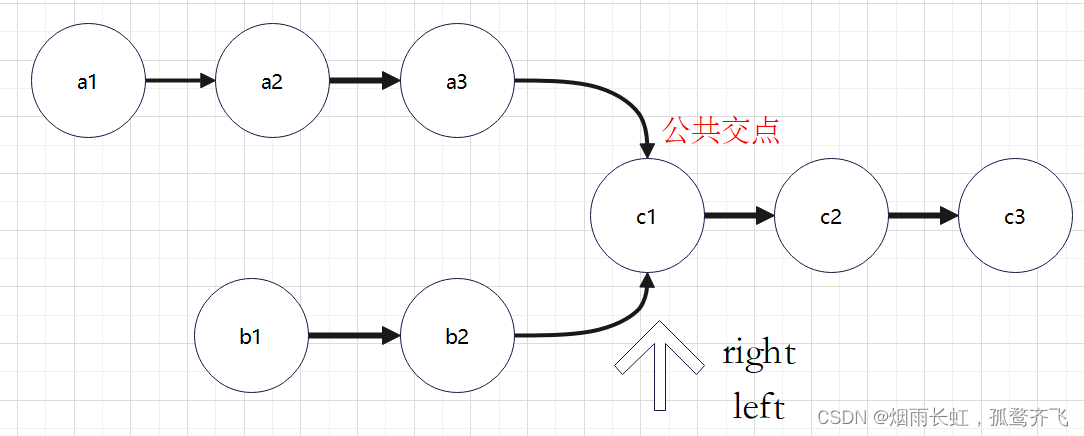
<1>判断相交:先找两个链表的尾节点,尾节点的 地址相同 就相交。
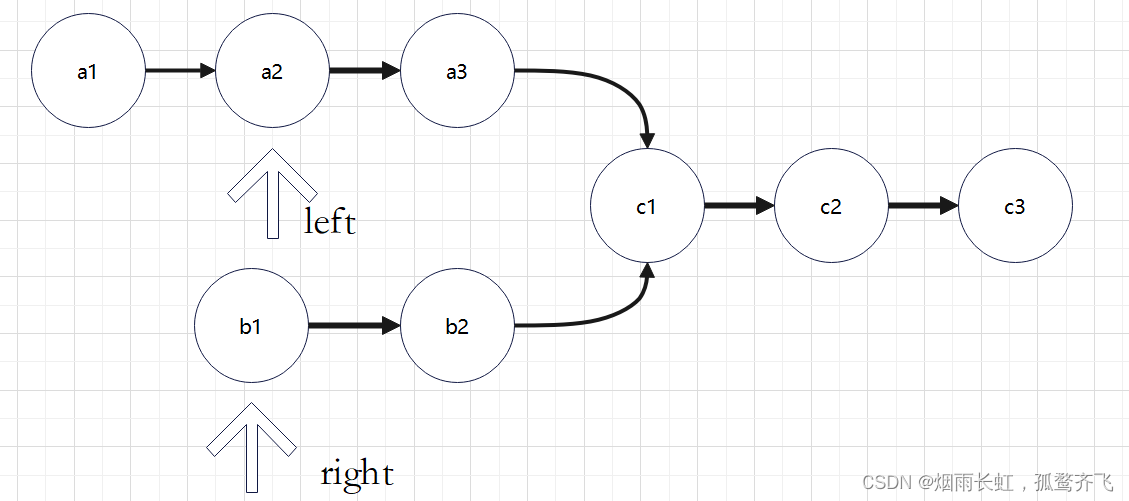
<2>链表的长度不一样,两个指针不会同时到达链表的尾节点,所以我们要先遍历两个链表的长度,然后让长的链表先走 长度差 ,在同时找交点(第一个地址相同的即为交点)。
注意 要考虑两链表是否为空的情况
代码测试一
- 时间复杂度:O(n+m)
- 空间复杂度:O(1)
是一个即节省时间,又不浪费空间的最优解,足以获得面试官的青睐,拿到offer
class Solution { public: ListNode *findFirstCommonNode(ListNode *headA, ListNode *headB) { //判断链表是否为空 if(headA == NULL) return NULL; if(headB == NULL) return NULL; ListNode* curA = headA; ListNode* curB = headB; int countA = 0,countB = 0; //遍历链表长度 while(curA) { countA++; curA = curA->next; } while(curB) { countB++; curB = curB->next; } //两指针都已经遍历到末尾,比较尾节点判断是否相交 if(curA != curB) return NULL; //较长的链表走完差值 int gap = abs(countA-countB); ListNode* longList = headA; ListNode* shortList = headB; if(countB>countA) { longList = headB; shortList = headA; } while(gap--) { longList = longList->next; } //同时遍历两个链表寻找交点 while(longList != shortList) { longList = longList->next; shortList = shortList->next; } return longList; } };
思路二
栈
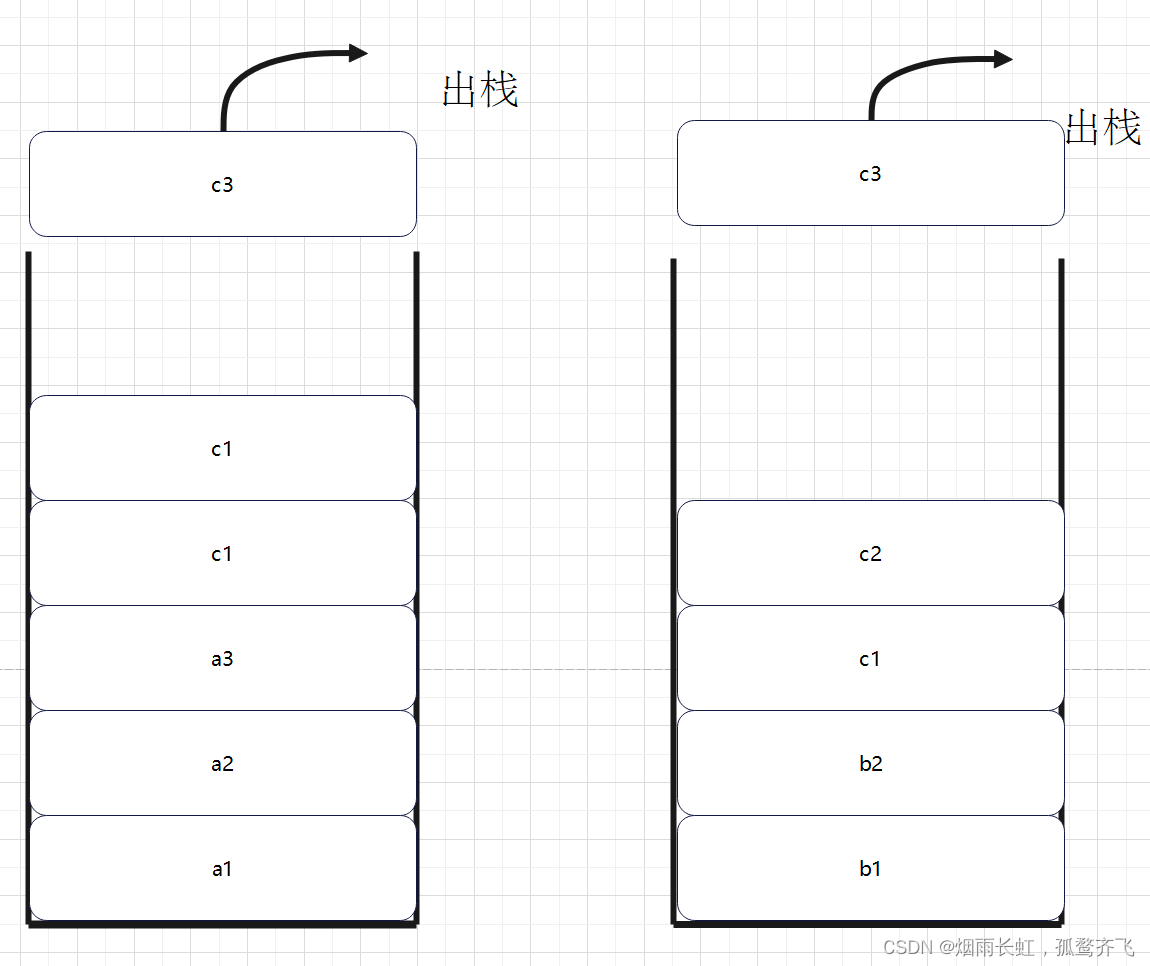
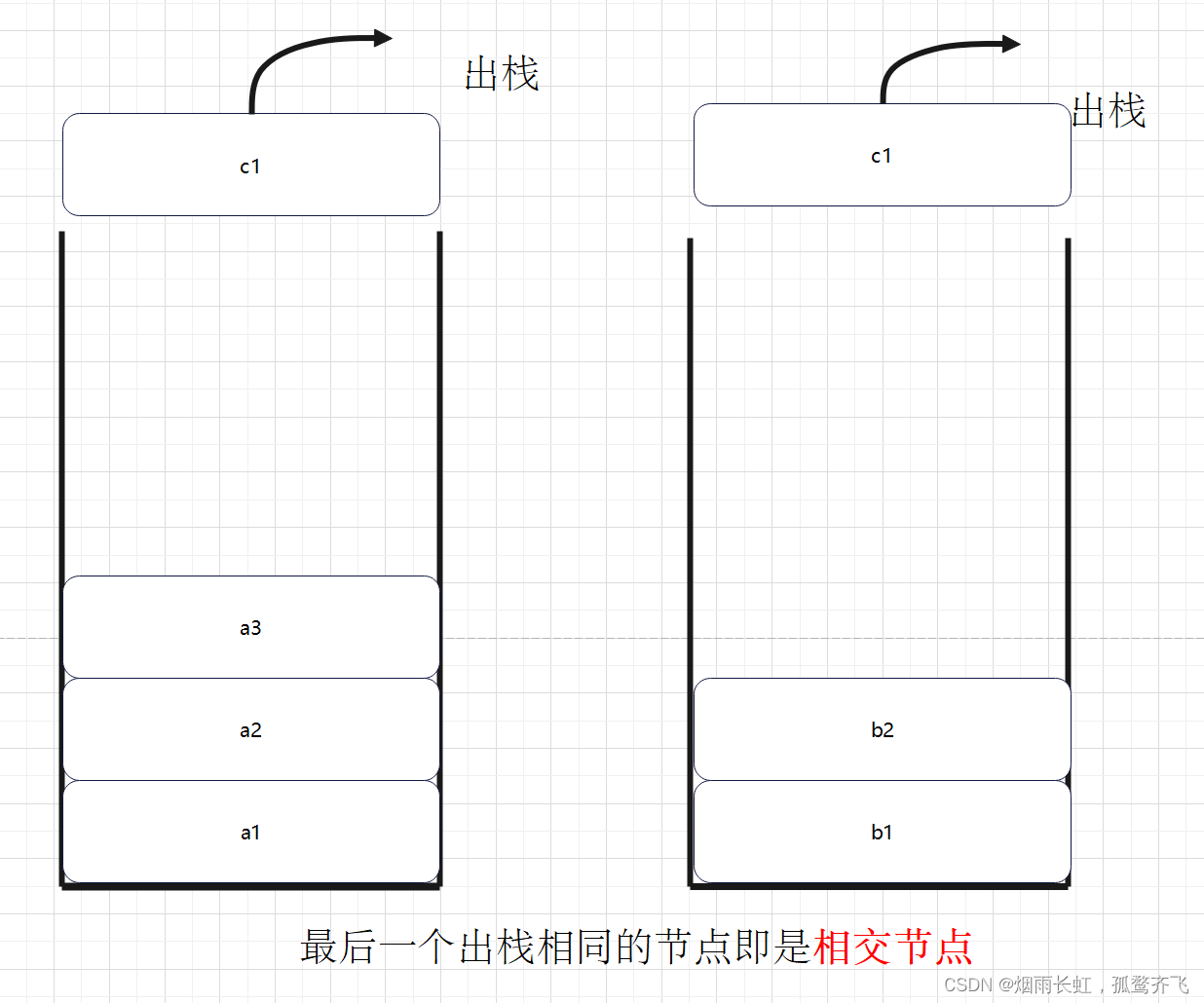
如果两个链表有公共节点,那么公共节点出现在两个链表的尾部。如果我们从两个链表的尾部开始往前比较,那么最后一个相同的节点就是我们要找的节点。可问题是,在单向链表中,我们只能从头节点开始按顺序遍历,最后才能到达尾节点。最后到达的尾节点却要最先被比较,这听起来是不是像 后进先出 ?于是我们就能想到用栈的特点来解决这个问题。
分别把两个链表的节点放入两个 栈 里,这样两个链表的尾节点就位于两个栈的栈顶,接下来比较两个栈顶的节点是否相同。如果相同,则把栈顶弹出接着比较下一个栈顶,直到找到最后一个相同的节点。
代码测试二
- 时间复杂度:O(n+m)
- 空间复杂度:O(n+m)
虽然不是最优解,但是还是比较容易想到和实现
class Solution { public: ListNode *findFirstCommonNode(ListNode *headA, ListNode *headB) { //创建栈 stack<ListNode *> s1, s2; //入栈 for (ListNode *p = headA; p != NULL; p = p->next) { s1.push(p); } for (ListNode *p = headB; p != NULL; p = p->next) { s2.push(p); } ListNode *ans = NULL; //比较栈中元素 for ( ; !s1.empty() && !s2.empty() && s1.top() == s2.top(); s1.pop(), s2.pop()) ans = s1.top(); return ans; } };
献上最后的压轴题:该题是由 剑指offer面试题35 改编题,与原题类似、直观
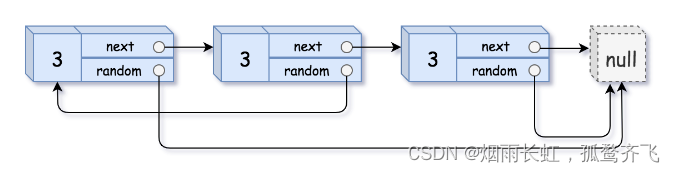
复杂链表的复刻
题目链接:复杂链表的复制
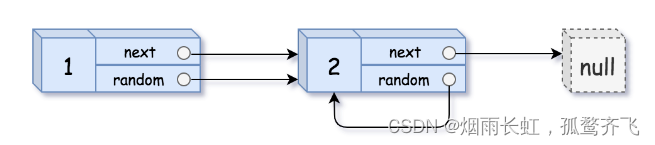
给你一个长度为
n的链表,每个节点包含一个额外增加的随机指针random,该指针可以指向链表中的任何节点或空节点。构造这个链表的 深拷贝。 深拷贝应该正好由
n个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的next指针和random指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。例如,如果原链表中有
X和Y两个节点,其中X.random --> Y。那么在复制链表中对应的两个节点x和y,同样有x.random --> y。返回复制链表的头节点。
用一个由
n个节点组成的链表来表示输入/输出中的链表。每个节点用一个
[val, random_index]表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。你的代码 只 接受原链表的头节点
head作为传入参数。示例 1:
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]示例 2:
输入:head = [[1,1],[2,1]] 输出:[[1,1],[2,1]]示例 3:
输入:head = [[3,null],[3,0],[3,null]] 输出:[[3,null],[3,0],[3,null]]提示:
0 <= n <= 1000-10^4 <= Node.val <= 10^4Node.random为null或指向链表中的节点。
思路
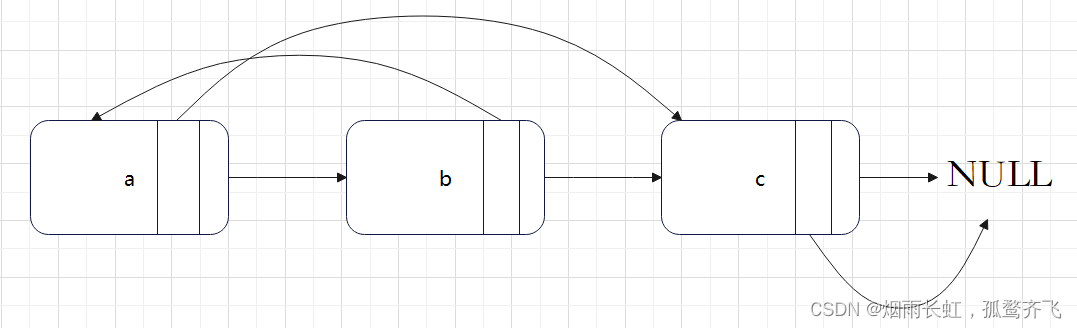
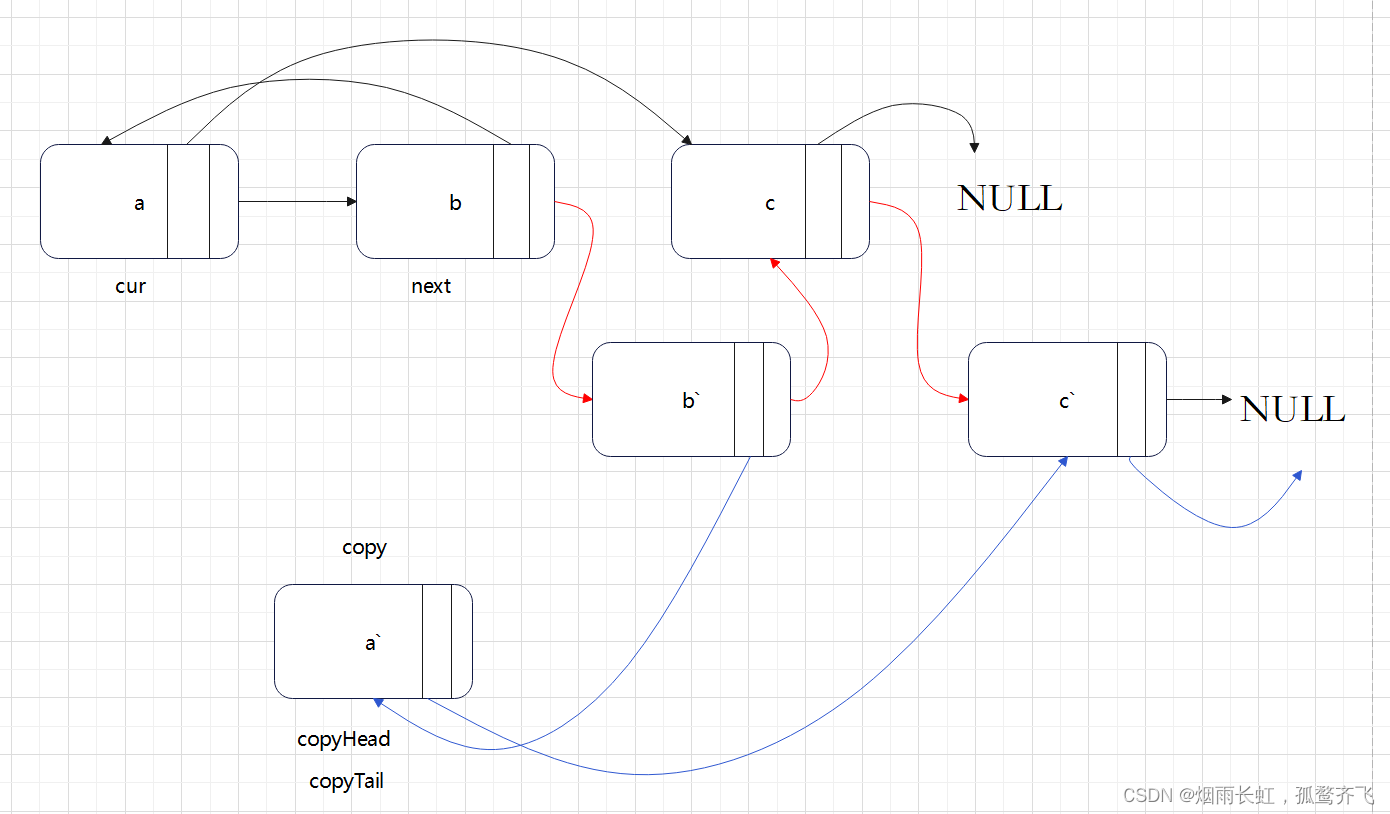
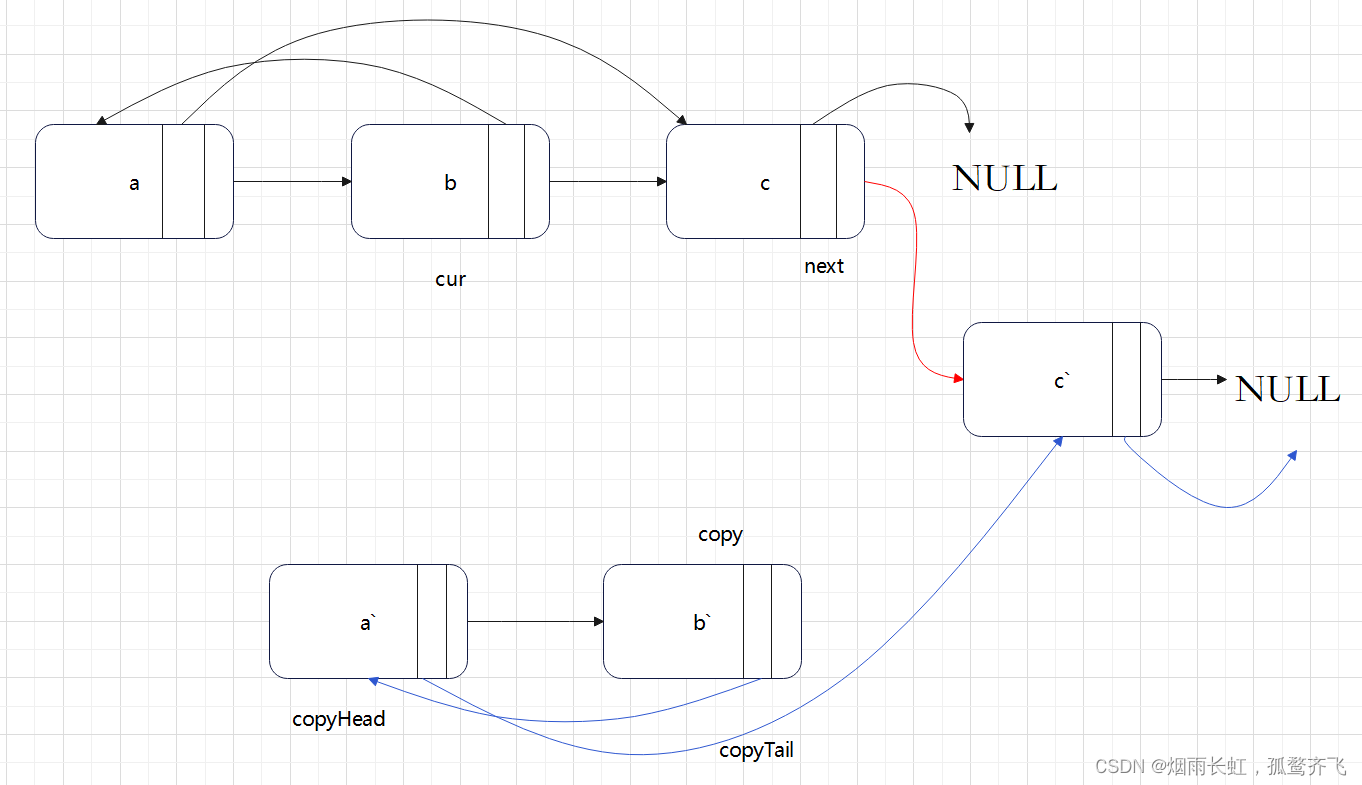
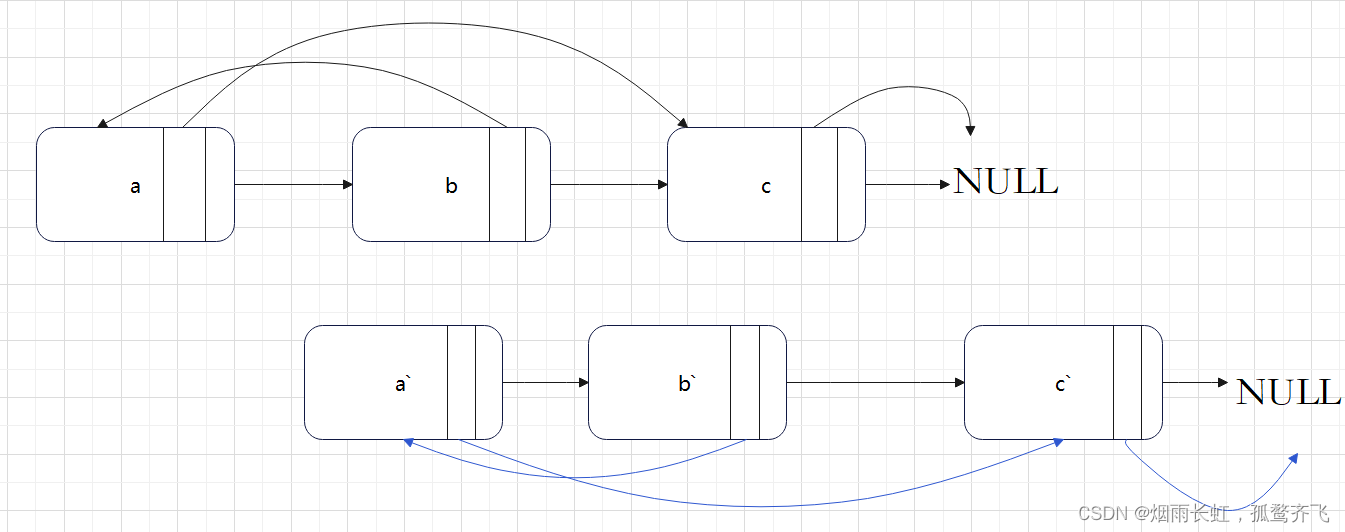
迭代 + 节点拆分
(1)拷贝随机节点
我们首先将该链表中每一个节点拆分为两个相连的节点,例如对于链表 a→b→c ,我们可以将其拆分为 a→a′→b→b′→c→c′,其中 a′ 为原节点 a 的后继拷贝。
这样做的目的:建立原节点和拷贝节点的关联关系,因为位置是挨着的,找到了原节点就找到了拷贝节点
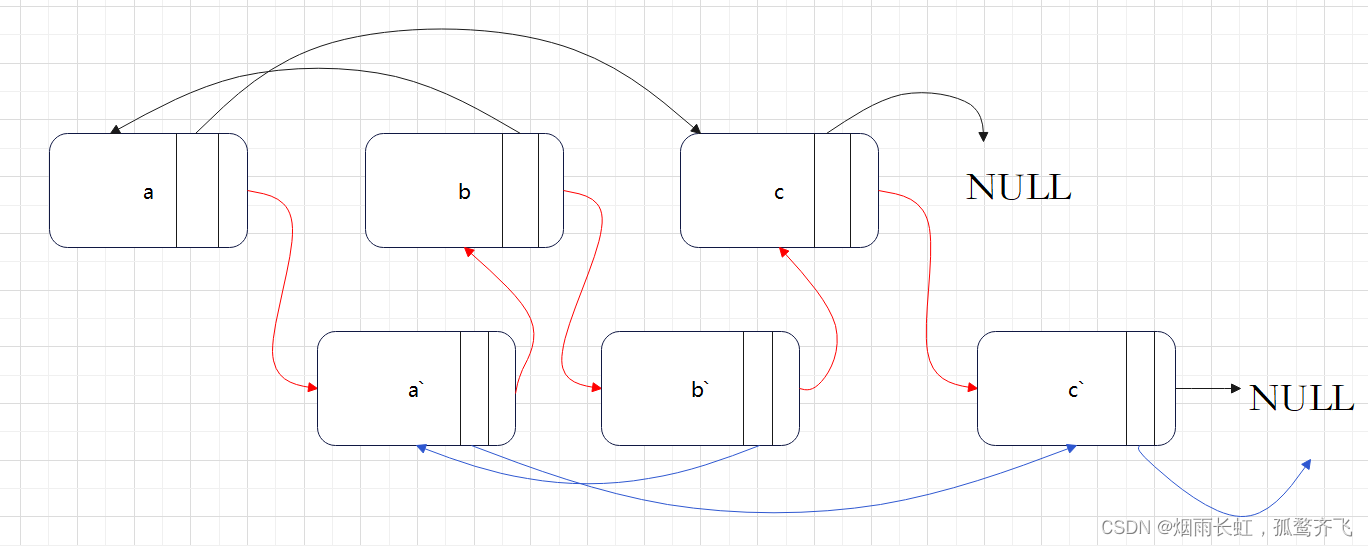
(2)拷贝随机指针
例如可以直接找到每一个拷贝节点 a′ 的随机指针应当指向的节点,即为其原节点 a 的随机指针
random指向的节点 c 的后继拷贝节点 c′ : copy->random = cur->random->next注意 原节点的随机指针可能为空,我们需要特别判断这种情况。
(3)链接原链表和拷贝链表
<1>我们可以在原节点的后继位置进行对该节点的拷贝
<2>然后拷贝节点的随机指针,即为原节点的
random 指针指向节点的后继拷贝节点
<3>链接原链表和拷贝链表
代码测试
时间复杂度:O(n)
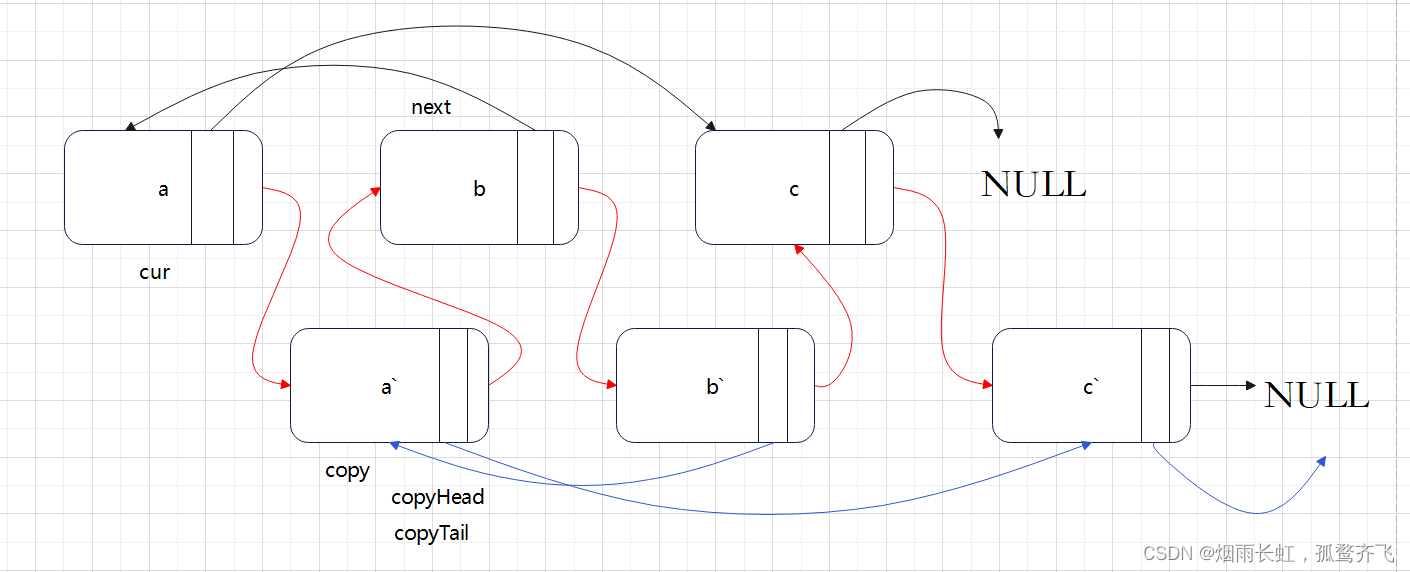
空间复杂度:O(1)class Solution { public: Node* copyRandomList(Node* head) { //拷贝链表,并插入到原节点的后面 Node* cur = head; while(cur) { Node* next = cur->next; Node* copy = (Node*)malloc(sizeof(Node)); copy->val = cur->val; //插入 cur->next = copy; copy->next = next; //迭代往下走 cur = next; } //置拷贝节点的随机指针random cur = head; while(cur) { Node* copy = cur->next; //判断原节点的随机指针是否为空 if(cur->random != NULL) copy->random = cur->random->next; else copy->random = NULL; cur = copy->next; } //链接拷贝节点 Node* copyHead = NULL, *copyTail = NULL; cur = head; while(cur) { Node* copy = cur->next; Node* next = copy->next; //copy解下来尾插 if(copyTail == NULL) { copyHead = copyTail = copy; } else { copyTail->next = copy; copyTail = copy; } cur->next = next; cur = next; } return copyHead; } };



本次的 剑指offer 就介绍到这里, 希望大家早日拿到大厂offer