这个是继上一篇文章 “Elasticsearch:Serarch tutorial - 使用 Python 进行搜索 (二)” 的续篇。在今天的文章中,本节将向你介绍一种不同的搜索方式,利用机器学习 (ML) 技术来解释含义和上下文。
向量搜索
嵌入 (embeddings) 简介
在机器学习中,嵌入是表示现实世界对象(例如单词、句子、图像或视频)的向量(数字数组)。 这些嵌入的有趣特性是,表示相似或相关的现实世界实体的两个嵌入也会共享一些相似性,因此可以比较嵌入,并且可以计算它们之间的距离。
当具体考虑搜索应用程序时,在向量空间中执行嵌入搜索往往会找到与概念更相关的结果,而不是与搜索提示中输入的确切关键字相关的结果。
在本教程的这一部分中,你将学习如何使用免费的机器学习模型生成嵌入,然后你将使用 Elasticsearch 的想量数据库支持来存储和搜索这些嵌入。 最后,你还将结合想量和全文搜索结果,并创建一个强大的混合搜索解决方案,提供两种方法的优点。
生成嵌入
在本节中,你将了解可用于生成文本嵌入的最方便的选项之一,该选项基于 SentenceTransformers框架。
当您探索并熟悉嵌入的使用时,建议使用 SentenceTransformers ,因为此框架下可用的模型可以安装在您的计算机上,无需 GPU 即可表现良好,并且可以免费使用。
安装SentenceTransformers
SentenceTransformers 框架作为 Python 包安装。 确保你的 Python 虚拟环境已激活,然后在终端上运行以下命令来安装此框架:
pip install sentence-transformers
与往常一样,每当你向项目添加新的依赖项时,最好更新你的需求文件:
pip freeze > requirements.txt选择模型
下一个任务是决定用于嵌入生成的机器学习模型。 文档中有预训练模型的列表。 由于 SentenceTransformers 是一个非常流行的框架,因此也有一些由与该框架不直接相关的研究人员创建的兼容模型。 要查看可用模型的完整列表,你可以检查 HuggingFace 上的 SentenceTransformers 标签。
就本教程而言,无需过度考虑模型选择,因为任何模型就足够了。 SentenceTransformers 文档包含以下有关其预训练模型的注释:
all-* 模型根据所有可用训练数据(超过 10 亿个训练对)进行训练,并被设计为通用模型。 all-mpnet-base-v2 模型提供最佳质量,而 all-MiniLM-L6-v2 速度快 5 倍,但仍提供良好的质量。
这似乎表明他们的全 MiniLM-L6-v2 模型是一个不错的选择,在速度和质量之间提供了良好的折衷,所以让我们使用这个模型。 在表中找到该模型,然后单击 “info” 图标以查看有关它的一些信息。
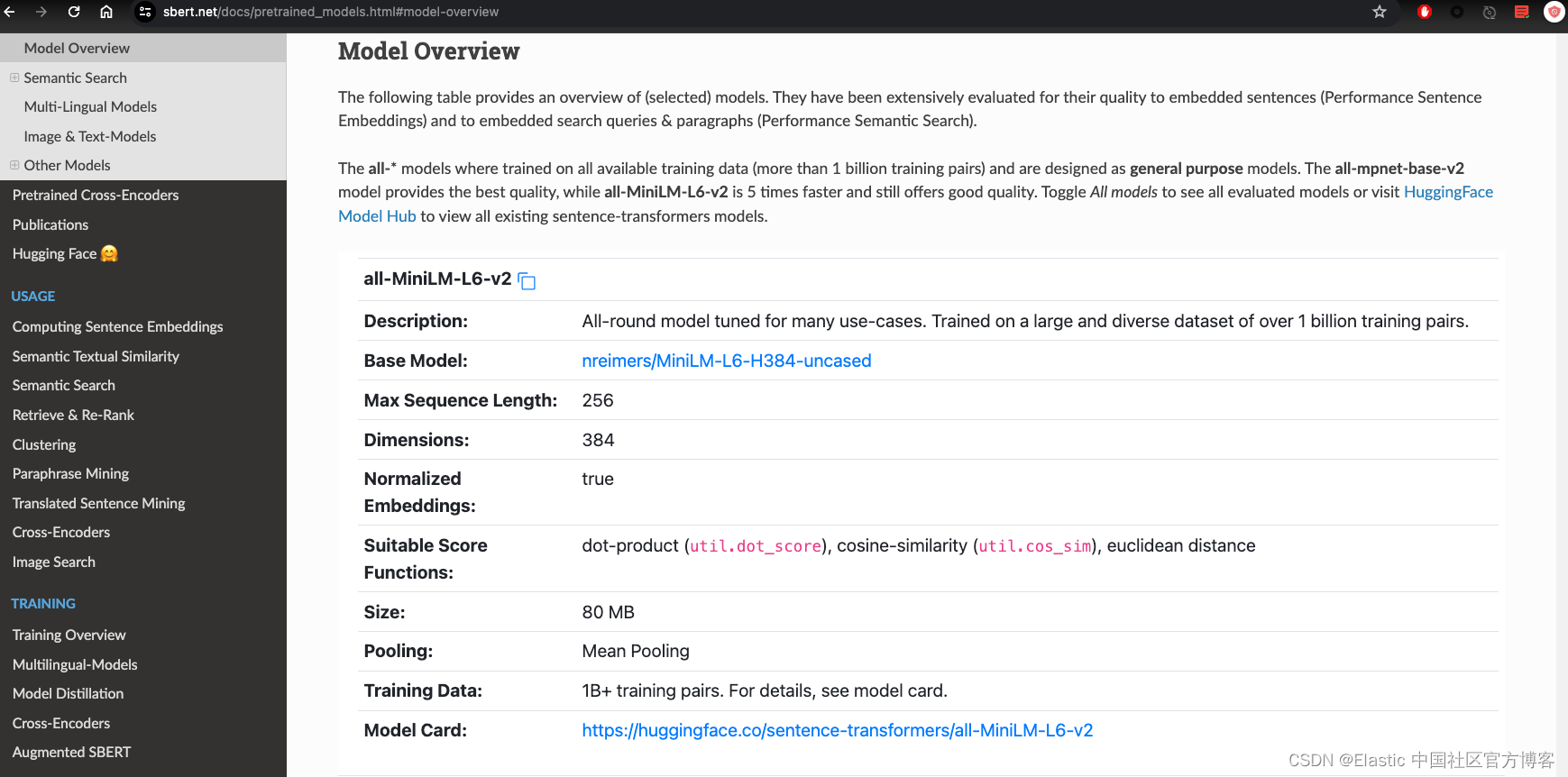
关于您选择的模型,需要注意的一个有趣的细节是生成的嵌入的长度,或者换句话说,生成的向量将具有多少个数字或维度。 这很重要,因为它直接影响你需要的存储量。 在全 MiniLM-L6-v2 的情况下,生成的向量具有 384 维。
加载模型
以下 Python 代码演示了如何加载模型。 你可以在 Python shell 中尝试此操作。
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('all-MiniLM-L6-v2')(.venv) $ python3
Python 3.11.6 (v3.11.6:8b6ee5ba3b, Oct 2 2023, 11:18:21) [Clang 13.0.0 (clang-1300.0.29.30)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from sentence_transformers import SentenceTransformer
>>> model = SentenceTransformer('all-MiniLM-L6-v2')
>>> 第一次执行此操作时,模型将被下载并安装在你的虚拟环境中,因此调用可能需要一些时间才能返回。 一旦安装了模型,实例化它应该不会花很长时间。
生成嵌入
模型实例化后,你现在就可以生成嵌入了。 为此,请将源文本传递给 model.encode() 方法:
embedding = model.encode('The quick brown fox jumps over the lazy dog')
结果是一个包含构成嵌入的所有数字的数组。 你还记得,所选模型生成的嵌入有 384 个维度,因此这是 embedding 数组的长。
在 Elasticsearch 中存储嵌入
Elasticsearch 提供对存储和检索向量的全面支持,这使其成为处理嵌入的理想数据库。
字段类型
在本教程的全文搜索一章中,你学习了如何创建包含多个字段的索引。 当时有人提到,Elasticsearch 在很大程度上可以根据数据本身自动确定每个字段使用的最佳类型。 尽管 Elasticsearch 8.11 能够自动映射某些向量类型,但在本章中,你将显式定义此类型,以此作为了解有关 Elasticsearch 中类型映射的更多信息的机会。
检索类型映射
与索引中每个字段关联的类型是在称为映射的过程中确定的,该过程可以是动态的或显式的。 本教程的全文搜索部分中创建的映射都是由 Elasticsearch 动态生成的。
Elasticsearch 客户端提供 get_mapping 方法,该方法返回对给定索引有效的类型映射。 如果你想自行探索这些映射,请启动 Python shell 并输入以下代码:
from app import es
es.es.indices.get_mapping(index='my_documents')
从这里你可以看到 created_on 和 updated_at 字段自动被识别为 date 字段类型,而其他每个字段都被识别为 text 类型。 当尝试决定类型时,Elasticsearch 首先检查数据的类型,这有助于为字段分配数字、布尔和对象类型。 当字段数据是字符串时,它还会尝试查看数据是否与日期模式匹配。 如果需要,还可以针对数字启用基于模式的字符串检测。
文本(text)字段具有带有 keyword 条目的字段定义。 这称为子字段,是在适当时可用的替代或辅助类型。 在 Elasticsearch 中,动态输入的文本字段被赋予 keyword子字段。 你已经使用 category.keyword 子字段对给定类别执行精确搜索。 为了避免添加子字段,可以给出 text 或 keyword 的显式映射,然后这将是主要且唯一的类型。
将 vector 字段添加到索引
让我们向索引添加一个新字段,其中将存储每个文档的嵌入。
显式映射的结构与 Elasticsearch 客户端的 get_mapping() 方法返回的响应的 mappings 键匹配。 仅需要给出需要显式键入的字段,因为映射中未包含的任何字段将继续像以前一样动态键入。
下面你可以看到 Search 类的 create_index() 方法的新版本,添加了一个名为 embedding 的显式类型字段。 在 search.py 中替换此方法:
search.py
class Search:
# ...
def create_index(self):
self.es.indices.delete(index='my_documents', ignore_unavailable=True)
self.es.indices.create(index='my_documents', mappings={
'properties': {
'embedding': {
'type': 'dense_vector',
}
}
})
正如你所看到的,embedding 字段被赋予了 dense_vector 类型,这是存储嵌入时的适当类型。 稍后你将了解另一种类型的向量,即 sparce_vector,它在其他类型的语义搜索应用程序中很有用。
dense_vector 类型接受一些参数,所有这些参数都是可选的。
- dims:将存储的向量的大小。 从版本 8.11 开始,插入第一个文档时会自动分配尺寸。
- index:必须设置为 True 以指示应为向量建立索引以进行搜索。 这是默认设置。
- similarity:比较向量时使用的距离函数。 最常见的两个是点积和余弦。 点积效率更高,但需要对向量进行归一化。 默认值为余弦。
向文档添加嵌入
在上一节中,你学习了如何使用 SentenceTransformers 框架和全 MiniLM-L6-v2 模型生成嵌入。 现在是时候将模型集成到应用程序中了。
首先,可以在 Search 类构造函数中实例化模型:
search.py
# ...
from sentence_transformers import SentenceTransformer
# ...
class Search:
def __init__(self):
url = f"https://{elastic_user}:{elastic_password}@{elastic_endpoint}:9200"
self.model = SentenceTransformer('all-MiniLM-L6-v2')
self.es = Elasticsearch(url, ca_certs = "./http_ca.crt", verify_certs = True)
client_info = self.es.info()
print('Connected to Elasticsearch!')
pprint(client_info.body)正如你在本教程的全文搜索部分中回想的那样,Search 类具有 insert_document() 和 insert_documents() 方法,用于分别将单个和多个文档插入到索引中。 这两种方法现在需要生成与每个文档对应的嵌入。
下一个代码块显示了这两个方法的新版本,以及返回嵌入的新 get_embedding() 辅助方法。
class Search:
# ...
def get_embedding(self, text):
return self.model.encode(text)
def insert_document(self, document):
return self.es.index(index='my_documents', document={
**document,
'embedding': self.get_embedding(document['summary']),
})
def insert_documents(self, documents):
operations = []
for document in documents:
operations.append({'index': {'_index': 'my_documents'}})
operations.append({
**document,
'embedding': self.get_embedding(document['summary']),
})
return self.es.bulk(operations=operations)修改后的方法将新的 embedding 字段添加到要插入的文档中。 嵌入是从每个文档的 summary 字段生成的。 一般来说,嵌入是从句子或短段落生成的,因此在这种情况下,summary 是一个理想的使用字段。 其他选项是名称字段,其中包含文档的 name,或者可能是文档 body 的前几句话。
通过这些更改,可以重建索引,以便它存储每个文档的嵌入。 要重建索引,请使用以下命令:
flask reindex(.venv) $ flask reindex
Connected to Elasticsearch!
{'cluster_name': 'elasticsearch',
'cluster_uuid': 'SXGzrN4dSXW1t0pkWXGfjg',
'name': 'liuxgm.local',
'tagline': 'You Know, for Search',
'version': {'build_date': '2023-11-04T10:04:57.184859352Z',
'build_flavor': 'default',
'build_hash': 'd9ec3fa628c7b0ba3d25692e277ba26814820b20',
'build_snapshot': False,
'build_type': 'tar',
'lucene_version': '9.8.0',
'minimum_index_compatibility_version': '7.0.0',
'minimum_wire_compatibility_version': '7.17.0',
'number': '8.11.0'}}
Index with 15 documents created in 100 milliseconds.如果你需要提醒,flask reindex 命令是在 app.py 中的 reindex() 函数中实现的。 它调用 Search 类的 reindex() 方法,该方法又调用 create_index(),然后将 data.json 文件中的所有数据传递给 insert_documents()。
通过运行上面的命令,我们可以在 Kibana 中进行查看:
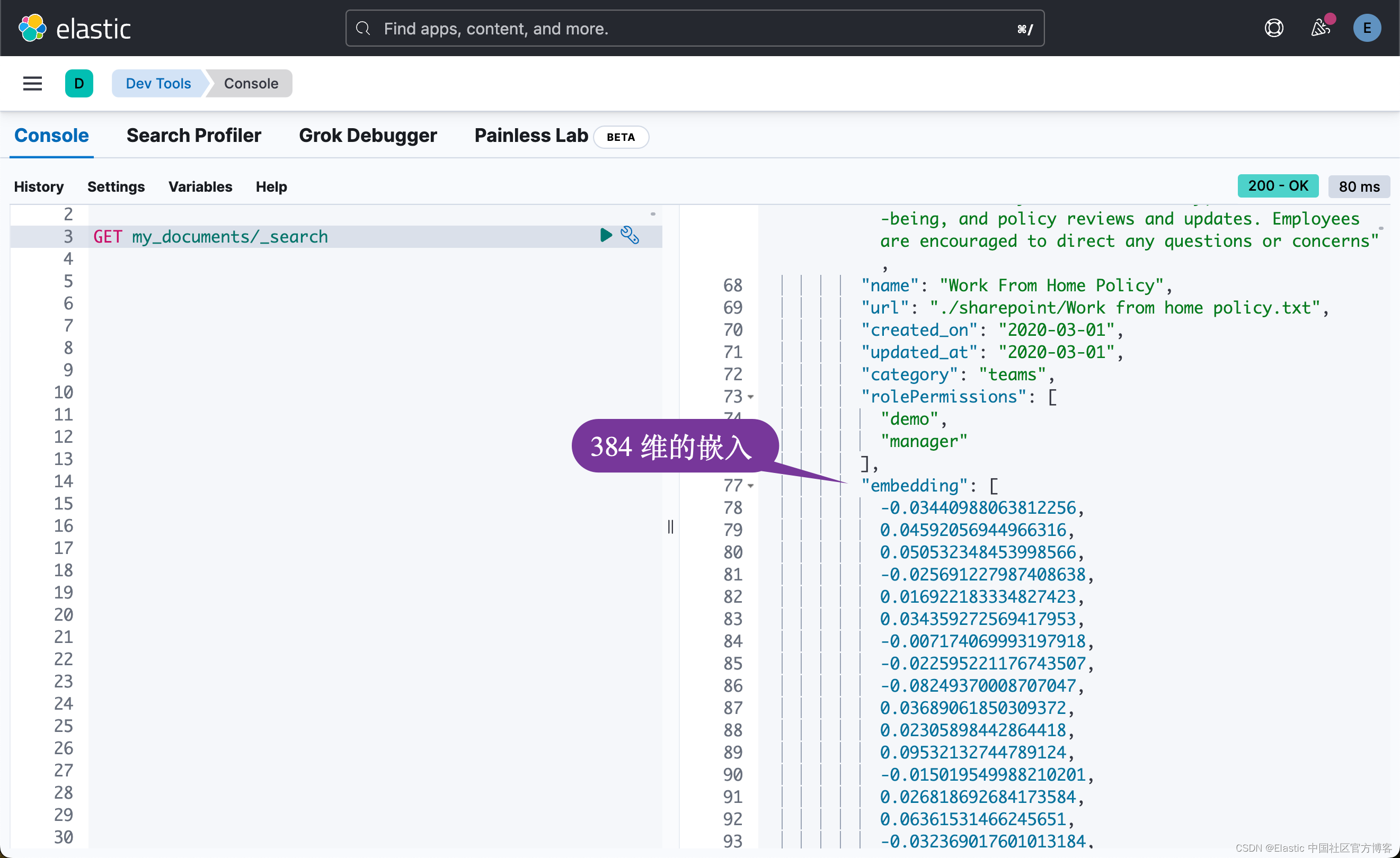
k 最近邻 (kNN) 搜索
k 最近邻 (kNN) 算法对密集向量类型的字段执行相似性搜索。 这种类型的搜索更合适地称为 “近似 kNN”,接受向量或嵌入作为搜索项,并查找索引中接近的条目。 这是
在本节中,你将学习如何使用上一节中创建的文档嵌入来运行 kNN 搜索。
knn 查询
在本教程的全文搜索部分中,你了解了传递给 Elasticsearch 客户端的 search() 方法的查询选项。 当搜索向量时,使用 knn 选项。
下面你可以在 app.py 中看到新版本的 handle_search() 函数,它对用户在搜索表单中输入的查询运行 kNN 搜索。
@app.post('/')
def handle_search():
query = request.form.get('query', '')
filters, parsed_query = extract_filters(query)
from_ = request.form.get('from_', type=int, default=0)
results = es.search(
knn={
'field': 'embedding',
'query_vector': es.get_embedding(parsed_query),
'num_candidates': 50,
'k': 10,
}, size=5, from_=from_
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=from_,
total=results['hits']['total']['value'])
在此版本的函数中,查询选项已替换为 knn。 用于分页的 size 和 from_ 选项保持不变,函数和 index.html 模板中的其他所有内容也与以前相同。
knn 搜索选项接受许多配置搜索的参数:
- field:索引中要搜索的字段。 该字段必须具有密集向量类型。
- query_vector:要搜索的嵌入。 这应该是从搜索文本生成的嵌入。
- num_candidates:每个分片要考虑的候选文档数量。 Elasticsearch 从每个分片中检索这么多候选者,将它们组合成一个列表,然后找到最接近的 “k” 个作为结果返回。
- k:要返回的结果数。 该数字对性能有直接影响,因此应尽可能小。 此选项中传递的值必须小于 num_candidates。
根据上面代码中使用的设置,将返回 10 个最佳匹配结果。
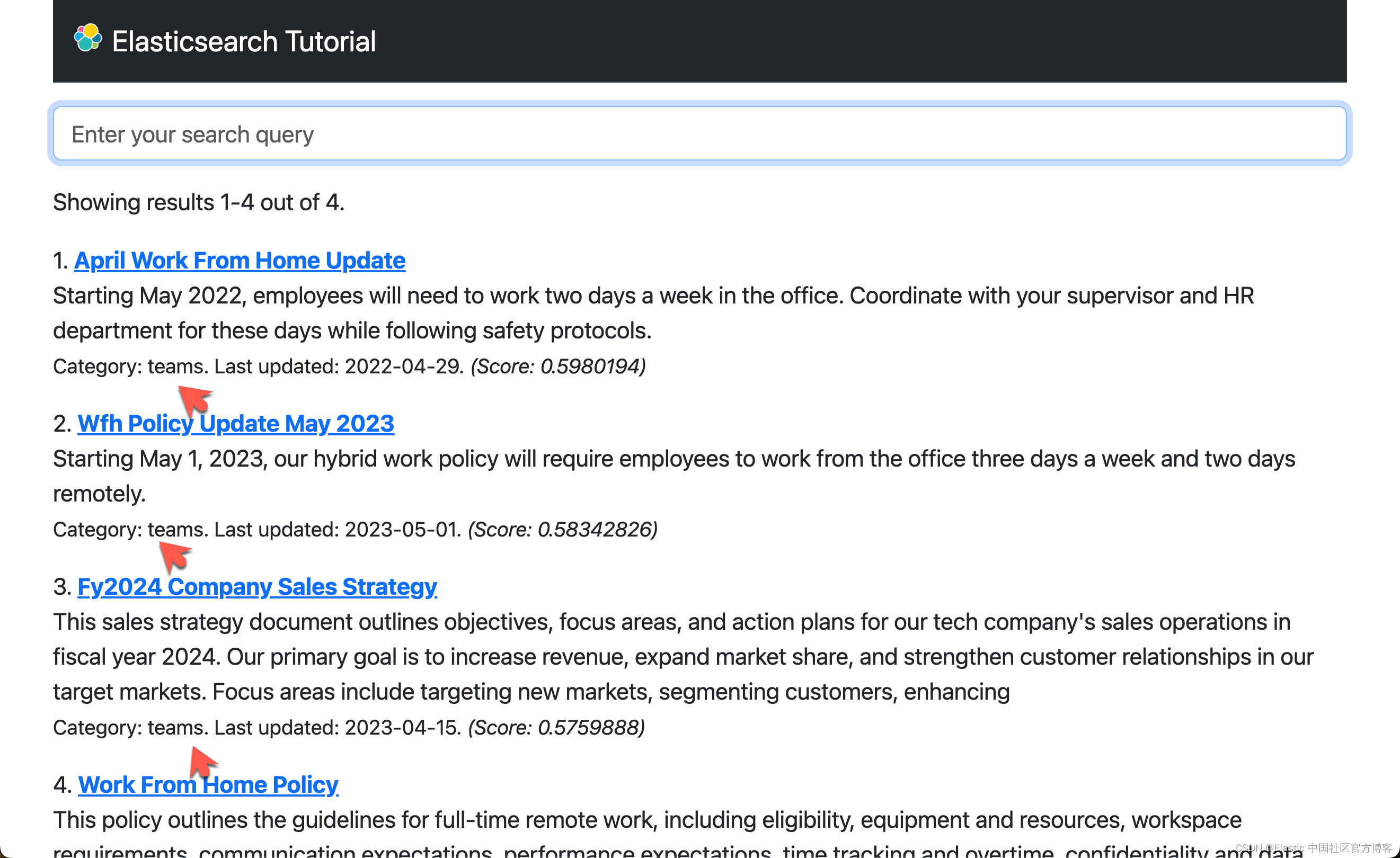
欢迎你尝试这个新版本的应用程序。 以下是两个很好的例子,可以让你了解这种类型的搜索有多么有用:
- 搜索 “holiday”(英式英语,相当于美式英语中的 “vacation”)时,kNN 搜索会返回文档 “Vacation Policy” 作为顶部结果,即使单词 “holiday” 本身没有出现在文档中。

- 搜索 “cats and dogs" 或任何其他与宠物相关的术语会将 “Office Pet Policy” 文档作为顶部结果,即使文档摘要未提及任何特定宠物。

在 kNN 查询中使用过滤器
搜索查询(如本教程全文部分中所定义)允许用户在搜索文本的任何位置使用语法 “category:<category-name>” 来请求使用特定类别。 app.py 中的 extract_filters() 函数负责查找这些过滤表达式并将其与搜索查询分离。 在上一节中的 handle_search() 函数版本中,没有使用 filters 变量,因此类别过滤器被忽略。
幸运的是,knn 选项还支持过滤。 filter 选项实际上接受相同类型的过滤器,因此可以将过滤器直接插入到 knn 查询中,与 extract_filters() 函数返回的过滤器完全相同:
@app.post('/')
def handle_search():
query = request.form.get('query', '')
filters, parsed_query = extract_filters(query)
from_ = request.form.get('from_', type=int, default=0)
results = es.search(
knn={
'field': 'embedding',
'query_vector': es.get_embedding(parsed_query),
'k': 10,
'num_candidates': 50,
**filters,
}, size=5, from_=from_
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=from_,
total=results['hits']['total']['value'])此版本的 handle_search() 函数具有与全文搜索版本相同的功能,使用向量量搜索而不是基于关键字的搜索来实现。

在下一节中,你将学习如何组合这两种不同搜索方法的结果。
混合搜索:结合全文和 kNN 结果
你现在已经看到了两种不同的方法来搜索文档集合,每种方法都有其独特的优点。 如果其中一种方法满足你的需求,那么你不需要任何其他方法,但在许多情况下,每种搜索方法都会返回其他方法可能会错过的有价值的结果,因此最好的选择是提供组合结果集。
对于这些情况,Elasticsearch 提供了倒数排名融合 (RRF),这是一种将两个或多个列表的结果合并到一个列表中的算法。
RRF 的运作方式
Elasticsearch 将 RRF 算法集成到搜索查询中。 考虑以下示例,其中包含分别请求全文和向量搜索的 query 和 knn 部分,以及将它们组合成单个结果列表的 rrf 部分。
self.es.search(
query={
# full-text search query here
},
knn={
# vector search query here
},
rank={
"rrf": {}
}
)虽然 RRF 在没有任何配置的情况下工作得相当好,但可以调整一些参数以提供最佳结果。 请查阅文档以详细了解这些内容。
RRF 实施
为了使组合搜索能够从全文搜索和向量搜索方法返回结果,必须恢复之前在 handle_search() 函数中使用的全文搜索逻辑。 要实现混合搜索策略,search() 方法必须接收查询和 knn 参数,每个参数请求一个单独的查询。 还添加了如上所示的排名部分,以将结果合并到单个排名列表中。
这是实现混合搜索策略的 handle_search() 版本:
@app.post('/')
def handle_search():
query = request.form.get('query', '')
filters, parsed_query = extract_filters(query)
from_ = request.form.get('from_', type=int, default=0)
if parsed_query:
search_query = {
'must': {
'multi_match': {
'query': parsed_query,
'fields': ['name', 'summary', 'content'],
}
}
}
else:
search_query = {
'must': {
'match_all': {}
}
}
results = es.search(
query={
'bool': {
**search_query,
**filters
}
},
knn={
'field': 'embedding',
'query_vector': es.get_embedding(parsed_query),
'k': 10,
'num_candidates': 50,
**filters,
},
rank={
'rrf': {}
},
size=5,
from_=from_,
)
return render_template('index.html', results=results['hits']['hits'],
query=query, from_=from_,
total=results['hits']['total']['value'])
在此版本中,结合了每种搜索方法的最佳结果。 单击此处查看包含这些更改的完整应用。
git clone https://github.com/liu-xiao-guo/search-tutorial-2