我们现在准备讨论更多关于CUDA内核功能以及启动这些内核功能的效果。在CUDA中,内核函数指定所有线程在并行阶段执行的代码。由于所有这些线程执行相同的代码,CUDA编程是众所周知的单程序多数据(SPMD)[Ata 1998]并行编程风格的实例,这是一种大规模并行计算系统的流行编程风格。
请注意,SPMD与SIMD(单指令多数据)不同[Flynn 1972]。在SPMD系统中,并行处理单元在数据的多个部分上执行相同的程序。然而,这些处理单元不需要同时执行相同的指令。在SIMD系统中,所有处理单元在任何时候都在执行相同的指令。
“在CUDA 3.0及更高版本中,每个线程块最多可以有1024个线程。一些早期的CUDA版本只允许一个块中最多512个线程。
当程序的主机代码启动内核时,CUDA运行时系统会生成一个线程网格,这些线程被组织成两级层次结构。每个网格都组织成线程块数组,为了简洁,将被称为线程块。网格的所有块大小相同;每个块最多可包含1024个线程。图2.11显示了每个块由256个线程组成的示例。每个线程都由一个卷曲的箭头表示,这个箭头来自一个标有数字的block。启动内核时,每个线程块中的线程总数由主机代码指定。同一内核可以在主机代码的不同部分使用不同数量的线程启动。对于给定的网格,块中的线程数在内置的blockDim变量中可用。
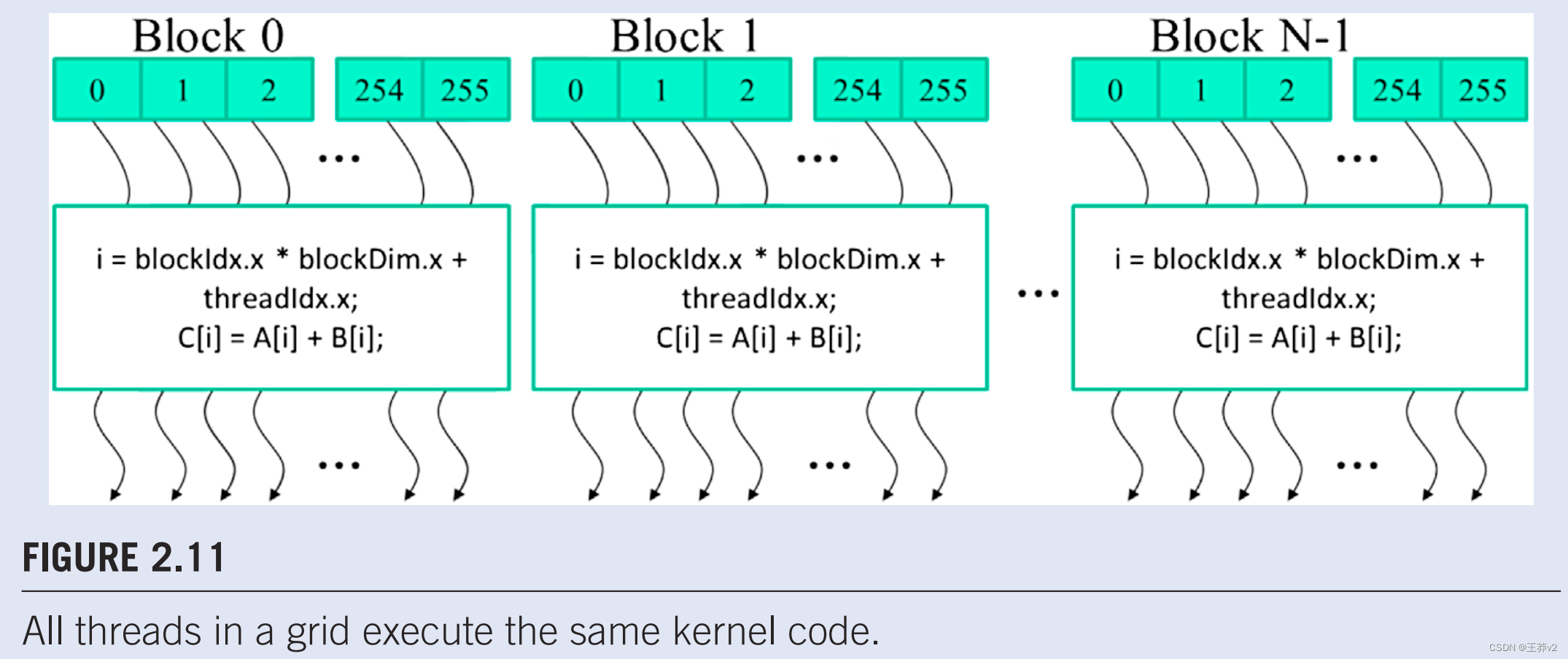
blockDim变量是结构类型,有三个无符号整数字段:x、y和z,这有助于程序员将线程组织成一维、二维或三维数组。对于一维组织,将只使用x字段。对于二维组织,将使用x和y字段。对于三维结构,将使用所有三个字段。组织线程的维度选择通常反映了数据的维度。这是有道理的,因为创建线程是为了并行处理数据。线程的组织反映了数据的组织,这是很自然的。在图2.11中,每个线程块都组织为线程的一维数组,因为数据是一维向量。blockDim.x变量的值指定了每个块中的线程总数,在图2.11中为256。一般来说,线程的数量由于硬件效率的原因,线程块每个维度的线程应该是32的倍数。我们稍后会重温这个问题。
CUDA内核可以访问另外两个内置变量(threadldx,blockldx),这些变量允许线程相互区分,并确定每个线程要处理的数据区域。变量threadldx在块内为每个线程提供唯一的坐标。例如,在图2.11中,由于我们使用的是一维线程组织,因此将只使用threadldx.x。每个线程的sthreadldx.x值显示在图2.11.中每个线程的小阴影框中。每个块中的第一个线程在其threadldx.x变量中具有值 0,第二个线程具有值1,第三个线程具有值2,等。
Blockldx变量为块中的所有线程提供一个公共块坐标。在图2.11中,第一个块中的所有线程在其blockldx.x变量中都有值0,第二个线程块中的值为1,以此等。使用与电话系统的类比,人们可以将threadldx.x视为本地电话号码,将blockldx.x视为区号。两者一起给每条电话线一个全国唯一的电话号码。同样,每个线程可以结合其threadldx和blockIdx值,在整个网格中为自己创建一个唯一的全局索引。
在图2.11中,**一个唯一的全局索引i计算为i = blockldx.x*blockDim.x + threadldx.x。**回想一下,在我们的例子中,blockDim是256。0块中线程的i值从0到255不等。第1块中线程的i值从256到511不等。第2块中线程的i值从512到767不等。也就是说,这三个块中线程的i值形成了从0到767的值的连续覆盖。由于每个线程使用i来访问A、B和C,这些线程涵盖了原始循环的前768次迭代。请注意,我们不会在内核中使用“h_”和“d_”约定,因为没有潜在的混淆。在我们的示例中,我们将无法访问主机内存。通过启动具有更多块的内核,可以处理更大的向量。通过启动具有n个或更多线程的内核,可以处理长度为n的向量。
图2.12显示了向量加法的内核函数。语法是ANSI C,有一些值得注意的扩展。首先,在vecAddKernel函数的声明前面有一个CUDA C特定的关键字“global”。此关键字表示该函数是内核,可以从主机函数调用以在设备上生成线程网格。


一般来说,CUDA C用三个限定词关键词扩展了C语言,这些关键词可用于函数声明。这些关键字的含义总结在图2.13 中“global”关键字表示正在声明的函数是CUDA C内核函数。请注意,“global”一词的两侧各有两个下划线字符。这种内核函数将在设备上执行,并且只能从主机代码调用,除非在支持动态并行的CUDA系统中,正如我们将在第13章CUDA动态并行性中解释的那样。“device”关键字表示正在声明的函数是CUDA设备函数。设备函数在CUDA设备上执行,只能从内核函数或其他设备函数调用。
我们稍后将解释在不同代CUDA中使用间接函数调用和递归的规则。一般来说,应该避免在其设备函数和内核函数中使用递归和间接函数调用,以实现最大的可移植性。
“host”关键字表示正在声明的函数是CUDA主机函数。主机函数只是一个传统的C函数,在主机上执行,只能从另一个主机函数调用。默认情况下,如果声明中没有任何CUDA关键字,CUDA程序中的所有函数都是主机函数。这是有道理的,因为许多CUDA应用程序是从仅CPU执行环境移植的。程序员将在移植过程中添加内核功能和设备功能。原始功能仍然是主机功能。将所有函数默认为主机函数,使程序员免于更改所有原始函数声明的繁琐工作。
请注意,可以在函数声明中同时使用“host”和“device”。这种组合告诉编译系统为同一函数生成两个版本的对象文件。一个在主机上执行,只能从主机函数调用。另一个在设备上执行,只能从设备或内核函数调用。这支持一个常见的用例,当相同的函数源代码可以重新编译以生成设备版本时。许多用户库功能可能属于这一类。
ANSI C的第二个值得注意的扩展,在图2.12中,是内置变量“threadldx.x”、“blockldx.x”和“blockDim.x”。回想一下,所有线程都执行相同的kernel代码。他们需要一种方法来区分自己,并将每个线程引向数据的特定部分。这些内置变量是线程访问硬件寄存器的手段,这些寄存器为线程提供识别坐标。不同的线程将在其threadldx.X、blockldx.x和blockDim.x变量中看到不同的值。为了简单起见,我们将线程称为 t h r e a d b l o c k i d x . x , t h r e a d i d x . x thread_{blockidx.x,threadidx.x} threadblockidx.x,threadidx.x。请注意,“x”意味着应该有“.y”和“.z”。我们很快就会回到这一点上。
图2.12中有一个自动(局部)变量i。.在CUDA内核函数中,自动变量对每个线程都是私有的。也就是说,将为每个线程生成一个i版本。如果内核以10,000个线程启动,将有10,000个版本的i,每个线程一个。线程分配给其i变量的值对其他线程不可见。我们将在第4章“内存和数据位置”中更详细地讨论这些自动变量。
图2.5和2.12之间的快速比较。揭示了CUDA内核和CUDA内核启动的重要见解。图2.12中的内核函数没有与图2.5.中的循环相对应的循环。读者应该问这个循环去了哪里。答案是,循环现在被线程网格所取代。整个网格形成等价的循环。网格中的每个线程对应于原始循环的一次迭代。这种类型的数据并行性有时也被称为循环并行性,其中原始顺序代码的迭代由线程并行执行。
**请注意,在图2.12.中的addVecKernel中有一个if(i < n)语句。这是因为并非所有向量长度都可以表示为块大小的倍数。**例如,让我们假设矢量长度是100。最小的高效螺纹块尺寸为32。假设我们选择了32个块大小。需要启动四个线程块来处理所有100个矢量元素。然而,这四个线程块将有128个线程。我们需要禁用线程块3中的最后28个线程,使其无法完成原始程序预期之外的工作。由于所有线程都将执行相同的代码,因此所有线程都将针对n(即100)测试其i值。使用if(i <n)语句,前100个线程将执行加法,而最后28个线程不会执行加法。这允许内核处理任意长度的向量。

当主机代码启动内核时,它通过执行配置参数设置网格和线程块尺寸。图2.14.中说明了这一点。配置参数在传统C函数参数之前的“<<<”和“>>>”之间给出。第一个配置参数给出了网格中线程块的数量。第二个指定每个线程块中的线程数。在本例中,每个块中有256个线程。为了确保我们有足够的线程来覆盖所有向量元素,我们将C ceiling 函数应用于n/256.0。使用foating点值256.0可确保我们为除法生成浮动值,以便 ceiling 函数可以正确四舍五入。例如,如果我们有1000个线程,我们将启动ceil(1000/256.0)= 4个线程块。因此,该语句将启动4*256 = 1024线程。使用内核中的if(i < n)语句,如图2.12所示,前1000个线程将对1000个矢量元素进行加法。剩下的24个不会。