基于R的Bilibili视频数据建模及分析——聚类分析篇
文章目录
- 基于R的Bilibili视频数据建模及分析——聚类分析篇
- 0、写在前面
- 1、数据分析
- 1.1 聚类分析
- 1.2 聚类统计
- 1.3 系统聚类
- 1.4 Kmeans与主成分分析
- 2、参考资料

0、写在前面
实验环境
- Python版本:
Python3.9 - Pycharm版本:
Pycharm2021.1.3 - R版本:
R-4.2.0 - RStudio版本:
RStudio-2021.09.2-382
该实验一共使用4个数据集,但文章讲述只涉及到一个数据集,并且对于每个数据集的分析,数据大小在110条左右
- 数据来源于和鲸社区
https://www.heywhale.com/mw/dataset/62a45d284619d87b3b2b9147/file
数据字段描述说明
- title:视频的标题
- duration:视频时长
- publisher:视频作者
- descriptions:视频描述信息
- pub_time:视频发布时间
- view:视频播放量
- comments:视频评论数
- praise:视频点赞量
- coins:视频投币数
- favors:视频收藏数
- forwarding:视频转发量
1、数据分析
数据分析阶段一共分为三个角度进行分析,分别是
变量相关性分析、聚类分析、建模-因子分析
下文讲述聚类分析阶段
1.1 聚类分析
该阶段分为
聚类统计、系统聚类以及Kmeans与主成分分析
viewArr = data1[,6]
forwardingArr = data1[,11]
view = c(viewArr)
forwarding = c(forwardingArr)
1.2 聚类统计
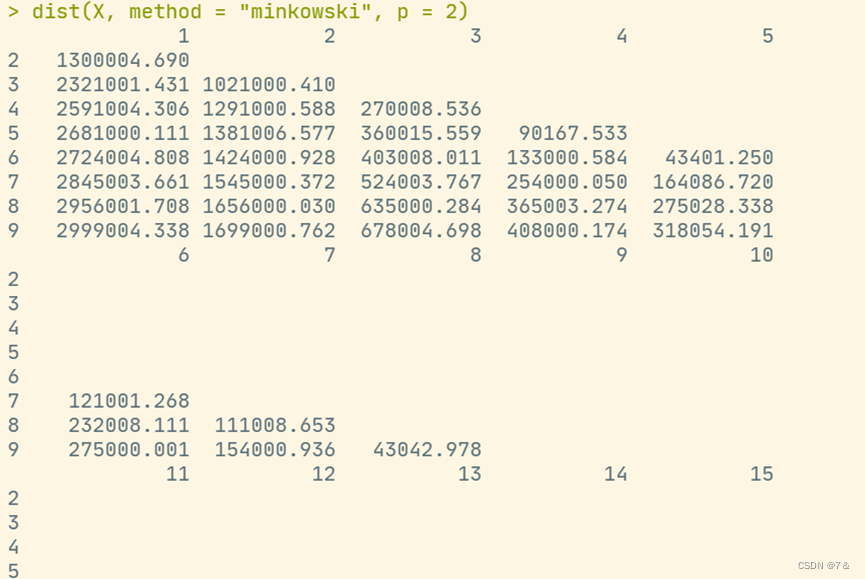
- 欧氏距离
X = cbind(view, forwarding)
dist(X)
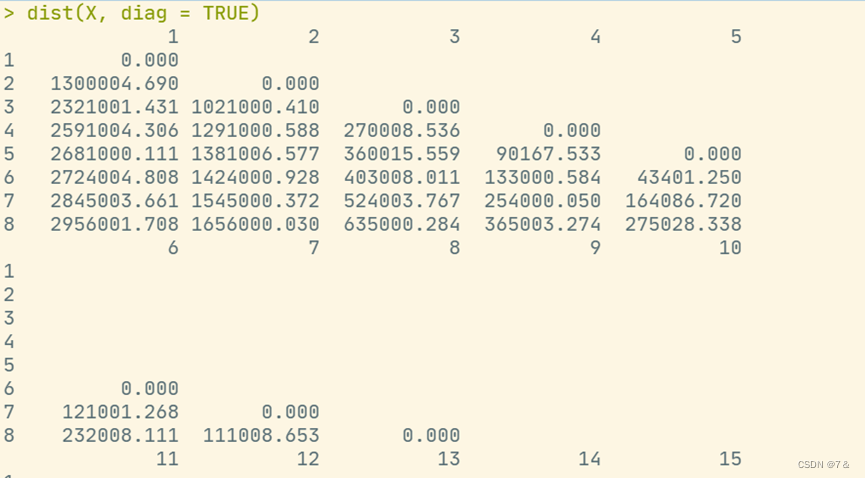
dist(X, diag = TRUE)
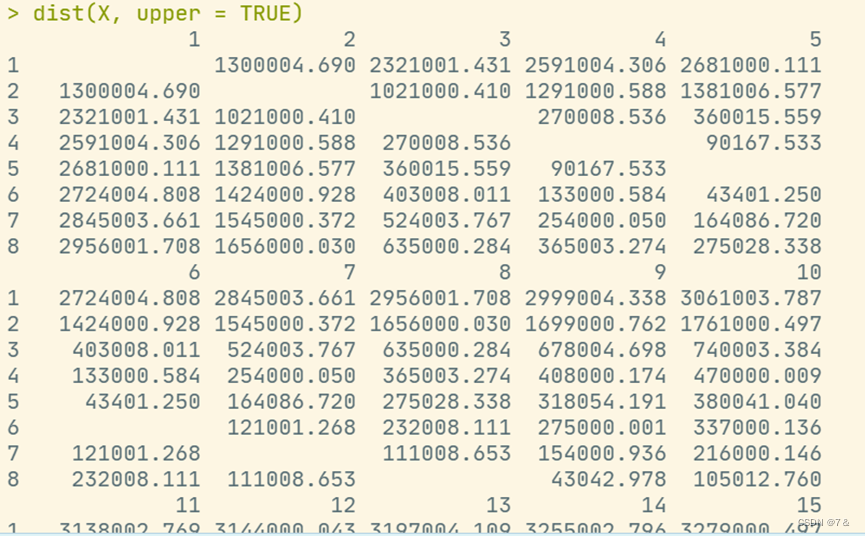
dist(X, upper = TRUE)

添加主对角线距离
添加上三角距离
- 马氏距离
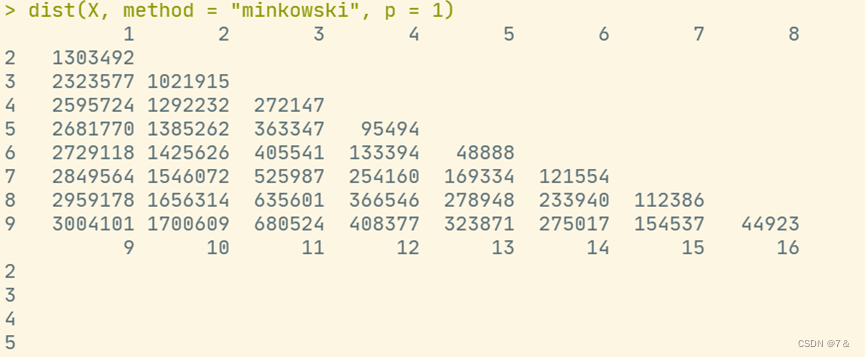
dist(X, method = "manhattan")
数据集1的马氏距离如下图所示:

1.3 系统聚类
针对数据集1,观看量view进行系统聚类
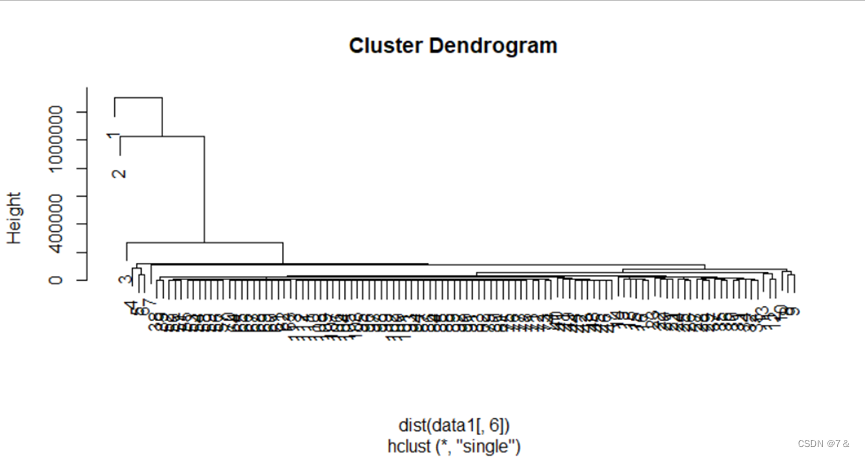
- 最短距离法:
hc=hclust(dist(data1[,6]),method = "single")
plot(hc)
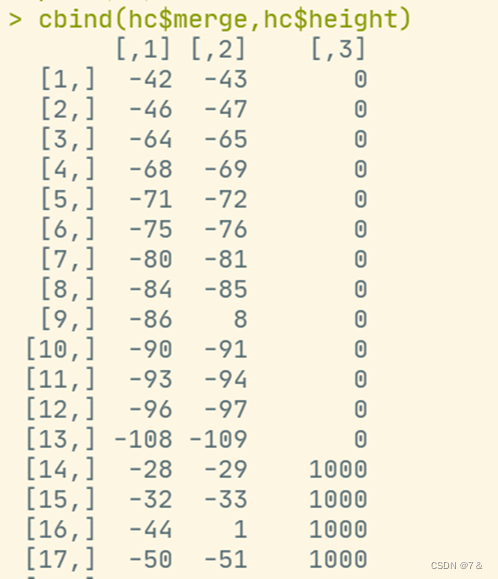
cbind(hc$merge,hc$height)
cutree(hc,5:1)

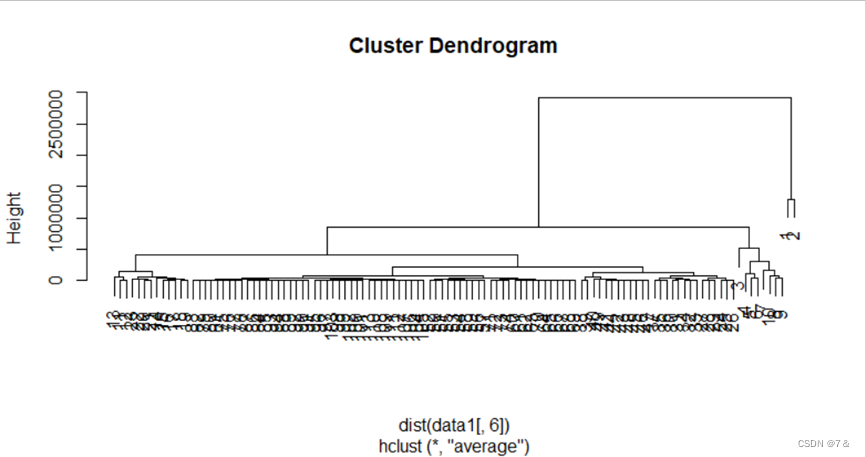
- 类平均法:
hc=hclust(dist(data1[,6]),method = "average")
plot(hc)
cbind(hc$merge,hc$height)
cutree(hc,5:1)
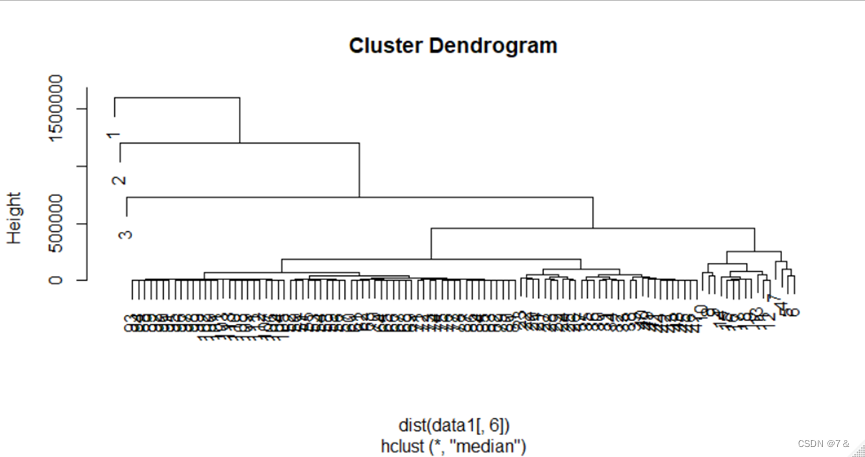
- 中间距离法:
hc=hclust(dist(data1[,6]),method = "median")
plot(hc)
cbind(hc$merge,hc$height)
cutree(hc,5:1)
1.4 Kmeans与主成分分析
针对数据集1,Kmeans是聚类的重要实现之一
- 使用
silhouette方法聚类,查看聚类的数目
library(factoextra)
fviz_nbclust(data1[6:11],kmeans,method = "silhouette")
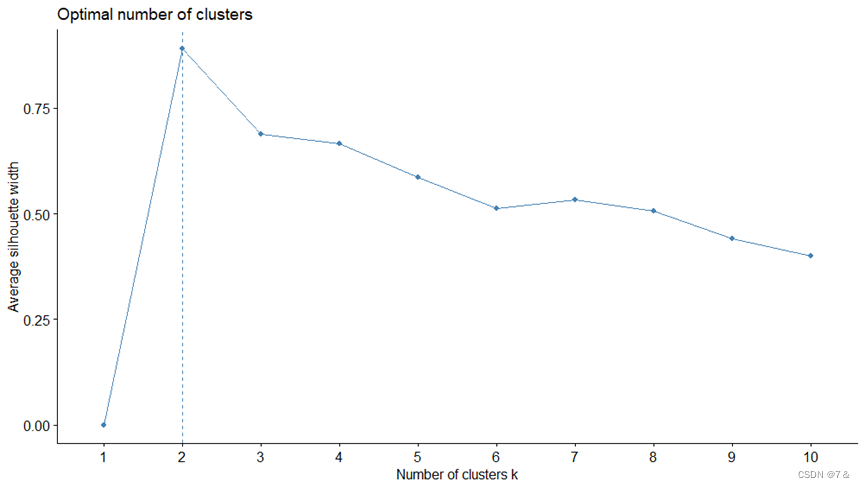
得到结果图,以此判断出数据集1使用kmeans方法聚类需要聚多少类
library(cluster)
gap_stat <- clusGap(data1[6:11], FUN = kmeans,K.max = 10)
fviz_gap_stat(gap_stat)
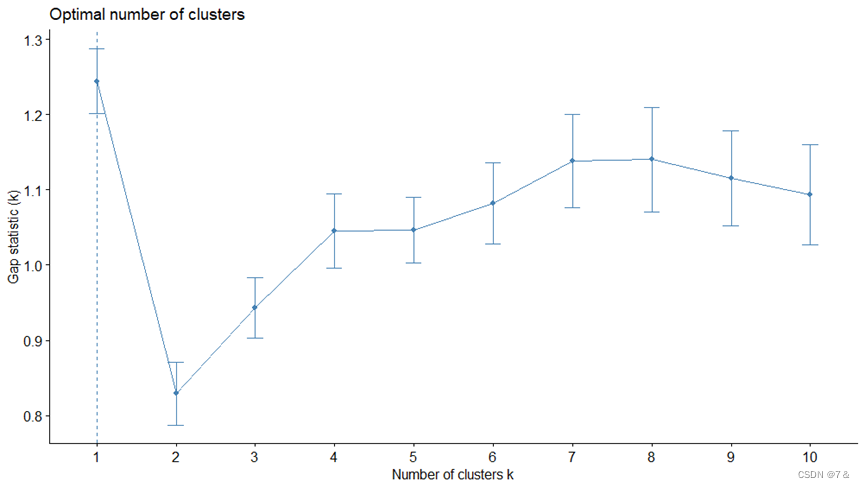
- 根据上图可知,针对数据集1,一共需要聚8类
代码如下
km=kmeans(data1[6:11], 8)
fviz_cluster(km,data1[6:11])
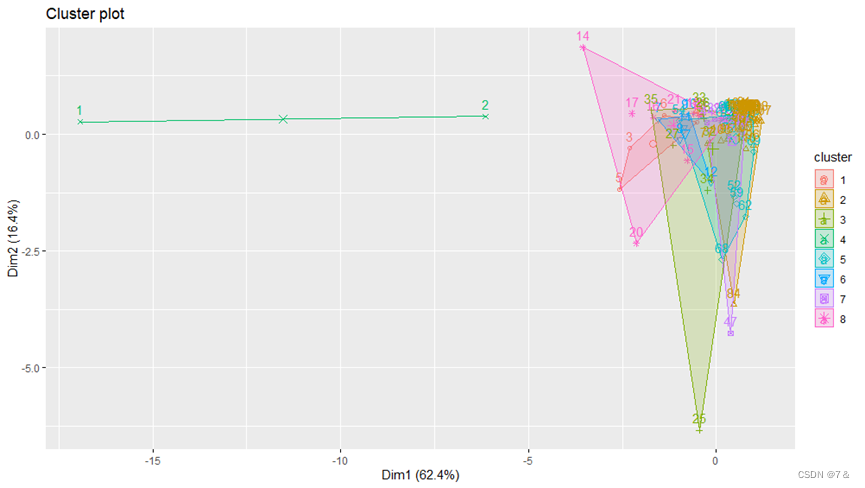
- 查看PCA负载(主成分载荷)
R语言的
corrplot包提供了一个在相关矩阵上的可视化探索工具,该工具支持自动变量重新排序,以帮助检测变量之间的隐藏模式。
corrplot 非常易于使用,并在可视化方法、图形布局、颜色、图例、文本标签等方面提供了丰富的绘图选项。它还提供 p 值和置信区间,以帮助用户确定相关性的统计显著性。
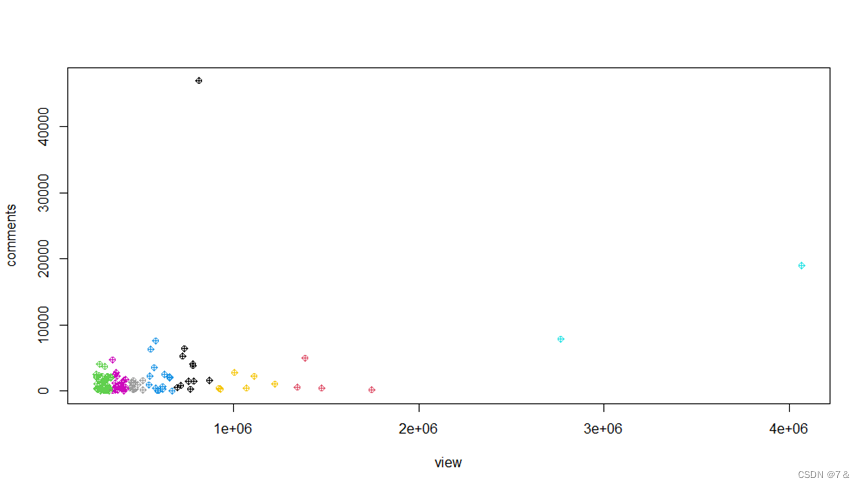
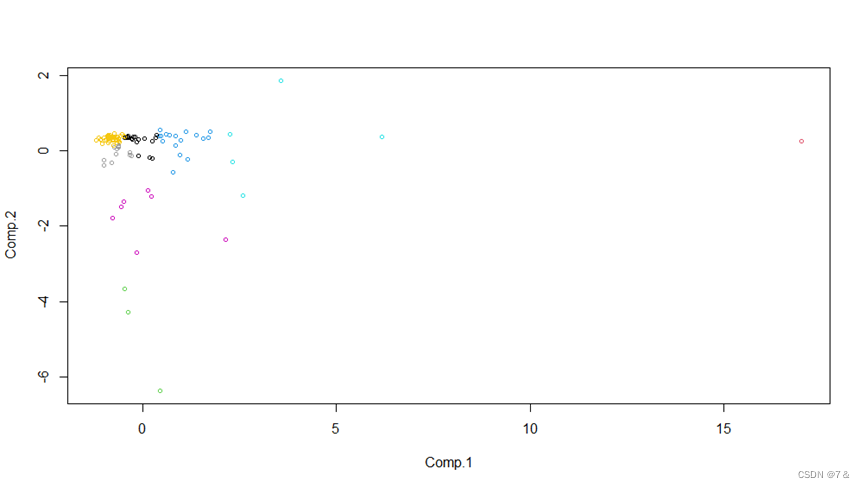
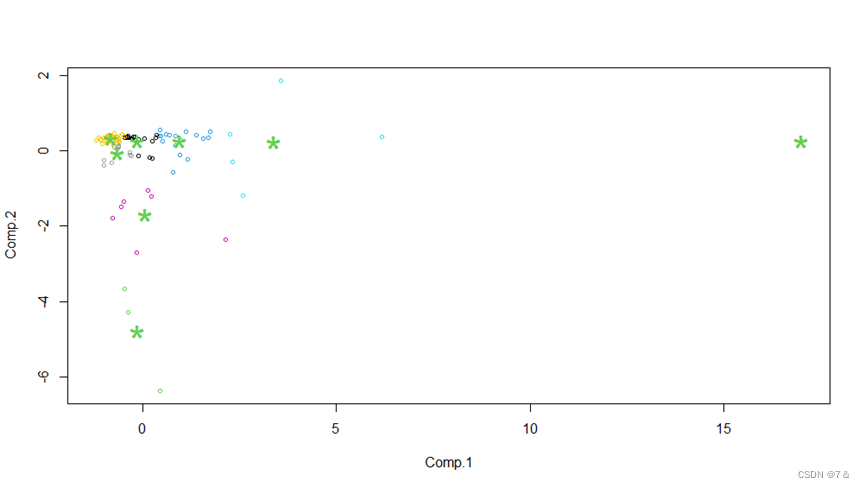
plot(as.matrix(data1[6:11]),col=km$cluster+1, pch=10)
points(km$centers,col=3,pch ="*",cex=3)
library(corrplot)
corpic=corrplot(PCA$loadings)
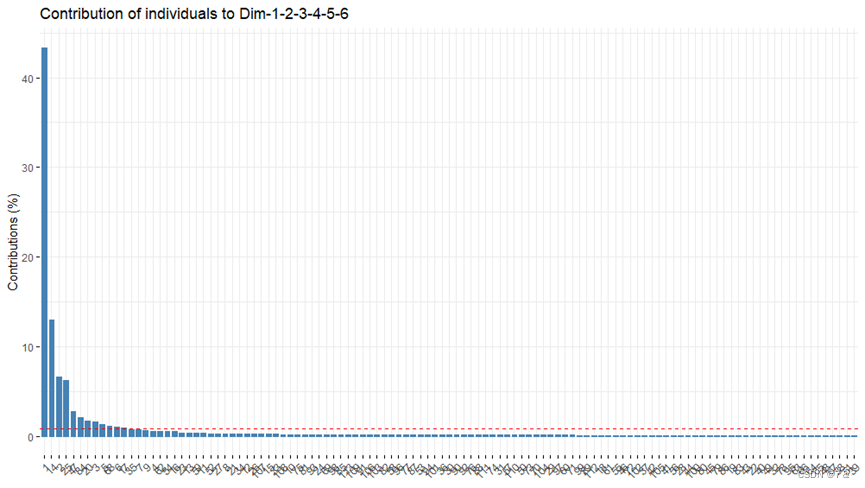
- 使用函数
fviz_contrib()[factoextra package] 用于绘制变量贡献的条形图
library(factoextra)
contri=fviz_contrib(PCA,choice = "ind",axes = 1:6)
contri
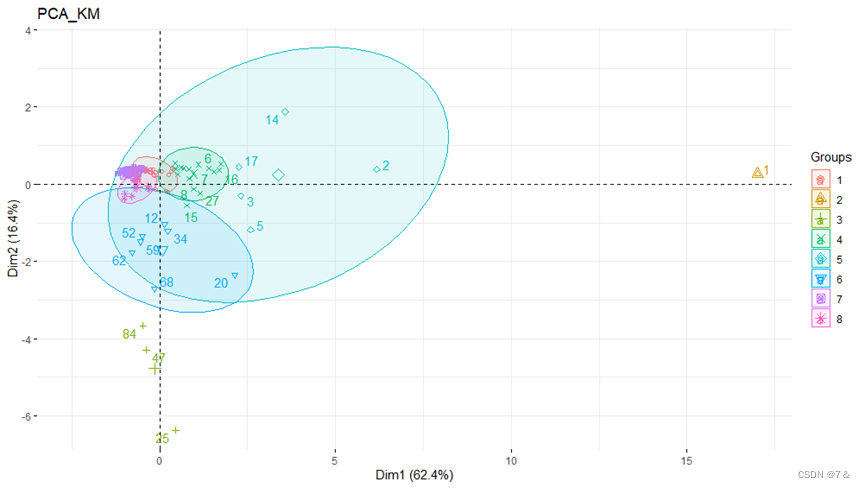
- Kmeans联合主成分分析进行聚类分析
fviz_pca_ind():是factoextra 包中的函数,能够以散点的形式展现数据分析结果。
fviz_pca_ind(PCA, col.ind = "cos2", gradient.cols=c("red","yellow","green"))
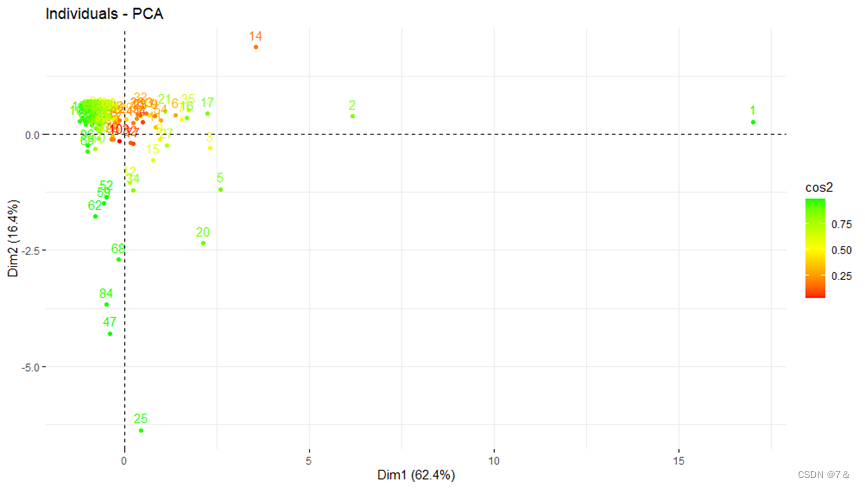
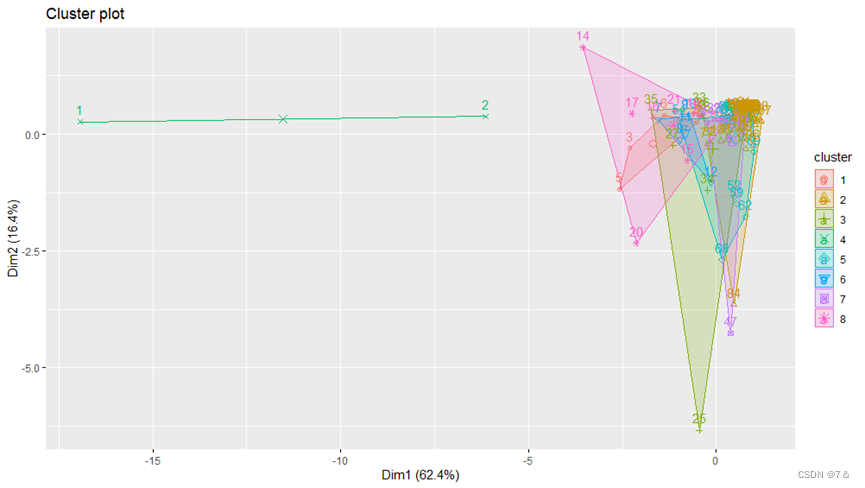
fviz_cluster提供基于ggplot2的分区方法的优雅可视化。如果ncol(data)>2,则用主成分在图中用点来表示观察结果。每个聚类周围画一个椭圆。
pca.km=kmeans(PCA$scores[,1:6],8)
fviz_cluster(km,data1[6:11])
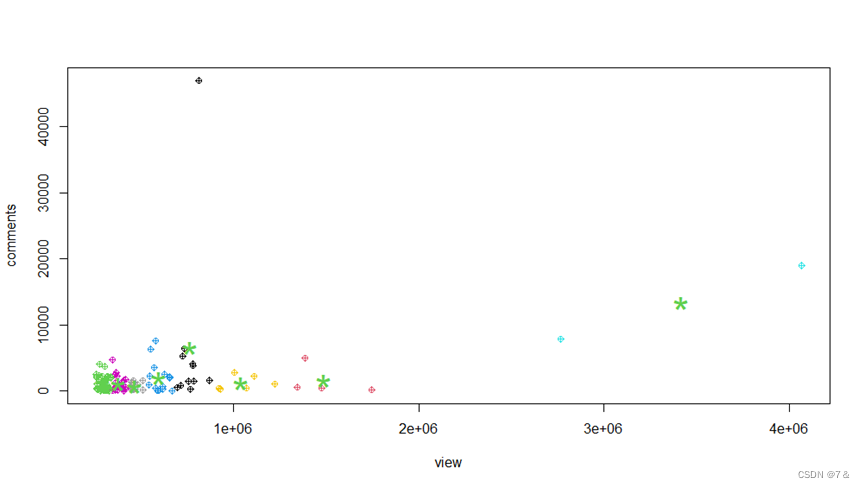
plot(as.matrix(PCA$scores[,1:6]),col=pca.km$cluster,cex=0.7)
points(pca.km$centers,col=3,pch ="*",cex=3)
fviz_pca_ind(PCA,habillage = pca.km$cluster,addEllipses = T,repel = T,ellipse.level=0.9)+ggtitle("PCA_KM")
绘制更美观的图
2、参考资料
- 多元统计分析及R使用(第五版)
结束!