删除有序数组中重复项的解决之路= =
这个标签是简单,所以比较好过。
题干描述
根据题目描述,重点在于原地删除,也就是空间复杂度为O(1)。

测试案例(部分)
第一次
根据题目描述,重点在于原地删除。
class Solution(object):
def removeDuplicates(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
for k, v in enumerate(nums):
i = 1
if k+i < len(nums):
temp = nums[k+i]
else:
break
while(v == temp):
nums.remove(v)
i += 1
if k+i < len(nums):
temp = nums[k+i]
else:
break
return len(nums)
测试了代码,有错误的结果,会有重复的部分没有被删除。
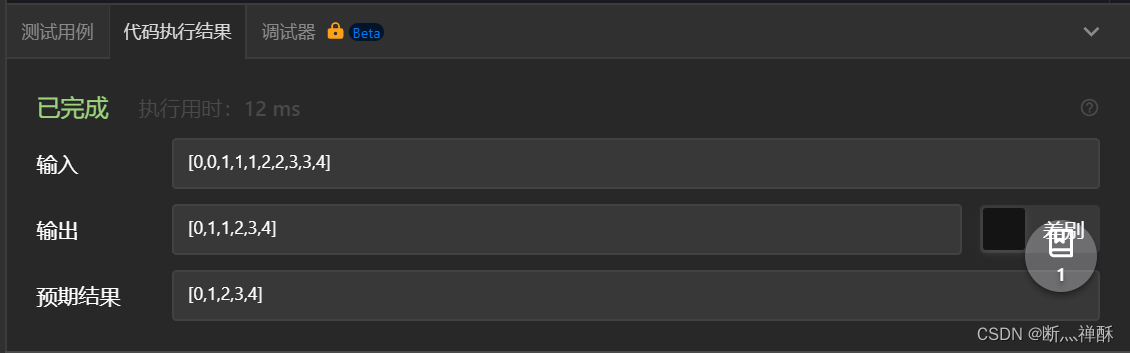
第二次
有的测试案例可以通过,但还是有问题,比如测试序列[0,0,1,1,1,2,2,3,3,4],输出的是[0,1,1,2,3,4],与答案不符。
原因我们找一下,用手算推演了一下过程,会发现,我们这个设计的nums[k+i]的探测不合理。
比如测试序列[0,0,1,1,1,2,2,3,3,4]中,这三个1的情况,第一次检测下标为2的1和下标为3的1重复,然后删除下标为2的1;现在新的下标为2的1和下标为3的1还是重复,但是因为这个i,反而不会与下标为3的1比较,而是与2+2=4的下标比较,所以最终输出会多出一个1没有被删除。
所以,+i改成一直+1就可以了,因为删除之后会产生新的下标,不需要动态的+i。
class Solution(object):
def removeDuplicates(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
for k, v in enumerate(nums):
if k+1 < len(nums):
temp = nums[k+1]
else:
break
while(v == temp):
nums.remove(v)
if k+1 < len(nums):
temp = nums[k+1]
else:
break
return len(nums)
测试案例全部通过,提交试试。通过了。
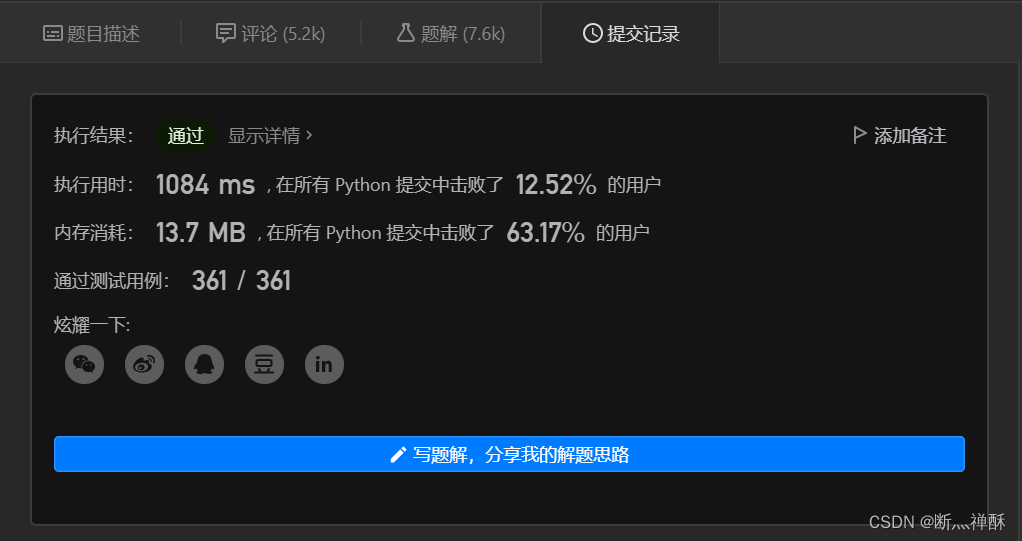
第三次(抄的)
提交了,通过了,不过时间就击败了12%。。。
回过头来看看代码,感觉应该想不出什么更快的方案了,翻翻万能的评论区。
woc,看到了一个老哥的代码,一下就搞定了。
class Solution(object):
def removeDuplicates(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
n = len(nums)
for i in range(n-1,0,-1):
if nums[i] == nums[i-1]:
nums.pop(i)
return len(nums)
就用了28ms,比我的1084要快好多啊,没想到这样还只是击败50%。。。。简直就是36(除了6还是6)
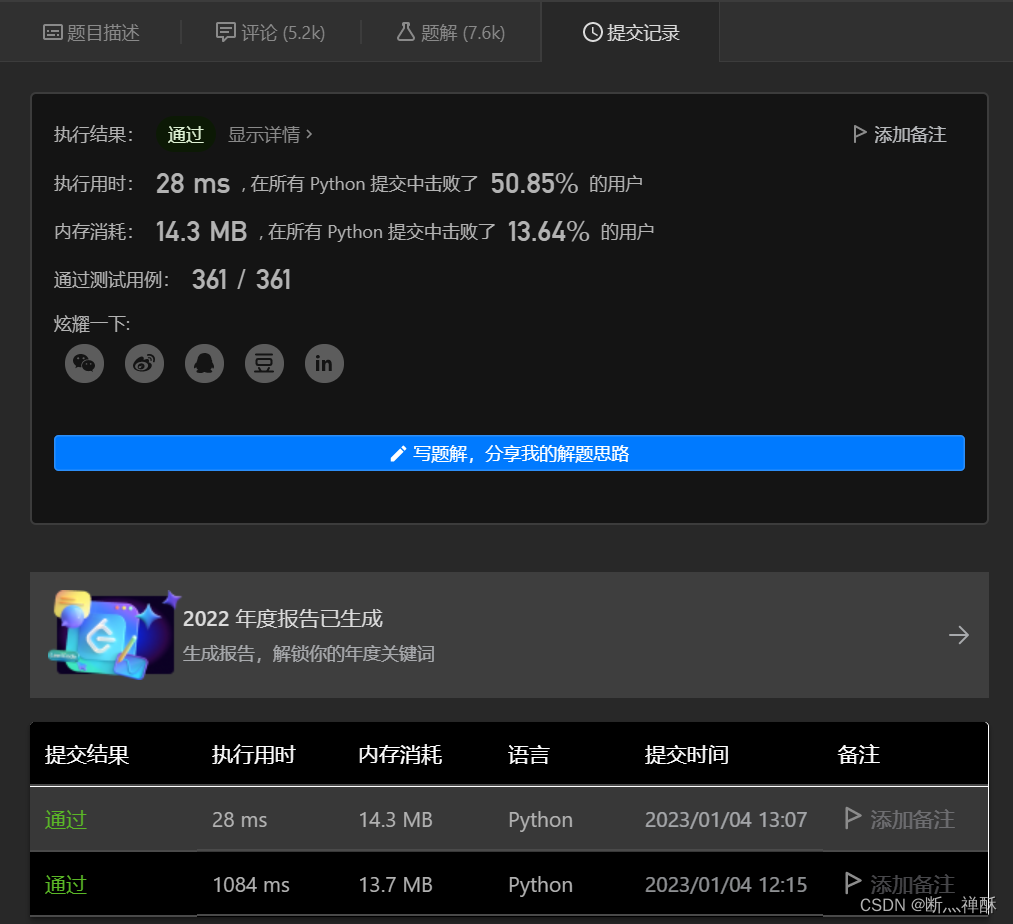
后续闲聊
学习了一下这个代码思路。最主要费时间的代码就是while循环,直接用一个if就可以代替了,不需要while循环判断。
至于为什么要逆序,如果用if来写的话,从前往后删除元素的时候,从前往后通过下标来进行每轮的for循环就会产生跳元素的情况。就像下面的代码
class Solution(object):
def removeDuplicates(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
for i in range(len(nums)):
if i+1 >= len(nums):
break
if nums[i] == nums[i+1]:
nums.remove(nums[i])
return len(nums)
执行测试案例,发现确实有跳元素的情况。
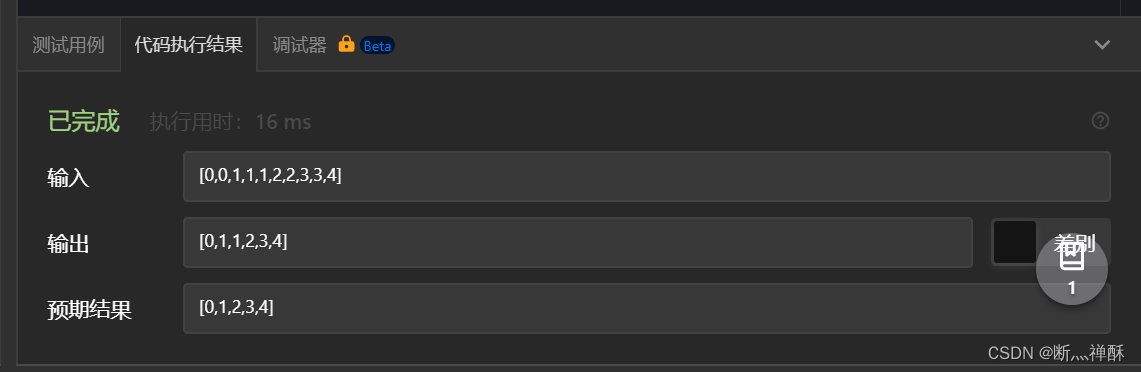
【第一轮for循环】i=0,无越界情况,比较下标为0的0和下标为1的0,发现相等,删除第一个0。
【第二轮for循环】i=1, 无越界情况,比较下标为1的1和下标为2的1,发现相等,删除第一个1。
【第三轮for循环】i=2, 无越界情况,比较下标为2的1和下标为3的2,不相等,进行下一次for循环。(跳过了一个1没有删除!)
而用逆序,就不用考虑下标混乱产生的跳元素现象了。
class Solution(object):
def removeDuplicates(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
for i in range(len(nums)-1, 0, -1):
if nums[i] == nums[i-1]:
nums.remove(nums[i])
return len(nums)
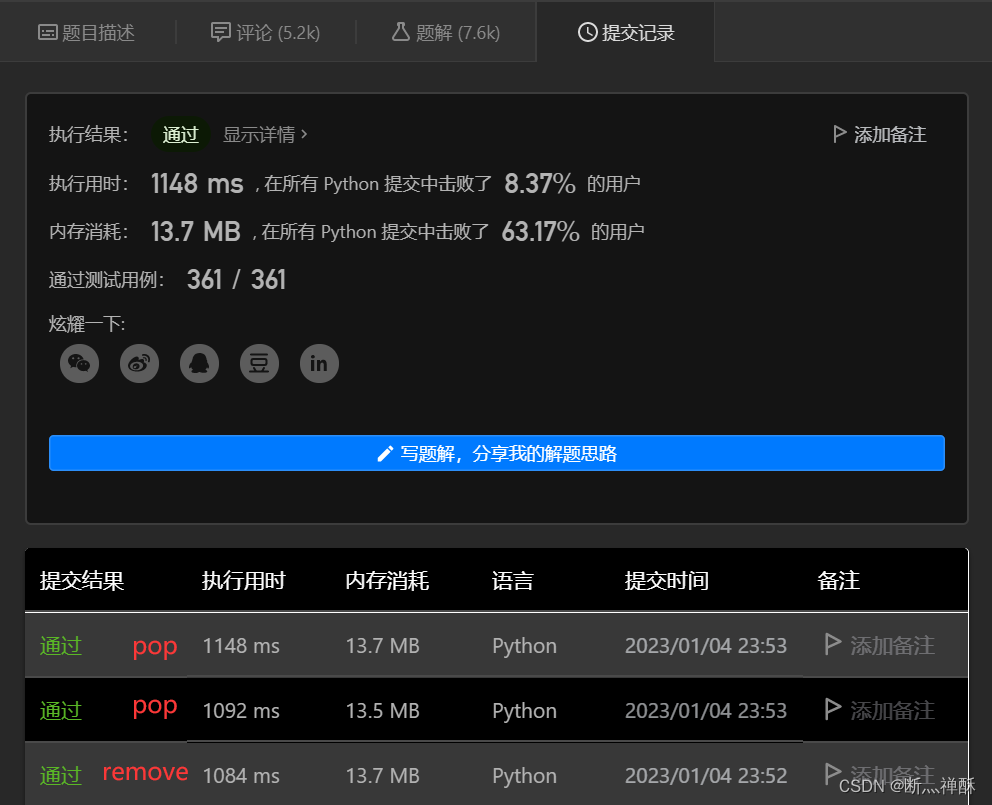
提交了,通过了,不过时间更长了。
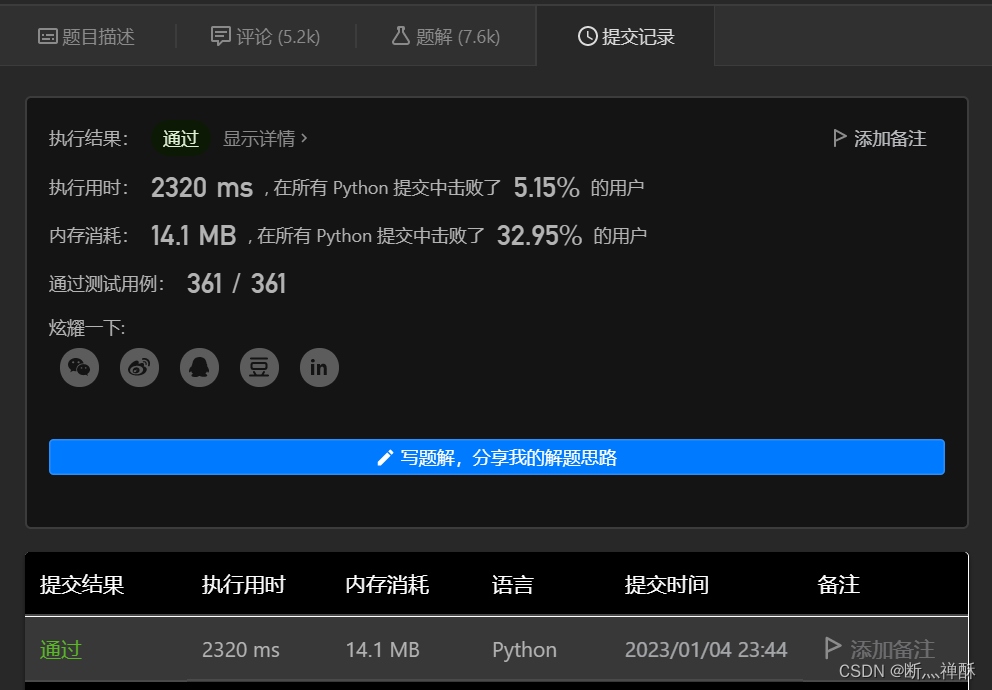
再看看代码的差异,就剩pop和remove这两个差异了。关于这两个函数的描述如下:
python的列表,提供两个删除元素的方法,一个是pop,一个是remove。
pop()是通过下标删除元素,比如pop(1),就是删除下标为1的元素。
remove()是通过查找元素来删除元素,比如remove(36),就是从列表的头开始找,找到第一个等于36的元素,然后把第一个36的元素删除(还有其他36的话,不会被删除)
可能是自己的代码中,使用了remove(),这种方式删除元素,需要O(n)的复杂度。(顺序查找元素要花费O(n))按下标删除元素会更快一些。改为pop(i)时间确实快了,而且pop(i)和pop(i-1)都可以。
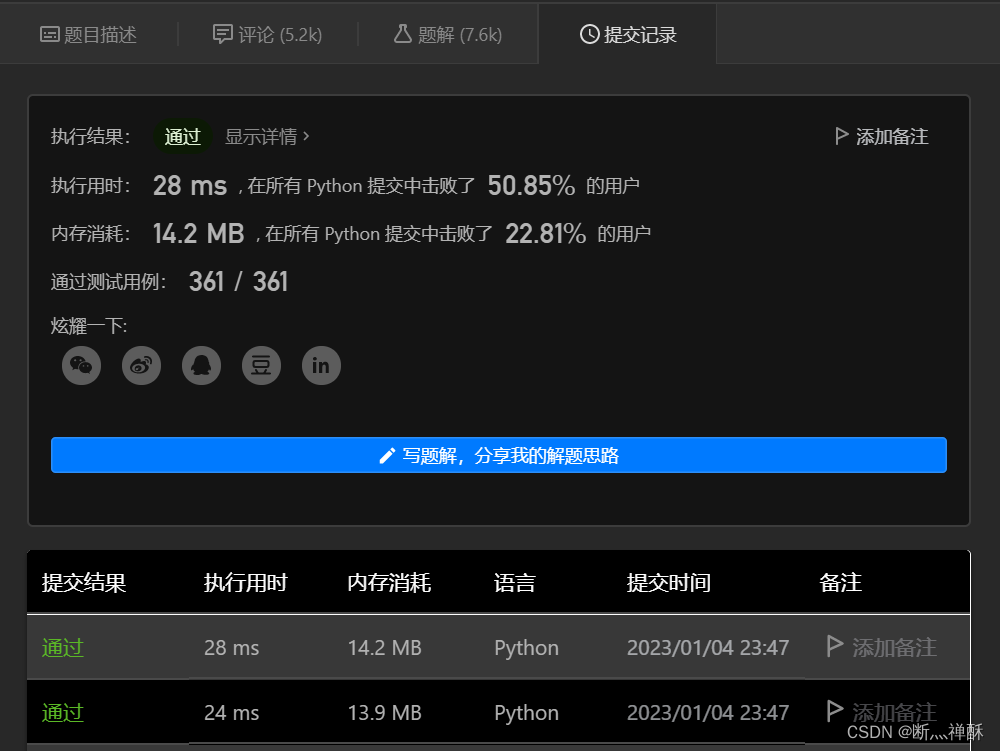
不过,python中remove()的底层实现,不一定是顺序查找再删除。因为使用while循环+pop()实现功能,时间差别不大,甚至更慢。






![JdbcUtils工具类的优化升级——通过配置文件连接mysql8.0,并对mysql8.0中的表进行[简单查询]操作](https://img-blog.csdnimg.cn/9bae8ccb7269403e9911afec07182d46.png)