本文着重在于讲解用 “堆实现优先级队列” 以及优先级队列的应用,在本文所举的例子中,可能使用优先级队列来解并不是最优解法,但是正如我所说的:本文着重在于讲解“堆实现优先级队列”
堆实现优先级队列
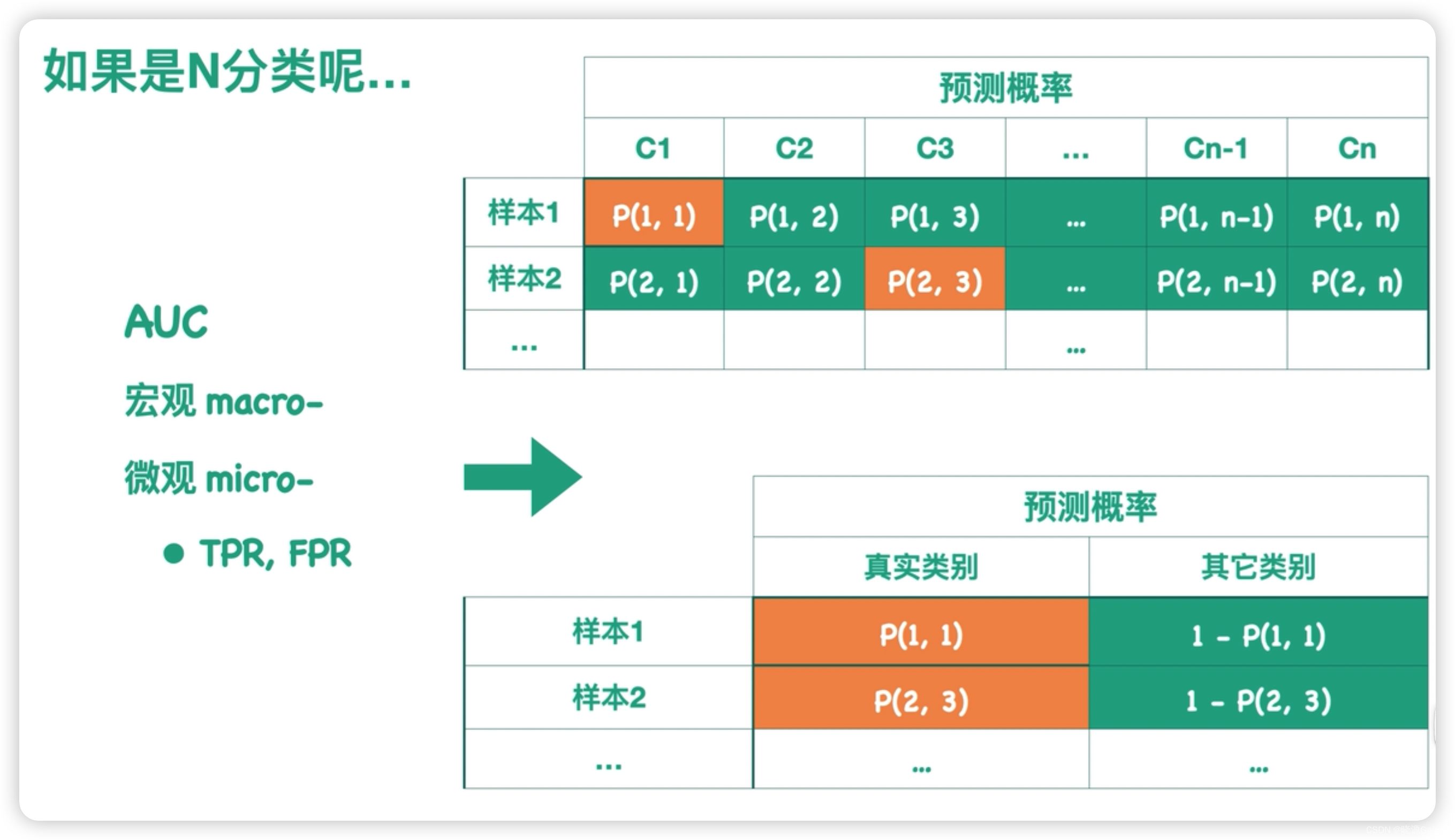
堆的主要应用有两个,一个是排序方法[堆排序],一个是数据结构 [优先级队列]。
我们会发现,人们总是把二叉堆画成一棵二叉树。其实二叉堆在逻辑上就是一种特殊的二叉树,只不过存储在数组里。
比如 arr 是一个字符数组,注意数组的第一个索引 0 空着不用:

为什么索引 0 空着不用?
为了方便计算父节点和子节点的索引,通常会将数组的第一个元素存储在索引1的位置上,而不是索引0。这样可以通过简单的数学计算得到父节点和子节点的索引,而无需进行额外的操作。
具体来说,在该代码中:
根据完全二叉树的性质,如果某个节点的索引为i,则其左子节点的索引为2i,右子节点的索引为2i + 1。
如果索引从1开始,则根节点的索引为1,其左子节点的索引为2,右子节点的索引为3。
如果索引从0开始,则根节点的索引为0,其左子节点的索引为1,右子节点的索引为2。
因此,为了避免对索引的调整和计算,通常会将数组的第一个元素放在索引1的位置上,并从索引1开始使用。这也是为什么在这段代码中索引0不被使用的原因。
请注意,这种索引方式只是约定俗成的一种做法,并非固定规定。在某些情况下,也可以使用索引从0开始的方式实现堆或优先队列。这取决于具体的实现和需求。
构建优先级队列
可以使用 最大堆/最小堆 来构建优先级队列,当插入或者删除元素的时候,元素会自动排序,这底层的原理就是二叉堆的操作。
当我们使用一个最大堆来实现一个优先级队列时,堆顶元素总是数组中的最大值。这背后就是由[上浮] 和 [下沉] 两个操作来维护堆结构的。
维护堆结构的操作——swim和sink
我们要讲的是最大堆,每个节点都比它的两个子节点大,但是在插入元素和删除元素时,难免破坏堆的性质,这就需要通过这两个操作来恢复堆的性质了。
对于最大堆,会破坏堆性质的有两种情况:
1、如果某个节点 A 比它的子节点(中的一个)小,那么 A 就不配做父节点,应该下去,下面那个更大的节点上来做父节点,这就是对 A 进行下沉。
2、如果某个节点 A 比它的父节点大,那么 A 不应该做子节点,应该把父节点换下来,自己去做父节点,这就是对 A 的上浮。
当然,错位的节点 A 可能要上浮(或下沉)很多次,才能到达正确的位置,恢复堆的性质。所以代码中肯定有一个 while 循环。
上浮操作的实现:
private void swim(int x) {
// 索引 1 是堆顶
//判断:x不是堆顶元素且x大于其父结点
while (x > 1 && less(parent(x), x)) {
// 交换x的父结点与x下标元素
swap(parent(x), x);
//将父节点的索引给x,指针指向x
x = parent(x);
}
}下沉操作的实现:
private void sink(int x) {
// size 是堆的最后一个索引
//判断:当x的左节点不是堆底元素时
while (left(x) <= size) {
// 先假设左边节点较大
int max = left(x);
// 如果右边节点存在,比一下大小
//判断:右节点不是堆底元素且右节点值大于max的值
if (right(x) <= size && less(max, right(x)))
max = right(x);
// 结点 x 比俩孩子都大,就不必下沉了
if (less(max, x)) break;
// 否则,不符合最大堆的结构,下沉 x 结点
swap(x, max);
x = max;
}
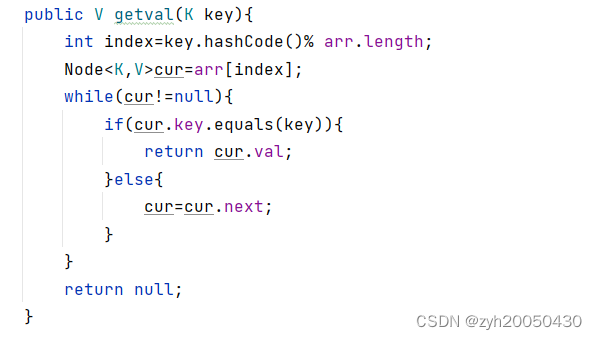
}数据结构的基本操作——增删查改
增加操作
将元素插到堆的底部,然后上浮到对应位置
public void insert(Key e) {
size++;
// 先把新元素加到最后
pq[size] = e;
// 然后让它上浮到正确的位置
swim(size);
}删除操作
将要删除的元素与堆底元素对调,然后删除堆底元素。最后维护堆结构
public Key delMax() {
// 最大堆的堆顶就是最大元素
Key max = pq[1];
// 把这个最大元素换到最后,删除之
swap(1, size);
pq[size] = null;
size--;
// 让 pq[1] 下沉到正确位置
sink(1);
return max;
}查看操作
查看最大值,直接返回堆顶元素即可
public Key max() {
return pq[1];
}整体代码
public class MaxPQ
<Key extends Comparable<Key>> {
/*完全二叉树中的索引下标是可以计算出来的*/
// 父节点的索引
int parent(int root) {
return root / 2;
}
// 左孩子的索引
int left(int root) {
return root * 2;
}
// 右孩子的索引
int right(int root) {
return root * 2 + 1;
}
// 存储元素的数组
private Key[] pq;
// 当前 Priority Queue 中的元素个数
private int size = 0;
public MaxPQ(int cap) {
// 索引 0 不用,所以多分配一个空间
pq = (Key[]) new Comparable[cap + 1];
}
/* 返回当前队列中最大元素 */
public Key max() {
return pq[1];
}
/* 插入元素 e */
public void insert(Key e) {
size++;
// 先把新元素加到最后
pq[size] = e;
// 然后让它上浮到正确的位置
swim(size);
}
/* 删除并返回当前队列中最大元素 */
public Key delMax() {
// 最大堆的堆顶就是最大元素
Key max = pq[1];
// 把这个最大元素换到最后,删除之
swap(1, size);
pq[size] = null;
size--;
// 让 pq[1] 下沉到正确位置
sink(1);
return max;
}
/* 上浮第 x 个元素,以维护最大堆性质 */
private void swim(int x) {
// 如果浮到堆顶,就不能再上浮了
//因为是从索引1开始的,所以索引1是堆顶
//判断:当x不是堆顶且x的父结点小于x时
while (x > 1 && less(parent(x), x)) {
// 如果第 x 个元素比上层大
// 交换数组下标元素
swap(parent(x), x);
x = parent(x);
}
}
/* 下沉第 x 个元素,以维护最大堆性质 */
private void sink(int x) {
// 如果沉到堆底,就沉不下去了
while (left(x) <= size) {
// 先假设左边节点较大
int max = left(x);
// 如果右边节点存在,比一下大小
if (right(x) <= size && less(max, right(x)))
max = right(x);
// 结点 x 比俩孩子都大,就不必下沉了
if (less(max, x)) break;
// 否则,不符合最大堆的结构,下沉 x 结点
swap(x, max);
x = max;
}
}
/* 交换数组的两个元素 */
private void swap(int i, int j) {
Key temp = pq[i];
pq[i] = pq[j];
pq[j] = temp;
}
/* pq[i] 是否比 pq[j] 小? */
private boolean less(int i, int j) {
return pq[i].compareTo(pq[j]) < 0;
}
}
附注1:对<Key extends Comparable<Key>>的解释
<Key extends Comparable<Key>>是Java的泛型语法。它指示了MaxPQ类使用一个类型参数Key,并且要求这个类型Key必须实现了Comparable<Key>接口。
Comparable<Key>接口是Java中定义的一个泛型接口,用于比较两个对象的顺序。它要求实现类具有比较自身与其他对象的能力,并返回一个整数值表示它们的相对顺序。
通过实现Comparable接口,我们可以在堆和优先级队列中比较元素的大小,以维护它们的排序规则。
在这段代码中,Key作为泛型参数限制了存储在pq数组中的元素类型必须实现Comparable接口,以便能够进行比较操作(例如使用compareTo方法)。这样做可以确保我们能够正确地进行插入、删除和获取最大元素等操作,使得堆和优先级队列能够按照特定的顺序进行排序和处理。
附注2:对“pq = (Key[]) new Comparable[cap + 1]”的解释
在这段代码中,pq = (Key[]) new Comparable[cap + 1];是用来创建一个泛型数组的操作。
首先,我们需要了解在Java中创建泛型数组的限制。由于Java的类型擦除机制,无法直接创建一个具体类型的泛型数组。
因此,我们只能通过创建一个非泛型数组,然后将其转换为泛型数组。
在这段代码中,new Comparable[cap + 1]创建了一个长度为cap + 1的非泛型数组,
并且元素的类型是Comparable接口。这个数组在内存中被分配了空间。
然后,(Key[])表示进行了一个类型转换。
因为我们知道该数组是要存储Key类型的元素,所以我们将其强制转换为泛型数组类型Key[]。
最后,将转换后的泛型数组赋值给变量pq,使得pq引用这个泛型数组。
需要注意的是,在进行强制类型转换时,存在一定的风险。
如果实际存储在数组中的元素类型不符合泛型参数Key的约束条件,可能会导致运行时错误。
因此,在使用该代码时,应确保泛型参数和实际存储的元素类型是匹配的。*/
优先级队列的应用
力扣215. 数组中的第K个最大元素
思路
使用数组构造一个最大堆,然后选出第k大的元素
构建最大堆
// 构建最大堆
public void buildMaxHeap(int[] a, int heapSize) {
for (int i = heapSize / 2; i >= 0; --i) {
maxHeapify(a, i, heapSize); // 对每个非叶子节点进行调整,使其满足最大堆的性质
}
}
// 调整以i为根节点的子树,使其满足最大堆的性质
public void maxHeapify(int[] a, int i, int heapSize) {
//计算左右节点的下标
int left = i * 2 + 1, right = i * 2 + 2, largest = i;
// 下沉操作:比较节点i与其左右子节点的值,找到最大值
// 先与左节点对比
if (left < heapSize && a[left] > a[largest]) {
largest = left;
}
// 再与右节点对比
if (right < heapSize && a[right] > a[largest]) {
largest = right;
}
if (largest != i) {
swap(a, i, largest); // 将节点i与最大值节点交换位置
maxHeapify(a, largest, heapSize); // 继续向下调整以保持最大堆的性质
}
}
// 交换数组中两个元素的位置
public void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}问题1: “for (int i = heapSize / 2; i >= 0; --i)”是什么意思?
在构建最大堆时,我们只需要对非叶子节点进行调整,而不需要对叶子节点进行调整。这是因为堆的性质决定了,一个完全二叉树的叶子节点已经满足最大堆的条件,即叶子节点的值不会比其父节点更大。
考虑到完全二叉树的特点,具有n/2个节点是非叶子节点,其中n是堆中元素的总数。比如下标为i的元素,其左节点为 2i,右节点为 2i+1,所以对n个节点来说,只能有n/2个节点是非叶子节点。
所以,我们可以从最后一个非叶子节点(索引为n/2 - 1)开始,向前逐个调用maxHeapify方法,将每个节点及其子树调整为最大堆。
由于最大堆的性质要求父节点的值大于或等于其子节点的值,通过逐层向上调整非叶子节点,我们能够确保整个堆都满足最大堆的要求。
因此,在buildMaxHeap方法中,我们只对非叶子节点进行调整,以节省时间
选出第k大的元素
选出第k大的元素的方法是取出堆顶的元素,将其与堆底元素交换,然后缩小堆,重新维护堆结构。就相当于把堆顶的最大元素删除了。
正数第k个元素就是倒数的第 length - k + 1个元素,所以我们将后面length - k + 1个元素与堆顶元素交换即可
public int findKthLargest(int[] nums, int k) {
int heapSize = nums.length;
buildMaxHeap(nums, heapSize); // 构建最大堆
for (int i = nums.length - 1; i >= nums.length - k + 1; --i) {
swap(nums, 0, i); // 将堆顶元素与当前未排序部分的最后一个元素交换
--heapSize; // 缩小堆的大小
maxHeapify(nums, 0, heapSize); // 调整堆使其继续满足最大堆的性质
}
return nums[0]; // 返回第k个最大元素(堆顶元素)
}整体代码
class Solution {
public int findKthLargest(int[] nums, int k) {
int heapSize = nums.length;
buildMaxHeap(nums, heapSize); // 构建最大堆
for (int i = nums.length - 1; i >= nums.length - k + 1; --i) {
swap(nums, 0, i); // 将堆顶元素与当前未排序部分的最后一个元素交换
--heapSize; // 缩小堆的大小
maxHeapify(nums, 0, heapSize); // 调整堆使其继续满足最大堆的性质
}
return nums[0]; // 返回第k个最大元素(堆顶元素)
}
// 构建最大堆
public void buildMaxHeap(int[] a, int heapSize) {
for (int i = heapSize / 2; i >= 0; --i) {
maxHeapify(a, i, heapSize); // 对每个非叶子节点进行调整,使其满足最大堆的性质
}
}
// 调整以i为根节点的子树,使其满足最大堆的性质
public void maxHeapify(int[] a, int i, int heapSize) {
//计算左右节点的下标
int left = i * 2 + 1, right = i * 2 + 2, largest = i;
// 下沉操作:比较节点i与其左右子节点的值,找到最大值
// 先与左节点对比
if (left < heapSize && a[left] > a[largest]) {
largest = left;
}
// 再与右节点对比
if (right < heapSize && a[right] > a[largest]) {
largest = right;
}
if (largest != i) {
swap(a, i, largest); // 将节点i与最大值节点交换位置
maxHeapify(a, largest, heapSize); // 继续向下调整以保持最大堆的性质
}
}
// 交换数组中两个元素的位置
public void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}力扣347. 前 K 个高频元素
使用哈希表记录每个元素与其出现次数的映射关系
构建一个大小为k的小根堆,如果不足k个元素就直接将当前数字加入到堆中
否则判断堆中的最小值是否小于当前数字的出现次数,如果堆中的最小值小于当前数字出现次数,说明目前的堆顶元素不在前k个高频元素中,将其弹出并将当前数字加入到堆中
import java.util.*;
class Solution {
public int[] topKFrequent(int[] nums, int k) {
// 统计每个数字出现的次数
Map<Integer, Integer> counter = new HashMap<>();
for (int num : nums) {
counter.put(num, counter.getOrDefault(num, 0) + 1);
}
// 定义小根堆,根据数字频率自小到大排序
Queue<Integer> pq = new PriorityQueue<>(
(v1, v2) -> counter.get(v1) - counter.get(v2));
// 遍历数组,维护一个大小为 k 的小根堆:
// 不足 k 个直接将当前数字加入到堆中;否则判断堆中的最小次数是否小于当前数字的出现次数,
// 若是,则删掉堆中出现次数最少的一个数字,将当前数字加入堆中。
for (int num : counter.keySet()) {
if (pq.size() < k) {
pq.offer(num);
} else if (counter.get(pq.peek()) < counter.get(num)) {
pq.poll();
pq.offer(num);
}
}
// 构造返回结果
int[] res = new int[k];
int idx = 0;
for (int num : pq) {
res[idx++] = num;
}
return res;
}
}



![[SwiftUI]系统弹窗和自定义弹窗](https://img-blog.csdnimg.cn/direct/cb7883773c41438cbe40b3361423c77b.png)