文章目录
- 1.UDF
- 2.UDAF
- 2.1 UDF函数实现原理
- 2.2需求:计算用户平均年龄
- 2.2.1 使用RDD实现
- 2.2.2 使用UDAF弱类型实现
- 2.2.3 使用UDAF强类型实现
1.UDF
用户可以通过 spark.udf 功能添加自定义函数,实现自定义功能。
如:实现需求在用户name前加上"Name:"字符串,并打印在控制台
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import sc.implicits._
//创建DataFrame
val dataRDD: RDD[(String,Int)] = sc.sparkContext.makeRDD(List(("zhangsan",21),("lisi",24)))
val dataframe = dataRDD.toDF("name","age")
//注册udf函数
sc.udf.register("addName",(x:String)=>
"Name:"+x
)
//创建临时视图
dataframe.createOrReplaceTempView("people")
//对临时视图使用udf函数
sc.sql("select addName(name) from people").show()
sc.stop()
}

2.UDAF
强类型的 Dataset 和弱类型的 DataFrame 都提供了相关的聚合函数, 如 count(),countDistinct(),avg(),max(),min()。除此之外,用户可以设定自己的自定义聚合函数。**通过继承 UserDefinedAggregateFunction 来实现用户自定义弱类型聚合函数。**从 Spark3.0 版本后,UserDefinedAggregateFunction 已经不推荐使用了。可以统一采用强类型聚合函数Aggregator。
2.1 UDF函数实现原理
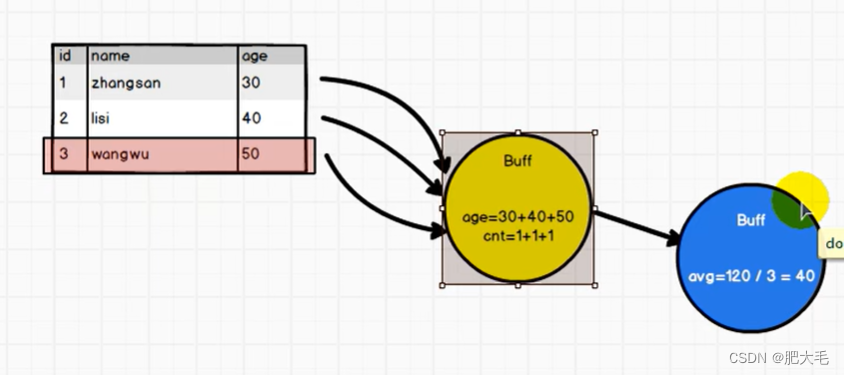
在Spark中,UDF(用户自定义函数)在对表中的数据进行处理时,通常会将数据放入缓冲区中以便进行计算。这种缓冲策略可以提高数据处理的效率,特别是对于大数据集。
2.2需求:计算用户平均年龄
2.2.1 使用RDD实现
val dataRDD: RDD[(String,Int)] = sc.sparkContext.makeRDD(List(("zhangsan",21),("lisi",24),("wangwu",26)))
val reduceResult: (Int, Int) = dataRDD.map({
case (name, age) => {
(age, 1)
}
}).reduce((t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
})
println(reduceResult._1/reduceResult._2)

2.2.2 使用UDAF弱类型实现
需要用户自定义类实现UserDefinedAggregateFunction,并重写其中的方法,当前已不推荐使用。
package bigdata.wordcount.udf
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
import org.apache.spark.sql.expressions.{MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, LongType, StructField, StructType}
import org.apache.spark.util.AccumulatorV2
/**
* 用户自定义函数
*/
object UDF_Demo02 {
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import sc.implicits._
val dataRDD: RDD[(String, Int)] = sc.sparkContext.makeRDD(List(("zhangsan", 19), ("lisi", 21), ("wangwu", 22)))
val dataFrame: DataFrame = dataRDD.toDF("name","age")
dataFrame.createOrReplaceTempView("user")
//创建聚合函数
var myAvg=new MyAverageUDAF()
//在Spark中注册自定义的聚合函数
sc.udf.register("avgMy",myAvg)
sc.sql("select avgMy(age) from user").show()
sc.stop()
}
case class User(var name:String,var age:Int)
}
class MyAverageUDAF extends UserDefinedAggregateFunction{
//输入的要进行聚合的参数的类型
override def inputSchema: StructType = StructType(Array(StructField("age",IntegerType)))
//聚合函数缓冲区中的值的数据类型
override def bufferSchema: StructType = StructType(Array(StructField("sum",LongType),StructField("count",LongType)))
//函数返回的值的数据类型
override def dataType: DataType = DoubleType
//判断函数的稳定性
//对于相同类型的输入是否有相同类型的输出
override def deterministic: Boolean = true
//聚合函数缓冲区中值的初始化
//因为数据是弱类型的,函数缓冲区中是根据索引来找到对应的变量
override def initialize(buffer: MutableAggregationBuffer): Unit = {
//年龄的总和
buffer(0)=0L
//年龄的个数
buffer(1)=0L
}
//更新缓冲区中的数据(执行操作步骤)
override def update(buffer: MutableAggregationBuffer, input: Row): Unit ={
//第0个索引值是否为空
if(!input.isNullAt(0)) {
//更新年龄sum的值
buffer(0)=buffer.getLong(0)+input.getInt(0)
//更新年龄个数
buffer(1)=buffer.getLong(1)+1;
}
}
//合并缓冲区
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
buffer1(0)=buffer1.getLong(0)+buffer2.getLong(0)
buffer1(1)=buffer1.getLong(1)+buffer2.getLong(1)
}
//计算最终结果
override def evaluate(buffer: Row): Double = {
buffer.getLong(0).toDouble / buffer.getLong(1)
}
}

2.2.3 使用UDAF强类型实现
Spark3.0 版本可以采用强类型的 Aggregator 方式代替 UserDefinedAggregateFunction
package bigdata.wordcount.udf
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, Encoder, Encoders, Row, SparkSession, TypedColumn}
import org.apache.spark.sql.expressions.{Aggregator, MutableAggregationBuffer, UserDefinedAggregateFunction}
import org.apache.spark.sql.types.{DataType, DoubleType, IntegerType, LongType, StructField, StructType}
import org.apache.spark.util.AccumulatorV2
/**
* 用户自定义函数
*/
object UDF_Demo03 {
def main(args: Array[String]): Unit = {
//创建上下文环境配置对象
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSQLDemo03")
//创建 SparkSession 对象
val sc: SparkSession = SparkSession.builder().config(conf).getOrCreate()
import sc.implicits._
val dataRDD: RDD[(String, Int)] = sc.sparkContext.makeRDD(List(("zhangsan", 19), ("lisi", 21), ("wangwu", 22)))
val dataFrame: DataFrame = dataRDD.toDF("name","age")
val dataset: Dataset[User01] = dataFrame.as[User01]
//创建聚合函数
var myAvg=new MyAverageUDAF01()
//将聚合函数转换为查询的列
val col: TypedColumn[User01, Double] = myAvg.toColumn
//执行查询操作
dataset.select(col).show()
sc.stop()
}
case class User(var name:String,var age:Int)
}
//输入数据类型
case class User01(var name:String,var age:Int)
//缓存中的数据类型
case class AgeBuffer(var sum:Long,var count:Long)
class MyAverageUDAF01 extends Aggregator[User01,AgeBuffer,Double]{
//设置初始值
override def zero: AgeBuffer = {
AgeBuffer(0L,0L)
}
//缓冲区实现聚合
override def reduce(b: AgeBuffer, a: User01): AgeBuffer = {
b.sum = b.sum + a.age
b.count = b.count + 1
b
}
//合并缓冲区
override def merge(b1: AgeBuffer, b2: AgeBuffer): AgeBuffer = {
b1.sum+=b2.sum
b1.count+=b2.count
b1
}
//计算最终结果
override def finish(buff: AgeBuffer): Double = {
buff.sum.toDouble/buff.count
}
//设置编码器和解码器
//自定义类型就是 product 自带类型根据类型选择
override def bufferEncoder: Encoder[AgeBuffer] = {
Encoders.product
}
override def outputEncoder: Encoder[Double] = {
Encoders.scalaDouble
}
}







![[LVGL] 可点击的文字label](https://img-blog.csdnimg.cn/direct/88dc00f068a844159272ec1e458ce0b6.png)