异构计算关键技术之mmap
一、背景
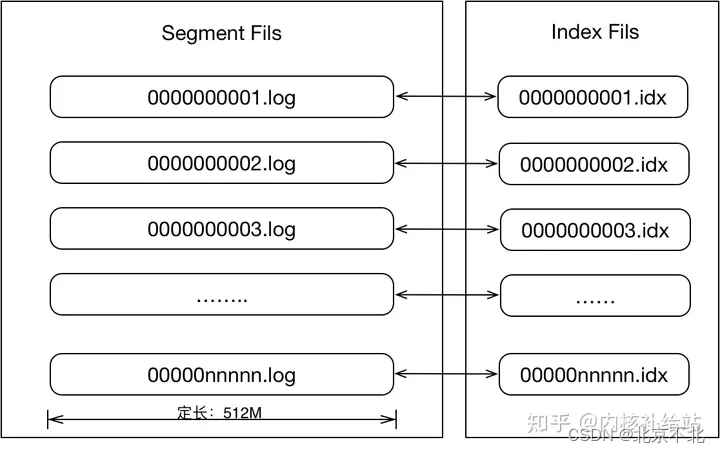
1. 日志存储系统
case 1:分布式日志存储系统,是一个基于raft协议自研分布式日志存储系统,logstore则是底层存储引擎。
logstore中,使用mmap对数据文件读写。
logstore的存储结构简化如下图:
2. 普通bin文件读取操作
最近博主需要读取一个bin文件,然后实时和FPGA接收到的数据进行比对,验证逻辑的正确性,采用的mmap技术。
...
int id = open(Parameter::xxxbin.c_str(), O_RDONLY);
if (fd < 0) {
std::cout << "cannot open file: " << xxxbin << std::endl;
return -1;
}
m_binbuff = (char *)mmap(NULL, m_fileSize, PROT_READ, MAP_SHARED, fd, 0);
if(nullptr == m_binBuff){
std::cout << "Can't mmap file: " << Parameter::xxxbin << std::endl;
return;
}
close(fd);
3. Ceph分布式文件系统性能关键技术
分布式文件系统在处理大规模数据时起着至关重要的作用。
为了满足日益增长的数据存储需求,Ceph作为一种先进的分布式文件系统方案被广泛使用。
然而,在Ceph的架构中,为了实现高性能和低延迟,诸如mmap等关键技术成为了不可或缺的一部分。
二、什么是mmap
在《深入理解计算机系统》书中,mmap定义为:linux通过将一个虚拟内存区域与一个磁盘上的对象(object)关联起来,以初始化这个虚拟内存的内容,这个过程称为内存映射(memory mapping)。
三、mmap的原理
1. mmap在进程虚拟内存做了什么
我们先来简单看一下mapping一个文件,mmap做了什么事情。如下图所示:
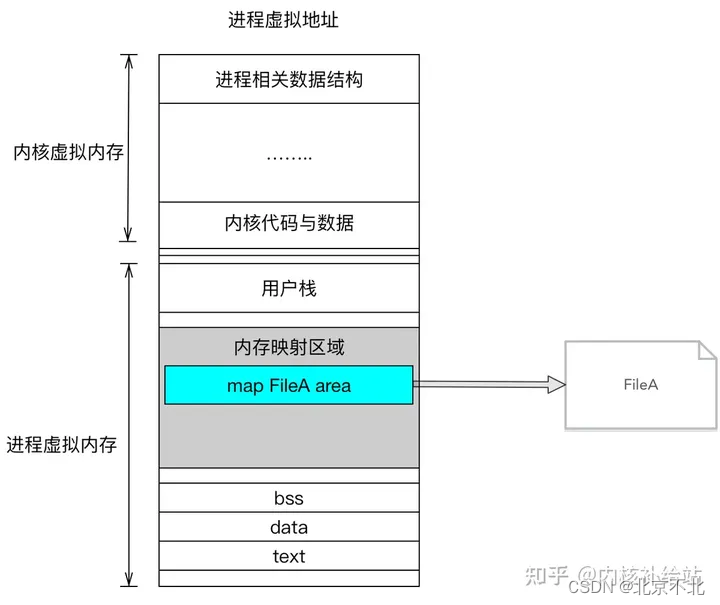
假设我们mmap的文件是FileA,在调用mmap之后,会在进程的虚拟内存分配地址空间,创建映射关系。
这里值得注意的是,mmap只是在虚拟内存分配了地址空间,举个例子,假设上述的FileA(dd创建)是5M大小:

rogeneous_compute_mmap%2F1707376111820.png&pos_id=img-YxH1LHWD-1707567132451)
在mmap之后,查看mmap所在进程的maps描述,可以看到:

由上可以看到,在mmap之后,进程的地址空间7f1da0a0f000-7f1da0f0f000被分配,并且map到FileA,7f1da0f0f000减去7f1da0a0f000,刚好是5242880(ps: 这里是整个文件做mapping)
2. mmap在物理内存做了什么
在Linux中,VM系统通过将虚拟内存分割为称作虚拟页(Virtual Page,VP)大小固定的块来处理磁盘(较低层)与上层数据的传输。
一般情况下,每个页的大小默认是4096字节。同样的,物理内存也被分割为物理页(Physical Page,PP),也为4096字节。
上述例子,在mmap之后,如下图:
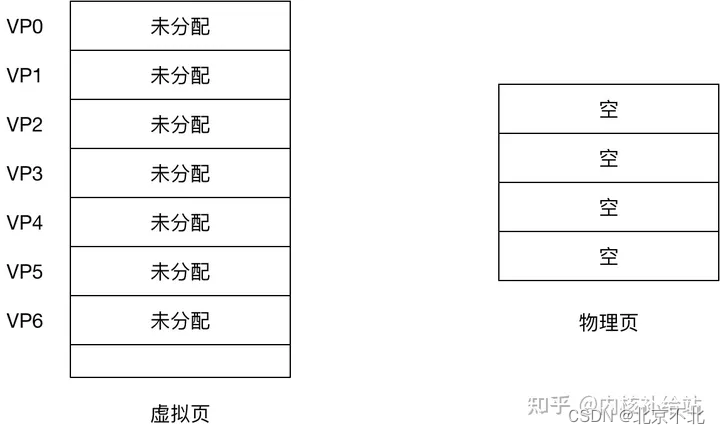
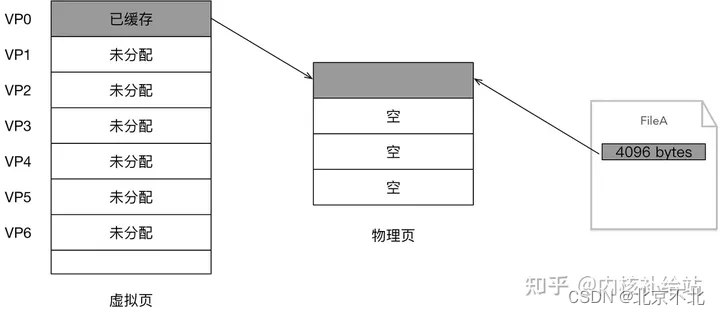
在mmap之后,并没有在将文件内容加载到物理页上,只上在虚拟内存中分配了地址空间。当进程在访问这段地址时(通过mmap在写入或读取时FileA),若虚拟内存对应的page没有在物理内存中缓存,则产生"缺页",由内核的缺页异常处理程序处理,将文件对应内容,以页为单位(4096)加载到物理内存,注意是只加载缺页,但也会受操作系统一些调度策略影响,加载的比所需的多,这里就不展开了。
缺页处理后,如下图:
3. mmap的分类
mmap有两种类型,一种是有backend,一种是没有backend。
有backend:

这种模式将普通文件做memory mapping(非MAP_ANONYMOUS),所以在mmap系统调用时,需要传入文件的fd。这种模式常见的有两个常用的方式,MAP_SHARED与MAP_PRIVATE,但它们的行为却不相同。
(1) MAP_SHARED
可以从两个角度去看:
1. 进程间可见:这个被提及太多,就不展开讨论了
2. 写入/更新数据会回写backend,也就是回写文件:这个是很关键的特性,是在Logstore设计实现时,需要考虑的重点。Logstore的一个基本功能就是不断地写入数据,从实现上看就是不断地mmap文件,往内存写入/更新数据以达到写入文件的目的。但物理内存是有限的,在写入数据超过物理内存时,操作系统会进行页置换,根据淘汰算法,将需要淘汰的页置换成所需的新页,而恰恰因为是有backend的,所以mmap对应的内存是可以被淘汰的(若内存页是"脏"的,则操作系统会先将数据回写磁盘再淘汰)。这样,就算mmap的数据远大于物理内存,操作系统也能很好地处理,不会产生功能上的问题。
(2) MAP_PRIVATE
这是一个copy-on-write的映射方式。虽然他也是有backend的,但在写入数据时,他会在物理内存copy一份数据出来(以页为单位),而且这些数据是不会被回写到文件的。这里就要注意,因为更新的数据是一个副本,而且不会被回写,这就意味着如果程序运行时不主动释放,若更新的数据超过可用物理内存+swap space,就会遇到OOM Killer。
无backend:
无backend通常是MAP_ANONYMOUS,就是将一个区域映射到一个匿名文件,匿名文件是由内核创建的。
因为没有backend,写入/更新的数据之后,若不主动释放,这些占用的物理内存是不能被释放的,同样会出现OOM Killer。
四、mmap比内存+swap空间大情况下,是否有问题
到这里,这个问题就比较好解析了。我们可以将此问题分离为:
- 虚拟内存是否会出问题
- 物理内存是否会出问题
虚拟内存是否会出问题:
回到上述的"mmap在进程虚拟内存做了什么",我们知道mmap会在进程的虚拟内存中分配地址空间,比如1G的文件,则分配1G的连续地址空间。那究竟可以maping多少呢?在64位操作系统,寻址范围是2^64 ,除去一些内核、进程数据等地址段之外,基本上可以认为可以mapping无限大的数据(不太严谨的说法)。
物理内存是否会出问题:
回到上述"mmap的分类",对于有backend的mmap,而且是能回写到文件的,映射比内存+swap空间大是没有问题的。但无法回写到文件的,需要非常注意,主动释放。
五、mmap的性能
mmap的性能经常与系统调用(write/read)做对比。
我们将读写分开看,先尝试从原理上分析两者的差异,然后再通过测试验证。
1. mmap的写性能
我们先来简单讲讲write系统调用写文件的过程:
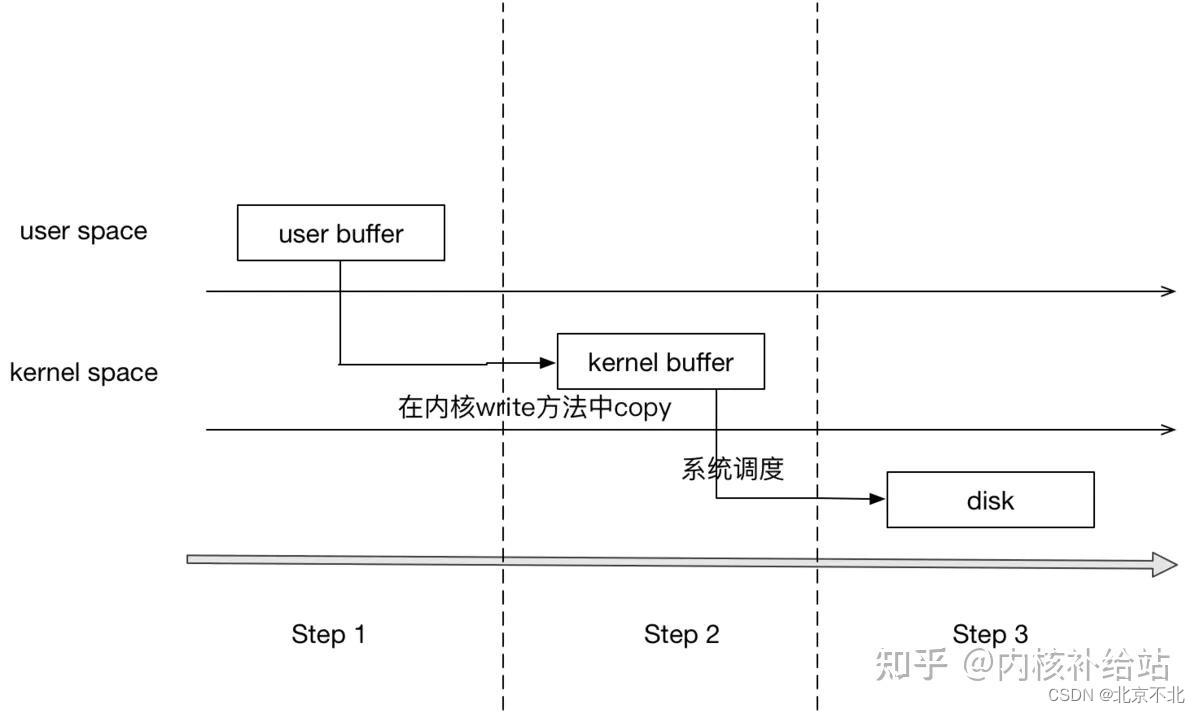
Step1:进程(用户态)调用write系统调用,并告诉内核需要写入数据的开始地址与长度(告诉内核写入的数据在哪)。
Step2:内核write方法,将校验用户态的数据,然后复制到kernel buffer(这里是Page Cache)。
Step3: 由操作系统调用,将脏页回写到磁盘(通常这是异步的)
再来简单讲讲使用mmap时,写入文件流程:
Step1:进程(用户态)将需要写入的数据直接copy到对应的mmap地址(内存copy)
Step2:
(2.1) 若mmap地址未对应物理内存,则产生缺页异常,由内核处理
(2.2) 若已对应,则直接copy到对应的物理内存
Step3:由操作系统调用,将脏页回写到磁盘(通常这是异步的)
系统调用会对性能有影响,那么从理论上分析:
1. 若每次写入的数据大小接近page size(4096),那么write调用与mmap的写性能应该比较接近(因为系统调用次数相近)
2. 若每次写入的数据非常小,那么write调用的性能应该远慢于mmap的性能。
下面我们对两者进行性能测试:
每次写入大小 | mmap 耗时 | write 耗时
--------------- | ------- | -------- | --------
| 1 byte | 22.14s | >300s
| 100 bytes | 2.84s | 22.86s
| 512 bytes | 2.51s | 5.43s
| 1024 bytes | 2.48s | 3.48s
| 2048 bytes | 2.47s | 2.34s
| 4096 bytes | 2.48s | 1.74s
| 8192 bytes | 2.45s | 1.67s
| 10240 bytes | 2.49s | 1.65s
可以看到mmap在100byte写入时已经基本达到最大写入性能,而write调用需要在4096(也就是一个page size)时,才能达到最大写入性能。
从测试结果可以看出,在写小数据时,mmap会比write调用快,但在写大数据时,反而没那么快。
2. mmap的读性能
我们还是来简单分析read调用与mmap的流程:
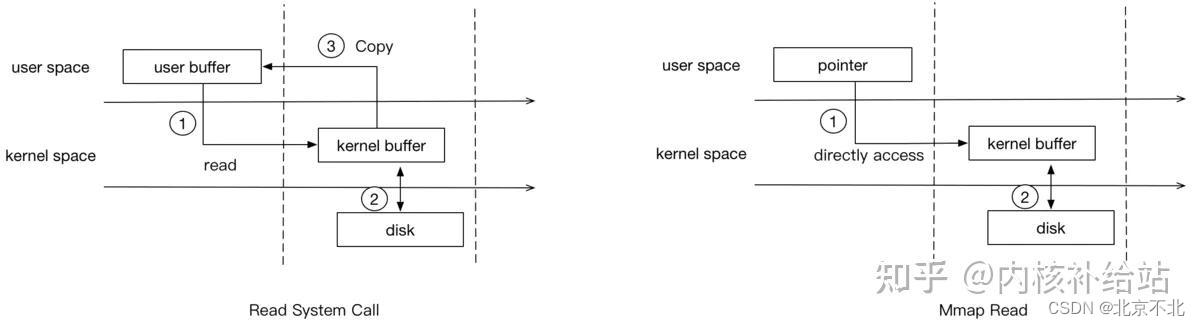
从图中可以看出,read调用确实比mmap多一次copy。因为read调用,进程是无法直接访问kernel space的,所以在read系统调用返回前,内核需要将数据从内核复制到进程指定的buffer。但mmap之后,进程可以直接访问mmap的数据(page cache)。
从原理上看,read性能会比mmap慢。
每次读取大小 | mmap 耗时 | write 耗时
--------------- | ------- | -------- | --------
| 1 byte | 8215.4ms | > 300s
| 100 bytes | 86.4ms | 8100.9ms
| 512 bytes | 16.14ms | 1851.45ms
| 1024 bytes | 8.11ms | 992.71ms
| 2048 bytes | 4.09ms | 636.85ms
| 4096 bytes | 2.07ms | 558.10ms
| 8192 bytes | 1.06ms | 444.83ms
| 10240 bytes | 867.88µs | 475.28ms
由上可以看出,在read上面,mmap比write的性能差别还是很大的。测试结果与理论推导吻合。
3. 总结
mmap被广泛应用于提高读取性能。传统上,读取数据需要通过复制数据到用户空间,这一过程涉及系统调用和数据拷贝操作,消耗大量的CPU资源和时间。而通过使用mmap,用户可以直接在内存中读取文件,避免了这些开销。因此,在Ceph中使用mmap可以提高文件读取的效率。
然而,并不是所有场景下mmap都适用。比如,对于大型文件或者需要修改文件内容的场景,mmap可能并不是最佳选择。因为一旦使用mmap映射了文件,文件的全部内容都会加载到内存中,这会导致内存消耗过大。并且,修改文件内容会引起复制写操作,降低写入性能。因此,在使用mmap时,需要根据实际情况进行权衡和选择。
六、未完待续
下章将继续介绍异构计算的关键技术:多线程的深度探索与应用。
欢迎关注知乎:北京不北
欢迎+V:beijing_bubei
欢迎关注douyin:near.X (北京不北)
获得免费答疑,长期技术交流。
七、参考文献
https://zhuanlan.zhihu.com/p/553423923









![基于完全二叉树实现线段树-- [爆竹声中一岁除,线段树下苦踌躇]](https://img-blog.csdnimg.cn/direct/f31f4264ed4247c1afc2364cbc720884.jpeg#pic_center)