在现代数据库管理系统中,窗口函数(Window Functions)已经成为处理复杂数据分析任务的关键工具。MySQL从8.0版本开始引入了对窗口函数的支持,这极大地增强了其在数据分析和报表生成方面的能力。本文将深入探讨MySQL窗口函数的原理、应用场景以及优化策略。
一、什么是窗口函数
窗口函数(Window Functions)是SQL标准中的一个高级特性,它允许用户在不改变查询结果集行数的情况下,对每一行执行聚合计算或其他复杂的计算。这些计算是基于当前行与结果集中其他行之间的关系进行的。窗口函数特别适用于需要执行跨多行的计算,同时又想保持原始查询结果集的行数不变的场景。
1. 窗口函数的原理
窗口函数通过在查询结果集上定义一个“窗口”来工作,这个窗口可以是整个结果集,也可以是结果集的一个子集。窗口函数会对窗口内的行执行计算,并为每一行返回一个值。这个值是根据窗口内行的值以及窗口函数本身的逻辑计算得出的。
窗口函数不会改变查询结果集的行数,而是为每一行添加一个额外的列,这个列包含了窗口函数的计算结果。这使得窗口函数非常适合于需要在保持原始数据的同时进行聚合或其他复杂计算的场景。
2. 窗口函数的组成部分
窗口函数的基本语法结构如下:
<窗口函数>(<参数>) OVER (
[PARTITION BY <分区表达式>]
[ORDER BY <排序表达式> [ASC | DESC]]
[ROWS/Range <窗口范围>]
)
-
<窗口函数>(<参数>):指定要使用的窗口函数及其参数。窗口函数可以是聚合函数(如SUM、AVG等),也可以是专门为窗口函数设计的函数(如ROW_NUMBER、RANK等)。
-
OVER():定义窗口的框架。所有窗口函数都需要使用OVER()子句来指定窗口的范围和行为。
-
PARTITION BY <分区表达式>(可选):将结果集分成多个分区,窗口函数会在每个分区内独立执行。分区表达式可以是一个或多个列名,用于确定如何将结果集分成不同的分区。
-
ORDER BY <排序表达式> [ASC | DESC](可选):指定窗口内行的排序顺序。排序表达式可以是一个或多个列名,用于确定窗口内行的排序方式。
-
ROWS/Range <行范围>(可选):定义窗口的行范围。行范围可以是固定的行数(如ROWS BETWEEN 2 PRECEDING AND CURRENT ROW),也可以是相对于当前行的动态范围(如ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW,表示从窗口开始到当前行的所有行)。
3. 解释下窗口范围
MySQL的窗口函数中,指定窗口大小的语法主要是通过OVER()子句来实现的,其中可以使用ROWS或RANGE关键字来定义窗口的边界。不过,需要注意的是,ROWS和RANGE定义了窗口的范围是基于物理行位置还是列值,而不是直接指定窗口的“大小”。窗口的“大小”实际上是由这些范围参数以及ORDER BY子句共同决定的。
以下是OVER()子句中指定窗口范围的基本语法:
OVER (
[PARTITION BY partition_expression, ... ]
[ORDER BY sort_expression [ASC | DESC], ...]
[ROWS frame_specification]
-- 或者
[RANGE frame_specification]
)
其中,frame_specification定义了窗口的起始和结束位置,它有以下几种形式:
BETWEEN frame_start AND frame_end:指定窗口的开始和结束边界。
frame_start:如果只指定了开始边界,则窗口会从该边界延伸到当前分区的最后一行。
frame_end:通常不会只单独指定结束边界,因为它需要开始边界来形成完整的窗口范围。
对于ROWS和RANGE,frame_start和frame_end可以是以下值之一:
UNBOUNDED PRECEDING:窗口从当前分区的第一行开始。
N PRECEDING:窗口从当前行之前的第N行开始,N是一个正整数。
CURRENT ROW:窗口从当前行开始。
N FOLLOWING:窗口从当前行之后的第N行开始。
UNBOUNDED FOLLOWING:窗口到当前分区的最后一行结束(通常只用于frame_end)。
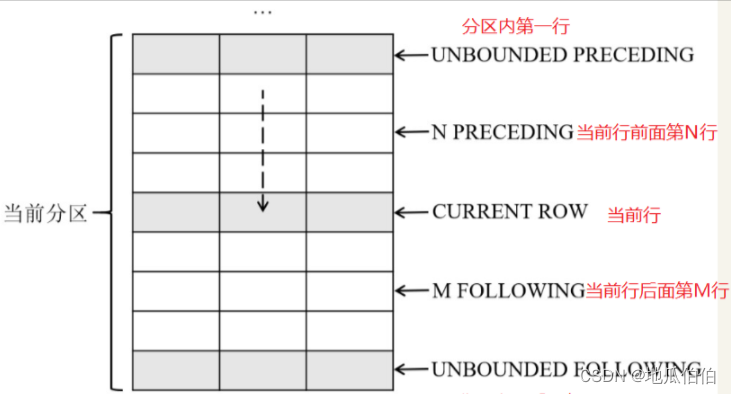
ROWS是基于行的物理位置来确定窗口范围的,而RANGE则是基于ORDER BY子句中指定的列值来确定窗口范围的。RANGE在处理数值数据时特别有用,因为它可以包含与当前行值相近的其他行,即使它们的物理位置不相邻。
例子:
-- 使用ROWS指定窗口范围,计算当前行及其前两行的销售额总和
SELECT sale_date, amount,
SUM(amount) OVER (ORDER BY sale_date ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) AS rolling_total
FROM sales;
-- 使用RANGE指定窗口范围,计算当前行值附近范围内的平均值
SELECT price,
AVG(price) OVER (ORDER BY price RANGE BETWEEN 10 PRECEDING AND 10 FOLLOWING) AS avg_nearby_price
FROM products;
在第一个例子中,ROLLING_TOTAL计算了包括当前行在内的前三行的AMOUNT字段的总和。在第二个例子中,AVG_NEARBY_PRICE计算了当前PRICE值前后10个单位范围内的平均价格(注意,实际范围可能包括更多的行,因为RANGE会包含所有在这个范围内的行,即使它们的物理位置不是紧挨着的)。
需要注意的是,RANGE的使用可能会因为列值的分布和重复情况而变得复杂,因为它必须维护一个有序的数据结构来确定哪些行在指定的范围内。而ROWS则简单地基于行的物理顺序来计算窗口。
以下是ROWS子句的常用选项:
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:从窗口的开始到当前行。这是默认的窗口范围,如果未指定ROWS子句,则使用此范围。
ROWS BETWEEN N PRECEDING AND CURRENT ROW:从当前行之前的第N行到当前行。N必须是一个非负整数。
ROWS BETWEEN CURRENT ROW AND N FOLLOWING:从当前行到当前行之后的第N行。
ROWS BETWEEN N PRECEDING AND M FOLLOWING:从当前行之前的第N行到当前行之后的第M行。
以下是RANGE子句的常用选项:
RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW:从窗口的最小值到当前行值。
RANGE BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING:从当前行值到窗口的最大值。
RANGE BETWEEN N PRECEDING AND CURRENT ROW:从当前行值减去N到当前行值。这里的N通常是一个数字表达式,它指定了与当前行值相关的范围大小。
RANGE BETWEEN CURRENT ROW AND N FOLLOWING:从当前行值到当前行值加上N。
请注意,RANGE通常与ORDER BY子句一起使用,以确定窗口边界的逻辑顺序。而且,当使用RANGE时,如果列值有重复,则窗口可能会包含比预期更多的行。
RANGE的一个常见用途是计算移动平均值,尤其是当数据点不是均匀分布时。然而,在实践中,由于RANGE需要维护一个有序的数据结构,并且处理重复值时可能会导致性能问题,所以ROWS通常比RANGE更受欢迎.
4. 窗口函数与聚合函数的区别
窗口函数和聚合函数在MySQL中都是用于数据分析和报告的强大工具,但它们之间存在明显的区别。以下将通过具体例子来说明这两者的不同。
- 聚合函数(Aggregate Functions)
聚合函数作用于一组行,并返回单个值。常见的聚合函数有 SUM()、AVG()、MIN()、MAX() 和 COUNT() 等。这些函数通常与 GROUP BY 子句一起使用,以便对分组的数据进行聚合。
例子:假设有一个销售数据表 sales,包含 product_id、sale_date 和 amount 列。要计算每种产品的总销售额,可以使用聚合函数如下:
SELECT product_id, SUM(amount) AS total_sales
FROM sales
GROUP BY product_id;
在这个例子中,SUM(amount) 是一个聚合函数,它对每个 product_id 分组内的 amount 值进行求和,返回每个产品的总销售额。结果集将包含更少的行,因为数据被聚合到了每个产品ID上。
- 窗口函数(Window Functions)
窗口函数作用于查询结果集的每一行,但它们的计算是基于一个“窗口”范围内的其他行。窗口函数不会减少结果集的行数,而是为每一行添加额外的计算结果。常见的窗口函数有 ROW_NUMBER()、RANK()、DENSE_RANK()、SUM()(作为窗口函数使用)、AVG()(作为窗口函数使用)等。
例子:使用相同的 sales 表,如果我们想要计算每种产品在每一天的销售额,并且还想知道到那一天为止该产品的累计销售额,我们可以使用窗口函数如下:
SELECT product_id, sale_date, amount,
SUM(amount) OVER (PARTITION BY product_id ORDER BY sale_date ASC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS cumulative_sales
FROM sales;
在这个例子中,SUM(amount) OVER (…) 是一个窗口函数。它计算了到当前行为止(包括当前行),按 sale_date 排序的每个 product_id 的累计销售额。PARTITION BY product_id 表示数据首先按产品ID分区,然后在每个分区内按销售日期排序。ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 定义了窗口范围,从分区的第一行到当前行。
结果集将包含与原始 sales 表相同数量的行,但会添加一个额外的 cumulative_sales 列,显示到每一行为止的累计销售额。
聚合函数减少结果集的行数,将多行数据聚合成单个值。
窗口函数保持结果集的行数不变,为每一行添加基于窗口范围内其他行的计算结果。
聚合函数通常与 GROUP BY 一起使用,而窗口函数则与 OVER() 子句一起使用来定义窗口的行为。
二、窗口函数分类
MySQL的窗口函数可以根据它们的功能和用途进行分类:
1. 序号窗口函数
序号函数为结果集中的每一行分配一个唯一的序号或排名。这些函数通常基于排序顺序和其他条件来分配这些序号。
ROW_NUMBER(): 为每一行分配一个唯一的序号。
RANK(): 为每一行分配一个排名,对于相同的值会留下空位。
DENSE_RANK(): 为每一行分配一个排名,但不会为相同的值留下空位。
假设我们有一个名为employees的表,其中包含员工的信息,如下所示:
CREATE TABLE employees (
emp_id INT PRIMARY KEY,
emp_name VARCHAR(50),
salary DECIMAL(10, 2)
);
INSERT INTO employees (emp_id, emp_name, salary) VALUES
(1, 'Alice', 50000),
(2, 'Bob', 55000),
(3, 'Charlie', 50000),
(4, 'David', 60000),
(5, 'Eva', 55000);
现在,我们想要为每个员工分配一个唯一的序号(使用ROW_NUMBER()),一个排名(使用RANK()),以及一个密集排名(使用DENSE_RANK()),都是基于他们的薪水。
SELECT
emp_id,
emp_name,
salary,
ROW_NUMBER() OVER (ORDER BY salary DESC) AS row_num,
RANK() OVER (ORDER BY salary DESC) AS rank,
DENSE_RANK() OVER (ORDER BY salary DESC) AS dense_rank
FROM
employees;
-- 这个查询的结果可能会是这样的:
emp_id | emp_name | salary | row_num | rank | dense_rank
-------+----------+--------+---------+------+------------
4 | David | 60000 | 1 | 1 | 1
2 | Bob | 55000 | 2 | 2 | 2
5 | Eva | 55000 | 3 | 2 | 2
1 | Alice | 50000 | 4 | 4 | 3
3 | Charlie | 50000 | 5 | 4 | 3
在这个结果集中:
row_num 列显示了使用 ROW_NUMBER() 函数分配的唯一序号。序号是根据薪水降序排列的,所以薪水最高的员工(David)得到了序号 1。
rank 列显示了使用 RANK() 函数分配的排名。注意,当两个员工的薪水相同时,他们会获得相同的排名,并且下一个员工会跳过相应的排名。在这个例子中,Bob 和 Eva 都获得了排名 2,因此 Alice 和 Charlie 跳过了排名 3,直接获得了排名 4。
dense_rank 列显示了使用 DENSE_RANK() 函数分配的密集排名。与 RANK() 不同,DENSE_RANK() 不会在遇到重复值时留下任何间隔。因此,尽管 Bob 和 Eva 的薪水相同,但 Alice 和 Charlie 仍然获得了紧接着的密集排名 3。
2. 分布窗口函数
分布函数用于计算值在窗口内的相对位置或分布。
PERCENT_RANK(): 计算行的百分比排名。
CUME_DIST(): 计算行相对于所有其他行的累积分布。
当使用窗口函数 PERCENT_RANK() 和 CUME_DIST() 时,这些函数通常用于计算结果集中行的相对排名和累积分布。下面是一个示例,展示了如何在一个查询中同时使用这两个函数。
假设我们有一个名为 sales 的表,其中包含销售数据,如下所示:
CREATE TABLE sales (
sale_id INT PRIMARY KEY,
sale_date DATE,
amount DECIMAL(10, 2)
);
INSERT INTO sales (sale_id, sale_date, amount) VALUES
(1, '2023-01-01', 1000),
(2, '2023-01-02', 1500),
(3, '2023-01-03', 1200),
(4, '2023-01-04', 1800),
(5, '2023-01-05', 1100);
现在,我们想要计算每一行销售额的百分比排名和累积分布。以下是查询的示例:
SELECT
sale_id,
sale_date,
amount,
PERCENT_RANK() OVER (ORDER BY amount DESC) AS percent_rank,
CUME_DIST() OVER (ORDER BY amount DESC) AS cume_dist
FROM
sales;
-- 这个查询的结果可能会是这样的:
sale_id | sale_date | amount | percent_rank | cume_dist
--------+-------------+--------+--------------+-----------
4 | 2023-01-04 | 1800 | 0 | 0.2
2 | 2023-01-02 | 1500 | 0.25 | 0.4
3 | 2023-01-03 | 1200 | 0.5 | 0.6
5 | 2023-01-05 | 1100 | 0.75 | 0.8
1 | 2023-01-01 | 1000 | 1 | 1.0
在这个结果集中:
percent_rank 列显示了使用 PERCENT_RANK() 函数计算的百分比排名。它是当前行的排名与总行数减1的比值,再乘以100。因为我们有5行数据,所以百分比排名的范围是0到1(包括0但不包括1),并且按 amount 降序排列。
cume_dist 列显示了使用 CUME_DIST() 函数计算的累积分布。它表示当前行的值小于或等于当前行的值的行数占总行数的比例。在这个例子中,CUME_DIST() 也是按 amount 降序排列的,所以最高销售额的行有最低的累积分布值(但不会是0,除非有相同的 amount 值),而最低销售额的行有最高的累积分布值(总是1)。
请注意,PERCENT_RANK() 和 CUME_DIST() 的计算结果可能会因数据库的实现和精度而略有不同,但上面的示例应该给出了大致的概念。此外,如果 amount 有相同的值,这两个函数的行为也会有所不同,PERCENT_RANK() 会为相同的值分配相同的百分比排名,而 CUME_DIST() 则会考虑相同值对累积分布的影响。
3. 前后窗口函数
前后函数允许您访问与当前行相关的前一行或后一行的值。
LAG(expr, offset, default): 返回指定偏移量之前的行的值。
LEAD(expr, offset, default): 返回指定偏移量之后的行的值。
4. 首尾窗口函数:
首尾函数允许您获取窗口的第一行或最后一行的值。
FIRST_VALUE(expr): 返回窗口内第一行的值。
LAST_VALUE(expr): 返回窗口内最后一行的值。
需要注意的是,FIRST_VALUE() 和 LAST_VALUE() 在没有指定 ORDER BY 子句时可能不会按预期工作,因为窗口的顺序是不确定的。此外,LAST_VALUE() 在某些情况下可能不如使用 LEAD() 函数灵活。
举个栗子:我们假设有一个名为 stock_prices 的表,该表记录了某支股票每天的价格信息。
表结构如下:
CREATE TABLE stock_prices (
stock_date DATE PRIMARY KEY,
price DECIMAL(10, 2)
);
INSERT INTO stock_prices (stock_date, price) VALUES
('2023-10-01', 100.00),
('2023-10-02', 102.50),
('2023-10-03', 99.75),
('2023-10-04', 101.25),
('2023-10-05', 104.00),
('2023-10-06', 105.50),
('2023-10-07', 103.00);
现在,我们想要查询每天的股票价格,以及前一天和后一天的价格,还有该股票在记录期间的首日和末日的价格。以下是查询的示例:
SELECT
stock_date,
price,
LAG(price) OVER (ORDER BY stock_date) AS prev_day_price,
LEAD(price) OVER (ORDER BY stock_date) AS next_day_price,
FIRST_VALUE(price) OVER (ORDER BY stock_date) AS first_day_price,
LAST_VALUE(price) OVER (ORDER BY stock_date ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_day_price
FROM
stock_prices;
-- 查询的结果可能如下:
stock_date | price | prev_day_price | next_day_price | first_day_price | last_day_price
------------+---------+----------------+----------------+-----------------+----------------
2023-10-01 | 100.00 | NULL | 102.50 | 100.00 | 103.00
2023-10-02 | 102.50 | 100.00 | 99.75 | 100.00 | 103.00
2023-10-03 | 99.75 | 102.50 | 101.25 | 100.00 | 103.00
2023-10-04 | 101.25 | 99.75 | 104.00 | 100.00 | 103.00
2023-10-05 | 104.00 | 101.25 | 105.50 | 100.00 | 103.00
2023-10-06 | 105.50 | 104.00 | 103.00 | 100.00 | 103.00
2023-10-07 | 103.00 | 105.50 | NULL | 100.00 | 103.00
请注意,LAST_VALUE() 默认不会按预期工作,因为它返回的是窗口内的最后一行,而不是整个结果集的最后一行。为了确保 LAST_VALUE() 返回整个结果集的最后一行,我们使用了 ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING,这样它就会考虑整个分区(在这种情况下,整个结果集就是一个分区)。
在这个例子中,prev_day_price 列显示了前一天的价格(使用 LAG 函数),next_day_price 列显示了后一天的价格(使用 LEAD 函数),first_day_price 列显示了整个记录期间的首日价格(使用 FIRST_VALUE 函数),而 last_day_price 列显示了整个记录期间的末日价格(使用 LAST_VALUE 函数,并确保了正确的窗口范围)。
请注意,根据您的数据库系统,LAST_VALUE() 的行为可能有所不同,特别是在处理默认窗口时。上面的查询在某些数据库系统中可能需要调整,以确保 LAST_VALUE() 正确地返回整个结果集的最后一行。在某些情况下,您可能需要使用子查询或其他技术来实现这一点。
5. 聚合窗口函数
聚合函数作为窗口函数:SUM(), AVG(), MIN(), MAX() 等也可以作为窗口函数使用,为每一行计算累计、移动或其他聚合值
假设我们有一个名为 sales_data 的表,该表记录了不同销售人员的每日销售额。表结构如下:
CREATE TABLE sales_data (
sales_date DATE,
salesperson_id INT,
sales_amount DECIMAL(10, 2)
);
INSERT INTO sales_data (sales_date, salesperson_id, sales_amount) VALUES
('2023-10-01', 1, 1000),
('2023-10-01', 2, 1500),
('2023-10-02', 1, 1200),
('2023-10-02', 2, 1300),
('2023-10-03', 1, 900),
('2023-10-03', 2, 1400),
('2023-10-04', 1, 1100),
('2023-10-04', 2, 1600);
现在,我们想要查询每位销售人员在每天的销售额,以及该销售人员到目前为止(从月初到当前日期)的平均销售额、最大销售额、总销售额和最小销售额。以下是查询的示例:
SELECT
sales_date,
salesperson_id,
sales_amount,
AVG(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS avg_sales,
MAX(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS max_sales,
SUM(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS total_sales,
MIN(sales_amount) OVER (PARTITION BY salesperson_id ORDER BY sales_date ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS min_sales
FROM
sales_data
ORDER BY
salesperson_id,
sales_date;
-- 查询的结果可能如下:
sales_date | salesperson_id | sales_amount | avg_sales | max_sales | total_sales | min_sales
------------+----------------+--------------+-----------+-----------+-------------+-----------
2023-10-01 | 1 | 1000.00 | 1000.00 | 1000.00 | 1000.00 | 1000.00
2023-10-02 | 1 | 1200.00 | 1100.00 | 1200.00 | 2200.00 | 1000.00
2023-10-03 | 1 | 900.00 | 1033.33 | 1200.00 | 3100.00 | 900.00
2023-10-04 | 1 | 1100.00 | 1050.00 | 1200.00 | 4200.00 | 900.00
2023-10-01 | 2 | 1500.00 | 1500.00 | 1500.00 | 1500.00 | 1500.00
2023-10-02 | 2 | 1300.00 | 1400.00 | 1500.00 | 2800.00 | 1300.00
2023-10-03 | 2 | 1400.00 | 1400.00 | 1500.00 | 4200.00 | 1300.00
2023-10-04 | 2 | 1600.00 | 1450.00 | 1600.00 | 5800.00 | 1300.00
在这个查询中:
sales_date, salesperson_id, 和 sales_amount 列直接来自 sales_data 表。
avg_sales 列计算了从月初到当前日期每位销售人员的平均销售额。
max_sales 列计算了从月初到当前日期每位销售人员的最大销售额。
total_sales 列计算了从月初到当前日期每位销售人员的总销售额。
min_sales 列计算了从月初到当前日期每位销售人员的最小销售额。
ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW 确保了窗口从当前分区的第一行开始,到当前行为止。在这种情况下,分区是由 PARTITION BY salesperson_id 定义的,每个销售人员的数据构成一个分区。ORDER BY sales_date 确保了数据按照销售日期排序,这对于计算累计的统计数据是必要的。
6. 其他函数:
这个类别包括一些不属于上述类别的窗口函数,但仍然在窗口计算的上下文中非常有用。
NTH_VALUE(expr, n): 返回窗口内第n行的值。
NTILE(n): 将结果集分成指定数量的近似相等的组,并为每一行分配一个组号。
假设我们有一个销售数据表sales_data,其中包含每个销售人员的销售额和销售日期。
表结构如下:
CREATE TABLE sales_data (
sales_id INT PRIMARY KEY,
salesperson_id INT,
sale_date DATE,
amount DECIMAL(10, 2)
);
-- 插入一些示例数据
INSERT INTO sales_data (sales_id, salesperson_id, sale_date, amount) VALUES
(1, 1, '2023-01-01', 1000.00),
(2, 2, '2023-01-01', 1500.00),
(3, 1, '2023-01-02', 700.00),
(4, 3, '2023-01-02', 900.00),
(5, 2, '2023-01-03', 1100.00),
(6, 1, '2023-01-03', 1200.00),
(7, 3, '2023-01-03', 1300.00);
现在,我们想要完成以下两个任务:
- 对于每天的销售数据,找出当天销售额排在第二位的销售人员及其销售额。
- 将每天的销售数据按照销售额分成两个等级,以便进行销售性能分析。
我们可以使用窗口函数来完成这些任务。首先,我们来完成第一个任务:
SELECT
sale_date,
salesperson_id,
amount AS second_highest_sale
FROM (
SELECT
sale_date,
salesperson_id,
amount,
NTH_VALUE(salesperson_id, 2) OVER (PARTITION BY sale_date ORDER BY amount DESC) AS second_salesperson_id,
NTH_VALUE(amount, 2) OVER (PARTITION BY sale_date ORDER BY amount DESC) AS second_highest_amount
FROM
sales_data
) AS subquery
WHERE
salesperson_id = second_salesperson_id
ORDER BY
sale_date;
-- 结果可能如下:
sale_date | salesperson_id | second_highest_sale
--------------+----------------+---------------------
'2023-01-01' | 2 | 1500.00
'2023-01-02' | 1 | 700.00
'2023-01-03' | 1 | 1200.00
注意:上述查询有个问题,NTH_VALUE可能不会返回预期的结果,因为它并不保证只返回一行。当存在并列的销售额时,NTH_VALUE可能会返回多个销售人员的ID。为了解决这个问题,我们可能需要使用ROW_NUMBER()或DENSE_RANK()。但是,为了简化,我们假设没有并列的销售额,并稍微调整查询。
一个更准确的查询可能是这样的:
WITH RankedSales AS (
SELECT
sale_date,
salesperson_id,
amount,
ROW_NUMBER() OVER (PARTITION BY sale_date ORDER BY amount DESC) AS rn
FROM
sales_data
)
SELECT
sale_date,
salesperson_id,
amount AS second_highest_sale
FROM
RankedSales
WHERE
rn = 2
ORDER BY
sale_date;
现在,让我们来完成第二个任务:
SELECT
sale_date,
salesperson_id,
amount,
NTILE(2) OVER (PARTITION BY sale_date ORDER BY amount DESC) AS sale_performance_group
FROM
sales_data
ORDER BY
sale_date,
sale_performance_group DESC,
amount DESC;
sale_date | salesperson_id | amount | sale_performance_group
--------------+----------------+-----------+----------------------
'2023-01-01' | 2 | 1500.00 | 1
'2023-01-01' | 1 | 1000.00 | 2
'2023-01-02' | 3 | 900.00 | 1
'2023-01-02' | 1 | 700.00 | 2
'2023-01-03' | 3 | 1300.00 | 1
'2023-01-03' | 1 | 1200.00 | 2
'2023-01-03' | 2 | 1100.00 | 2
这个查询将每天的销售数据按照销售额降序排列,并使用NTILE(2)将它们分成两组。销售额较高的销售人员将被分配到第一组(sale_performance_group = 1),而销售额较低的销售人员将被分配到第二组(sale_performance_group = 2)。在每个日期内,销售额是独立分组的。
三、常见的应用场景
窗口函数在多个场景中非常有用,以下是几个典型示例:
- 计算累计总和:使用SUM()函数和OVER()子句,可以轻松计算每一行的累计总和,这在分析销售数据、财务报表等方面非常有用。
- 计算排名:ROW_NUMBER()、RANK()和DENSE_RANK()等函数可以根据特定列的值对结果集进行排名。这在体育赛事、学生成绩排名等场景中非常常见。
- 计算移动平均值:通过指定窗口范围,可以计算移动平均值,这对于分析时间序列数据、股票价格等非常有帮助。
- 计算差异和百分比变化:使用LAG()和LEAD()函数,可以计算当前行与前一行或后一行的差异和百分比变化。
四、优化策略
虽然窗口函数功能强大,但在处理大量数据时,性能可能会成为问题。以下是一些优化策略:
- 减少数据量:在应用窗口函数之前,通过适当的筛选条件减少数据量。这可以通过WHERE子句或子查询实现。
- 选择适当的窗口大小:过大的窗口会增加计算开销,而过小的窗口可能无法提供所需的分析深度。根据具体需求选择合适的窗口大小。
- 使用索引:确保查询中涉及的列已正确索引,这有助于加速数据访问和计算过程。
- 避免嵌套窗口函数:嵌套窗口函数可能导致查询变得复杂并降低性能。如果可能,尝试将嵌套窗口函数拆分为多个独立的查询步骤。
- 查询优化器提示:在某些情况下,可以使用查询优化器提示来指导MySQL如何执行查询。但请谨慎使用,因为不当的提示可能导致性能下降。
四、总结
MySQL窗口函数为数据分析和报表生成提供了强大的工具。通过深入理解其原理和应用场景,并采用有效的优化策略,可以充分发挥窗口函数在数据处理和分析中的优势。随着数据量的不断增长和分析需求的日益复杂,掌握窗口函数将成为数据库开发人员和数据分析师的重要技能之一。