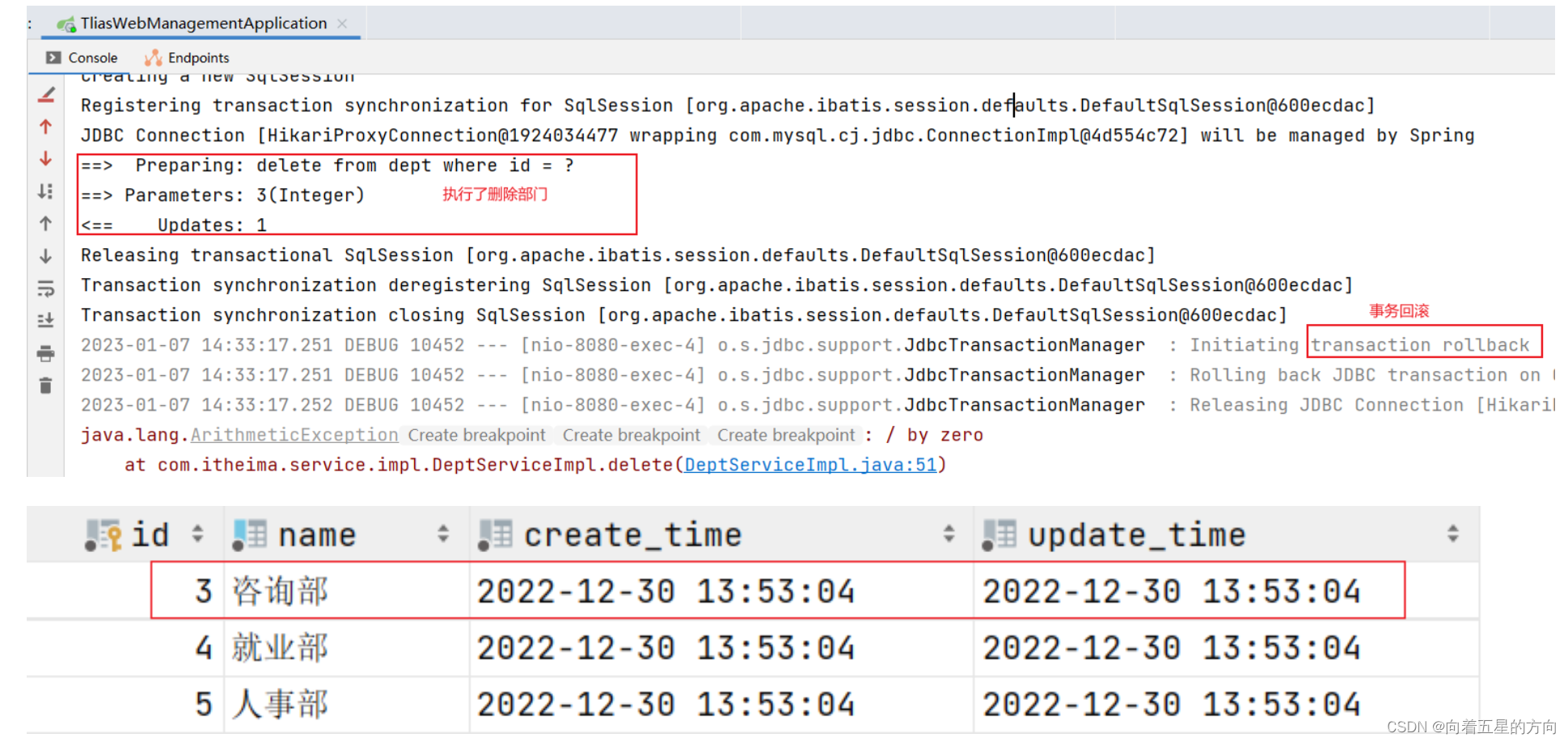
一、什么是文本分析?
作为一种新兴的基于定性研究的量化分析方法,文本分析法能够揭示文本的变化与特征,为经典问题的研究提供了新思路。
文本分析应用于多个领域,比如在旅游业中,可以通过文本分析去研究旅游形象感知情况,比如在经济学中,可以通过文本分析进行研究目前保险政策等等,以及还有其它领域都会应用到文本分析。
二、文本分析常见研究步骤
文本分析的常见步骤有五步,包括数据搜集、分词、数据清洗、特征提取以及建模和其它分析具体如下图:

- 数据搜集
文本分析的第一步需要进行数据搜集,获取文本数据的方式一般包括网络平台、媒体平台、新闻、知网、论坛等等。 - 分词
计算机会将我们导入的字符串进行分词划分便于后续的分析。 - 数据清洗
在文本分析的过程中,首先需要对文本进行预处理,预处理是非常重要的一步,它直接影响后续分析的准确性和可靠性。标点符号和停用词的去除是预处理的常见操作,可以有效地去除文本中的无关信息,提高分析效率。同时,对文本进行分词、去除停用词等操作,也有助于提取出更准确的关键词和主题。除此之外还会通过关键词词频,分布等等进行剖析文本的主题,以及有些研究者还会通过分析情感词去了解文本的情感倾向。 - 特征提取
数据清洗后进行特征提取,比如可以使用可视化板块里的tf-idf,其是常用的特征提取方法,它考虑了词汇在文本中的重要性和在语料库中的普遍性。TF-IDF值越高,表示该词汇在文本中的重要性越高,以及还有其它方法。 - 后续分析
利用文本数据进行后续分析,比如可视化图形展示、主题分析,聚类等等,下个模块会有说明。
三、SPSSAU如何操作?
文本分析的操作演示:通过SPSSAU主系统左侧仪表盘点击‘文本分析模块’进入。

进入文本分析模块后,研究者可以自行选择上传数据,包括粘贴文本进行上传或者上传txt/excel文件等(大小限制5m内)。如下图所示:

然后就可以根据自己的需求进行选择分析方法,进行分析:

四、文本分析都能干什么?

文本分析的应用有很多,以SPSSAU为例,其可以进行文本可视化(词云分析)、文本情感分析、文本聚类分析、社会网络关系图、LDA主题分析语义分析等等。
文本可视化
文本分析模块中,最重要和最基础的为展示分词结果,通常是使用词云进行展示。在‘词云分析等’中,SPSSAU提供四种功能,分别是词云分析、自定义词云、词定位和tf-idf。
- 词云分析
词云图直观展示住建很2023年12月共41条新闻内容的关键词信息,住户、城市、发展、建设等均是关键信息。默认是展示前100个高频关键词,可自主设置该数字。也可修改词云风格和下载该词云图。

- 自定义词云
如果对词云分析不满意,也可以使用自定义词云,研究者可将整理好的信息,包括关键词和其词频,直接粘贴(或者自主编辑)在表格中,然后就会出现相应的词云图。

- 词定位
通过词定位可以观察到某个词,具体出现在那些行中,可通过行号进行查看。

- tf-idf
文本分析中,tf-idf是个重要的指标,其反映某关键词在整份数据中的重要性程度,当tf-idf越高时,其重要性越高。其与词频的意义不尽相同,词频是指出现次数,而tf-idf更加关注于关键词的重要性程度。其中:tf-idf = tf * idf;其中tf:tf = n / N,其中n为某关键词的词频,N为整份数据关键词词频总和,N是个固定值,当n即词频越高时tf越高,说明该关键词越重要;idf = log(D/(1+d)),log是取对数,D为数据的行数,d为数据中某个词在多少行中出现过。D为固定值,d值越大即到处出现时idf反而越小,d值越小即并非到处出现时idf反而越高,idf越高代表某关键词重要性越高。

文本情感分析
目前,主流的文本情感分析方法可分为基于情感词典、机器学习和深度学习三类。基于情感词典的方法是传统的情感分析方法,它利用情感词典中的情感极性计算目标语句的情感值。尽管基于词典的分析方法实现简单,但其也有缺点,其准确率在很大程度上依赖于构建词典的质量,并且构建情感词典需要耗费大量人力物力,对新词的适应能力也较差。
文本分析模块中,SPSSAU共提供两种方式的情感分析,分别是按词情感分析和按行情感分析。按词情感分析是指针对提取的关键词进行情感分析,并且进行可视化展示;按行情感分析是指针对分析的原始数据以‘行’为单位进行情感分析,并且可下载具体的情感得分值信息等。

文本聚类
文本聚类即:将需要分析的关键词进行聚类分析,并且进行可视化展示,SPSSAU共提供两种文本聚类方式,分别是按词聚类和按行聚类。

社会网络关系图
社会网络关系图展示关键词之间的关系情况,此处的关系是指‘共词矩阵’,即两个关键词同时出现的频数情况,将‘共词矩阵’信息使用可视化方式进行呈现出来。
共词矩阵:主要用于表示关键词之间的关联强度。它是一个由行和列组成的矩阵,通过矩阵中的元素来表示关键词之间的关联程度。在共词矩阵中,元素的值越大,说明两个关键词之间的关联性越强,即它们共同出现的频率越高。

社会网络关系图:社会网络关系图在文本分析中的应用主要是为了揭示文本中各个实体之间的关联关系。这种关系图可以帮助我们更好地理解文本的主题和内容,发现文本中的隐藏信息和模式。

LDA主题分析
主题模型是指用来统计一系列文档中出现的主题个数的一种统计模型,LDA可以通过无监督的学习方法发现文本中隐含的主题信息。LDA将主题当成是文档内容的浓缩,所以我们可以通过LDA将大规模的语料库中的信息生成文档,生成的文档可以看作是由许多主题构成的,构成主题的每一个词汇又都是无序的,从而达到降低文档维数的效果,大大降低了问题的复杂性,同时也具有语义上的特征。SPSSAU结果如下(气泡大小表示该主题的重要性情况,以及条形的长度表示该主题时该词的权重大小情况):

新词发现
无法被词典识别到的,新词发现时涉及到两个关键指标,分别是:信息熵和互信息。信息熵越大即意味着某词越容易与其它词组合在一起形成一个词语,信息熵越小即意味着某词越不容易与其它词组合在一起。

停用词/情感词
停用词:停用词是指在文本中出现频率较高但对文本主题和内容贡献较小的词,停用词的去除可以提高分析效率和精度;

情感词:情感词是指表达情感或情感倾向的词,情感词的识别和分析可以帮助我们更好地理解文本的情感内涵;

五、使用SPSSAU进行文本分析
“这个冬天,哈尔滨火了。” 进入12月份以来,从各地飞往哈尔滨赏冰乐雪的游客络绎不绝,很多小伙伴在去“尔滨”会提前看一下攻略,但是看了几篇下来大家攻略各有千秋。小编选取了携程网最新攻略共10篇进行文本分析(结论不作为参考,仅供案例参考)。
1、搜索数据
在携程网搜索“哈尔滨市”相关攻略文本,以最近的旅游攻略进行搜集。
2、上传spssau平台
以文字粘贴的形式,上传至SPSSAU平台。

3、数据清洗
上传数据前已经进行简单处理过,包括标点符号,特殊字符等等。
4、开始文本分析
从文本中提取出100个关于哈尔滨市旅游攻略的高频词汇。如下表:

首先从词性角度分析,高频词汇中地名名词、形容旅游感受的形容词较多,具体集中在景点、美食体验。词频越高说明旅游者对此词关注度越高。通过上表的高频词汇分析可知,中央大街、雪乡、教堂、松花江等旅游景点位序较高,说明游客对上述景点的关注度较高。
同时也可以将哈尔滨市旅游攻略高频词以词云图的形式可视化展示,在词云图中,词频越高的词语会以较大的形式呈现出来,词频越低的词语会以较小的形式呈现出来。

并且如果研究者想要了解某词出现在哪些地方,也可以使用“词定位”进行查看,比如对“中央大街”比较感兴趣,点击“中央大街”就可以查看他出现在哪些地方。

并且想要查看关键词在整份数据中的重要性程度,发现几个攻略中,“麻辣烫”比较重要。

并且也可以使用文本聚类:

从聚类类别1中可以看出,吃占比重较大,比如“巧克力”、“秋林”等(结果有些牵强,可能是与数据过少有关,案例仅供演示)。
更多内容可以登录SPSSAU网站自行查看。










![基于完全二叉树实现线段树-- [爆竹声中一岁除,线段树下苦踌躇]](https://img-blog.csdnimg.cn/direct/f31f4264ed4247c1afc2364cbc720884.jpeg#pic_center)