1. Java IO
IO,即输入(in)和输出(out),指应用程序和外部设备之间的数据传递,常见的外部设备包括文件、管道、网络连接。Java 中是通过流处理 IO 的,
那么什么是流?
流(Stream),是一个抽象的概念,是指一连串的数据(字符或字节),是以先进先出的方式发送信息的通道。当程序需要读取数据的时候,就会开启一个通向数据源的流,这个数据源可以是文件,内存,或是网络连接。类似的,当程序需要写入数据的时候,就会开启一个通向目的地的流。这时候你就可以想象数据好像在这其中 “流” 动一样。
一般来说关于流的特性有下面几点:
- 先进先出:最先写入输出流的数据最先被输入流读取到。
- 顺序存取:可以一个接一个地往流中写入一串字节,读出时也将按写入顺序读取一串字节,不能随机访问中间的数据。(RandomAccessFile 除外)
- 只读或只写:每个流只能是输入流或输出流的一种,不能同时具备两个功能,输入流只能进行读操作,对输出流只能进行写操作。在一个数据传输通道中,如果既要写入数据,又要读取数据,则要分别提供两个流。
1.1 IO 流分类
IO 流主要的分类方式有以下 3 种:
- 按数据流的方向:输入流、输出流
- 按处理数据单位:字节流、字符流
- 按功能:节点流、处理流
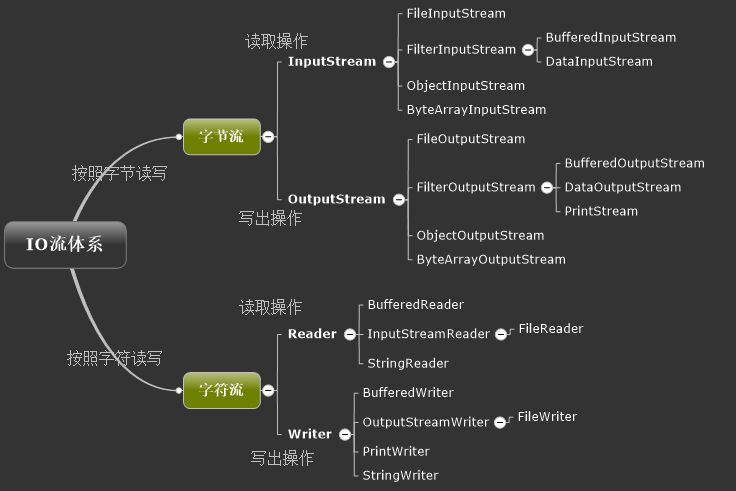
1.1.1 输入流与输出流
输入与输出是相对于应用程序而言的,比如文件读写,读取文件是输入流,写文件是输出流,这点很容易搞反。

1.1.2 字节流与字符流
字节流和字符流的用法几乎完成全一样,区别在于字节流和字符流所操作的数据单元不同,字节流操作的单元是数据单元是 8 位的字节,字符流操作的是数据单元为 16 位的字符。
为什么要有字符流?
Java 中字符是采用 Unicode 标准,Unicode 编码中,一个英文为一个字节,一个中文为两个字节。而在 UTF-8 编码中,一个中文字符是 3 个字节。那么问题来了,如果使用字节流处理中文,如果一次读写一个字符对应的字节数就不会有问题,一旦将一个字符对应的字节分裂开来,就会出现乱码了。为了更方便地处理中文这些字符,Java 就推出了字符流。
字节流和字符流的其他区别?
- 字节流一般用来处理图像、视频、音频、PPT、Word 等类型的文件。字符流一般用于处理纯文本类型的文件,如 TXT 文件等,但不能处理图像视频等非文本文件。用一句话说就是:字节流可以处理一切文件,而字符流只能处理纯文本文件。
- 字节流本身没有缓冲区,缓冲字节流相对于字节流,效率提升非常高。而字符流本身就带有缓冲区,缓冲字符流相对于字符流效率提升就不是那么大了。
1.1.3 节点流和处理流
- 节点流:可以从或向一个特定的地方(节点)读写数据。如 FileReader.
- 处理流:是对一个已存在的流的连接和封装,通过所封装的流的功能调用实现数据读写。如 BufferedReader. 处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
常用的节点流
- 文 件 FileInputStream FileOutputStrean FileReader FileWriter 文件进行处理的节点流。
- 字符串 StringReader StringWriter 对字符串进行处理的节点流。
- 数 组 ByteArrayInputStream ByteArrayOutputStream CharArrayReader CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
- 管 道 PipedInputStream PipedOutputStream PipedReaderPipedWriter 对管道进行处理的节点流。
常用处理流(关闭处理流使用关闭里面的节点流)
-
缓冲流:BufferedInputStrean BufferedOutputStream BufferedReader BufferedWriter--- 增加缓冲功能,避免频繁读写硬盘。
-
转换流:InputStreamReader OutputStreamReader 实现字节流和字符流之间的转换。
-
数据流 DataInputStream DataOutputStream 等 - 提供将基础数据类型写入到文件中,或者读取出来.
流的关闭顺序
- 一般情况下是:先打开的后关闭,后打开的先关闭
- 另一种情况:看依赖关系,如果流 a 依赖流 b,应该先关闭流 a,再关闭流 b。例如,处理流 a 依赖节点流 b,应该先关闭处理流 a,再关闭节点流 b
- 可以只关闭处理流,不用关闭节点流。处理流关闭的时候,会调用其处理的节点流的关闭方法。
1.2 IO 模型
I/O 模型: 就是用什么样的通道或者说是通信模式和架构进行数据的传输和接收,很大程度上决定 了程序通信的性能。
Java 共支持 3 种网络编程的 I/O 模型: BIO、NIO、AIO 实际通信需求下,要根据不同的业务场景和性能需求决定选择不同的 I/O 模型。
1.2.1 Java BIO
同步并阻塞 (传统阻塞型),服务器实现模式为一个连接一个线程, 即客户端有连接请求时服务器 端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。

1.2.2 Java NIO
Java NIO : 同步非阻塞,服务器实现模式为一个线程处理多个请求 (连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有 I/0 请求就进行处理。
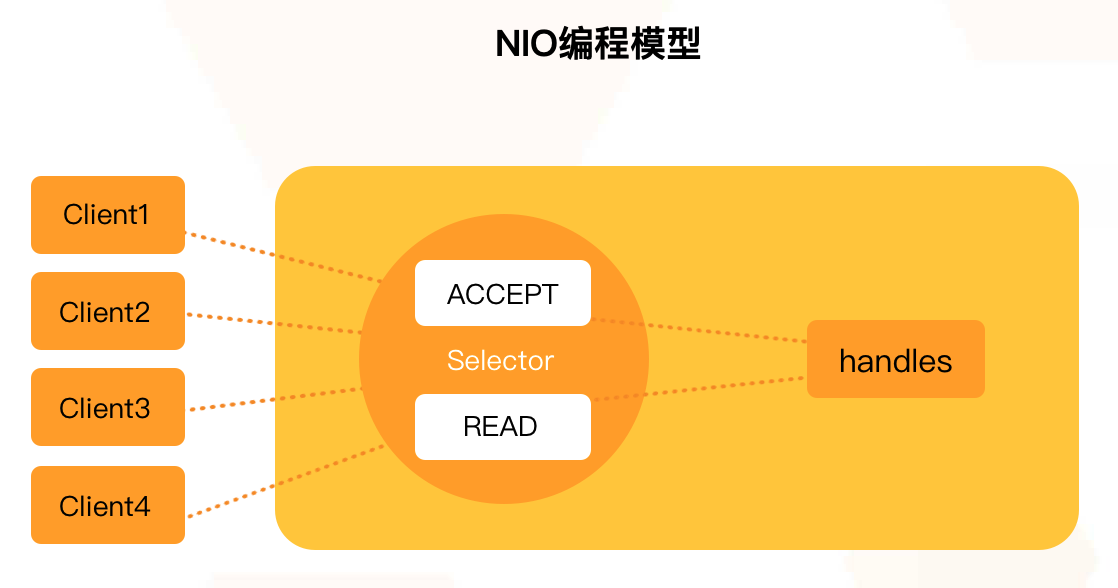
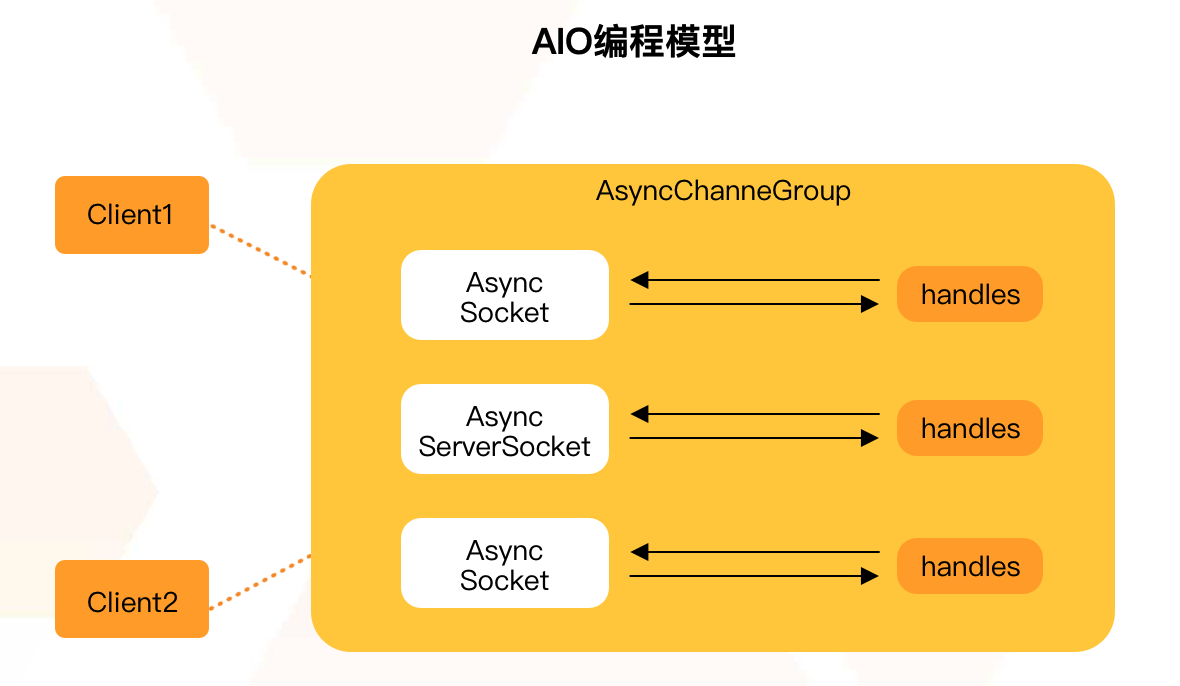
1.2.3 Java AIO
Java AIO(NIO.2) : 异步 异步非阻塞,服务器实现模式为一个有效请求 - 个线程,客户端的 I/O 请 求都是由 OS 先完成了再通知服务器应用去启动线程进行处理,一般适用于连接数较多且连接时间 较长的应用
1.2.4 BIO、NIO、 AIO 适用场景分析
- BIO 方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4 以前的唯一选择, 但程序简单易理解。
- NIO 方式适用于连接数目多且连接比较短 (轻操作) 的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂, JDK1.4 开始支持。当前主流的编程模型。
- AIO 方式使用于连接数目多且连接比较长 (重操作) 的架构,比如相册服务器,充分调用 OS 参与并发操作,编程比较复杂,JDK7 开始支持。
2. 序列化和反序列化
2.1 为什么需要序列化
答:保存 (持久化) 对象及其状态到内存或者磁盘。
Java 平台允许我们在内存中创建可复用的 Java 对象,但一般情况下,只有当 JVM 处于运行时,这些对象才可能存在,即:这些对象的生命周期不会比 JVM 的生命周期更长。但在现实应用中,就可能要求在 JVM 停止运行之后能够保存 (持久化) 指定的对象,并在将来重新读取被保存的对象,Java 对象序列化就能够帮助我们实现该功能。
2.2 如何序列化对象
序列化对象将以字节数组的形式保存,所以静态成员不会被保存。使用 Java 对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的” 状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
序列化对象实现远程数据传输
除了在持久化对象时会用到对象序列化之外,当使用 RMI(远程方法调用),或在网络中传递对象时,都会用到对象序列化。Java 序列化 API 为处理对象序列化提供了一个标准机制,该 API 简单易用。
Serializable 实现序列化
在 Java 中,只要一个类实现了 java.io.Serializable 接口,那么它就可以被序列化。ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化。通过 ObjectOutputStream 和 ObjectInputStream 对对象进行序列化及反序列化。writeObject 和 readObject 自定义序列化策略在类中增加 writeObject 和 readObject 方法可以实现自定义序列化策略。
序列化 ID
其实,这个序列化 ID 起着关键的作用,它决定着是否能够成功反序列化。简单来说,Java 的序列化机制是通过在运行时判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地实体类中的 serialVersionUID 进行比较,如果相同则认为是一致的,便可以进行反序列化,否则就会报序列化版本不一致的异常。
虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID),当 ID 一致时才可以被反序列化。
transient 关键字
Transient 关键字阻止该变量被序列化到文件中。
- 在变量声明前加上 Transient 关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
- 服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
2.2 反序列化
反序列化就是序列化的反向操作,将二进制的数据转换成对内存中对象的过程。
![[UUCTF 2022 新生赛]ez_rce](https://img-blog.csdnimg.cn/direct/1d2d444b37fc45abbafed936622a4be3.png#pic_center)