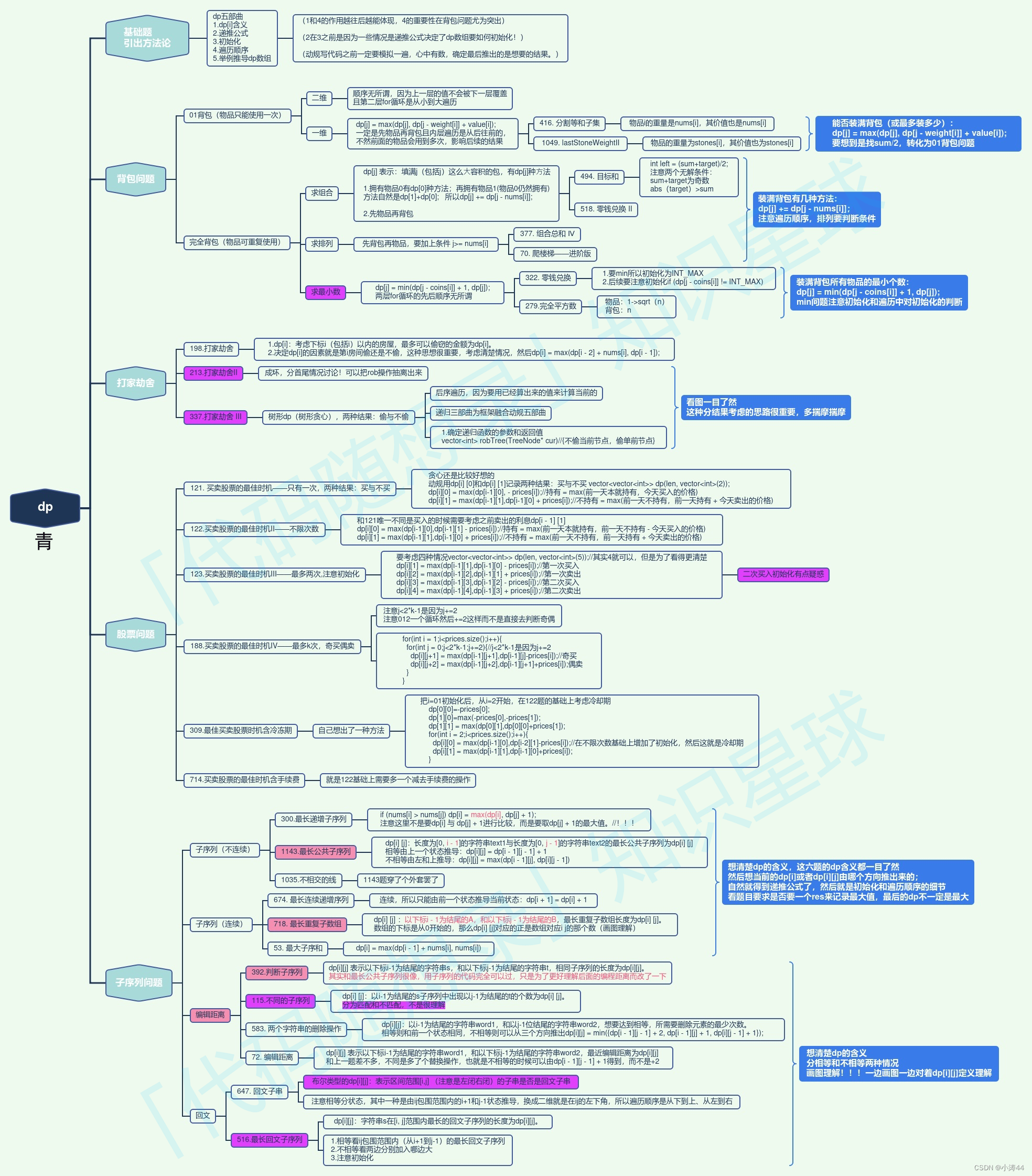
文章目录
- 1. 输入与输出
- 2. Self-attention
- 2.1 介绍
- 2.2 运作过程
- 2.3 矩阵相乘理解运作过程
- 3. 位置编码
- 4. Truncated Self-attention
- 4.1 概述
- 4.2 和CNN对比
- 4.3 和RNN对比
1. 输入与输出
1. 一般情况下在简单模型中我们输入一个向量,输出结果可能是一个数值或者一个类别。但是在复杂的模型中我们一般会输入一组向量,那么输出结果可能是一组数值或一组类别。

2. 一句话、一段语音、一张图等都可以转换成一组向量。



3. 输入一组向量,一般输出结果有3种情况:(1) N对N;(2) N对1;(3) N对M。我们这里着重讲第1种。
注:Seq2Seq(Sequence to Sequence,序列到序列模型)是循环神经网络模型的变种,包括编码器(Encoder)和解码器(Decoder)两部分。Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。

2. Self-attention
2.1 介绍
1. 有时候我们输入转化后的一组向量之间会有关联。比如 “I saw a saw-----我看见一把锯子” 这句话,对于传统的模型,可能会将第一个 saw 和第二个 saw 输出相同的结果,但事实上两个 saw 是完全不一样的意义,第一个 saw 意思是"看见",而第二个 saw 意思是"锯子"。
2. 所以出现了自注意力机制(Self-attention)模型来解决上述这个问题。对于输入 Seg 中向量不确定多的情况,Self-attention会考虑所有向量。Self-attention的输入是一组向量,输出也是一组向量,但考虑了整个 Seq 产生的。

3. 当然,Self-attention也可以使用多次。注:其实Self-attention是Transformer模型中的关键组件。

2.2 运作过程
1. Self-attention对于每一个的输出结果都是综合考虑了所有的输入。我们接下来以输入 a 1 a^1 a1 输出 b 1 b^1 b1 为例来讲解,其他的过程类似。

2. 步骤(1):对于输入向量
a
1
a^1
a1,Self-attention首先会判断向量
a
1
a^1
a1 与其他向量的关联性。对两个向量的关联程度,Self-attention会给出一个数值
α
α
α。
求关联性
α
α
α 的方法很多。比如点积法:将两个向量分别乘以权重矩阵,再进行点积;点积和相加法:将两个向量分别乘以权重矩阵,结果进行相加后再与权重矩阵进行点积。注:我们常用下面图片中左边的方法。


3. 步骤(2):计算出每个的关联性 α α α,再用 s o f t m a x softmax softmax 函数得到 α ′ α' α′。 注:这里不一定用 s o f t m a x softmax softmax 函数,也可以用其他的激活函数。


4. 步骤(3):然后再将所有向量 v ∗ α v * α v∗α,再求和得到 b b b。

5. 类似的,得到 b 2 b^2 b2 也是一样的过程。

2.3 矩阵相乘理解运作过程


3. 位置编码
1. 在人类的语言中,单词的位置与顺序定义了语法,也影响着语义。无法捕获的单词顺序会导致我们很难理解一句话的含义,如下图所示。


2. 我们知道自注意力机制是Transformer模型中的关键组件,但是Transformer中的自注意力机制无法捕捉输入元素序列的顺序。因此我们需要一种方法将单词的顺序合并到Transformer架构中,于是位置编码应运而生。
3. 目前,主流的位置编码方法主要分为绝对位置编码与相对位置编码两大类。其中绝对位置编码的作用方式是告知Transformer架构每个元素在输入序列中的位置,类似于为输入序列的每个元素打一个 “位置标签” 标明其绝对位置。而相对位置编码则是作用于自注意力机制,告知Transformer架构两两元素之间的距离。如下图所示。

4. 由于相对位置编码作用于自注意力机制,所以我们这里介绍一下相对位置编码。相对位置编码中,一般我们会在一组输入向量中的每个位置加一个位置向量 e e e,然后把 e e e 加到 a a a 上。

4. Truncated Self-attention
4.1 概述
1. Truncated Self-attention(缩减的自注意力机制)只看自己和前后一个向量之间的attention。
计算方法:只计算矩阵中蓝色部分值,其余灰色的不用计算(填0)。
问题:相当于只关联sequence中相邻的token,失去了Attention的全局性,和CNN的效果就比较相似了,只有局部感受野。

2. 例如对于长序列的语音问题,转换成输入向量后数量很大,这个时候我们可以只取一小段范围。 因为有时候关注一小段范围就可以得到我们想要的输出结果。

4.2 和CNN对比
自注意力机制和CNN在处理图像问题时,有一些显著的区别。
CNN,即卷积神经网络,可以看作是简化版的自注意力机制。在CNN中,每个神经元只考虑一个感受野里的信息,而感受野的大小和范围是人工设定的。然而,自注意力机制考虑整张图片的信息,相当于每个神经元自动学习如何确定其感受野。在自注意力机制中,感受野是通过注意力机制算法自动学出来的。
具体来说,自注意力机制中,模型会用attention机制去找出相关的像素;而在CNN中,每个神经元只考虑一个固定感受野里的像素。此外,在处理大量数据时,自注意力机制表现得更好,而在训练数据较少时,CNN表现得更好。
总的来说,自注意力机制和CNN在处理图像问题时各有优势。自注意力机制能够更好地处理大量数据,而CNN在处理少量数据时表现较好。在实际应用中,需要根据具体任务和数据量来选择使用哪种模型。



4.3 和RNN对比
自注意力机制和RNN(循环神经网络)在自然语言处理和其他序列处理任务中都有广泛应用,但它们之间存在一些关键区别。
(1) 上下文处理:RNN在处理序列时,通常按照顺序逐个处理输入元素,因此其对于上下文的处理主要依赖于之前的隐藏状态。这意味着RNN在处理当前元素时,只能考虑到该元素之前的上下文信息。相比之下,自注意力机制能够同时处理整个序列,直接关联并考虑所有的上下文信息,而不仅仅局限于当前元素之前的部分。
(2) 并行计算:由于RNN的顺序处理特性,其计算通常是顺序进行的,这限制了其并行计算的能力。而自注意力机制的计算可以并行进行,因为所有的输入元素都是同时处理的,这有助于提高计算效率。
(3) 输入顺序:RNN对输入序列的顺序是敏感的,因为顺序的改变会影响隐藏状态的计算。而自注意力机制本身对输入序列的顺序是不敏感的,因为其在计算注意力权重时并不考虑元素的位置信息。然而,为了在需要的情况下捕捉序列的顺序信息,可以在自注意力机制中引入位置编码。
(4) 长期依赖问题:RNN在处理长序列时,可能会遇到梯度消失或梯度爆炸的问题,这使得网络难以学习到长期依赖关系。虽然一些改进的RNN变体(如LSTM和GRU)能够在一定程度上缓解这个问题,但自注意力机制由于其全局上下文处理的能力,通常能够更好地处理长期依赖关系。
总的来说,自注意力机制和RNN在序列处理任务中各有优势。自注意力机制能够更好地处理全局上下文和长期依赖关系,并具有并行计算的优势;而RNN则更适合处理具有明确顺序关系的序列数据。在实际应用中,可以根据具体任务的需求选择合适的模型或结合两者以充分利用其优势。










![[设计模式Java实现附plantuml源码~创建型] 对象的克隆~原型模式](https://img-blog.csdnimg.cn/direct/2473c30ed78045959184631275c0a1bb.png)
