概念

冲突(碰撞)
1.概念:
2.冲突的发生是必然的,我们要做的就是降低冲突率
3.冲突的避免--哈希函数的设计
1.直接定制法(常用)
4.冲突的避免--负载因子调节
散列表的载荷因子(负载因子)=填入表中的元素/散列表的长度
由于表长是定值,所以填入的元素越多,负载因子越大,产生冲突的可能性就越大。一般要将载荷因子控制在0.75以下,当超过0.75时,就应该对哈希表中的数组进行扩容
5.冲突的解决之闭散列


6.冲突的解决之开散列(哈希桶)
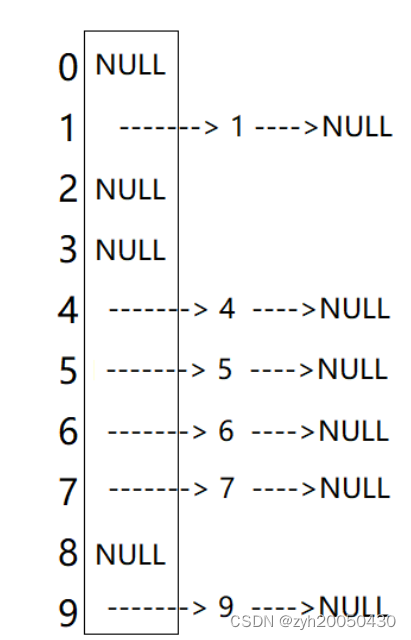
7.哈希桶的实现
首先注意,哈希桶是一个数组,数组的元素其实就是每个链表的头节点
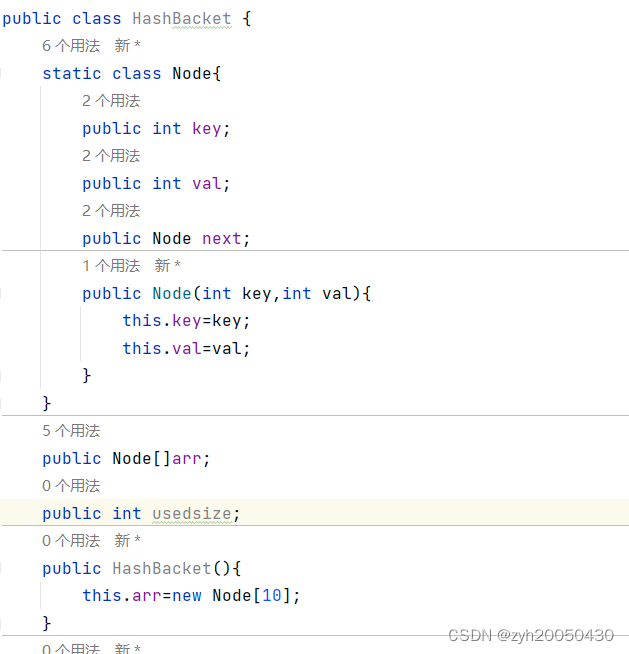
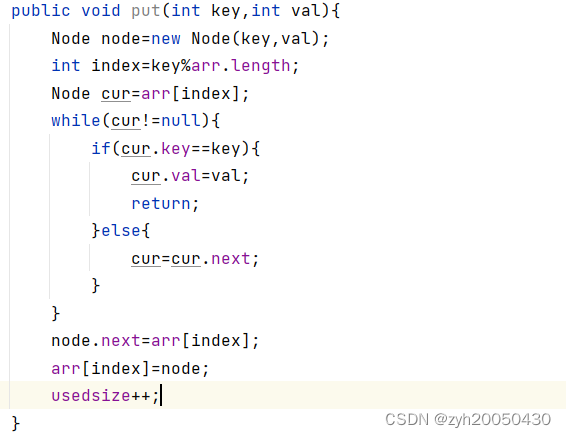
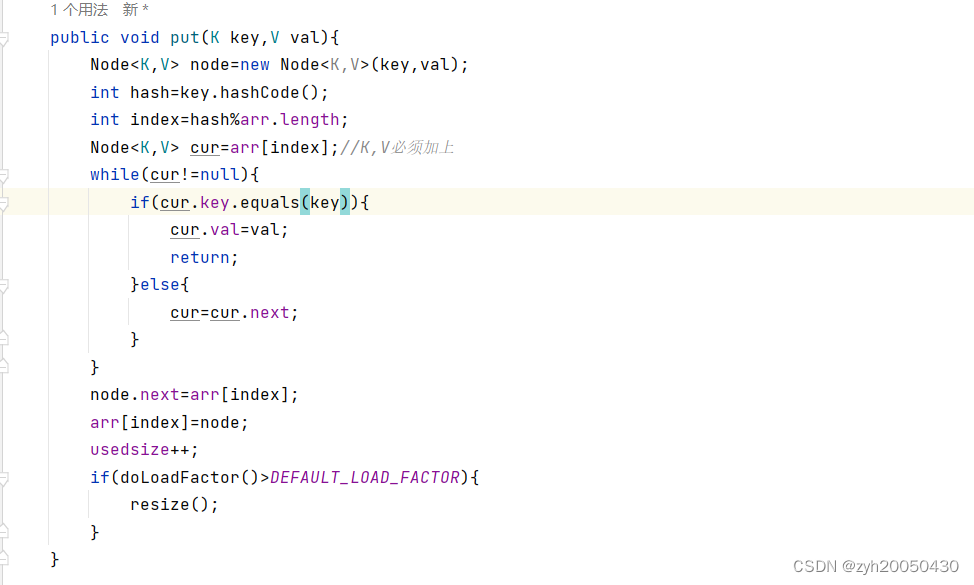
放置元素:
首先要找到对应链表,然后遍历该链表,如果某个结点的key等于待插入结点的key,就更新该节点的value值,然后结束该方法即可;如果没有对应的key,就通过头插法或者尾插法插入该节点,代码如下:
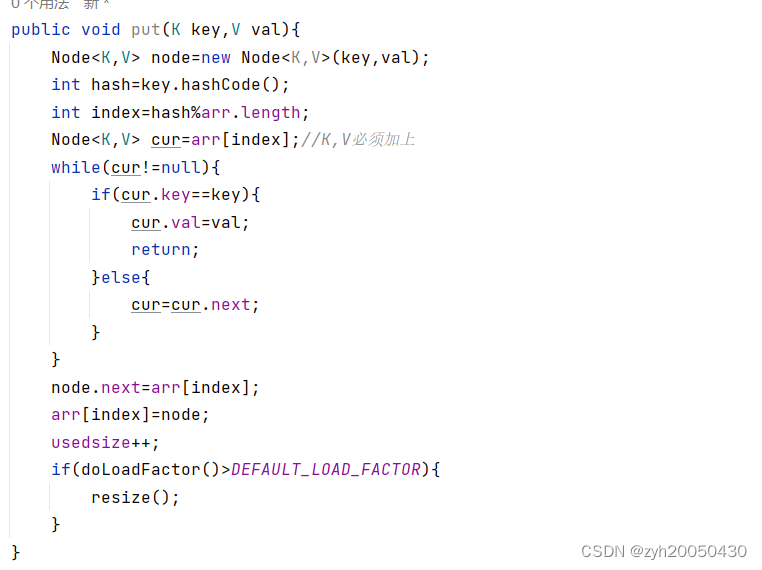
但这样是有缺陷的,我们之前提到了负载因子最好不超过0.75,所以我们再加一个方法返回当前的负载因子,如果大于0.75就进行扩容,代码如下:

首先添加一个成员变量,即默认最大负载因子

然后是计算负载因子
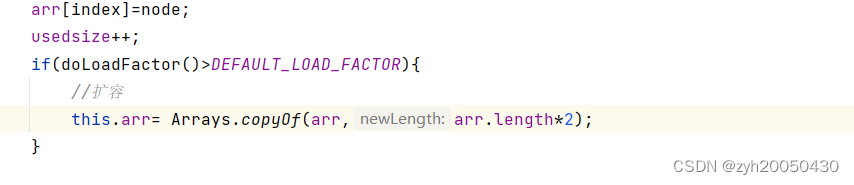
最后是在put方法的最后进行扩容。
但这样的扩容不对!!!因为数组长度变了,对应的key所在的下标就会变!!!,所以代码应为(我用的头插法扩容):
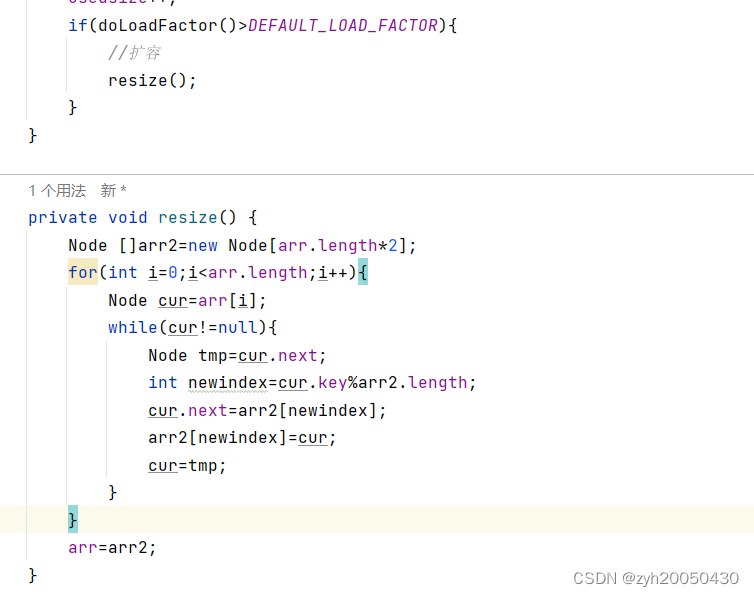
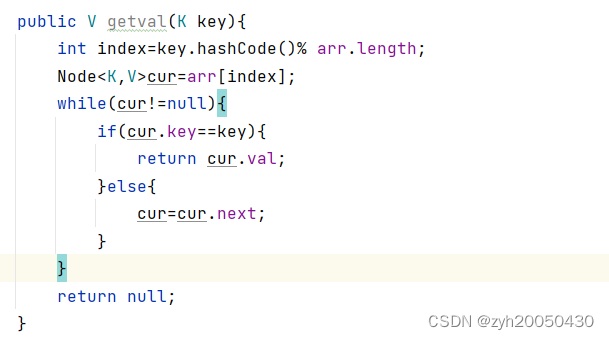
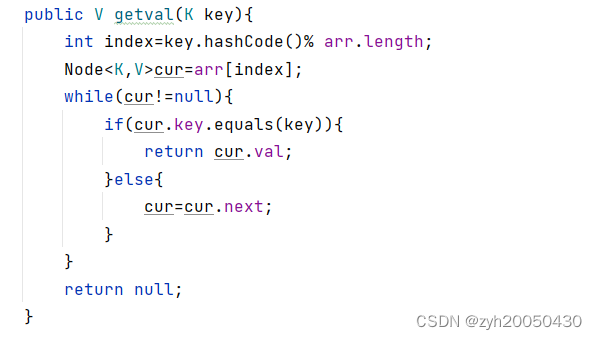
获得value:

HashMap,HasSet的实现
1.Map不支持迭代器遍历,因为它没有实现Iterable接口,要想用迭代器,就必须将Map转化成Set
2.Map中的对象不需要必须可比较,因为他是通过Hash函数来计算所处位置,而不是通过大小比较。并且key或value可以是null,如下:
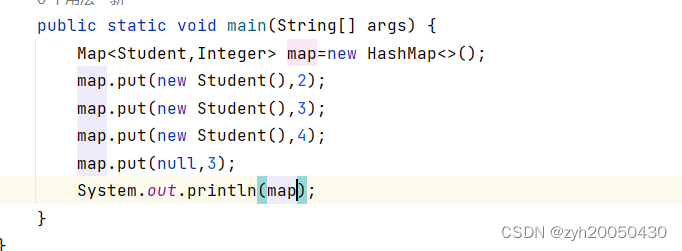
3.HashMap和HashSet一样是可以天然去重的,(TreeSet,TreeMap也一样)如下:

4.HashMap,HashSet对象不一定可比较,key也不一定是一个整数,那么系统是怎么找到对应的下标从而将键值对放进去的呢?这就用到了HashCode方法来生成一个整数。看源码:


当key不是null时,就会调用key的hashCode方法,如果key本身没有hashCode方法,就会调用Object类的方法:


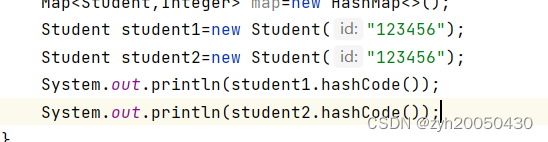
这段话的意思是,在合理情况下,不同的对象会返回不同的整数,这通常是将对象的内部地址转换为整数实现的,所以下面的情况,即使Student的id是相同的,产生的hashCode也是不同的,如下

要想产生同样的整数,就可以重写hashCode方法:
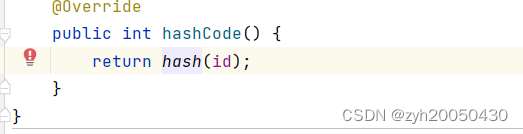
这是我们根据上面的源码自己重写的方法,调用了hash方法,传参时直接传入id,但最好是通过编译器直接生成hashCode方法,同时一并重写equals方法
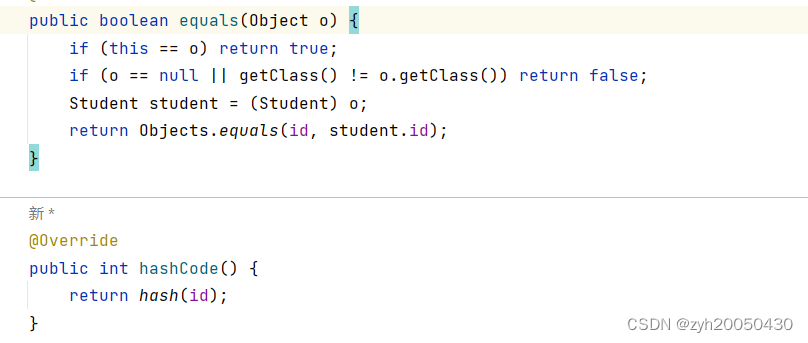
如果不重写equals方法,相同id的对象jinxingequals方法后产生的结果是false,因为源码中equals是根据对象的地址比较的
哈希桶的优化代码
我们将哈希桶写成一个泛型类,并让其可以通过各种类型的key生成对应的整数,代码如下:

1.放置键值对:
2.根据key得到对应的value
看下面的一段代码:
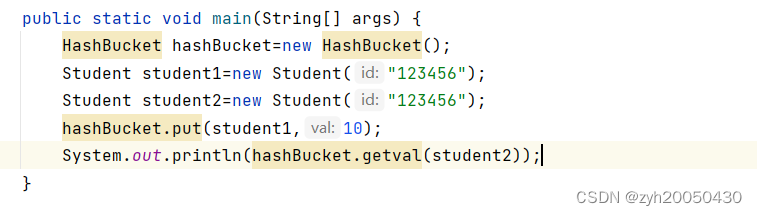
student1和student2的id是一样的,而且我们重写了hashCode方法,所以说,虽然我们只在哈希桶里面放置了student1,但在根据student2取元素时,得到的也应该是10,但结果却如下:

这是因为put函数和getval函数有一句是错的,即if(cur.key==key),应该用equals方法,代码如下:







![[LVGL] 可点击的文字label](https://img-blog.csdnimg.cn/direct/88dc00f068a844159272ec1e458ce0b6.png)