通常来说,构造决策树直到所有叶结点都是纯的叶结点,但这会导致模型非常复杂,并且对于训练数据高度过拟合。
为了防止过拟合,有两种常见策略:
1、尽早停止树的生长,也叫预剪枝
2、先构造树,但随后删除或折叠信息量很少的结点,也叫后剪枝。
预剪枝的限制条件可能包含限制树的最大深度、限制叶结点的最大数目、规定一个结点中数据点的最小数目。
如果不防止过拟合:
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
import graphviz
plt.rcParams['font.sans-serif'] = ['SimHei']
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(
cancer.data,cancer.target,stratify=cancer.target,random_state=42
)
tree=DecisionTreeClassifier(random_state=0)
tree.fit(X_train,y_train)
print('训练集score:{:.3f}'.format(tree.score(X_train,y_train)))
print('测试集score:{:.3f}'.format(tree.score(X_test,y_test)))

可以看到,训练集上精度是100%,但测试集的精度只有93.7%。
防止过拟合,比如限制决策树的深度为4:
tree=DecisionTreeClassifier(max_depth=4,random_state=0)
可以看到,虽然训练集的精度下降,但是测试集的精度有所提升。
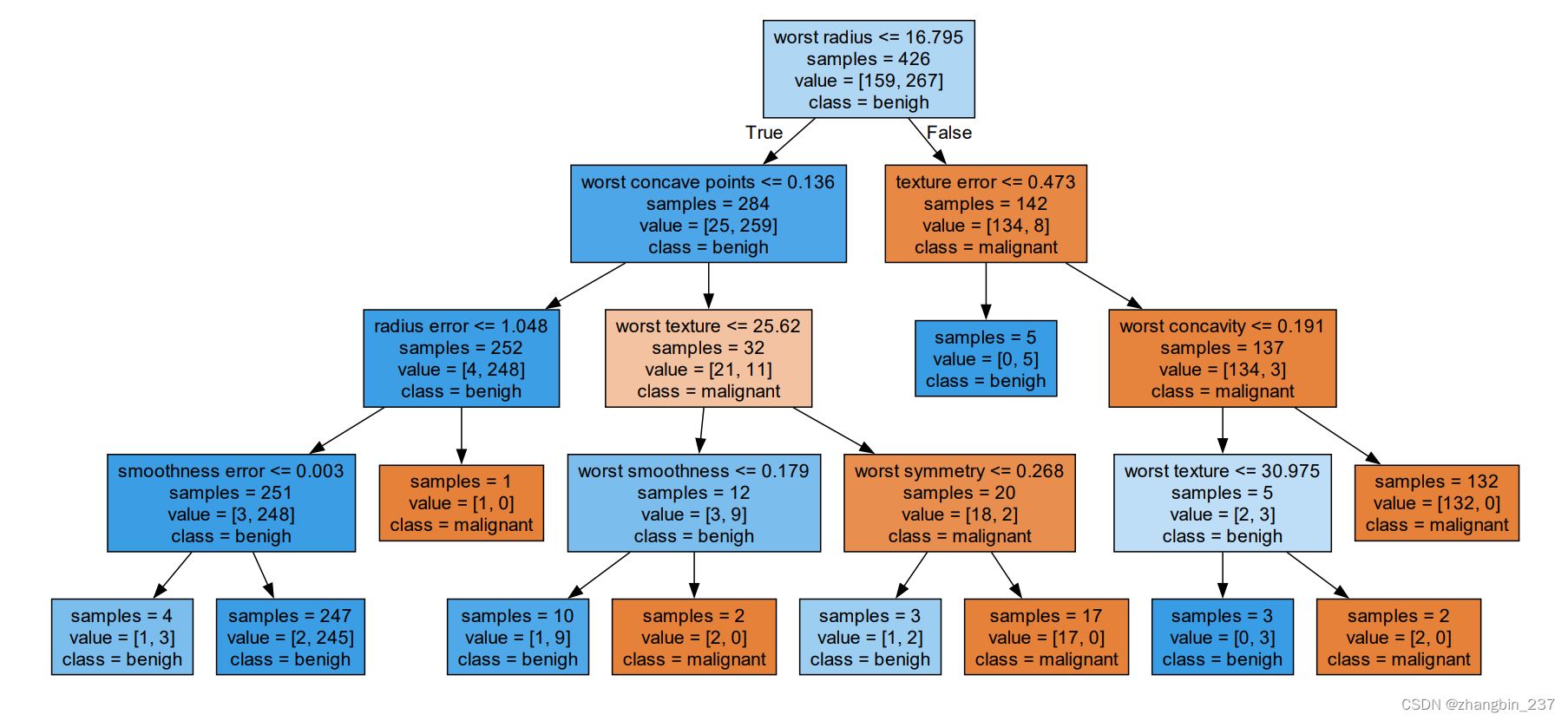
还可以用tree模块的export_graphviz函数来将树可视化。这个函数会生成一个dot文件,然后用graphviz读取这个文件并可视化(通过生成pdf文件的方式):
export_graphviz(tree,out_file='tree_1.dot',class_names=['malignant','benigh'],feature_names=cancer.feature_names,impurity=False,filled=True)
with open('tree_1.dot') as f:
dot_graph=f.read()
g=graphviz.Source(dot_graph)
g.render('决策树可视化')