paper题目:Street Tree Extraction and Segmentation from Mobile LiDAR Point Clouds Based on Spatial Geometric Features of Object Primitives
Abstract
从移动光探测与测距(LiDAR)点云中提取行道树仍然面临挑战,如在复杂的城市环境中提取精度低、鲁棒性差,以及重叠树木分割困难。针对这些问题,提出了一种基于对象图元空间几何特征的行道树提取和分割方法。本文首先基于所提出的图分割方法将移动激光雷达点云分割成目标基元,有效地减轻了计算负担。根据分割对象图元的空间几何特征,提取主干点。这样做,可以提高茎检测的鲁棒性和准确性。此外,体素连接性分析和个体树优化相结合。这样,相邻的树可以被成功地分开。在中国河南理工大学的四个数据集上验证了该方法的性能。四个移动激光雷达点云分别包含106、45、76和46棵树。实验结果表明,该方法能够实现4个试验地块的单株木分离。与其他三种方法相比,该方法能够很好地平衡误报和漏报,并获得最高的F1平均分数。
Keywords: 移动激光雷达;对象原语;特殊几何特征;行道树
1. Introduction
构建高精度的树木模型对于改善环境质量和城市居民服务具有重要意义[1–3]。获取行道树信息的传统方法主要包括人工测量、实时动态测量和全站仪测量。这些方法需要大量的人力和物力。此外,这些测量方法的低信息收集效率不能满足快速提取行道树信息的需要[4]。
激光雷达技术是一种快速发展的主动遥感技术,可以快速获得物体表面精确的三维(3D)点云[5]。虽然商业摄影测量软件可以以更便宜的方式从图像中生成数百万个点,但这种技术无法提供额外的信息,如强度、反射回波等。,这对于后期应用也很有用。因此,激光雷达技术已广泛应用于道路检测、电力线提取、森林参数估计、三维模型重建等领域[6,7]。
根据平台的不同,激光雷达系统可以分为机载激光雷达、地面激光雷达和移动激光雷达[8]。机载激光雷达具有测量范围广、效率高的优点[9]。因此,机载激光扫描(ALS)数据已被广泛用于各种树木提取[10–13]。Yao等人[14]联合分析了机载激光雷达数据和图像的光谱、几何和空间背景属性。实验结果表明,该方法能够很好地提取和分割居民区和街道区域的树木。张等[15]提出了一种结合高光谱图像和机载激光雷达数据的城市植被提取和分割方法。由于树冠重叠,个别树木往往分割不足或过度。为了解决确定分割停止标准的困难,Amiri等人[16]提出了一种基于树木视觉外观的自适应停止标准。虽然机载激光雷达可以在大范围内提取三维城市信息,但它是一种自上而下的扫描系统,其信号容易被树冠遮挡,难以获得完整的树干信息[17]。
与机载激光雷达相比,地面激光雷达一般可以获得更密集的点云,精度更高,尤其是在局部地区。因此,地面激光雷达是森林调查的重要手段之一,可用于单棵树的测量和重建[18–20]。Kiraly和Brolly [21]提出了一种基于统计聚类的单棵树检测方法。Lindberg等人[22]采用霍夫变换来识别和检测陆地激光扫描(TLS)数据中的树干。Pueschel等人[23]首先根据高程值对数据进行分层,然后使用相邻点之间的距离差作为树干检测的条件,确定树干位置,提取完整的树。钟等[24]提出了一种基于八叉树结构的树检测和分割方法。实验结果表明,基于八叉树节点直方图的树干检测方法能够将树干与灯杆、行人等其他杆状地物区分开来。虽然TLS可以获得密集的点云,但其较差的移动性和较低的效率限制了TLS在较大城市环境中的应用[25,26]。
与机载激光雷达和地面激光雷达相比,移动激光雷达可以更高效地获取城市道路和周围物体的三维信息[27,28]。移动激光扫描(MLS)不仅可以获得比ALS更完整的树干点,而且可以在短时间内实现比TLS更大的测量范围。虽然TLS具有与MLS相似的单个树检测工作流,但是TLS获得的点云必须被注册以获得完整的点云。显然,注册过程容易出错。更重要的是,在城市环境下,TLS的数据采集效率远低于MLS。因此,基于MLS数据的行道树提取和分割方法仍然是主流[29]。林等[30]采用三层框架策略和RD-schematic算法,利用树冠表面模型的形态特征检测行道树。Zhong等人[31]结合RGB信息进行树分离。吴等[32]提出了一种新的基于体素的标记邻域搜索方法。实验结果表明,该方法对行道树检测的完整率和正确率均在98%以上。Guan等人[33]使用欧几里德距离聚类和基于体素的归一化切割分割来提取单个树木。黄等[34]根据特征值和水平信息提取了完整的行道树。侯赛因等人[35]提出了一个层次分析法来分类树对象。Yadav等人[36]根据线性和数据分布同质性,采用自下而上的策略检测茎。实验结果表明,该方法能有效地从道路场景的MLS数据中识别出树木。李等人[37]提出了一个单独的树提取方法,工作在点的指导,并采用监督学习算法。李等人[38]提出了一种分枝-主干约束的层次聚类方法来从MLS数据中提取街道树。
尽管MLS数据可用于有效提取城市地区的行道树信息,但基于MLS的行道树提取和分割仍面临以下挑战:
i. 行道树提取方法的鲁棒性差;当遇到复杂的城市环境提取时,准确率会较低。
ii. 线状特征的对象容易被误认为是树干,降低行道树提取的准确性。
iii. 相邻的簇状树很难分离,这会导致较大的个体树提取误差。
针对上述问题,该文提出了一种基于对象图元空间几何特征的行道树提取与分割方法。在本文中,首先设置约束条件以构建图结构以从MLS数据中获取对象基元。然后,根据分割后的对象基元的空间几何特征检测干点。之后,通过对点云进行体素化和体素成分分析来提取行道树点。最后,通过比较每个点到根点的最短路径,分离出个体树。
本文的其余部分安排如下。第 2 节描述了所提出方法的原理。在第 3 节中,描述了实验。第 4 节讨论和分析实验结果。第 5 节总结了本文。
2. Methodology
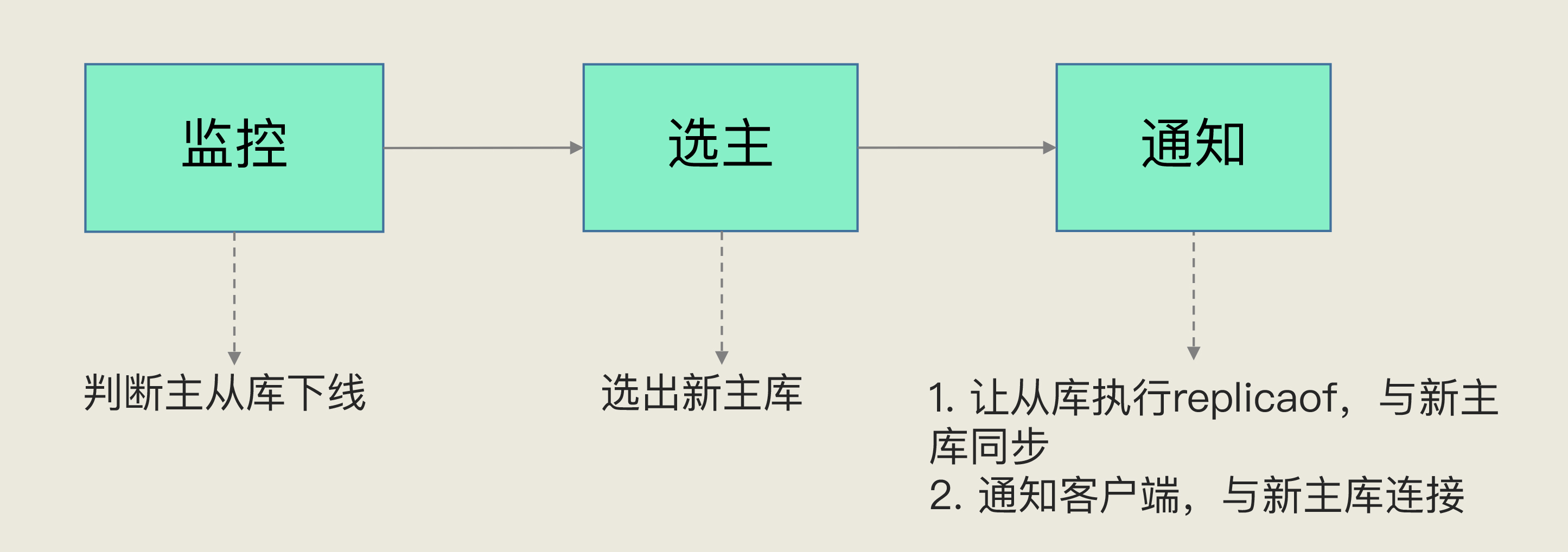
所提方法的流程图如图 1 所示。首先,采用 Hui 等人[39]提出的一种改进的形态学滤波方法来分离地面点和非地面点。然后,移除具有较高海拔的非地面点。在本文中,高程阈值设置为 2 m。这样一来,几乎所有的树干都可以保留下来,而树冠点或高楼点则可以去掉。随后,构建了图结构,并在本文提出的约束下通过图分割获得了对象图元。之后,计算对象基元的空间特征以提取树干点。然后,将非地面点进行体素化,通过分析相邻体素的连通性提取初始树点。为成功分离相邻的丛生树,本文通过最短路径分析对初始树点进行分割,得到个体树。本文包括四个主要步骤:(i)基于图分割的对象基元获取,(ii)使用对象基元特征的茎检测,(iii)基于连通性分析的初始树识别,以及(iv)基于个体树优化关于体素最短路径分析。
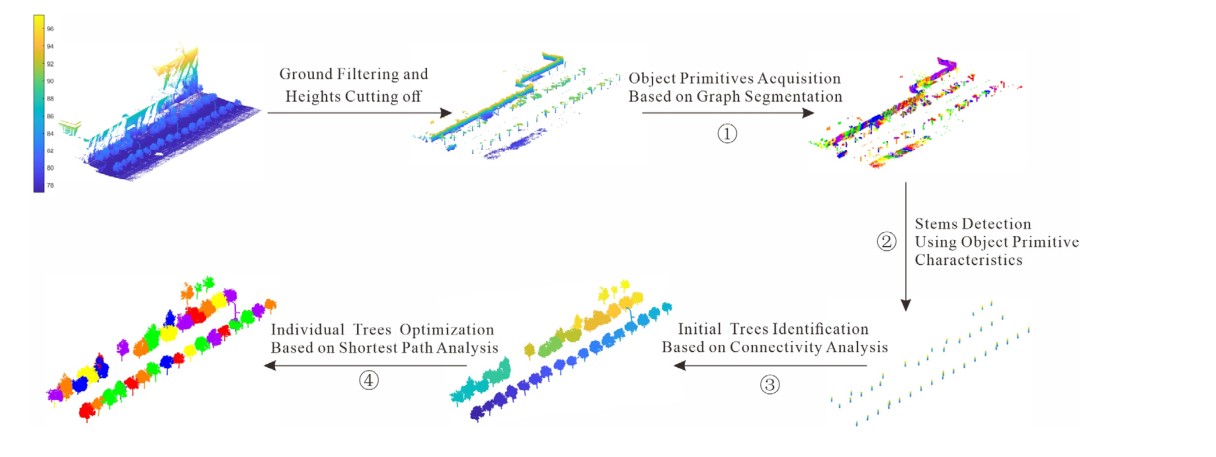
图 1. 所提出方法的流程图。
2.1. Object Primitives Acquisition Based on Graph Segmentation
为了有效地提取树干,本文首先通过构建点的图结构来获取初始对象基元。该图定义为等式(1)[40]:
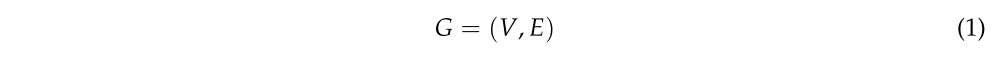
其中 V 代表节点 (vi),E 代表边 (ei,j)。 vi 由所有点 (pi,i = 1, 2, . . N) 组成,而 ei,j 连接成对的相邻点 (pi, pj)。一般来说,边的构造决定了图分割的结果。为了有效地提取树干目标,本文基于提出的三个约束构建了图,如图2所示。

图 2. 图分割。左图显示了根据分割前的高程着色的点。右图为分割结果;不同的对象基元具有不同的颜色。
2.1.1. The Constraint of Neighboring Radius
为了限制图的复杂性,应该约束图内的边。有效的方法是仅在相邻点内构造边。一般来说,有两种方法可以用来定义相邻点。一种是设置固定数量的相邻点。但是,MLS 数据的密度是多种多样的;如果选择了固定数量的相邻点,则图中将有更长的边。这是因为缺少距离约束。当点云稀疏或存在异常值时,图结构往往具有长边。定义相邻点的另一种方法是设置固定的相邻半径。然而,固定相邻半径的阈值很难确定。为了解决这个问题,本文将这两种相邻确定方法结合在一起。首先从树点中随机选取n个点,然后检测这n个点的k个最近邻点。对于每组k个最近邻,可以计算出k个点内的最长距离。固定的相邻半径被计算为这k个最长距离的平均值。如图3a所示,R为计算得到的固定邻域半径,可定义为式(2):
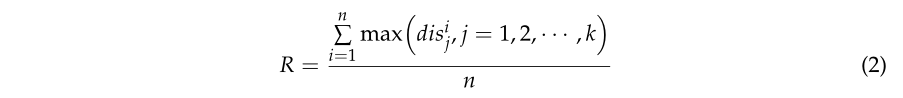
其中n是随机选择点的个数,disi j是第j个相邻点的距离,k是相邻点的个数。必须注意的是,k 影响图的复杂性和实现效率。考虑到它们之间的平衡,本文[41]中将k设置为10。根据式(2),可以根据不同数据的密度和空间分布自动确定邻域半径。
2.1.2. The Constraint of the Angle between Normal Vectors
一般来说,树干的对象基元具有法向量一致性。即,相邻点之间的法向量夹角较小。因此,该特征可用于将这些非地面对象分离成相同的对象基元。反之,树冠和低矮植被的点比较分散,不具备法向量的一致性。结果,这些对象将被分成小的、分散的对象基元。因此,为了正确提取树干,同一对象基元内的点应该具有相似的法向量。本文通过计算各点与其相邻点的法向量夹角(θ),得到具有相似空间特征的物体图元,如图3b所示。如果 θ 小于阈值,则保留两点之间的边缘。在本文中,通过反复试验将阈值设置为 30°。基于这个阈值,可以更好地提取词干点。 θ 定义为等式 (3)。
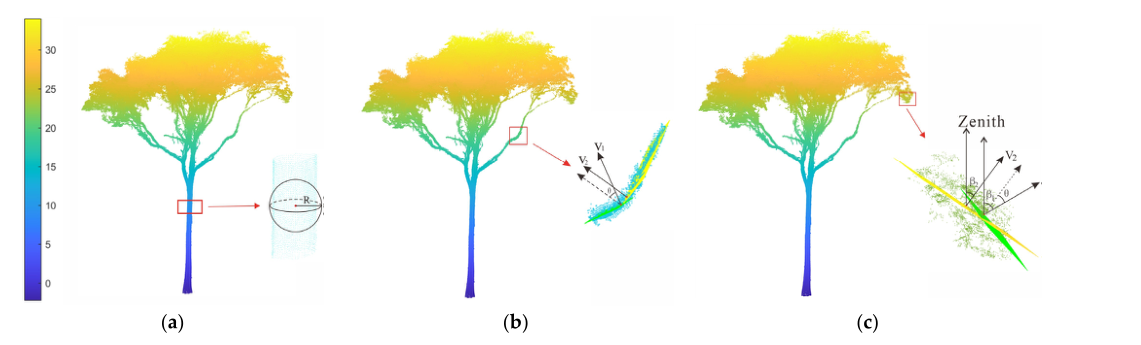
图 3. 图分割约束:(a) 邻域半径约束; (b) 法向量夹角的约束; © 垂直角梯度的约束。
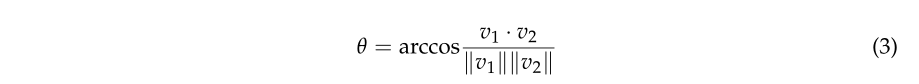
其中 v1 和 v2 是两个相邻节点的法向量。
2.1.3. The Constraint of the V ertical Angle Changing Rate
一般来说,茎点有规则的垂直分布,而其他点,如冠点,通常呈随机散布分布。换句话说,冠点的法向量与Z方向之间的角度通常比茎点的变化大。因此,本文将第三个约束设置为垂直角度变化率,定义为式(4):
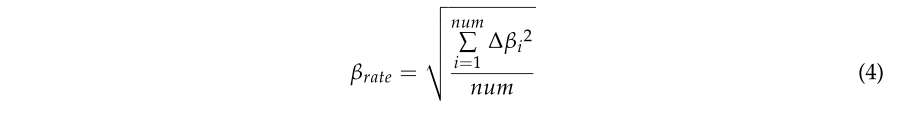
式中 4βi 为该点与其相邻点的垂直角差;如图3c所示,num是相邻点的个数。如图2所示,可以将垂直角度变化率相似的点划分为相同的物体基元,例如树干和建筑物。同时,垂直角度变化率较大的点,如树冠,被分成几个较小的对象基元。
2.2. Stems Detection Using Geometric Characteristics of Object Primitives
图分割后,点云将被分成多个对象基元。茎基元通常呈现独立的圆柱形。为了准确提取干点,本文计算了每个对象基元的几何特征,如图4a所示。图 4b 显示了线性度的计算。可以发现,大多数stem primitive都具有较大的线性度,如图4c所示的黄色点。对象基元的线性定义为等式(5):
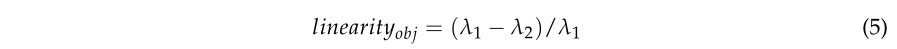
其中 λ 是原语协方差矩阵的特征值。这里,λ1 > λ2 > λ3 > 0。从图4b可以发现,与冠点相比,茎和枝的λ1明显大于λ2。因此,茎干点和分支点的线性度通常大于冠点的线性度。
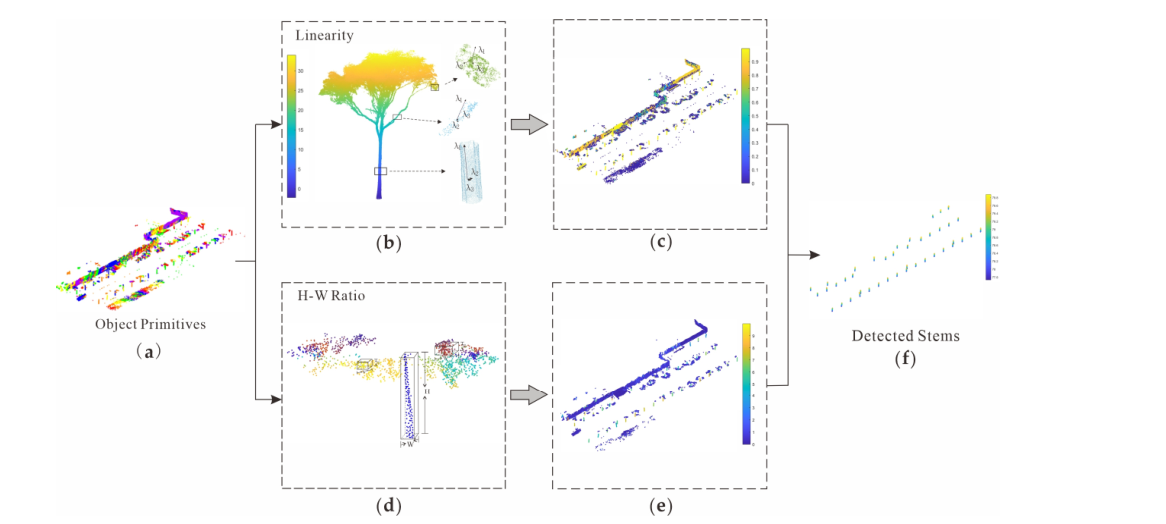
图 4. 使用对象基元的几何特征进行词干检测:(a) 是初始对象基元。每个对象基元的线性度和 H-W 比率分别计算并显示在 (b–e) 中。检测到的茎显示在(f)中。
由于建筑物和低矮植被等物体也可能具有较高的线性度,因此本文采用另一种空间特征来检测树干。本文将其定义为对象基元的高宽比(H-W)。在本文中,H-W ratio 是指每个对象的最小边界框的高度和宽度的比值,如图 4d 所示。由于茎为圆柱形,茎基元的 H-W 比大于其他基元的 H-W 比。因此,可以通过检测具有较大 H-W 比的图元来进一步优化茎点。 H-W 比定义为等式 (6):
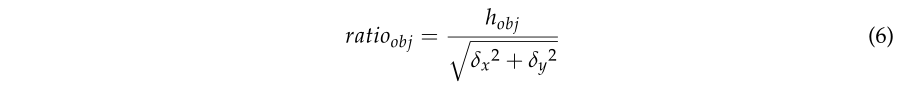
其中 hobj 计算为对象内最高点和最低点之间的高程差。 δx 和 δy 分别是 X 轴和 Y 轴上对象基元内的点的范围。基于线性度和 H-W 比,可以如图 4f 所示检测茎。
2.3. Initial Tree Points Identification Based on Voxel Connectivity Analysis
树干提取后,基于体素连通性分析获取初始树点。如图 5a 所示,通过第 2.2 节中描述的方法检测到茎(红点)。随后,所有点都被体素化为一系列体素。为了获得初始树点,将体素连通性分析应用于体素化结果。体素连通性分析的过程如图6所示[42]。图 6a 显示了分割前的体素。没有点的体素标记为0,而包含点的体素标记为1。图6b是本文使用的六连通模型。这意味着只有分布为六连通模型的体素才能被视为连通性。在体素连通性分析步骤中,选择茎的体素作为种子体素。然后,搜索相邻的体素,并判断与种子体素的连通性。如上所述,只有具有公共面的相邻体素才被视为具有连通性。随后,可以得到如图6c所示的连接结果。
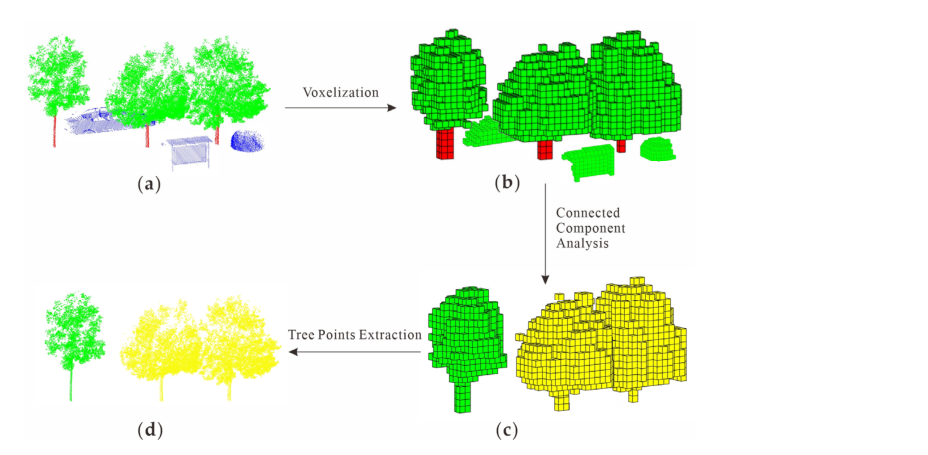
图 5. 基于体素连通性分析的树点提取:(a) MLS 获取的点云; (b) 体素化的结果; © 体素连通性分析的结果; (d) 提取的树点。
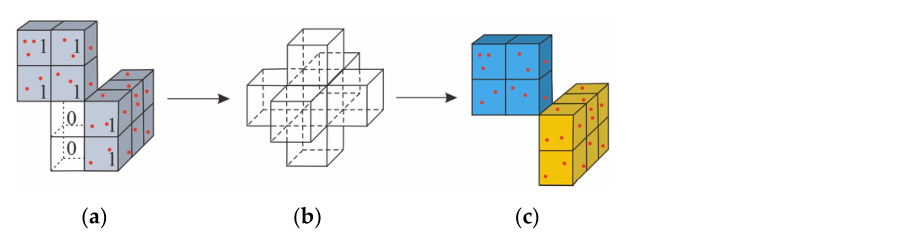
图 6. 体素连通性分析的过程。 (a) 分割前的体素。没有点的体素标记为 0,而包含点的体素标记为 1。 (b) 六连接模型; © 体素连通性分析后的结果。不同的对象图元用不同的颜色着色。
使用建议的体素连接分析,连接到茎的体素可以合并在一起,如图 5c 所示。根据连接结果,可以得到整树点如图5d所示。需要注意的是,在树干检测的步骤中,一些细长的物体,如灯柱、电线杆等,也会被误判为树干。这是因为这些对象基元还同时拥有更大的线性度和 H-W 比。为了避免这些错误检测的茎的影响,本文在体素连通性分析后去除了体素数量较少的对象。这是因为错误检测到的树木(例如灯柱)的尺寸通常较小。因此,通过限制每个对象的体素数量,可以删除错误检测的树木。
2.4. Individual Trees Optimization Based on Voxel Shortest Path Analysis
从图5可以看出,经过体素连通性分析后,可以根据检测到的树干将树点与其他点区分开来。但是,有一些相邻的簇状树连接成一棵树,如图 5d 所示。这是因为相邻的两棵树之间的距离很近;在进行体素连通性分析时,很容易将相邻的树木连接成一棵树。因此,应该进行进一步的优化以获得最佳的个体树分离结果。
个体树优化的流程图如图7所示。在该方法中,每个树基元被一一遍历。树图元是体素连通性分析后的树点提取结果。显然,每个树基元中都会包含一棵或多棵树。为了确定这一点,计算每个原始树中的茎。在遍历过程中,如果树内有不止一根树干,则树基元分割不足,需要进一步优化。在优化中,首先对欠分割的树图元进行体素化处理,然后以每个体素的中心构成构建图。这样做可以减轻计算负担,提高效率。由于欠分割的树基元包含多个树干,根据图 8 所示的 Dijkstra 算法,树基元中的每个点都将有一条到不同树干基部的最短路径 (SP)。显然,这些点应该属于到具有较短 SP 的茎。 Dijkstra算法是一种著名的SP计算方法[43]。在 Dijkstra 算法中,首先计算从源节点到末端节点的直接路径。然后,可以计算出其中的最短路径,用于调整其他路径。在调整后的路径中,可以找到最短的路径。迭代此过程,直到检测到从源节点到其他端节点的所有 SP。通过比较 SP,相邻的树可以作为单独的树进行优化。
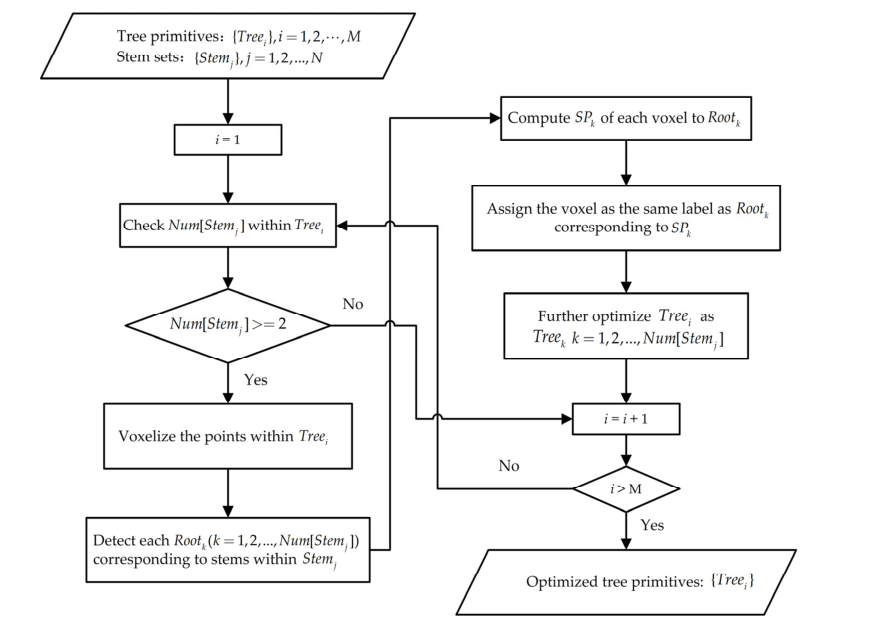
图 7. 基于最短路径分析的个体树优化流程图。
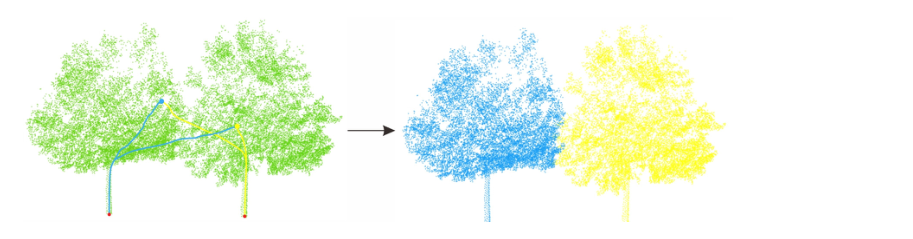
图 8. 个体树优化。左图显示了两棵优化前树冠重叠的树。蓝点到左树底部的最短路径长度明显小于到右树底部的最短路径长度,所以蓝点与左树底部归为同一类.右图是优化后的结果。
5. Conclusions
行道树提取是数字孪生城市建设的重要一步。在本文中,移动 LiDAR 点云首先基于所提出的在特定约束下的图分割被分割成对象基元。这样做可以减轻计算负担。为了提高茎检测的准确性和鲁棒性,结合了线性度和 H-W 比的几何特征。对于大多数传统的单树检测方法来说,分离相邻的树木仍然是一个挑战。在本文中,提出了体素最短路径分析以实现优化的个体树分离结果。使用四个数据集验证了所提出的方法。实验结果表明,所提方法在四个试验样地均能取得良好的行道树提取和分割性能。与其他三种方法相比,本文的树分割方法取得了最高的平均 F1 分数。这表明所提出的方法可以平衡佣金率和遗漏率,有效避免过度分割。然而,所提出方法的实现需要设置一些参数,例如对象基元的线性阈值和 H-W 比。如何提高方法的自动化程度,使参数根据每个点云的特殊性自动确定,将是我们进一步研究的重点。