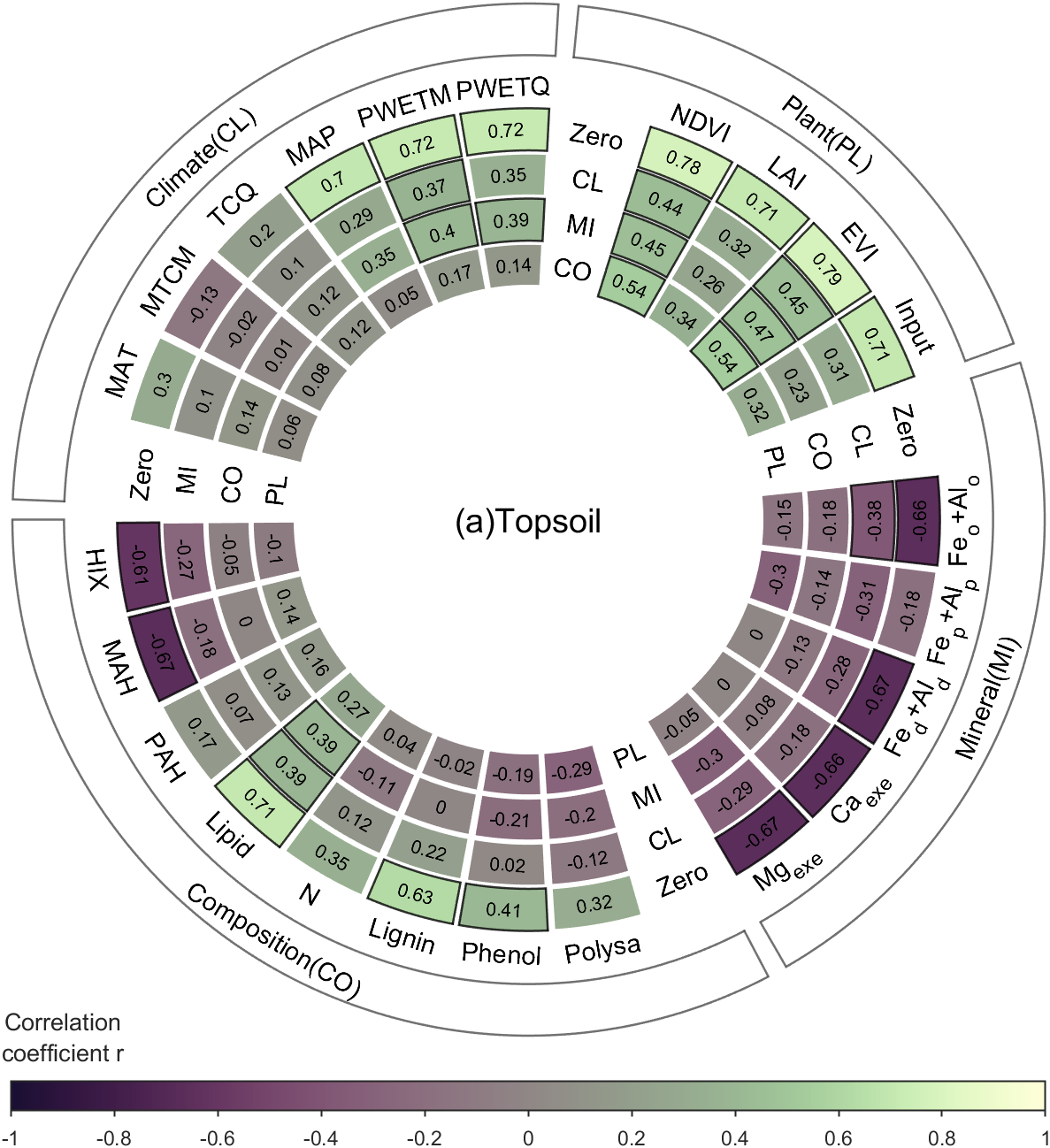
深度学习推理框架
- 1.移动端深度学习推理框架调研
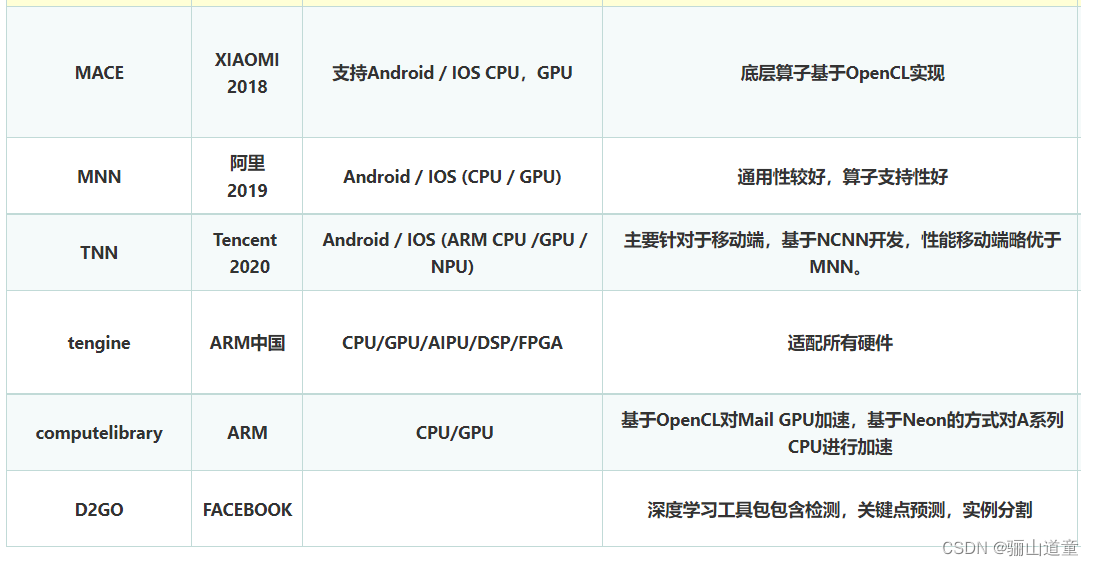
- 1.1 小米的MACE(2017)
- 1.2 阿里的MNN
- 1.3 腾讯的TNN
- 1.4 ARM的tengine
- 1.5 百度的paddle-mobie
- 1.6 Facebook的Caffe2(*)
- 1.7 Google的TensorFlow Lite (*)
- 1.8 Apple的Core ML(*)
- 1.9 OpenVINO(Intel,cpu首选OpenVINO)
- 1.10 TensorRT(Nvidia)
- 1.11 Mediapipe(Google)---处理视频、音频等
- 2. 重点对SNPE的介绍(高通芯片*)
1.移动端深度学习推理框架调研
相关平台的介绍的链接
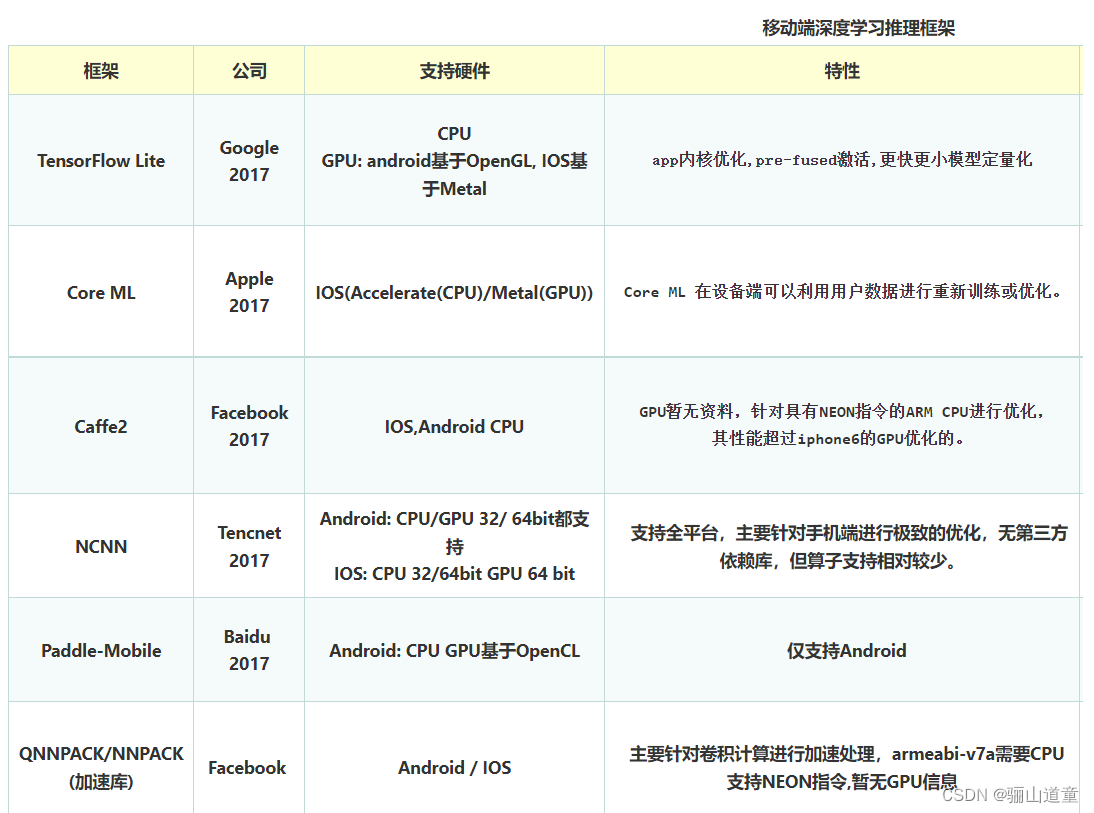
1.1 小米的MACE(2017)
比较:TensorFlow/Caffe
MACE最大的优势是对GPU和DSP等异构计算的支持,劣势则是知名度和生态有不小的差距。

小米AI推理框架MACE介绍
官方手册:https://buildmedia.readthedocs.org/media/pdf/mace/latest/mace.pdf
开源github地址:https://github.com/XiaoMi/mace.git
mace模型库地址:https://github.com/XiaoMi/mace-models.git
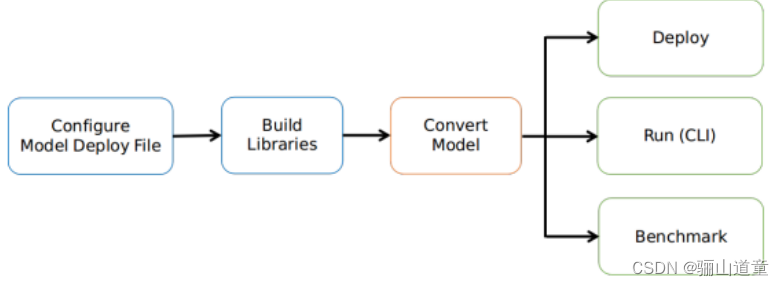
MACE 自定义了一种类似 Caffe2 的模型格式。Tensorflow 和 Caffe 训练得到的模型可以转换成 MACE 模型进行部署。MACE 采用 YAML 文件描述模型的部署细节。
小米则采用了半精度浮点和8比特整形量化的方法来进行压缩。
1.2 阿里的MNN

开源github地址:https://github.com/alibaba/MNN
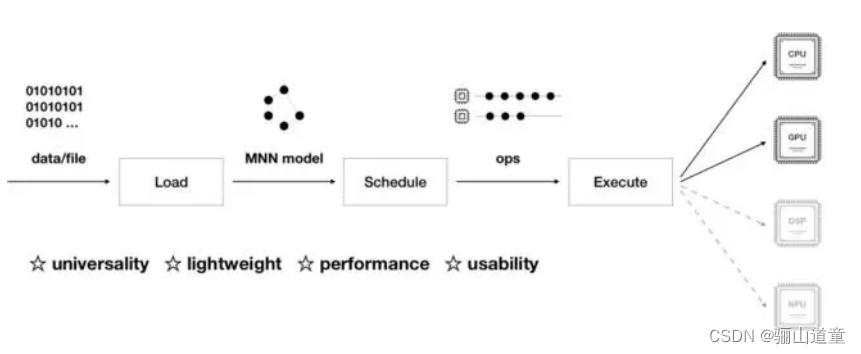 支持 Tensorflow、Caffe、ONNX 等主流模型格式,支持 CNN、RNN、GAN 等常用网络;
支持 Tensorflow、Caffe、ONNX 等主流模型格式,支持 CNN、RNN、GAN 等常用网络;
支持 86 个 TensorflowOp、34 个 CaffeOp ;各计算设备支持的 MNN Op 数:CPU 71 个,Metal 55 个,OpenCL 40 个,Vulkan 35 个,Android 上提供了 OpenCL、Vulkan、OpenGL 三套方案,尽可能多地满足设备需求,针对主流 GPU(Adreno和Mali)做了深度调优。
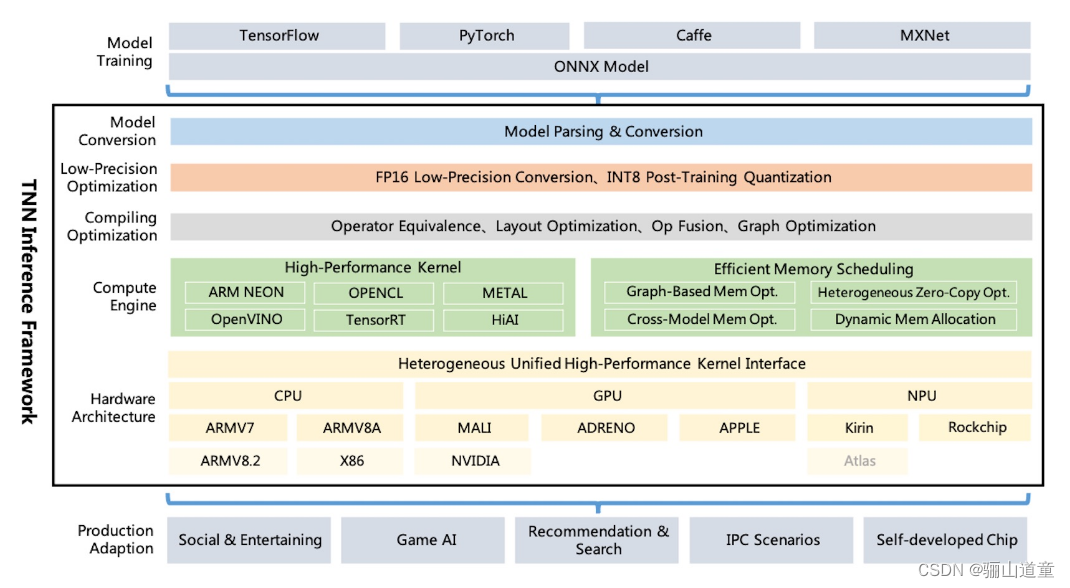
1.3 腾讯的TNN

开源github地址:https://github.com/Tencent/TNN
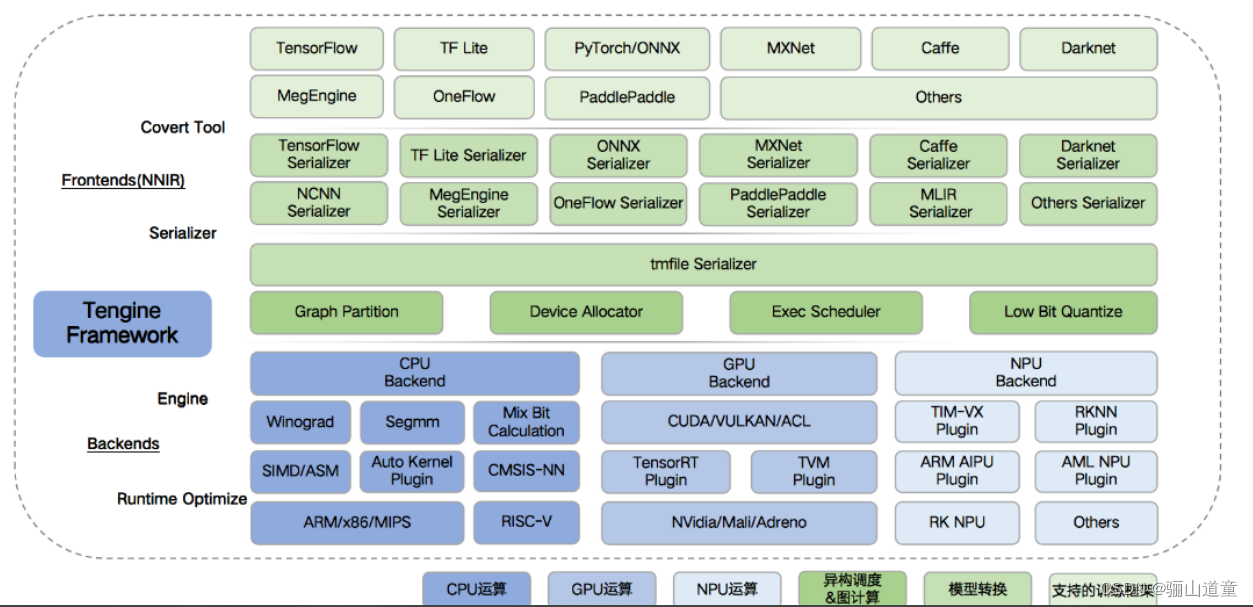
1.4 ARM的tengine
它支持TensorFlow、Caffe、MXNet 、PyTorch、 MegEngine、 DarkNet、ONNX、 ncnn 等业内主流框架。
开源github地址:https://github.com/OAID/Tengine
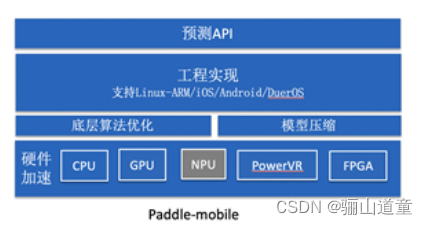
1.5 百度的paddle-mobie
例程:在Android手机上使用PaddleMobile实现图像分类
开源github地址: https://github.com/PaddlePaddle/paddle-mobile
1.6 Facebook的Caffe2(*)
PyTorch在研究、实验和尝试新的神经网络方面做得很好;
caffe2正朝着支持更多工业强度的应用程序的方向发展,重点是移动应用程序。
pytorch转化到caffe2:
先将pytorch转化为caffe,然后再将caffe转化为caffe2:https://caffe2.ai/docs/caffe-migration.html
将caffe的model转化为caffe2model: https://caffe2.ai/docs/caffe-migration.html

1.7 Google的TensorFlow Lite (*)
TensorFlow Lite 指南csdn
TensorFlow Lite官网链接:https://tensorflow.google.cn/lite/guide
中文版部署教程
- TensorFlow Lite 是一组工具,可帮助开发者在移动设备、嵌入式设备和 IoT 设备上运行 TensorFlow 模型。它支持设备端机器学习推断,延迟较低,并且二进制文件很小。
- Android 和 Ios
- 大多数 TensorFlow Lite 运算都针对的是浮点(float32)和量化(uint8、int8)推断,但许多算子尚不适用于其他类型(如 tf.float16 和字符串)。
1.8 Apple的Core ML(*)
一切可在用户设备端完成
1.9 OpenVINO(Intel,cpu首选OpenVINO)
英特尔的cpu,
开源github地址: https://github.com/openvinotoolkit/openvino
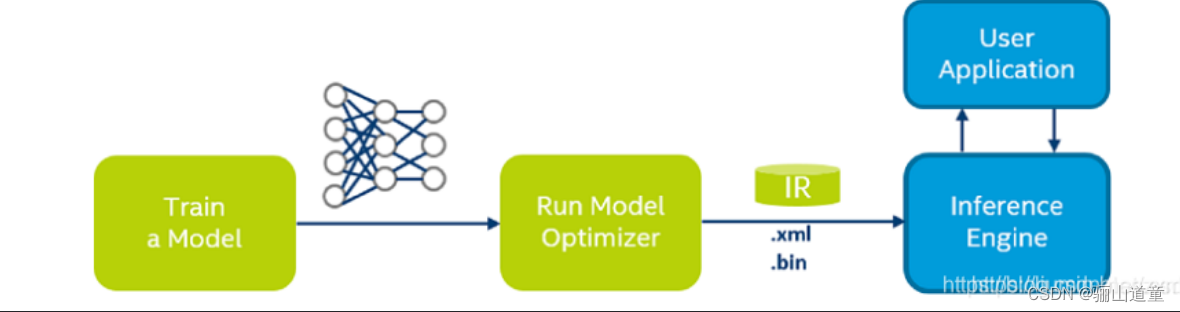
模型优化器(Model Optimizer)将给定的模型转化为标准的 Intermediate Representation (IR) ,并对模型优化。同时对传统的OpenCV图像处理库也进行了指令集优化,有显著的性能与速度提升。
ONNX
TensorFlow
Caffe
MXNet
Kaldi
1.10 TensorRT(Nvidia)
只能用在NIVDIA的GPU上的推理框架。NIVDIA自家的Jetson平台。
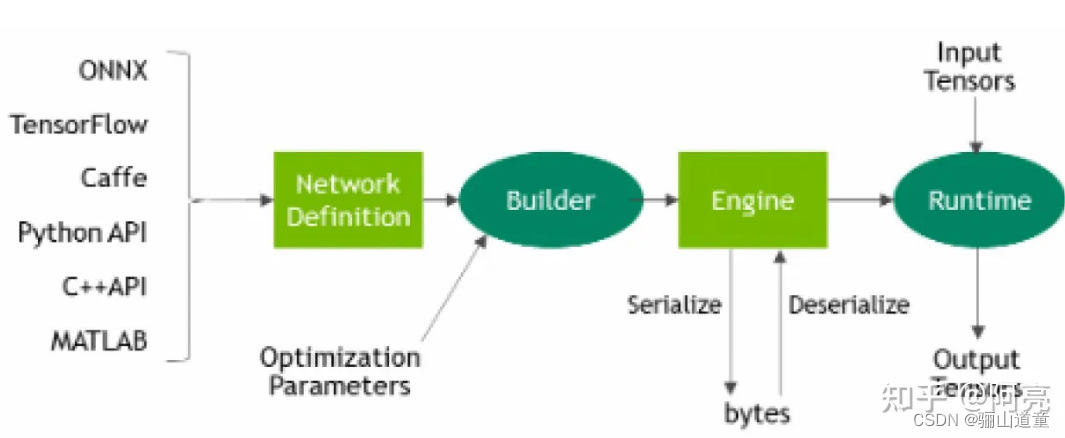
在保证准确率的情况下,通过将模型量化到INT8来更大限度地提高吞吐量,TensorRT包含两个阶段:编译build和部署deploy,
- 编译阶段对网络配置进行优化,并生成一个plan文件,用于通过深度神经网络计算前向传递。plan文件是一个优化的目标代码,可以序列化并且可存储在内存和硬盘中。
- TensorRT为所有支持平台提供了C++实现,以及在x86、aarch64和ppc64le平台上提供Python支持
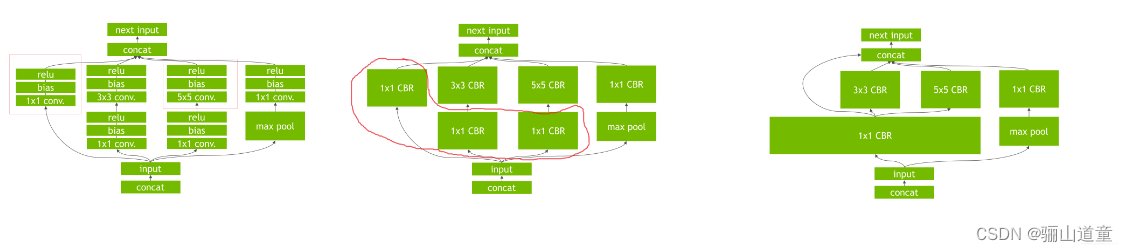
编译阶段在图层中执行如下优化:
消除输出未被使用的层
消除等价于no-op的运算
卷积层,偏差和ReLu操作的融合
聚合具有足够相似参数和相同目标张量的操作(例如,Googlenet v5 inception 模型的1*1卷积)
通过直接将层输出定向到正确最终目的来合并concatenation 层
- 部署阶段通常采用长时间运行的服务或者用户应用程序的形式。它们接收批量输入数据,通过执行plan文件在输入数据上进行推理,并且返回批量的输出数据(分类、目标检测等)
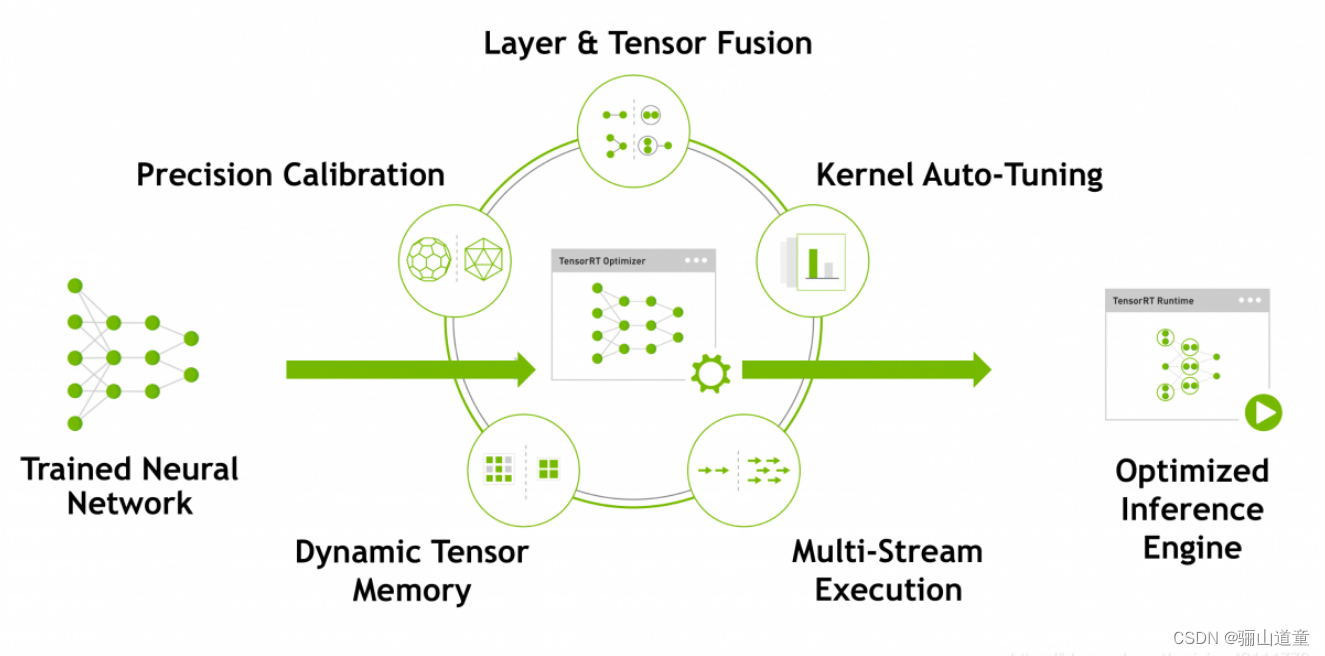
使用TensorRT的流程:
将一个训练好的模型部署到TensorRT上的流程为:
1.从模型创建一个TensorRT网络定义
2.调用TensorRT生成器从网络创建一个优化的运行引擎
3.序列化和反序列化,以便于运行时快速重新创建
4.向引擎提供数据以执行推断
# 导入TensorRT
import tensorrt as trt
# 日志接口,TensorRT通过该接口报告错误、警告和信息性消息
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
- 创建TensorRT builder 和 network
为特定的格式创建TensorRT 解析器
使用解析器解析导入的模型并填充模型
import tensorrt as trt
# 以CaffeParse为例
datatype = trt.float32 # 定义数据类型
# 定义配置文件和参数模型路径
deploy_file = 'data/mnist/mnist.prototxt'
model_file = 'data/mnist/mnist.caffemodel'
# 创建builder, network 和 parser
with trt.Builder(TRT_LOGGER) as builder, builder.create_network() as network, trt.CaffeParser() as parser:
model_tensors = parser.parse(deploy=deploy_file, model=model_file, network=network, dtype=datatype)
3.序列化和反序列化
序列化,意味着将engine转化为一种可以存储的格式并且在以后可以进行推理。用于推理使用时,只需要简单地反序列化engine
# 序列化模型到modelstream
serialized_engine = engine.serialize()
# 反序列化modelstream用于推理。反序列化需要创建runtime对象。
with trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(serialized_engine)
# 序列化engine并且写入一个file中
with open(“sample.engine”, “wb”) as f:
f.write(engine.serialize())
# 从文件中读取engine并且反序列化
with open(“sample.engine”, “rb”) as f, trt.Runtime(TRT_LOGGER) as runtime:
engine = runtime.deserialize_cuda_engine(f.read())
4.执行,分配内存,创建流,上下文,激活值,返回主机输出。
# engine有一个输入binding_index=0和一个输出binding_index=1
h_input = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(0)), dtype=np.float32)
h_output = cuda.pagelocked_empty(trt.volume(context.get_binding_shape(1)), dtype=np.float32)
# 为输入和输出分配内存
d_input = cuda.mem_alloc(h_input.nbytes)
d_output = cuda.mem_alloc(h_output.nbytes)
# 创建一个流在其中复制输入/输出并且运行推理
stream = cuda.Stream()
#创建一些空间来存储中间激活值。由于引擎包含网络定义和训练参数,因此需要额外的空间。它们被保存在执行上下文中。
with engine.create_execution_context() as context:
# 将输入数据转换到GPU上
cuda.memcpy_htod_async(d_input, h_input, stream)
# 运行推理
context.execute_async_v2(bindings=[int(d_input), int(d_output)], stream_handle=stream.handle)
# 从GPU上传输预测值
cuda.memcpy_dtoh_async(h_output, d_output, stream)
# 同步流
stream.synchronize()
# 返回主机输出
return h_output
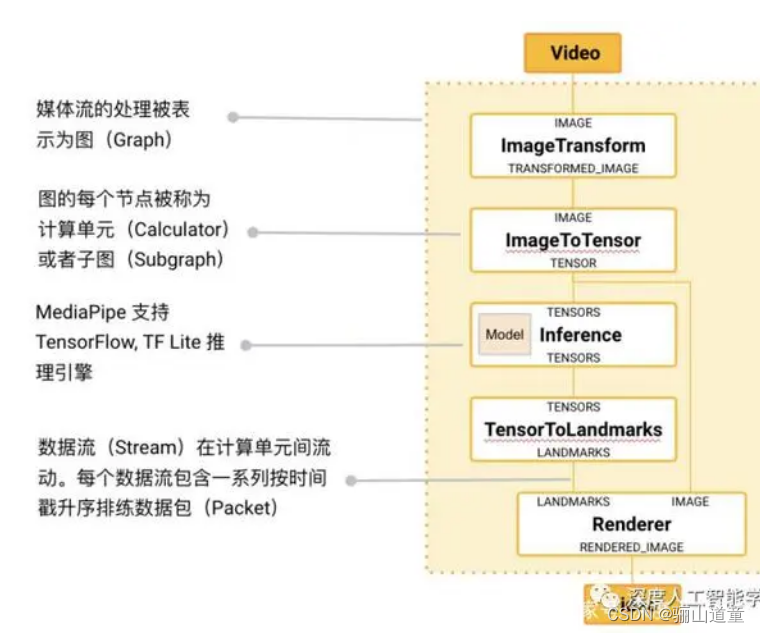
1.11 Mediapipe(Google)—处理视频、音频等
MediaPipe是个基于图形的跨平台框架,用于构建多模式应用的机器学习管道。MediaPipe可在移动设备,工作站和服务器上跨平台运行,并支持移动GPU加速,服务端,移动端,嵌入式平台。
Mediapipe github链接:https://github.com/google/mediapipe
2. 重点对SNPE的介绍(高通芯片*)
支持:TensorFlow, Caffe, Caffe2, ONNX, TensorFlow, PyTorch,转换成dlc文件
将训练好的模型用SNPE的工具转成DLC文件就可以在SNPE运行环境里跑了。装成DLC之后也可以用它自带的量化工具量化成8位整形。

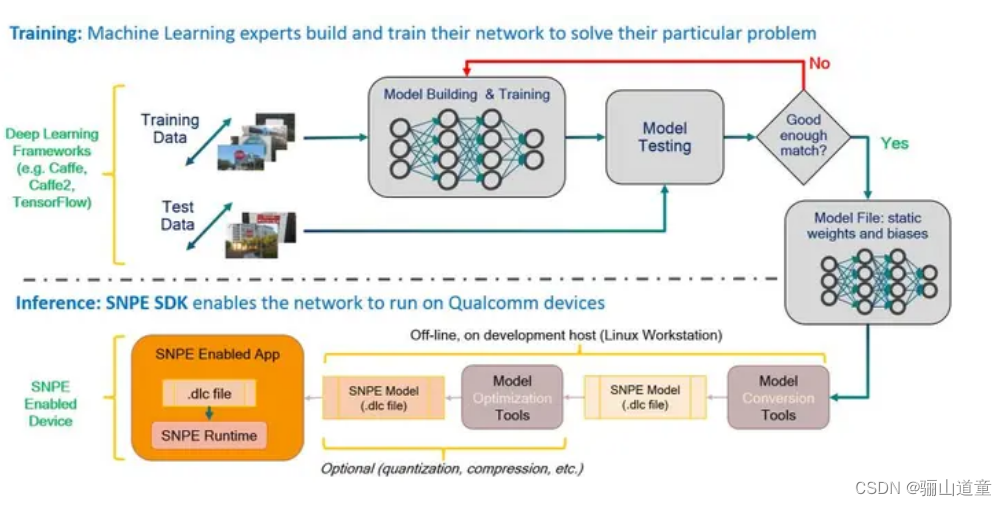
基本的SNPE工作流程只包含几个步骤:
1.将网络模型转换为可由SNPE加载的DLC文件。
2.可选择量化DLC文件以在Hexagon DSP上运行。
3.准备模型的输入数据。
4.使用SNPE运行时加载并执行模型。
上手SNPE-推理inception_v3
SNPE的安装 snpe-tensorflow-to-dlc 模型转化工具的使用 snpe-net-run
在Ubuntu环境下的inceptionv3模型是推理。 如何在商用手机上使用SNPE 加速模型推理。
(1)TensorFlow和SNPE的环境:snpe高通官网下载,unzip snpe-1.52.0.zip 解压
python3-dev’, ‘wget’, ‘zip’,‘libc+±9-dev’
(2)NDK,路径配置
SNPE_ROOT,TENSORFLOW_HOME,PATH, LD_LIBRARY_PATH, 和PYTHONPATH
(3)得到pb模型,将 pb模型转化为SNPE支持的DLC模型格式
root@3e28cb421090:/workspace/tutor/inceptionv3: snpe-tensorflow-to-dlc -i inception_v3.pb -d input 1,299,299,3 --out_node InceptionV3/Predictions/Reshape_1
(4)准备数据集和验证脚本
拷贝数据到\models\xxxx下面,在snpe环境下进行验证
snpe-net-run --version