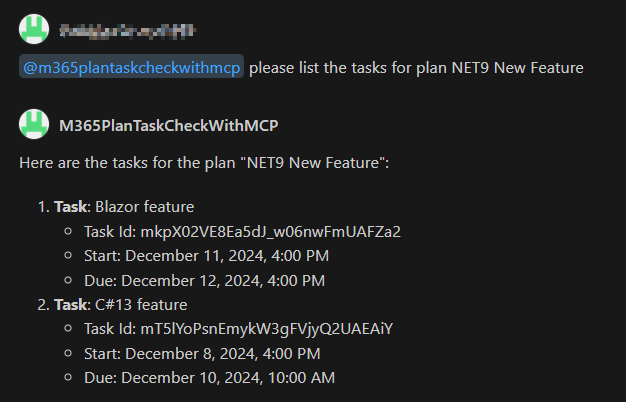
BEVFormer
- 一、文章基本信息
- 二、文章背景
- 三、BEVFormer架构
- (1) BEV 查询
- (2) 空间交叉注意力机制
- (3) 时间自注意力机制
- (4) BEV应用
- (5) 实施细节
- 四、实验
- 五、总结
一、文章基本信息
| 标题 | BEVFormer: Learning Bird’s-Eye-view Representation from Multi-camera images via spatiotemporal transformers |
|---|---|
| 会议 | ECCV (European Conference on Computer Vision) |
| 作者 | Zhiqi Li;Wenhai Wang;Hongyang Li;Enze Xie;Chonghao Sima;Tong Lu;Yu Qiao;Jifeng Dai |
| 主要单位 | Nanjing University;Shanghai AI Laboratory |
| 日期 | v1: 31 Mar 2022;v2: 13 July 2022 |
| 论文地址 | https://arxiv.org/abs/2203.17270 |
| 项目地址 | https://github.com/fundamentalvision/BEVFormer |
本会议论文扩展后被2025年TPAMI第三期收录,增加了点云数据模态,本文主要分享ECCV版本,对期刊版本感兴趣的朋友可以自行查看。

文章摘要:3D视觉感知任务,包括基于多摄像头图像的3D检测和地图分割,对于自动驾驶系统至关重要。在这项工作中,我们提出了一个名为BEVFormer的新框架,它通过时空Transformer学习统一的鸟瞰视图(BEV)表示,可以支持多种自动驾驶感知任务。简而言之,BEVFormer通过预定义的网格状BEV查询与空间和时间维度进行交互,从而利用空间和时间信息。为了聚合空间信息,我们设计了空间交叉注意力机制,使每个BEV查询能够从跨摄像头视图的感兴趣区域中提取空间特征。对于时间信息,我们提出了时间自注意力机制,以循环融合历史BEV信息。我们的方法在nuScenes测试集上,以NDS指标衡量达到了56.9% 的最新最优水平,比之前的最佳方法高出9.0个百分点,与基于激光雷达的基线性能相当。我们进一步表明,BEVFormer显著提高了在低能见度条件下速度估计的准确性(velocity estimation)和物体的召回率。代码可在 https://github.com/ zhiqi-li/BEVFormer获取。 |
二、文章背景
3D空间的感知任务对于自动驾驶、机器人而言是十分重要的应用。尽管基于激光雷达的方法取得了较大的进步,但基于相机的方法今年来也获得了较大的关注,因为其有如下几个优点:
- 部署成本低(low cost for deployment)
- 更远的检测距离(detect long-range distance objects)
- 可以识别视觉化的路侧单元(identify vision-based road elements)
自动驾驶的环境感知是希望能从多个相机给出的2D提示中,来预测3D检测框或语义地图。目前最直接的方法包括基于单目相机框架和多相机后处理的方法。该框架的下游是分别地处理不同视角,不能捕捉多个相机的信息,从而导致较低的精度和效率。
BEV视图为多相机图像提供了一个更好的融合空间,可以清晰地获取目标的位置和大小,适合自动驾驶的不同任务(感知与规划)。尽管地图语义分割已经证明了BEV的效率,但在3D目标检测中还没展现出具体的优势。最主要的原因在于:3D目标检测任务需要更多的BEV特征来实现检测框的预测,然而,从2D平面生成BEV特征是一个病态问题(ill-posed)。有名的基于深度信息生成BEV特征的框架十分受欢迎,但是,该范式对于深度值或深度分布是敏感的。因此,作者们有了第一个motivation: 不依赖于深度信息来生成BEV特征,而是直接学习BEV特征。Transformer利用注意力机制来动态融合有价值的特征,刚好满足需要。
另一个motivation是想要通过BEV特征来联合时间与空间。在人类感知系统中,时间信息扮演了一个重要的角色,可以帮助我们捕捉物体的运动和识别遮挡,然而很少有研究关注时间信息。重大挑战在于自动驾驶对时间要求极高,且场景中的物体变化迅速,因此简单地堆叠跨时间戳的鸟瞰图(BEV)特征会带来额外的计算成本和干扰信息,这可能并不理想。作者受RNN的启发:利用BEV特征从过去时刻循环发送时间信息到现在时刻,有点像RNN的隐藏状态。
出于这个考量,本文提出了一个基于注意力机制的BEV编码器,叫做BEVFormer,该模块能有效融合多视图相机和BEV历史特征的时空特征。从BEVFormer获取的BEV特征可以有效地应用于多个3D感知任务,例如:3D目标检测、地图划分;如下图所示,BEVFormer包括3个关键的设计:
- 通过灵活的注意力机制来融合空间和时间特征的网格形状BEV查询器 (grid-shaped BEV queries)
- 从多个相机的图片融合空间特征的空间交叉注意力模块(spatial cross-attention module)
- 从历史BEV特征中提取时间信息的时间自注意力模块(temporal self-attention)

这些设计有助于移动目标的速度估计和严重遮挡目标的检测,并且只会带来微不足道的计算增加。
三、BEVFormer架构
BEVFormer的整体架构如下图所示,相当于每个相机视角有一个encoder,每一个encoder包括一个grid-shaped BEV queries, temporal self-attention and spatial cross-attention
- 首先,通过时间自注意力机制来,使用BEV查询获取 B t − 1 B_{t-1} Bt−1
- 其次,通过空间交叉注意力机制,使用BEV查询来获取多相机视图的空间信息
- 最后,在经过一个前馈网络之后,编码器输出重新定义的BEV特征

(1) BEV 查询
预定义了一组网格状的可学习参数作为BEVFormer的查询 Q ∈ R H × W × C Q\in R^{H \times W\times C} Q∈RH×W×C,其中网格的形状是 H × W H \times W H×W。
- 具体来说,位于 Q Q Q中 p = ( x , y ) p = (x, y) p=(x,y) 处的查询 Q p ∈ R 1 × C Q_{p} \in \mathbb{R}^{1×C} Qp∈R1×C 负责BEV平面中对应的网格单元区域。 每个BEV平面的单元都和真实事件的尺寸对应。
- 默认下,BEV特征得中心对应自车的位置。
(2) 空间交叉注意力机制
因为之前普通的全局注意力,对于6个视角的图像而言计算负担太大了,所以作者采用了deformable attention的思想,但是该思想起源于2D感知,要应用于3D必须得做一些修改:
对于一个BEV查询,投影后的2D点只能落在某些视图上,而其他视图不会被投影:这些被投影到的视图被成为
V
h
i
t
V_{hit}
Vhit,将这些2D点视为查询
Q
p
Q_{p}
Qp的参考点,并从这些被投影到的
V
h
i
t
V_{hit}
Vhit视图中围绕这些参考点采样特征。最后,对采样特征进行加权求和。时空交叉注意力机制被列为下式:
S
C
A
(
Q
p
,
F
t
)
=
1
∣
V
h
i
t
∣
∑
i
∈
V
h
i
t
∑
j
=
1
N
r
e
f
D
e
f
o
r
m
A
t
t
n
(
Q
p
,
P
(
p
,
i
,
j
)
,
F
t
i
)
SCA(Q_{p},F_{t})=\frac{1}{|V_{hit}|}\sum_{i\in V_{hit}}\sum_{j=1}^{N_{ref}}DeformAttn(Q_{p}, P(p, i, j),F_{t}^i)
SCA(Qp,Ft)=∣Vhit∣1i∈Vhit∑j=1∑NrefDeformAttn(Qp,P(p,i,j),Fti)
- i i i 表示相机视图的索引
- j j j 表示参考点的索引
- N r e f N_{ref} Nref是每个BEV查询的总参考点数
- F t i F_{t}^i Fti 是第 i i i个相机视图的特征
- 对于每个BEV查询 Q p Q_{p} Qp,采用投影函数 P ( p , i , j ) P(p, i, j) P(p,i,j)来获取第 i i i 个视图图像上的第 j j j 个参考点
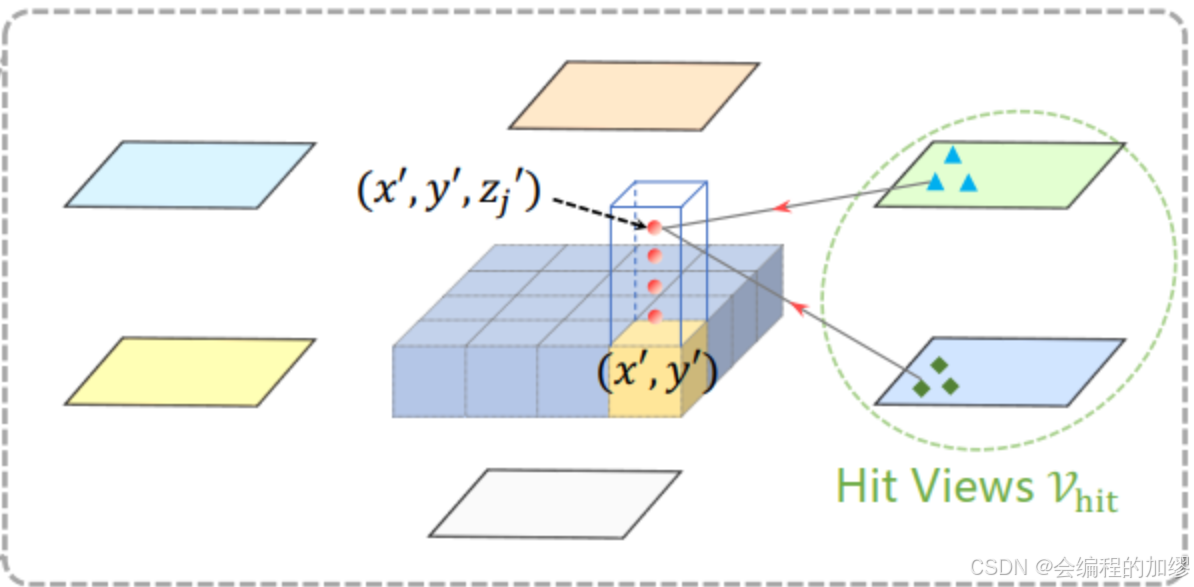
如何实现投影函数 P ( p , i , j ) P(p, i, j) P(p,i,j)呢?
-
计算 p = ( x , y ) p=(x, y) p=(x,y)点处的查询 Q p Q_{p} Qp相对应的真实世界位置 ( x ′ , y ′ ) (x', y') (x′,y′), 如图
x ′ = ( x − W 2 ) × s ; y ′ = ( y − H 2 ) × s x' = (x-\frac{W}{2})\times s; \ y'=(y-\frac{H}{2}) \times s x′=(x−2W)×s; y′=(y−2H)×s -
在3D空间中,位于 ( x ′ , y ′ ) (x', y') (x′,y′)上的目标会在z轴上具有一个 z ′ z' z′的高度,所以预定义一组锚点高度 { z j ’ } j = 1 N r e f \{{z_{j}’}\}_{j=1}^{N_{ref}} {zj’}j=1Nref来确保能获取不同高度的线索
-
通过这种方式,每一个查询 Q p Q_{p} Qp,我们可以获得一个3D参考点柱体 ( x ′ , y ′ , z j ′ ) j = 1 N r e f (x',y',z_{j}')_{j=1}^{N_{ref}} (x′,y′,zj′)j=1Nref
-
最后,通过相机的投影矩阵,来获得不同视图的参考点 ( x ′ , y ′ , z j ′ ) (x', y',z'_{j}) (x′,y′,zj′)
(3) 时间自注意力机制
本文作者设计了一个时间自注意力模块(temporal self-attention),它是通过历史BEV特征表现出的当前环境。
给定当前时刻
t
t
t 的BEV查询
Q
Q
Q, 和
t
−
1
t-1
t−1 时刻保留的历史BEV特征
B
t
−
1
B_{t-1}
Bt−1 :
- 根据自车的运动来对齐 t − 1 t-1 t−1时刻的BEV特征与 Q Q Q查询,使得特征在与相同真实世界位置关联的BEV网格中
- 因为真实世界中,不同时刻相同目标在BEV特征中可能有偏差,所以通过时间自注意力机制(temporal self-attention, TSA)来对这种时间关联进行建模
T S A ( Q p , { Q , B t − 1 ′ } ) = ∑ V ∈ { Q , B t − 1 ′ } D e f o r m A t t n ( Q p , p , V ) TSA(Q_{p}, \{Q, B_{t-1}'\})=\sum_{V\in\{Q,B_{t-1}'\}}DeformAttn(Q_{p},p,V) TSA(Qp,{Q,Bt−1′})=V∈{Q,Bt−1′}∑DeformAttn(Qp,p,V)
- Q p Q_{p} Qp表示在 p = ( x , y ) p=(x, y) p=(x,y)点处的BEV查询
不同于普通的deformable attention,时间自注意力机制中的偏差 Δ p \Delta p Δp,通过一连串的 Q Q Q和 B t − 1 ′ B_{t-1}' Bt−1′来预测。特别地,每一个序列的第一个样本,自动退化为没有时间信息的自注意力机制,通过重复的BEV查询 { Q , Q } \{Q,Q\} {Q,Q}来取代 { Q , B t − 1 ′ } \{Q, B_{t-1}'\} {Q,Bt−1′}。
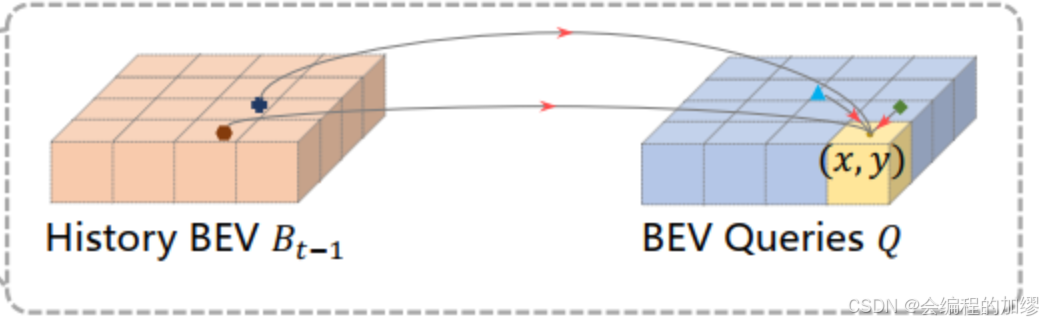
与简单堆叠的BEV模型相比,我们的时空自注意力机制能更加有效地建模长时间依赖
(4) BEV应用
BEV特征 B t ∈ R H × W × C B_{t} \in R^{H\times W\times C} Bt∈RH×W×C是一个多功能的2D特征图(versatile 2D feature map),可以被用于不同的自动驾驶感知任务。
- 3D目标检测—>用的2D detector Deformable DETR
- 地图分割 —>用的2D segmentation method Panoptic SegFormer
(5) 实施细节
训练阶段
对于时间戳 t t t的每个样本,我们从过去2秒的连续序列中随机抽取另外3个样本,(这三个随机选择的样本并不是连续的,因为2秒内不止3张图片)这种随机采样策略可以增加自车运动的多样性[57]。我们将这四个样本的时间戳分别记为 t − 3 t - 3 t−3、 t − 2 t - 2 t−2、 t − 1 t - 1 t−1和 t t t。前三个时间戳的样本用于循环生成BEV特征 { B t − 3 , B t − 2 , B t − 1 } \{B_{t - 3}, B_{t - 2}, B_{t - 1}\} {Bt−3,Bt−2,Bt−1},此阶段不需要计算梯度。对于时间戳 t − 3 t - 3 t−3的第一个样本,由于没有之前的BEV特征,时间自注意力会退化为自注意力。在时间 t t t时,模型基于多摄像头输入和之前的BEV特征 B t − 1 B_{t - 1} Bt−1生成BEV特征 B t B_{t} Bt,这样 B t B_{t} Bt就包含了跨越这四个样本的时空线索。最后,我们将BEV特征 B t B_{t} Bt输入到检测头和分割头中,并计算相应的损失函数。
推理阶段
在推理阶段,我们按时间顺序评估视频序列的每一帧。前一个时间戳的BEV特征会被保存下来并用于下一次推理,这种在线推理策略高效且符合实际应用场景。尽管我们利用了时间信息,但我们的推理速度仍与其他方法相当。
四、实验
数据集
- nuScenes Dataset: 1000个持续20帧的训练场景
- Waymo Open Dataset: 798个训练序列、202个测试序列
实验设置
采用了两类主干网络:
- ResNet101-DCN (用了FCOS3D的权重文件来初始化)
- VoVnet-99 (用DD3D的权重文件来初始化)
用从不同尺寸的FPS来输出多尺度特征:
在nuScenes数据集上进行实验时,BEV查询的默认大小为200×200,X轴和Y轴的感知范围均为[-51.2米, 51.2米],BEV网格的分辨率 s s s为0.512米。我们对BEV查询采用可学习的位置嵌入。BEV编码器包含6个编码层,在每一层中不断细化BEV查询。每个编码层的输入BEV特征 B t − 1 B_{t - 1} Bt−1相同且不需要计算梯度。对于每个局部查询,在由可变形注意力机制实现的空间交叉注意力模块中,它对应于3D空间中4个具有不同高度的目标点,预定义的高度锚点是从-5米到3米均匀采样得到的。对于2D视图特征上的每个参考点,每个注意力头在该参考点周围使用四个采样点。默认情况下,我们使用24个epoch、学习率为 2 × 1 0 − 4 2×10^{-4} 2×10−4来训练模型。
在Waymo数据集上进行实验时,我们更改了一些设置。由于Waymo的摄像头系统无法捕捉到自车周围的完整场景,BEV查询的默认空间形状为300×220,X轴的感知范围是[35.0米, 75.0米],Y轴的感知范围是[75.0米, 75.0米]。每个网格的分辨率S为0.5米。在BEV视图中,自车的位置是(70, 150) 。
消融实验
对比了不同的注意力机制和提取BEV的骨干网络
- BEV骨干网络
- VPN
- List-Splat
- Attention
- Global
- Points
- Local

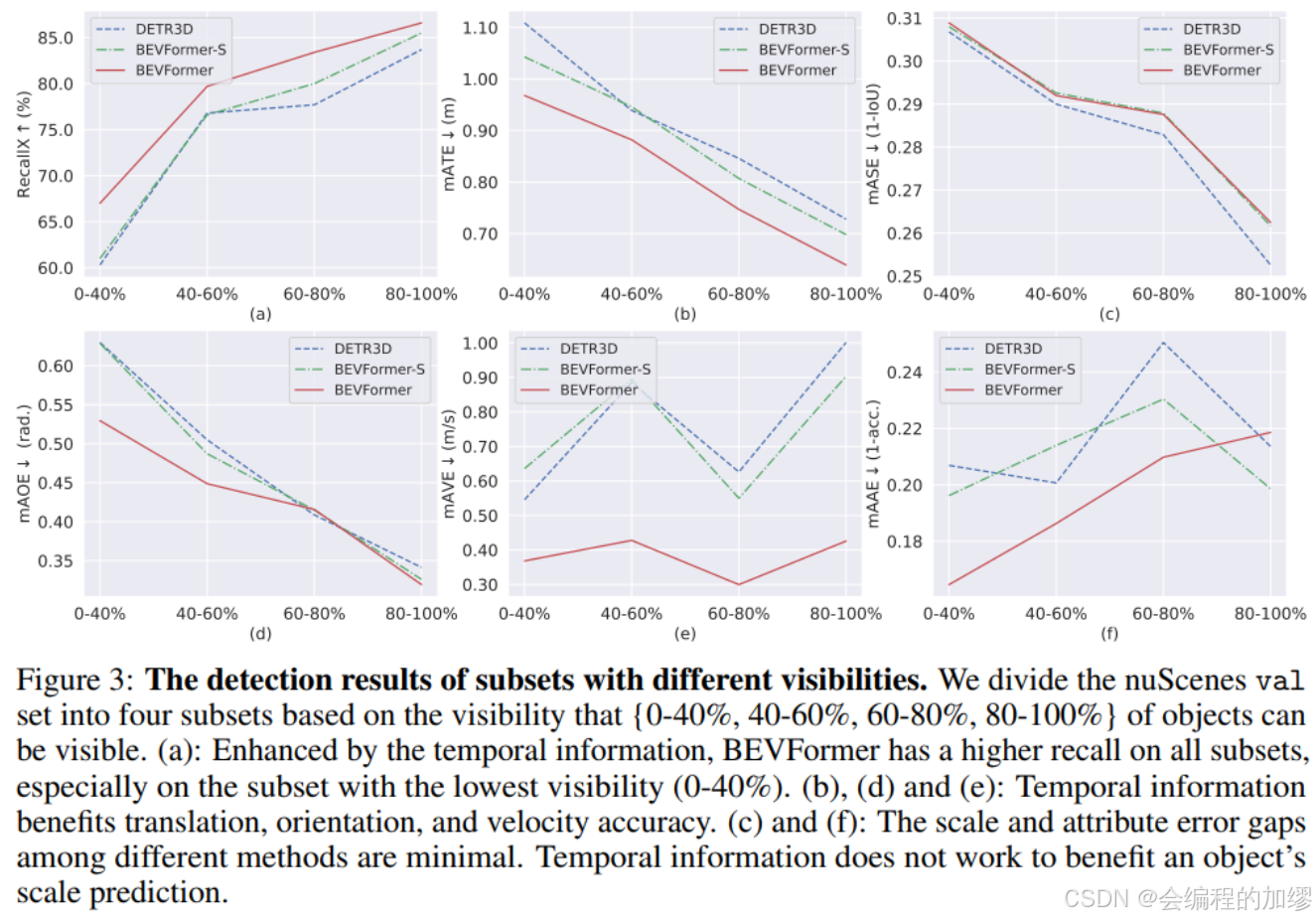
同时为了验证时间自注意力的效果,作者对比了不同遮挡等级的模型效果,可以明显看到的是BEVFormer的召回率更高:
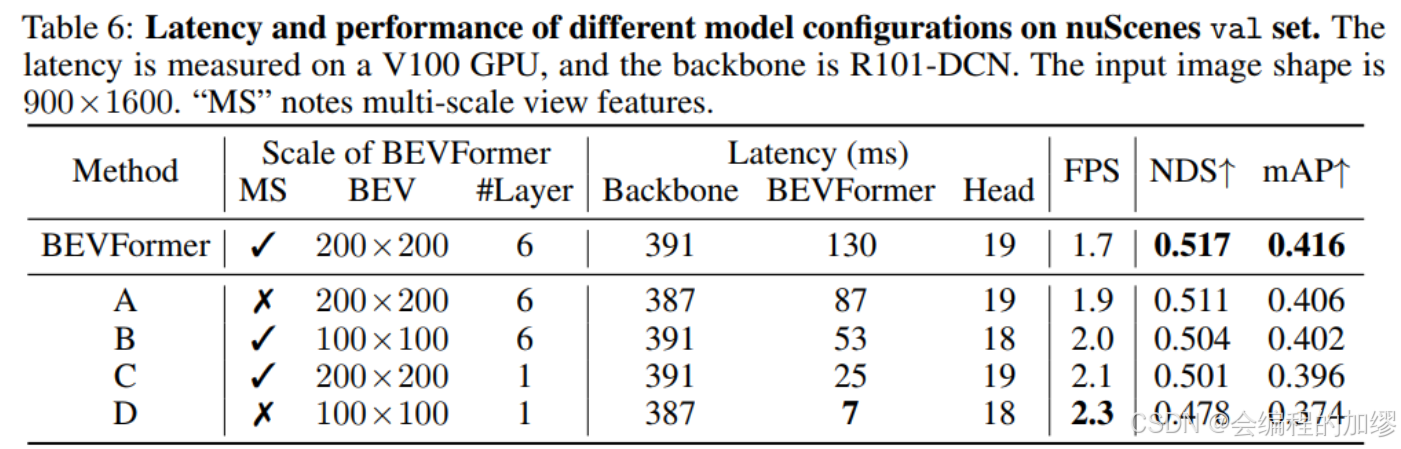
与此同时,作者还对比了不同模型参数设置下的推理速度:
五、总结
总结:在这项工作中,我们提出了BEVFormer,用于从多摄像头输入中生成鸟瞰图特征。BEVFormer能够高效地聚合空间和时间信息,并生成强大的鸟瞰图(BEV)特征,这些特征可同时支持3D目标检测和地图分割任务。 |