为持续夯实MobTech袤博科技的数智技术创新能力和技术布道能力,本期极客星球邀请了企业服务研发部工程师梁立从 TCP 的粘包/半包、 Netty 处理粘包/半包及源码分析、 开源项目对 channelHandler最佳实践三方面对《netty 中channelHandler的原理与最佳实践》进行了全面的技术分享。
![]()
版本信息
![]()
本次分析版本基于netty 4.1.40.Final
![]()
TCP 的粘包/半包问题
![]()
在TCP/IP 协议传输网络数据包时,用户发送消息ABCD,服务端可能收到是ABCD. AB?CD?等。对于粘包问题,主要原因是发送方每次写入数据小于套接字缓冲区大小, 以及接受方读取消息不及时。对于半包问题, 主要原因是发送方每次写入数据大于套接字缓冲区大小,以及发送数据大于协议最大传输单位,底层需要拆包。那么针对此类问题,应当如何解决呢 ?常见的方式解码方式有三种:固定长度,使用固定分隔符来分割消息,以及固网长度字段存放内容长度信息。

![]()
解码实现思考
![]()
在分析之前,我们可以思考一下,如果是我们来实现上面三种编解码会如何实现 ?
我们可以整理如下需求:
1.我们需要存放我们解码好的消息;
2.我们需要提供一个解码方法来让不同子类实现, 例如固定长度,分隔符,以及固定长度字段解码的方式肯定有差别;
3.我们从套接字读取消息后就可以让我们解码器去处理了。
针对上述需求,我们还需要带着三个问题,查看源码看下是否和我们猜想的类似:
问题1:我们需要一个集合存放我们解码的消息;
问题2:我们需要不同子类对解码细节做不同实现,所以我们需要有一个父类;ByteToMessageDecoder, 可以在父类实现公共逻辑,提供给子类一个decode(List out,ByteBuf in); 方法;
问题3 :我们从套接字读取数据之后,发送一个读事件(fireChannelRead)让我们解码器去处理。
![]()
Netty 处理粘包/半包及源码分析
![]()
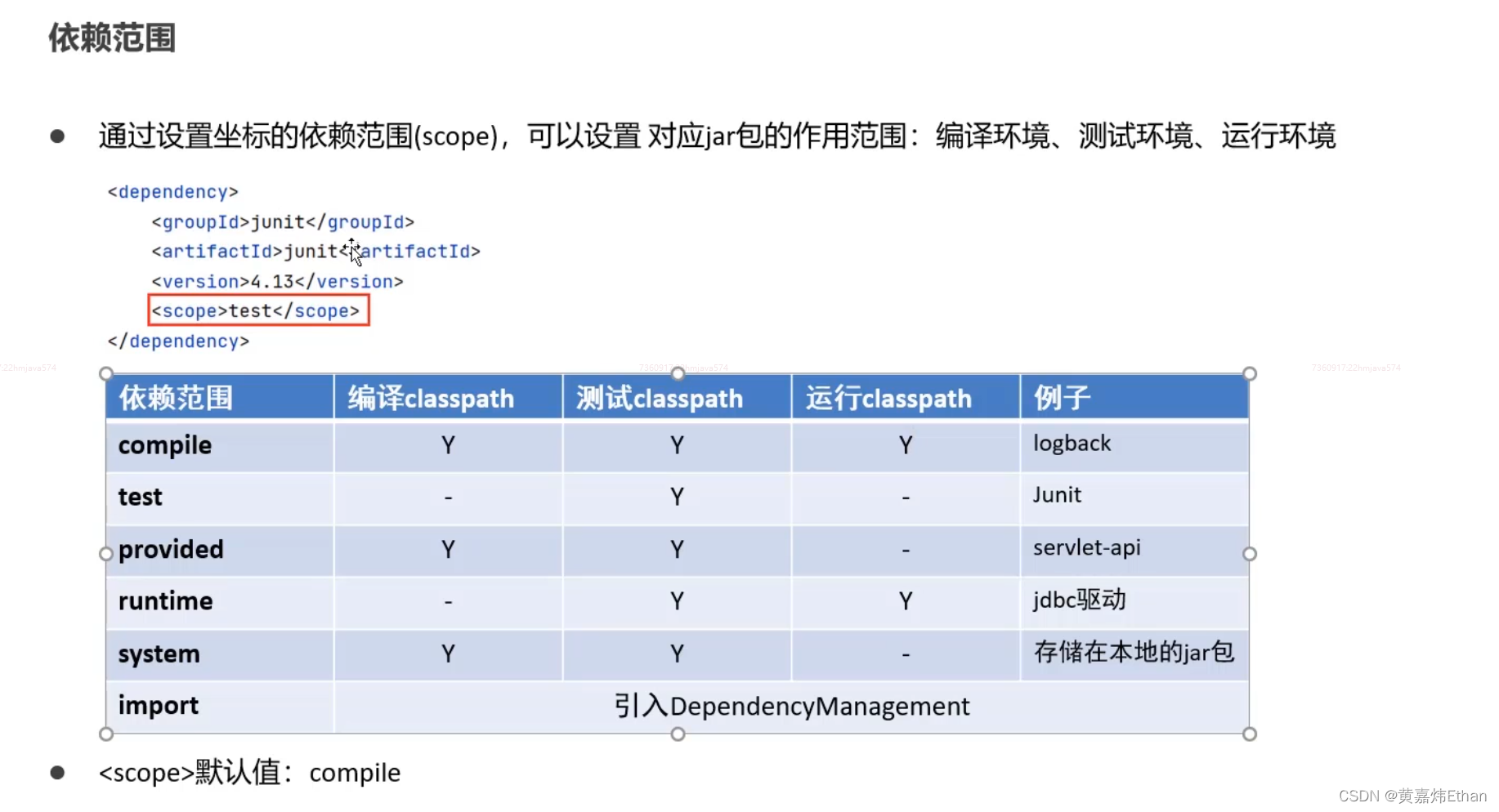
| 封帧方式 | 解码 |
| 固定长度 | FixedLengthFrameDecoder |
| 分隔符 | DelimiterBasedFrameDecoder |
| 固定长度字段存内容长度信息 | LengthFieldBasedFrameDecoder |
我们以固定长度解码器为例:
ServerBootstrap b = new ServerBootstrap();// ....b..childHandler(new ChannelInitializer<SocketChannel>() {@Overridepublic void initChannel(SocketChannel ch) throws Exception {ChannelPipeline p = ch.pipeline();p.addLast(new FixedLengthFrameDecoder(2));//.... 后续业务处理handler}});public class FixedLengthFrameDecoder extends ByteToMessageDecoder {//....}public class ByteToMessageDecoder {// ....protected abstract void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception;}
我们查看 FixedLengthFrameDecoder ,发现果然继承父类ByteToMessageDecoder,然后父类也有一个channelRead方法处理消息,并提供一个decode抽象方法让子类实现。
channelRead
假设我们发送端发送ABCD消息,从套节字读取之后,后续会调用channelRead 方法进行解码。
我们看到获取一个集合实例CodecOutputList, 该类实现List接口。如果是首次调用,会把当前ByteBuf 赋值给cumulation,并调用callDecode(ctx, cumulation, out)。
@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {if (msg instanceof ByteBuf) {CodecOutputList out = CodecOutputList.newInstance();try {ByteBuf data = (ByteBuf) msg;first = cumulation == null;if (first) {cumulation = data;} else {cumulation = cumulator.cumulate(ctx.alloc(), cumulation, data);}callDecode(ctx, cumulation, out);} catch (DecoderException e) {throw e;} catch (Exception e) {throw new DecoderException(e);} finally {//.....}} else {ctx.fireChannelRead(msg);}}
callDecode
通过字面意思就知道这个方法会做和解码相关操作。首先会判断in.isReadable() 是否可读,然后我们的outSize 目前是空, 进入到 decodeRemovalReentryProtection , 该方法会调用子类FixedLengthFrameDecoder的decode方法进行具体解码,该decode 方法比较简单就是当从ByteBuf 读取到指定长度就添加到out 中。我们读取完成后, outSize == out.size() 和 oldInputLength == in.readableBytes()都不满足,进入下一次循环, 我们outSize 大于0, 发送fireChannelRead。到此消息就被解码,并发送给我们业务channelHandler 。
protected void callDecode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) {try {while (in.isReadable()) {int outSize = out.size();if (outSize > 0) {fireChannelRead(ctx, out, outSize);out.clear();// Check if this handler was removed before continuing with decoding.// If it was removed, it is not safe to continue to operate on the buffer.//// See:// - https://github.com/netty/netty/issues/4635if (ctx.isRemoved()) {break;}outSize = 0;}int oldInputLength = in.readableBytes();//decode中时,不能执行完handler remove清理操作。//那decode完之后需要清理数据。decodeRemovalReentryProtection(ctx, in, out);// Check if this handler was removed before continuing the loop.// If it was removed, it is not safe to continue to operate on the buffer.//// See https://github.com/netty/netty/issues/1664if (ctx.isRemoved()) {break;}if (outSize == out.size()) {if (oldInputLength == in.readableBytes()) {break;} else {continue;}}if (oldInputLength == in.readableBytes()) {throw new DecoderException(StringUtil.simpleClassName(getClass()) +".decode() did not read anything but decoded a message.");}if (isSingleDecode()) {break;}}} catch (DecoderException e) {throw e;} catch (Exception cause) {throw new DecoderException(cause);}}final void decodeRemovalReentryProtection(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)throws Exception {decodeState = STATE_CALLING_CHILD_DECODE;try {decode(ctx, in, out);} finally {boolean removePending = decodeState == STATE_HANDLER_REMOVED_PENDING;decodeState = STATE_INIT;if (removePending) {handlerRemoved(ctx);}}}public class FixedLengthFrameDecoder extends ByteToMessageDecoder {@Overrideprotected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {Object decoded = decode(ctx, in);if (decoded != null) {out.add(decoded);}}protected Object decode(@SuppressWarnings("UnusedParameters") ChannelHandlerContext ctx, ByteBuf in) throws Exception {if (in.readableBytes() < frameLength) {return null;} else {return in.readRetainedSlice(frameLength);}}}
![]()
channelHandler 的最佳实践
![]()
了解Netty 的小伙伴都知道channelHandler 分为ChannelInboundHandler 和 ChannelOutboundHandler, 分别用来处理inbound 和 outbound。
channelHandler 的最佳实践本质就是inbound 和outbound 的最佳实践。
下面列举了三种具有代表性的场景
• 按照职责划分channelHandler,例如有处理编解码,有处理心跳的,有专门处理业务的;
• 因为channel和eventLoop 线程绑定,然后一个evnetLoop 可能服务多个channel,所以我们不要在channelHandler 做耗时操作;
• outbound 我们可以优化写,减少系统调用。
按照职责划分channelHandler
rocketMq
我们可以查看rocketMq 是如何划分channelHandler , 比如具有专门处理编/解码的NettyEncoder/NettyDecoder,通过IdleStatHandler 发现不活跃连接,管理连接handlerNettyConnectManageHandler 进行处理,
业务处理 NettyServerHandler 。
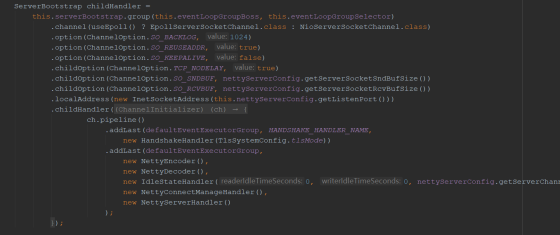
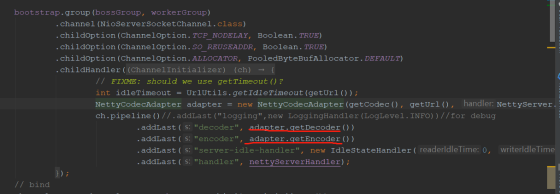
dubbo
处理编解码,检查不活跃channel,以及业务处理handler。
不在channelHandler 做耗时操作
之前介绍过一个eventLoop 线程服务多个channel,假设某个channelHandler处理耗时的任务,会影响其他channel,所以我们不要在channelHandler 执行耗时操作。
如果确实需要执行耗时操作,我们可以给channelHandler 添加一个线程池处理
final DefaultEventLoopGroup defaultEventLoopGroup = new DefaultEventLoopGroup();// 为我们的serverHandler 添加单独的线程池处理事件。pipeline.addLast(defaultEventLoopGroup,serverHandler);
outbound 优化写
writeAndFlush存在的问题
我们来看一下下面代码有什么问题?
public class EchoServerHandlerextends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) {ctx.writeAndFlush(msg);}}
代码的问题在于ctx.writeAndFlush 每次调用都会触发一次系统调用。然后channelRead 在一次业务处理中可能被调用多次,问题就变为一次业务请求,执行多次系统调用。
优化writeAndFlush
怎么优化?
我们可以重写channelRead 和 channelReadComplete,在channelRead 中调用write 方法,
在channelReadComplete中调用flush 方法 。
public class EchoServerHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) {ctx.write(msg);}@Overridepublic void channelReadComplete(ChannelHandlerContext ctx) {ctx.flush();}}
上面的实现方式确实减少系统调用,但是在netty 内部当有数据可读,会默认会连续16次,最后在调用channelReadComplete() 方法。
默认的行为存在两个问题:
1.写出数据到对端的时间被延迟了;
2.默认16 次这个数据不一定适合所有业务场景(不够灵活)。
我们需要结合业务的特性,例如业务如果关注吞吐量,可以适当把读取几次后刷新设置的大一些。如果业务关注及时性,读取几次后刷新就适当设置小一点。基于上述需求,FlushConsolidationHandler 就诞生了, 可以指定读取几次后刷新一次。
FlushConsolidationHandler 优化写
使用在pipeline中添加FlushConsolidationHandler,读取几次刷新一次可以根据业务设置,例如这里设置5次,我们是优化 EchoServerHandler的写,就放在它的前面。
// 每5次就触发一次flush// ....p.addLast(new FlushConsolidationHandler(5));p.addLast(new EchoServerHandler());// ....public class EchoServerHandler extends ChannelInboundHandlerAdapter {@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) {ctx.writeAndFlush(msg);}}
原理分析:
首先FlushConsolidationHandler 继承 ChannelDuplexHandler,能同时处理入站和出站消息,
入站我们查看 channelRead 和 channelReadComplete 实现,出站我们查看 flush 方法 (没有对write方法进行重写)。
channelRead
• 设置readInProgress 就把事件向下传递
• 我们的EchoServerHandler 会channelRead 会被调用,我们在channelRead 中调用ctx.writeAndFlush。
• 触发write 和 flush 的出站消息, FlushConsolidationHandler的flush进行处理
• 先判断readInProgress, ++flushPendingCount == explicitFlushAfterFlushes 判断是否达到期望刷新次数,我们设置为5 ,不执行刷新。
• 接着channelReadComplete 被调用,会重置准备刷新次数,并执行刷新。
关键就在channelRead 和 channelReadComplete
假设我们channelRead 读取了多次, 当读取次数大于等于5次就会刷新,小于5次时由channelReadComplete 刷新。
这样就达到了减少系统调用并且每读取几次在刷新也可以配置
public class FlushConsolidationHandler extends ChannelDuplexHandler {// explicitFlushAfterFlushes 表示几次flush后,才真正调用flush 方法// consolidateWhenNoReadInProgress 支持异步的情况,当readInProgress不为true 也可以支持flushpublic FlushConsolidationHandler(int explicitFlushAfterFlushes, boolean consolidateWhenNoReadInProgress){//....}@Overridepublic void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {readInProgress = true;ctx.fireChannelRead(msg);}@Overridepublic void channelReadComplete(ChannelHandlerContext ctx) throws Exception {// This may be the last event in the read loop, so flush now!// 内部就是将 readInProgress = false; 当flushPendingCount 就调用flushresetReadAndFlushIfNeeded(ctx);ctx.fireChannelReadComplete();}@Overridepublic void flush(ChannelHandlerContext ctx) throws Exception {//根据业务线程是否复用IO线程两种情况来考虑://复用情况if (readInProgress) { //正在读的时候// If there is still a read in progress we are sure we will see a channelReadComplete(...) call. Thus// we only need to flush if we reach the explicitFlushAfterFlushes limit.//每explicitFlushAfterFlushes个“批量”写(flush)一次//不足怎么办?channelReadComplete会flush掉后面的if (++flushPendingCount == explicitFlushAfterFlushes) {flushNow(ctx);}//以下是非复用情况:异步情况} else if (consolidateWhenNoReadInProgress) {//(业务异步化情况下)开启consolidateWhenNoReadInProgress时,优化flush//(比如没有读请求了,但是内部还是忙的团团转,没有消化的时候,所以还是会写响应)// Flush immediately if we reach the threshold, otherwise scheduleif (++flushPendingCount == explicitFlushAfterFlushes) {flushNow(ctx);} else {scheduleFlush(ctx);}} else {//(业务异步化情况下)没有开启consolidateWhenNoReadInProgress时,直接flush// Always flush directlyflushNow(ctx);}}}

附录
默认读取16次设置入口源码分析
默认创建DefaultChannelConfig ,会接着调用重载的构造函数。
在setRecvByteBufAllocator可以看到获取metadata.defaultMaxMessagesPerRead()。
而ChannelMetadata 默认构造为 16次 new ChannelMetadata(false, 16)。
public abstract class AbstractNioByteChannel extends AbstractNioChannel {private static final ChannelMetadata METADATA = new ChannelMetadata(false, 16);//.....}// 默认选择自适应接受缓存分配器,然后在调用setRecvByteBufAllocator。// setRecvByteBufAllocator就是指定最大读取多少次的入口 ,默认为16次public class DefaultChannelConfig implements ChannelConfig {public DefaultChannelConfig(Channel channel) {//除UDP外都默认选择自适应接受缓存分配器this(channel, new AdaptiveRecvByteBufAllocator());}protected DefaultChannelConfig(Channel channel, RecvByteBufAllocator allocator) {//UDP的使用固定SIZE的接受缓存分配器:FixedRecvByteBufAllocatorsetRecvByteBufAllocator(allocator, channel.metadata());this.channel = channel;}}private void setRecvByteBufAllocator(RecvByteBufAllocator allocator, ChannelMetadata metadata) {if (allocator instanceof MaxMessagesRecvByteBufAllocator) {((MaxMessagesRecvByteBufAllocator) allocator).maxMessagesPerRead(metadata.defaultMaxMessagesPerRead());} else if (allocator == null) {throw new NullPointerException("allocator");}setRecvByteBufAllocator(allocator);}public final class ChannelMetadata {private final boolean hasDisconnect;private final int defaultMaxMessagesPerRead;// ....}