其实学了几个小月,我们肯定知道,MLP有多deeper ,卷积层有多少层呀
抑或是Transformer架构,大量的参数,只能用huge 来描述,
可实际上我们的设备,有时候并没有服务器那么厉害,所以人们就想着
能不能在不改变model的精确度和效率,减少一下模型的规模
就是怎么样减少一下模型的复杂度或者参数量也好呀,在不失去优雅的情况下哈哈哈哈
这就是人类,贪婪的欲望推动着科技的进步哈哈哈哈
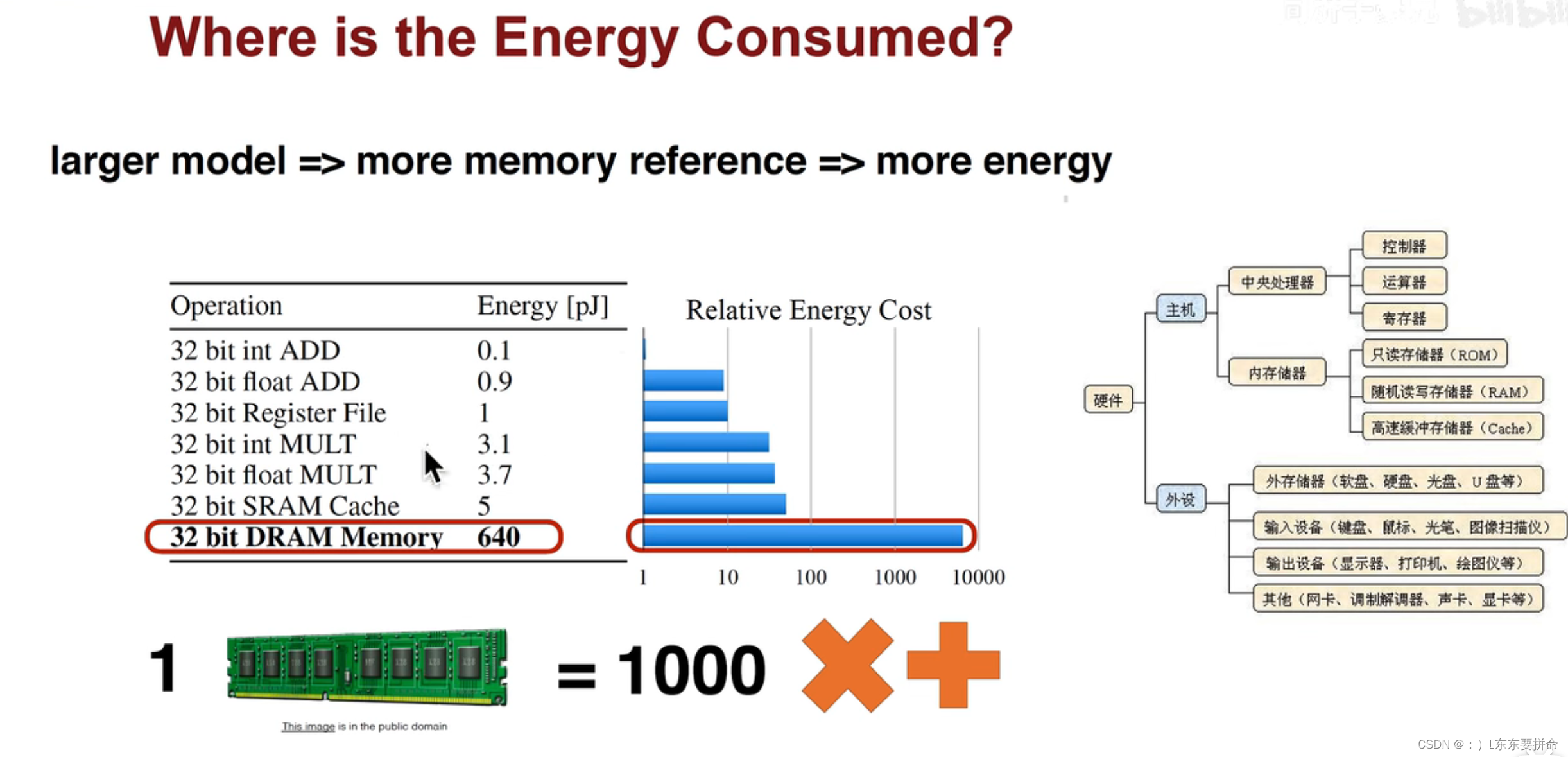
这个图是我偷的,斯坦福的,
没别的意思,就是想告诉大家,我们做DeepLearning 蛮耗能量的
杜绝挖矿!!!遵循人类可持续发展,我们是人类命运共同体啊啊啊
我们现在碳中和哦 小伙子们
面临的问题和挑战:当前基于深度卷积神经网络的目标检测算法计算资源需求太大和内存消耗严重使得成本较高
而轻量化网络因可以牺牲一小部分检测精度使检测速度获得较大的提升受到了广泛关注。轻量化网络的设计核心是在尽可能保证模型精度的前提下,降低模型的计算复杂度和空间复杂度,从而使得深度神经网络可以被部署在计算性能和存储空间有限的嵌入式边缘设备上,实现从学术界到工业界的跃迁
1.直接设计轻量化的深度网络模型
人工设计的轻量化神经网络 、基于神经网络架构搜索(Neural architecturesearch,NAS)的自动设计神经网络技术、卷积神经网络压缩和基于 AutoML的自动模型压缩。
2.模型的压缩
参数剪枝与量化(Parameter Pruning and Quantization),
低秩分解(Low-rank Factorization),
轻量化模块设计(Light-weight Module Design),
知识蒸馏(Knowledge Distillation)
method
目前常见的轻量化目标检测模型通常采用单阶段目标检测算法和高效的轻量级骨干网络,
将分类问题中的训练模型作为目标检测的预训练模型,
这可以为训练检测器提供更丰富的语义信息。
最经典的做法采用深度可分离卷积、分组卷积等轻量卷积方式,减少卷积过程的计算量。此外,利用全局池化来取代全连接层,利用1×1卷积实现特征的通道降维,也可以降低模型的计算量,
SqueezeNet (压缩再拓展) MobileNet(深度可分离卷积)ShuffleNet(通道混洗)
通过采用巧妙的融合策略与算法改进
轻量化 R-CNN 系列
自身体系结构的问题限制了检测速度。
轻量化 YOLO 系列
YOLO在轻型化目标检测尤其是在嵌入式平台下的重要地位
SSD平衡了YOLO和Faster RCNN的优缺点的模型,也常被用来与轻量级骨干网络进行结合达到高效率的目的。
最新的轻量化目标检测算法
1.NanoDet是一个 速度超快、(移动端 97fps)和轻量级(1.8MB)的移动端Ancho-free目标检测模型
2.谷歌MobileDets [19](arXiv2020 CVPR2021)
3.超越YOLOv4-Tiny!CSL-YOLO:移动端实时检测(2021)
4.Micro-YOLO(2021)保持检测性能的同时显着减少了参数数量和计算成本
YOLOv3-tiny网络中的卷积层替换为深度分布偏移卷积DSConv和移动反向瓶颈卷积 MBConv,并设计渐进式通道级剪枝算法以最小化数量参数并最大化检测性能。
5.苹果团队MobileViT:更小,更快,高精度的轻量级Transformer端侧网络架构
它是一个轻量级,通用的,低时延的端侧网络架构,将Transformer视为卷积,允许利用卷积和Transformer(例如,全局处理)的优点来构建轻量级和通用ViT模型。结合了CNN的归纳偏置优势和ViT的全局感受野能力,利用了CNN中的空间归纳偏置优势以及对数据增强技巧的低敏感性的特性,再结合了ViT中对输入特征图信息进行自适应加权和建立全局依赖关系等优点。
6.华为GhostNet
提出了一种新的Ghost模块,可以从廉价的操作中生成更多的特征图。基于一组内在特征映射,以低廉的成本应用一系列线性变换来生成许多能充分揭示内在特征信息的ghost feature maps。论文提出的Ghost模块可以作为一个即插即用的组件来升级现有的卷积神经网络。Ghost bottlenecks用来堆叠Ghost模块,从而可以方便地建立轻量级GhostNet。
7.百度开源 PP-PicoDet:轻量型实时目标检测模型
8.EdgeNeXt打混合拳:集CNN与Transformer于一体
整体架构采取标准的“四阶段”金字塔范式设计,其中包含卷积编码器与SDTA编码器两个重要的模块。在卷积编码器中,自适应核大小的设计被应用,这与SDTA中的多尺度感受野的思想相呼应。而在SDTA编码器中,特征编码部分使用固定的3×3卷积,但通过层次级联实现多尺度感受野的融合,而此处若使用不同尺寸的卷积核是否会带来更好的效果有待考证。在自注意计算部分,通过将点积运算应用于通道维度,得到了兼顾计算复杂度与全局注意力的输出,是支撑本文的一个核心点。
9.腾讯DisCo: 提升轻量化模型在自监督学习中的效果(ECCV2022)
Distilled Contrastive Learning (DisCo),一种简单有效的基于蒸馏的轻量化模型的自监督学习方法,该方法可以显著提升Student的效果并且部分轻量化模型可以非常接近Teacher的性能。
1)基于自监督的蒸馏学习;
(2)放弃共享队列,使整个框架不依赖于MoCo-V2,整个框架更加简洁。Teacher/Student 模型可以与其他比MoCo-V2更加有效的自监督/无监督表征学习方法结合,进一步提升轻量化模型蒸馏完的最终性能。
(3)目前的自监督方法中,MLP的隐藏层维度较低可能是蒸馏性能的瓶颈。在自监督学习与蒸馏阶段增加这个结构的隐藏层的维度可以进一步提升蒸馏之后最终轻量化模型的效果,而部署阶段不会有任何额外的开销。
10.阿里提出目标检测新范式GiraffeDet:轻骨干、重Neck
提出了首个轻骨干+灵活FPN组合的检测器,所提GiraffeDet包含一个轻量S2D-chain骨干与一个Generalized-FPN并取得了SOTA性能。
(1)不同常规骨干,本文设计了一种轻量型S2D-chain骨干,同时通过可控实验证实:相比常规骨干,FPN对于检测模型更为重要;
(2)提出GFPN(Generalized-FPN)以跨尺度连接方式对前一层与当前层的特征进行融合,跳层连接提供了更有效的信息传输,同时可以扩展为更深的网络;
在不同FLOPs-性能均衡下,所提GiraffeDet均取得了优异性能。当搭配多尺度测试时,GiraffeDet-D29在COCO数据集上取得了54.1%mAP指标,超越了其他SOTA方案。
11.ParC-Net超苹果
通过将vision transformers的优点融合到ConvNet 中。提出了位置感知循环卷积(ParC),这是一种轻量级的卷积运算,它拥有全局感受野,同时产生与局部卷积一样的位置敏感特征。将ParCs和squeeze-exictation ops结合起来形成一个类似于元模型的模型块,它还具有类似于transformers的注意力机制。上述块可以即插即用的方式使用,以替换ConvNets或transformers中的相关块
依赖于巧妙的轻量化特征提取网络设计,以及网络内部高效的信息提取与传递机制
笔记来源于看了几十篇轻量化目标检测论文扫盲做的摘抄笔记_Y蓝田大海的博客-CSDN博客_目标检测轻量化