处理过拟合
-
过拟合
-
定义:对训练集拟合得很好,但在验证集表现较差
神经网络 通常含有大量参数 (数百万甚至数十亿), 容易过拟合
-
处理策略:参数正则化、早停、随机失活、数据增强
-
-
早停
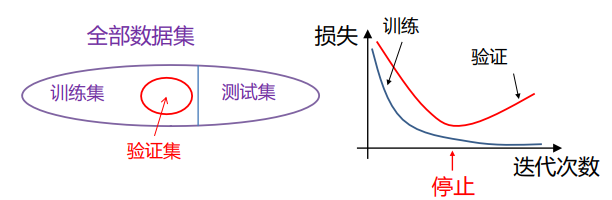
当发现训练损失逐渐下降,但验证集损失逐渐上升时,及时停止优化。
-
随机失活
-
训练过程
在训练迭代过程中,以 p p p(通常为0.5)的概率随机舍弃掉每个隐含层神经元(输出置零)
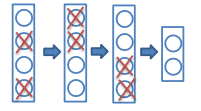
这些被置零的输出,将用于在反向传播中计算梯度
-
优点:
-
一个隐含层神经元不能依赖于其它存在的神经元,因此可以防止神经元出现复杂的相互协同(co-adaptations)
-
相当于在合理的时间内训练了大量不同的网络,并将其结果平均
-
-
测试过程
使用"平均网络(mean network)”,包含所有隐含层神经元
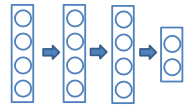
需要调整神经元输出的权重,用来弥补训练中只有一部分被激活的现象
- p=0.5时,将权重减半
- p=0.1,在权重上乘1-p,即0.9
实践中,p在低层设得较小,例如0.2,但在高层设得更大,例如0.5
这样得到的结果与在大量网络上做平均得到的结果类似
-
-
数据增强
数据增强(Data Augmentation)是一种用于优化深度学习模型的方法,它可以通过从现有数据生成新的训练数据来扩展原数据集,从而提高模型的泛化能力和防止过拟合。
数据增强的工具可以对数据进行各种操作和转换,如旋转、缩放、裁剪、翻转、调整亮度、对比度、颜色等,以生成新的、多样的、有代表性的样本。
-
随机翻转
通常只用左右翻转

-
随机缩放和裁剪

- 将测试图像缩放到模型要求的输入大小
- 剪裁一个区域(通常是中心区域)并输入到模型
- 剪裁多个并输入到模型,对输出作平均
-
随机擦除

测试时可以输入整张图像
-