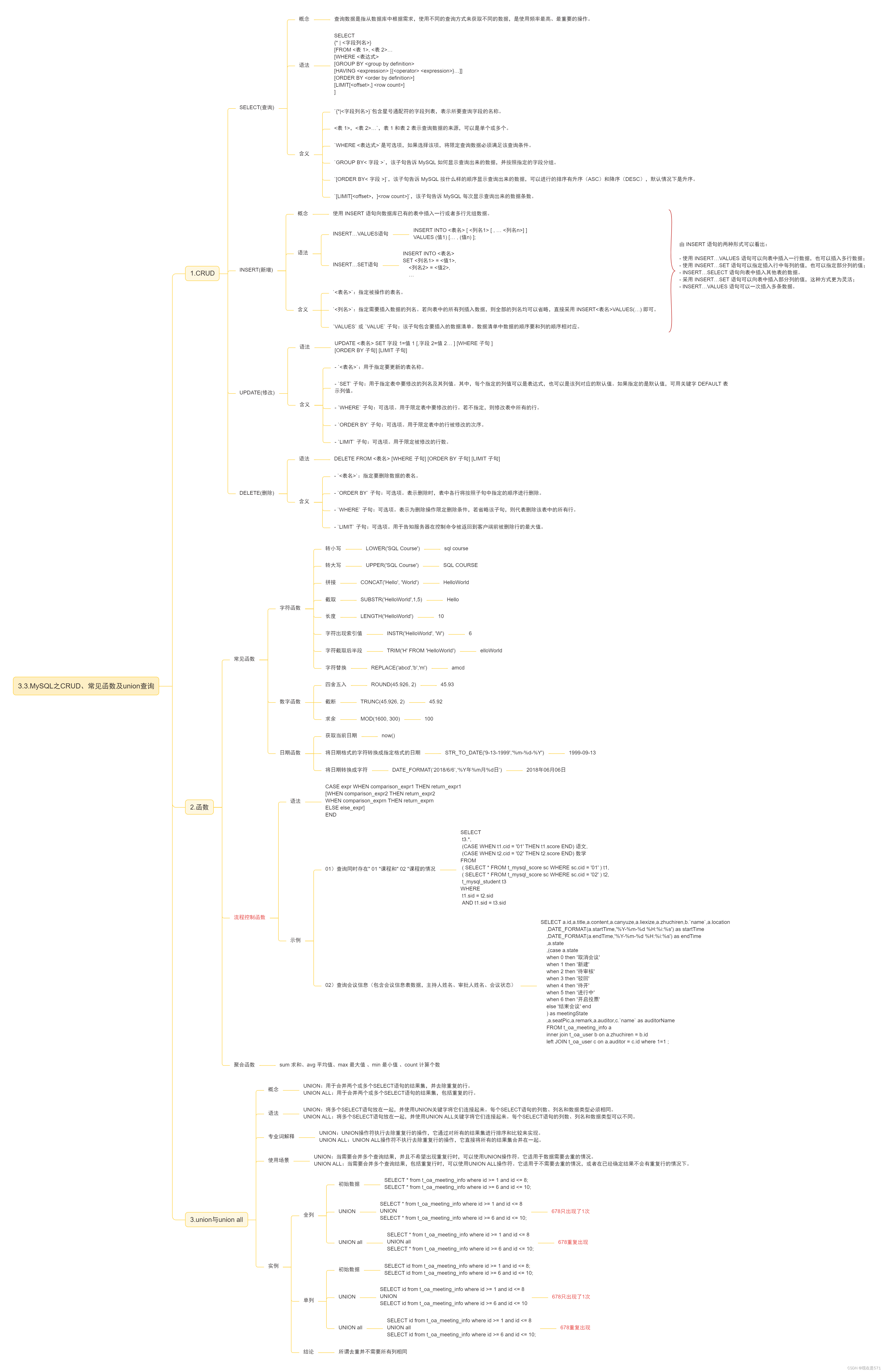
尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试资格,遇到很多关于RocketMQ 的、很重要的面试题:
如何保证RocketMQ消息有序?
RocketMQ 顺序消息,底层原理是什么?
这些题目是非常常见的面试题,回答的时候 有两个层面
- 第一个层面:应用 开发层
- 第二个层面:底层 源码层
第一个层面开发层面的回答,参考答案请参见尼恩《技术自由圈》前面的一篇文章
阿里面试:如何保证RocketMQ消息有序?如何解决RocketMQ消息积压?
一般来说,能够回答到上面的层次,已经非常牛掰了。
但是,如果能够更上一层楼,去到第二个层面:底层 源码层,能从Rocketmq源码层去解答,那就更加让面试官 “不能自已、口水直流、震惊不已”,当然,实现”offer直提”,“offer自由”。
这里,尼恩这道面试题以及第二个层面的参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V156版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
特别提示,尼恩的3高架构宇宙,尼恩Java面试宝典,都是持续升级。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取
文章目录
- 尼恩说在前面
- 回顾: 什么是顺序消息
- 1、分区有序消息
- 2、全局有序消息
- 应用开发层的实现
- 第一个阶段:消息发送有序
- 第二个阶段:消息消费有序
- 源码层:4把锁,保证消息的有序性
- 第一把锁:broker端的分布式锁
- 第二把锁:broker端的全局锁
- 本地消费的两级锁
- 消费者自动负载均衡(再平衡)
- 客户端获取分布式锁:
- RebalanceImpl#lockAll()发送同步请求 ,加上分布式锁
- 消息拉取服务 pullMessageService
- ConsumeMessageOrderlyService 有序消息消费
- 4级锁的总结
- 注意消息的积压
- 说在最后:有问题可以找老架构取经
- 尼恩技术圣经系列PDF
回顾: 什么是顺序消息
一条订单产生的三条消息:订单创建、订单付款、订单完成。
上面三消息是有序的,消费时要按照这个顺序依次消费才有意义,但是不同的订单之间这些消息是可以并行消费的。
什么是顺序消息?顺序消息是指对于一个指定的 Topic ,消息严格按照先进先出(FIFO)的原则进行消息发布和消费,即先发布的消息先消费,后发布的消息后消费。
顺序消息分为两种:
- 分区有序消息
- 全局有序消息
1、分区有序消息
对于指定的一个 Topic ,所有消息根据 Sharding Key 进行区块分区,同一个分区内的消息按照严格的先进先出(FIFO)原则进行发布和消费。
同一分区内的消息保证顺序,不同分区之间的消息顺序不做要求。
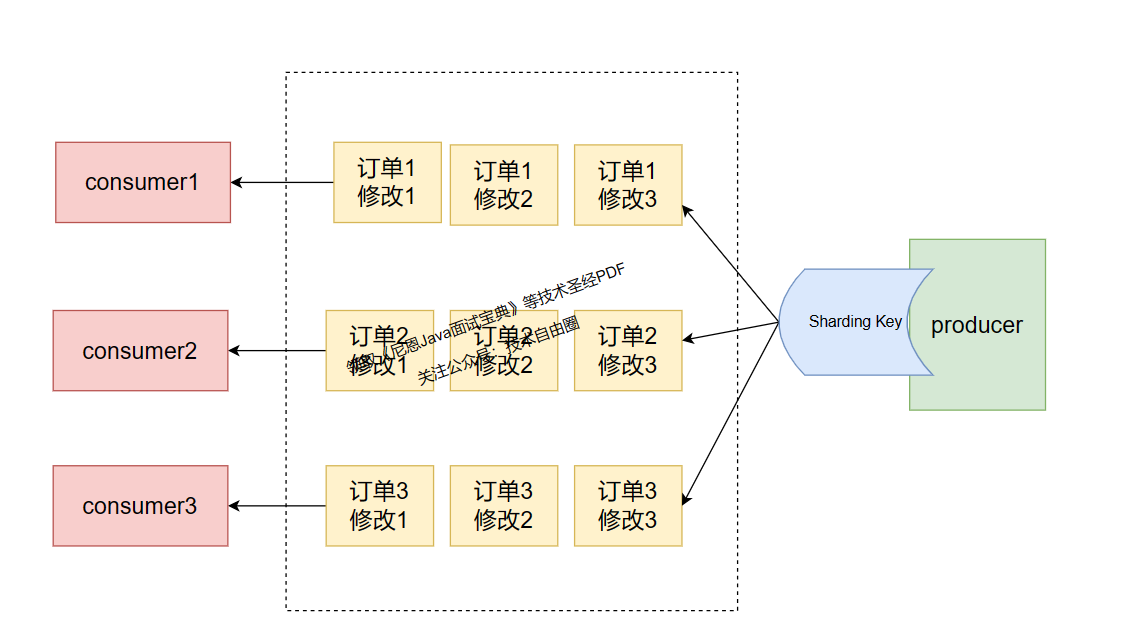
- 适用场景:适用于性能要求高,以 Sharding Key 作为分区字段,在同一个区块中严格地按照先进先出(FIFO)原则进行消息发布和消费的场景。
- 示例:电商的订单创建,以订单 ID 作为 Sharding Key ,那么同一个订单相关的创建订单消息、订单支付消息、订单退款消息、订单物流消息都会按照发布的先后顺序来消费。
2、全局有序消息
对于指定的一个 Topic ,所有消息按照严格的先入先出 FIFO 的顺序来发布和消费。
全局顺序消息实际上是一种特殊的分区顺序消息,即 Topic 中只有一个分区。
因此**:全局顺序和分区顺序的实现原理相同**,区别在于分区数量上。
因为分区顺序消息有多个分区,所以分区顺序消息比全局顺序消息的并发度和性能更高。
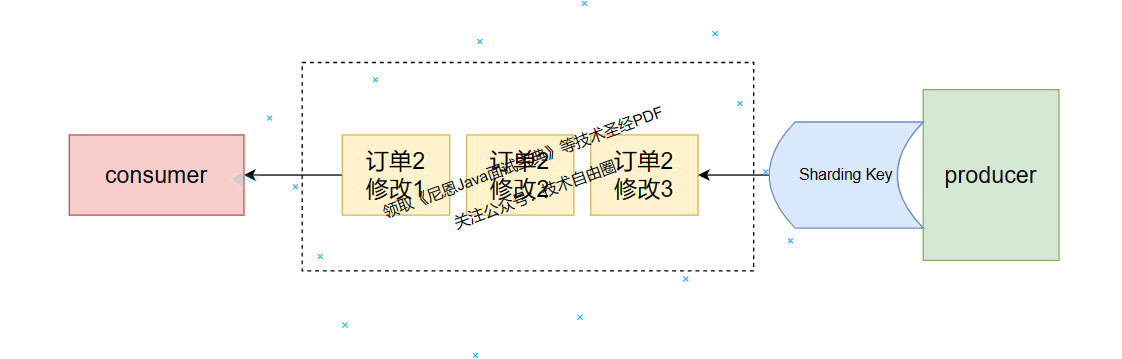
- 适用场景:适用于性能要求不高,所有的消息严格按照 FIFO 原则来发布和消费的场景。
- 示例:在证券处理中,以人民币兑换美元为 Topic,在价格相同的情况下,先出价者优先处理,则可以按照 FIFO 的方式发布和消费全局顺序消息。
应用开发层的实现
如何实现消息有序?
实现顺序消息所必要的条件:顺序发送、顺序存储、顺序消费。
顺序存储环节,RocketMQ 里的分区队列 MessageQueue 本身是能保证 FIFO 的。
所以,在应用开发过程中,不能顺序消费消息主要有两个原因:
- 顺序发送环节,消息发生没有序:Producer 发送消息到 MessageQueue 时是轮询发送的,消息被发送到不同的分区队列,就不能保证 FIFO 了。
- 顺序消费环节,消息消费无序:Consumer 默认是多线程并发消费同一个 MessageQueue 的,即使消息是顺序到达的,也不能保证消息顺序消费。
我们知道了实现顺序消息所必要的条件:顺序发送、顺序存储、顺序消费。顺序存储 由 Rocketmq 完成,所以,在应用开发层, 消息的顺序需要由两个阶段保证:
-
消息发生有序
-
消息消费有序

第一个阶段:消息发送有序
很简单,顺序消息发送时, RocketMQ 支持将 Sharding Key 相同(例如同一订单号)的消息序路由到一个队列中。
在应用开发层面,要实现顺序消息发送时,主要涉及到一个组件: 有序分区选择器 MessageQueueSelector 接口
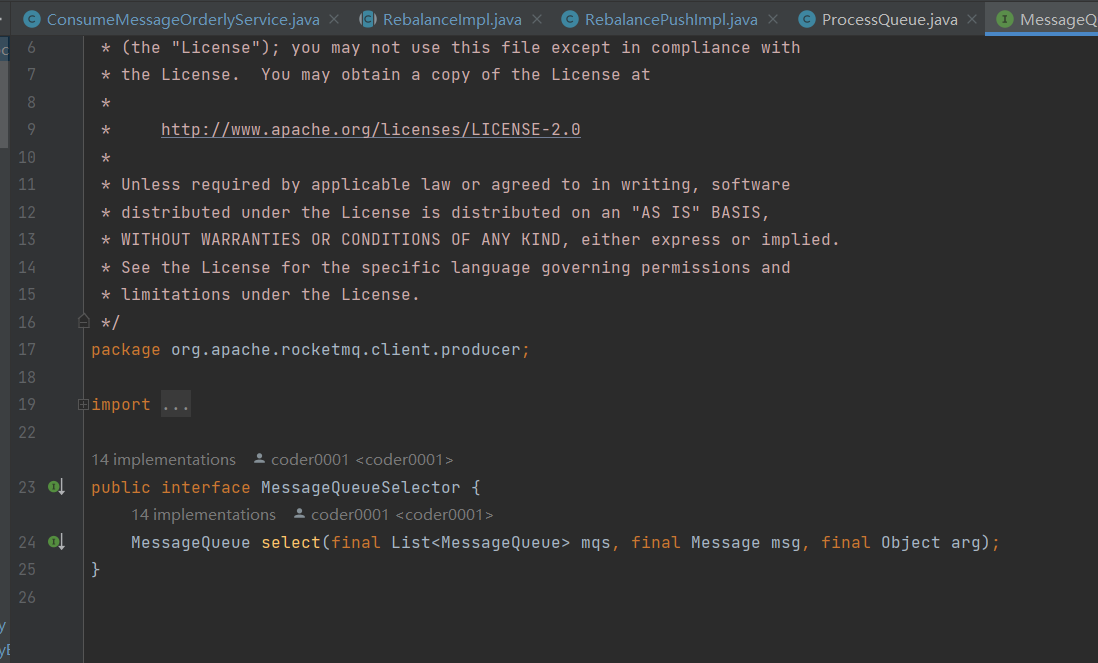
select 三个参数:
- mqs 是可以发送的队列,
- msg是消息,
- arg是上述send接口中传入的Object对象,
select 返回的是该消息需要发送到的队列。
生产环境中建议选择最细粒度的分区键进行拆分,例如,将订单ID、用户ID作为分区键关键字,可实现同一终端用户的消息按照顺序处理,不同用户的消息无需保证顺序。
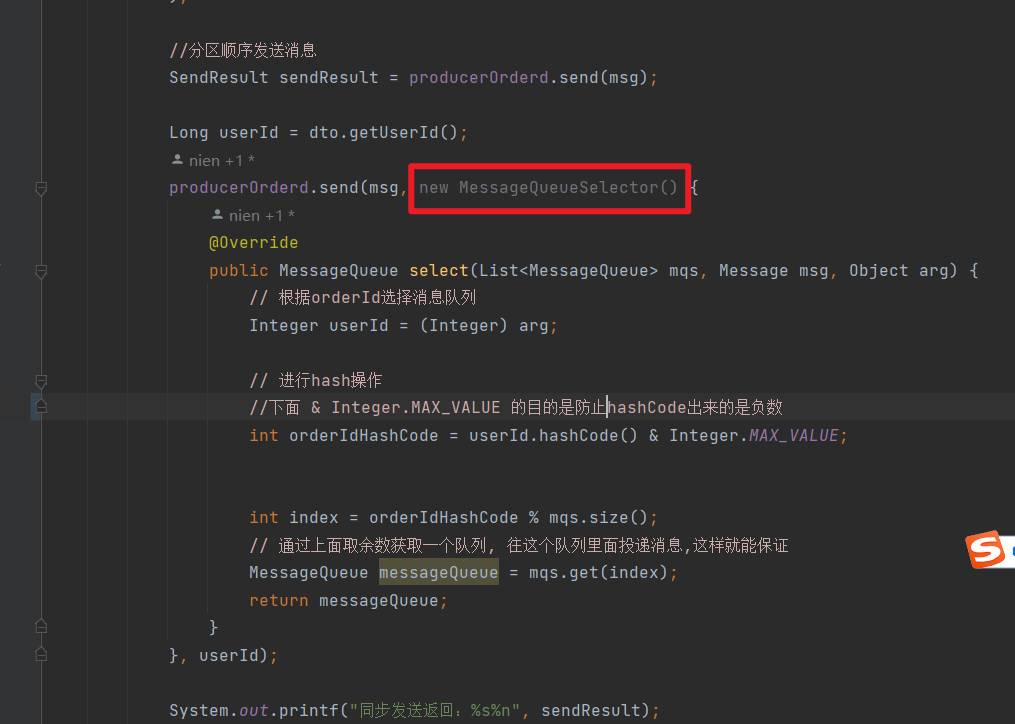
上述例子里,是以userid 作为分区分类标准,对所有队列个数取余,来对将相同userid 的消息发送到同一个队列中。
注意,先hash再取模,防止 不同的分区 发生数据倾斜。防止:没有hash会不均匀度,导致消费者有的 饿的饿死,汗的汗死。
第二个阶段:消息消费有序
消息的顺序需要由两个阶段保证:
- 消息发送有序
- 消息消费有序
RocketMQ 消费过程包括两种,分别是并发消费和有序消费
-
并发消费
并发消费的接口 MessageListenerConcurrently
并发消费是 RocketMQ 默认的处理方法,
并发消费 场景,消费者使用线程池技术,可以并发消费多条消息,提升机器的资源利用率。
默认配置是 20 个线程,所以一台机器默认情况下,同一瞬间可以消费 20 个消息。
-
有序消费 MessageListenerOrderly
有序消费模式 的接口是,MessageListenerOrderly。
在消费的时候,还需要保证消费者注册MessageListenerOrderly类型的回调接口,去实现顺序消费,如果消费者采用Concurrently并行消费,则仍然不能保证消息消费顺序。
MessageListenerOrderly 有序消息监听器

下面是一个例子:
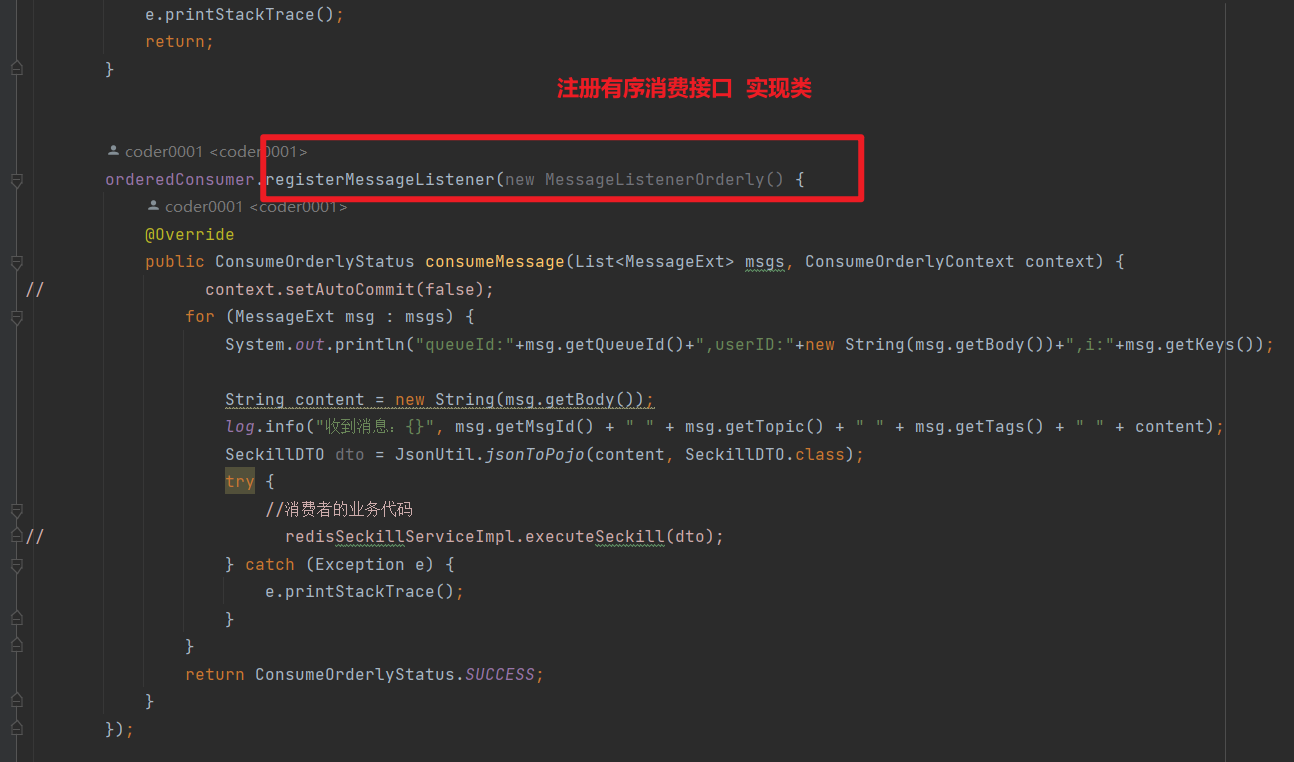
顺序消费的事件监听器为 MessageListenerOrderly,表示顺序消费。
- 并发消费消息时,当消费失败时,会默认延迟重试16次。
- 有序消费消息时,重试次数为 Integer.MAX_VALUE,而且不延迟。
换言之,有序消费场景,如果某一条消息消费失败且重试始终失败,将会导致后续的消息无法消费,产生消息的积压。
所以,顺序消费消息时,一定要谨慎处理异常情况。防止消息队列积压。
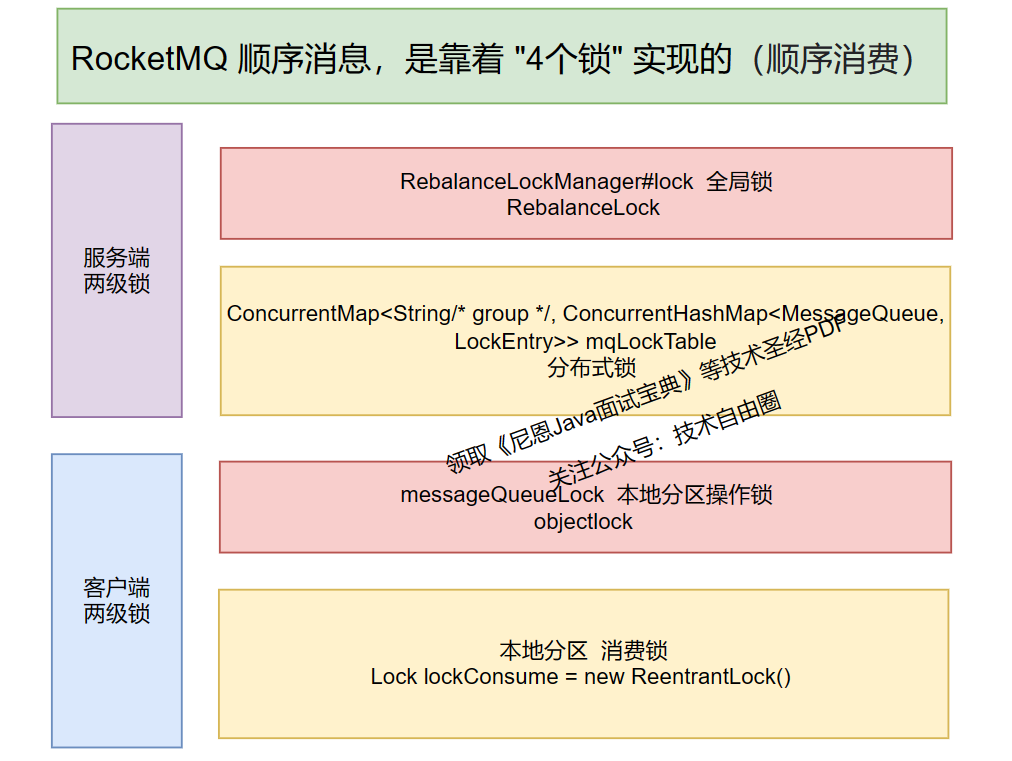
源码层:4把锁,保证消息的有序性
特别说明:
在生产端,所有消息根据 ShardingKey 进行分区,相同 ShardingKey 的消息必须被发送到同一个分区。
所以,生产端的有序性,在源码层不需要太多处理。
在源码层只需要关心 消费的有序处理就行。要实现消息的顺序消费,至少要达到两个条件:
- 第一个条件:一个分区,只能投递给同一个客户端
- 第二个条件:一个客户端,只能同时一个线程去执行消息的消费。
第一个条件:一个分区,只能投递给同一个客户端。怎么实现呢?使用分布式锁去实现。
第二个条件:同一个客户端,只能同时一个线程去执行消息的消费。怎么实现呢?使用本地消费锁去实现。
另外,光两个锁还不够,RocketMQ 为了实现 broker 服务端分布式锁的操作安全,以及本地的操作安全,还使用了额外的两把锁去做加强,
所以,为了保证有序消息的有序投递,一共用了4把锁。
4把锁,保证消息的有序性,具体如下图所示:
第一把锁:broker端的分布式锁
正常的逻辑,如果保证一个分区,分配到也仅仅分配到一个client,就需要布式锁,比如redis分布式锁。
RocketMQ没有用redis分布式锁,而是自研分布式锁,在broker中设置分布式锁,所以broker直接充当redis这些角色而已。
所以,在 RocketMQ 的 broker端:
- 通过分布式锁,实现一个分区 queue 绑定到一个消费者client,
- 并且 broker 设置一个专门的管理器,来管理分布式锁。
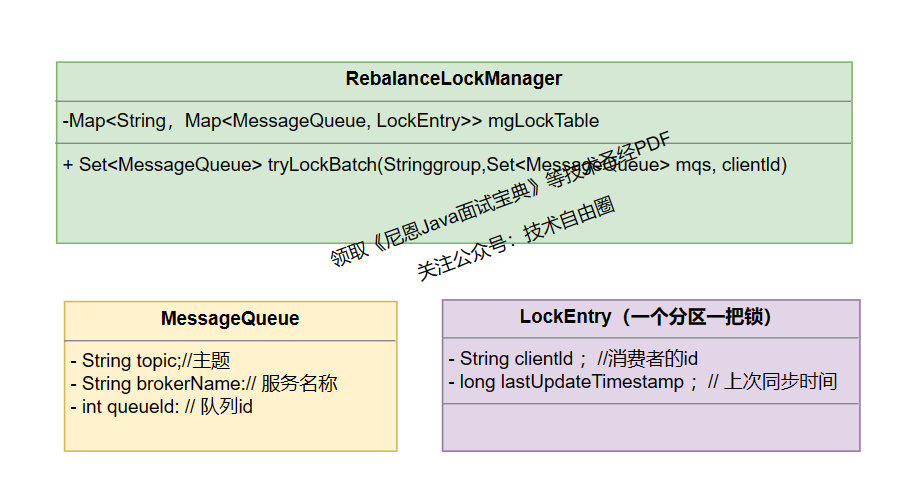
broker端的分布式锁通过 RebalanceLockManager 管理,存储结构为
ConcurrentMap<String/* group */, ConcurrentHashMap<MessageQueue, LockEntry>>,
该分布式锁保证:
同一个consumerGroup下同一个messageQueue只会被分配给一个consumerClient。
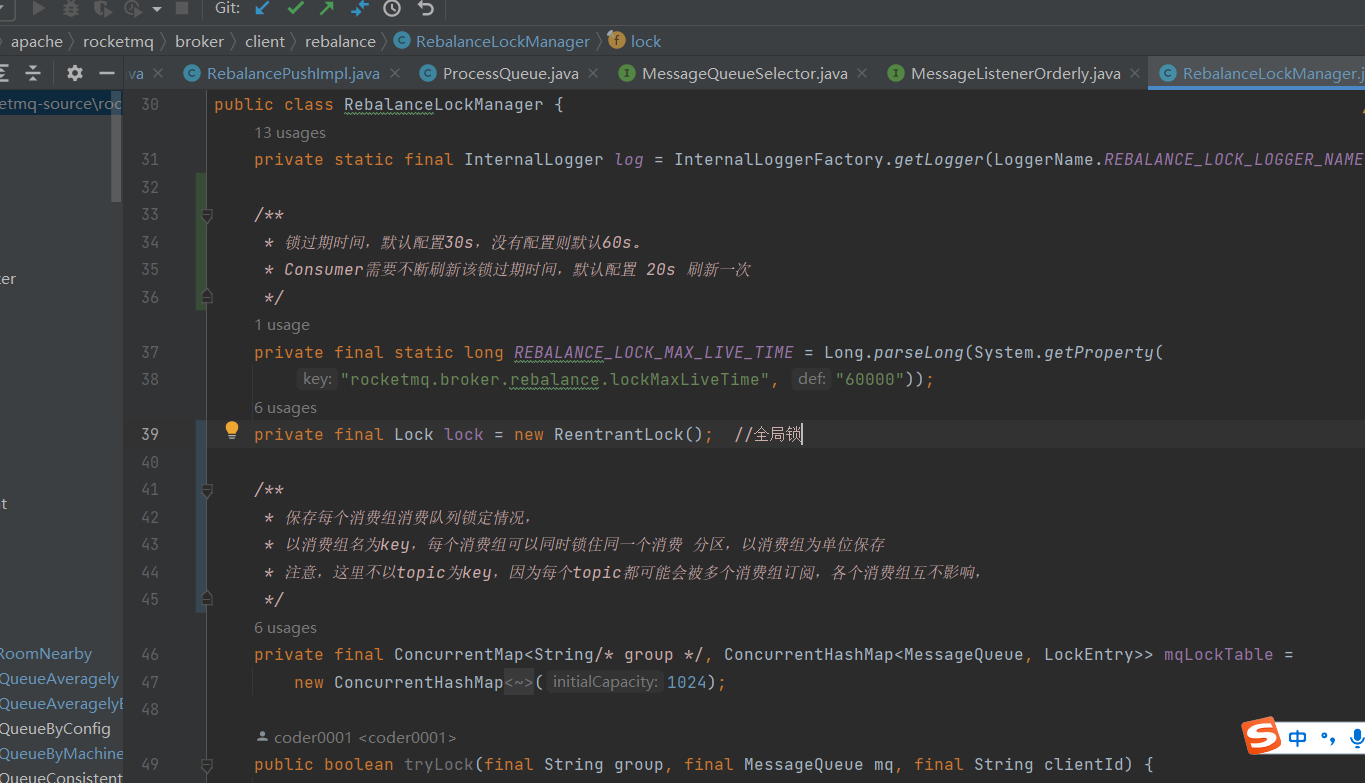
客户端, 在开始拉消息之前,首先要获取 queue的 分布式锁。
如何获取 queue的 分布式锁呢? 客户端会通过rpc 命令去发送获取 queue的 分布式锁的请求,
这个命令,在Broker端,锁定队列的请求由AdminBrokerProcessor处理器的lockBatchMQ 方法去 处理
/**
* 批量锁队列请求
*/
private RemotingCommand lockBatchMQ(ChannelHandlerContext ctx,
RemotingCommand request) throws RemotingCommandException {
final RemotingCommand response = RemotingCommand.createResponseCommand(null);
LockBatchRequestBody requestBody = LockBatchRequestBody.decode(request.getBody(), LockBatchRequestBody.class);
// 通过再平衡锁管理器去锁消息队列,返回锁定成功的消费队列
// 锁定失败就代表消息队列被别的消费者锁住了并且还没有过期
Set<MessageQueue> lockOKMQSet = this.brokerController.getRebalanceLockManager().tryLockBatch(
requestBody.getConsumerGroup(),
requestBody.getMqSet(),
requestBody.getClientId());
LockBatchResponseBody responseBody = new LockBatchResponseBody();
// 将锁定成功的队列响应回去
responseBody.setLockOKMQSet(lockOKMQSet);
response.setBody(responseBody.encode());
response.setCode(ResponseCode.SUCCESS);
response.setRemark(null);
return response;
}
然后调用RebalanceLockManager 管理器的的tryLockBatch 方法,获取对应的分布式锁。
public Set<MessageQueue> tryLockBatch(final String group, final Set<MessageQueue> mqs,
final String clientId) {
// 存放:目前已被clientId对应的消费者 锁住的分区
Set<MessageQueue> lockedMqs = new HashSet<MessageQueue>(mqs.size());
// 存放:目前已被clientId 尝试加锁 而 未锁住的分区
Set<MessageQueue> notLockedMqs = new HashSet<MessageQueue>(mqs.size());
for (MessageQueue mq : mqs) {
// 判断分区是否已被clientId对应的消费者锁住
if (this.isLocked(group, mq, clientId)) {
lockedMqs.add(mq);
} else {
notLockedMqs.add(mq);
}
}
//clientId 尝试加锁 而 未锁住的分区 , 存在
if (!notLockedMqs.isEmpty()) {
try {
//进入重入锁,保证 分区 分配的 原子性
this.lock.lockInterruptibly();
try {
// 该消费组下 分区的 分布式锁
ConcurrentHashMap<MessageQueue, LockEntry> groupValue = this.mqLockTable.get(group);
// 如果为空,就创建一个 新的分布式锁
if (null == groupValue) {
groupValue = new ConcurrentHashMap<>(32);
this.mqLockTable.put(group, groupValue);
}
// 对于clientId 锁定的分区,开始尝试去锁定
for (MessageQueue mq : notLockedMqs) {
LockEntry lockEntry = groupValue.get(mq);
// 为空就是该分区 还没被锁定,可以直接 锁定
if (null == lockEntry) {
lockEntry = new LockEntry();
lockEntry.setClientId(clientId);
groupValue.put(mq, lockEntry);
log.info(
"tryLockBatch, message queue not locked, I got it. Group: {} NewClientId: {} {}",
group,
clientId,
mq);
}
// 如果不为空,之前被我锁住,就更新锁住时间,添加到锁定队列中
if (lockEntry.isLocked(clientId)) {
lockEntry.setLastUpdateTimestamp(System.currentTimeMillis());
lockedMqs.add(mq);
continue;
}
// 到这说明 被别的消费者锁住了
String oldClientId = lockEntry.getClientId();
// 如果过期了就直接换我锁住
if (lockEntry.isExpired()) {
lockEntry.setClientId(clientId);
lockEntry.setLastUpdateTimestamp(System.currentTimeMillis());
log.warn(
"tryLockBatch, message queue lock expired, I got it. Group: {} OldClientId: {} NewClientId: {} {}",
group,
oldClientId,
clientId,
mq);
lockedMqs.add(mq);
continue;
}
//被其他 消费者锁定了,告警
//然后去 抢占下一个 分区的分布式锁
log.warn(
"tryLockBatch, message queue locked by other client. Group: {} OtherClientId: {} NewClientId: {} {}",
group,
oldClientId,
clientId,
mq);
}
} finally {
// 释放重入锁,其他线程,也可以进行 分区的分配
this.lock.unlock();
}
} catch (InterruptedException e) {
log.error("putMessage exception", e);
}
}
return lockedMqs;
}
第二把锁:broker端的全局锁
一个分区配备一把锁,分布式锁this.mqLockTable 是一个 ConcurrentMap。
为了保证分布式锁操作的原子性,brocker设置一个专门的管理器,来管理分布式锁。

所以在broker上是两级锁。
分布式锁this.mqLockTable 是一个 ConcurrentMap
/**
* 保存每个消费组消费队列锁定情况,
* 以消费组名为key,每个消费组可以同时锁住同一个消费 分区,以消费组为单位保存
* 注意,这里不以topic为key,因为每个topic都可能会被多个消费组订阅,各个消费组互不影响,
*/
private final ConcurrentMap<String/* group */, ConcurrentHashMap<MessageQueue, LockEntry>> mqLockTable =
new ConcurrentHashMap<String, ConcurrentHashMap<MessageQueue, LockEntry>>(1024);
为啥需要 额外的全局锁呢?
broker处理RPC命令的线程可不只有一个, 所以这里用一个全局锁,来实现 分布式锁操作的原子性
//进入重入锁,保证 分区 分配的 原子性
//clientId 尝试加锁 而 未锁住的分区 , 存在
if (!notLockedMqs.isEmpty()) {
try {
//进入重入锁,保证 分区 分配的 原子性
this.lock.lockInterruptibly();
操作 分布式锁 this.mqLockTable
....
} finally {
// 释放重入锁,其他线程,也可以进行 分区的分配
this.lock.unlock();
}
}
本地消费的两级锁
消费者消费消息时,需要保证消息消费顺序和存储顺序一致,最终实现消费顺序和发布顺序的一致。
虽然MessageListenerOrderly被称为有序消费模式,但是仍然是使用的线程池去消费消息。实际上,每一个消费者的的消费端都是采用线程池实现多线程消费的模式,即消费端是多线程消费。
MessageListenerConcurrently是拉取到新消息之后就提交到线程池去消费,而MessageListenerOrderly则是通过加分布式锁和本地锁保证同时只有一条线程去消费一个队列上的数据。
一个消费者至少需要涉及队列自动负载、消息拉取、消息消费、位点提交、消费重试等几个部分。其中,与远程分布式锁有关系的是
- 自动负载
- 消息拉取
两级本地锁主要涉及到的是
- 消息消费
- 位点提交
消息消费这块,由于涉及线程池去消费消息,所以需要设置一个专门的消费锁。
对于同一个queue,除了消费之外,还涉及位点提交等,所以,一个分区额外设计一把 分区锁。加起来,在消费者本地,也是两级锁:

消费者自动负载均衡(再平衡)
一个消费者至少需要涉及队列自动负载、消息拉取、消息消费、位点提交、消费重试等几个部分。
与远程分布式锁有关系的是
- 自动负载
- 消息拉取
两级本地锁主要涉及到的是
- 消息消费
- 位点提交
MQClientInstance 客户端实例,会开启多个异步并行服务:
- 负载均衡服务 rebalanceService:再平衡服务, 专门进行 queue分区的 再平衡,再分配
- 消息拉取服务 pullMessageService:专门拉取消息,通过内部实现类DefaultMQPushConsumerImpl 拉取
- 消息消费线程:ConsumeMessageOrderlyService 有序消息消费
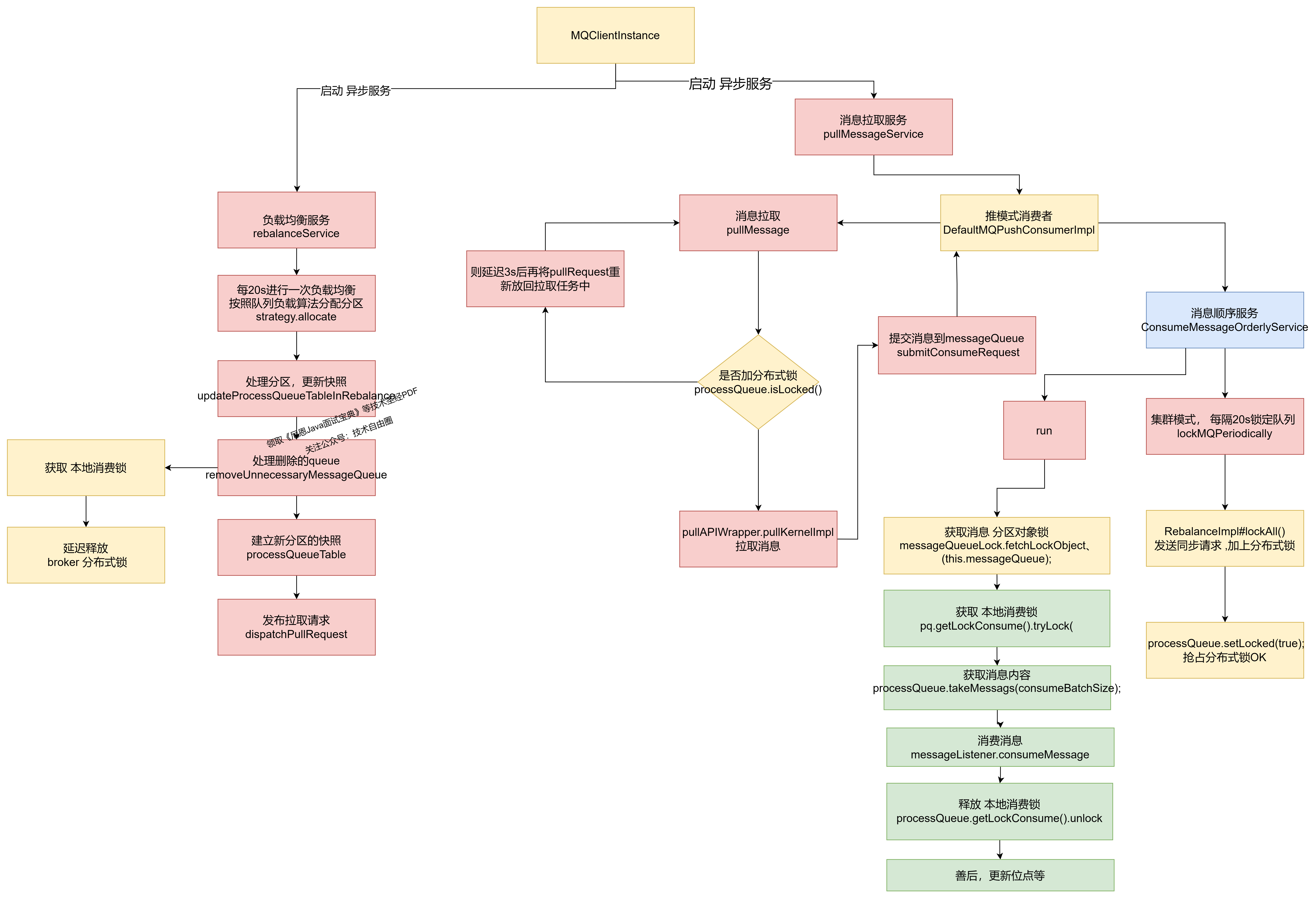
RebalanceService 线程启动后,会以 20s 的频率计算每一个消费组的队列负载。
如果有新分配的队列。这时候 ConsumeMessageOrderlyService 可以尝试向Broker 申请分布式锁
客户端获取分布式锁:
前面三个并行服务,首先发生作用的是rebalanceService 负载均衡服务,负责获取 责任分区。
如果不是 有序消息而是普通消息的话,rebalanceService 负载均衡服务获取到 分区后,就可以开始拉取消息了。
但是有序消息却不行, 还需要先去 获取分布式锁。
这个获取分布式锁的操作, 由另外一个 异步 ConsumeMessageOrderlyService 服务去定期获取,周期是20s。

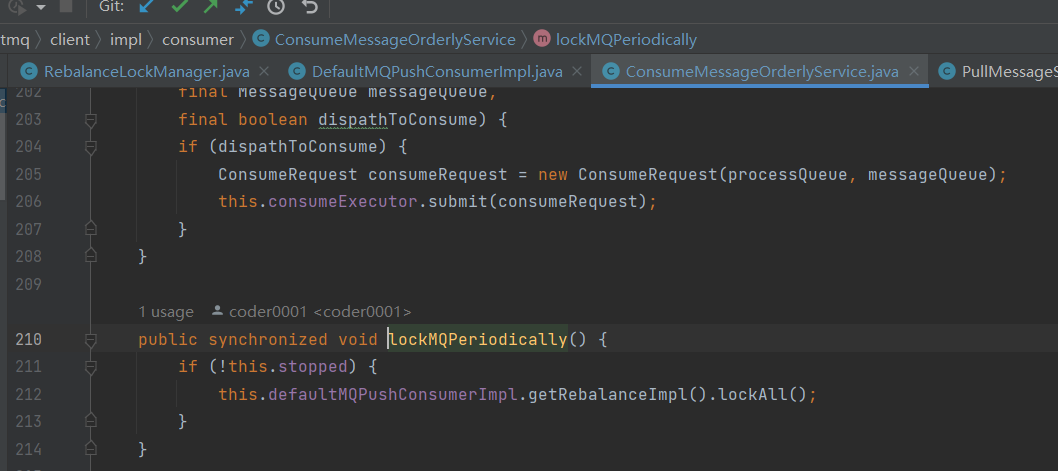
RebalanceImpl#lockAll()发送同步请求 ,加上分布式锁
// 锁定 分配到 MessageQueue 分区
public void lockAll() {
// 查询分配的到的分区
// key为broker名称,value为该消费者在该broker上分配到的消息分区 , 注意,一个topic 可以在多个broker上建立分区
HashMap<String /*BrokerName*/, Set<MessageQueue>> brokerMqs = this.buildProcessQueueTableByBrokerName();
//按照 broker 为单位进行锁定
Iterator<Entry<String, Set<MessageQueue>>> it = brokerMqs.entrySet().iterator();
while (it.hasNext()) {
Entry<String, Set<MessageQueue>> entry = it.next();
final String brokerName = entry.getKey();
final Set<MessageQueue> mqs = entry.getValue();
if (mqs.isEmpty())
continue;
// 向该broker发送 批量锁消息分区的请求
FindBrokerResult findBrokerResult = this.mQClientFactory.findBrokerAddressInSubscribe(brokerName, MixAll.MASTER_ID, true);
if (findBrokerResult != null) {
LockBatchRequestBody requestBody = new LockBatchRequestBody();
requestBody.setConsumerGroup(this.consumerGroup);
requestBody.setClientId(this.mQClientFactory.getClientId());
requestBody.setMqSet(mqs);
try {
// 发送同步请求 ,加上分布式锁
Set<MessageQueue> lockOKMQSet =
this.mQClientFactory.getMQClientAPIImpl().lockBatchMQ(findBrokerResult.getBrokerAddr(), requestBody, 1000);
//迭代锁定的 分区
for (MessageQueue mq : lockOKMQSet) {
// 获取 ProcessQueue (分区消费快照 Queue consumption snapshot)
ProcessQueue processQueue = this.processQueueTable.get(mq);
if (processQueue != null) {
//如果没有 锁定消费快照 ,则消费快照加锁
if (!processQueue.isLocked()) {
log.info("the message queue locked OK, Group: {} {}", this.consumerGroup, mq);
}
processQueue.setLocked(true);
processQueue.setLastLockTimestamp(System.currentTimeMillis());
}
}
for (MessageQueue mq : mqs) {
if (!lockOKMQSet.contains(mq)) {
ProcessQueue processQueue = this.processQueueTable.get(mq);
if (processQueue != null) {
processQueue.setLocked(false);
log.warn("the message queue locked Failed, Group: {} {}", this.consumerGroup, mq);
}
}
}
} catch (Exception e) {
log.error("lockBatchMQ exception, " + mqs, e);
}
}
}
}
获取分布式锁之后,在本地, 设置到 消费快照的 locked 标志
消息拉取服务 pullMessageService
如果不是 有序消息,rebalanceService 负载均衡服务获取到 分区后,就可以开始拉取消息了。
会创建消息去拉取请求,交个消息拉取服务去异步执行。
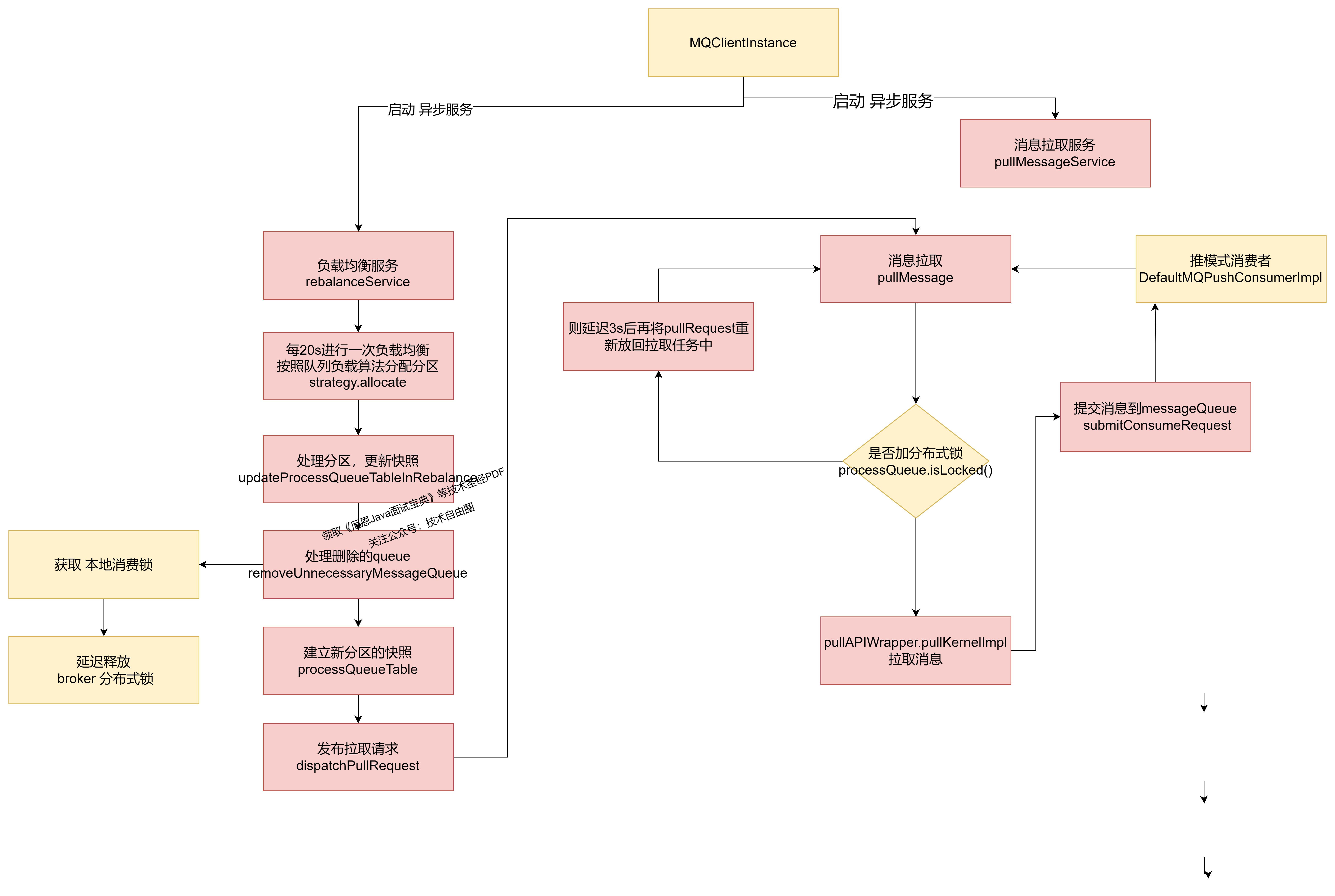
pullMessage 方法中,首先判断有没有分布式锁, 没有就延迟则延迟3s后再将pullRequest重新放回拉取任务中
判断有没有分布式锁,是通过 本地快照的标志位来的。
//对应关系: topic每一个的queue在消费的时候,都会指定一个pullRequest
//可以反向导航: 通过请求,去取得那个 topic的queue
public void pullMessage(final PullRequest pullRequest) {
...这个方法太长了
// 并发消费模式
// 针对于普通消息
if (!this.consumeOrderly) {
....
} else {
// 顺序消费模式
// 针对于顺序消息
// 若是是顺序消息,那么 processQueue 就是须要 上 本地快照 锁
// 必须进行同步操作, 保障在消费端不会出现乱序
if (processQueue.isLocked()) {
// 如果该 消费分区 是第一次拉取消息 lockedFirst = false ,则先计算拉取偏移量
if (!pullRequest.isLockedFirst()) {
// 计算从哪里开始消费
final long offset = this.rebalanceImpl.computePullFromWhere(pullRequest.getMessageQueue());
boolean brokerBusy = offset < pullRequest.getNextOffset();
log.info("the first time to pull message, so fix offset from broker. pullRequest: {} NewOffset: {} brokerBusy: {}",
pullRequest, offset, brokerBusy);
if (brokerBusy) {
log.info("[NOTIFYME]the first time to pull message, but pull request offset larger than broker consume offset. pullRequest: {} NewOffset: {}",
pullRequest, offset);
}
// 设置下次拉取的offSet
pullRequest.setLockedFirst(true);
pullRequest.setNextOffset(offset);
}
} else {
// 如果本地快照 锁 没被锁定,则延迟3s后再将pullRequest重新放回拉取任务中
this.executePullRequestLater(pullRequest, pullTimeDelayMillsWhenException);
log.info("pull message later because not locked in broker, {}", pullRequest);
return;
}
}
...
}
有分布式锁,才拉取消息。
拉取消息后,提交消费。
ConsumeMessageOrderlyService 有序消息消费
前面讲到,MQClientInstance 客户端实例,会开启多个异步并行服务:
- 负载均衡服务 rebalanceService :再平衡服务, 专门进行 queue分区的 再平衡,再分配
- 消息拉取服务 pullMessageService :专门拉取消息,通过内部实现类DefaultMQPushConsumerImpl 拉取
- 消息消费线程 :ConsumeMessageOrderlyService 有序消息消费
客户端与远程分布式锁有关系的是
- 自动负载
- 消息拉取
两级本地锁主要涉及到的是
- 消息消费
- 位点提交
ConsumeMessageOrderlyService 有序消息消费 ,在他run方法中
首先获取分区操作锁, 这个是一个对象锁
然后获取 消费锁, 这是一个 ReentrantLock 锁。
@Override
public void run() {
if (this.processQueue.isDropped()) {
log.warn("run, the message queue not be able to consume, because it's dropped. {}", this.messageQueue);
return;
}
// 获取消息 分区的对象锁
final Object objLock = messageQueueLock.fetchLockObject(this.messageQueue);
synchronized (objLock) {
.....
// 批量消费消息个数
final int consumeBatchSize =
ConsumeMessageOrderlyService.this.defaultMQPushConsumer.getConsumeMessageBatchMaxSize();
// 获取消息内容
List<MessageExt> msgs =
this.processQueue.takeMessags(consumeBatchSize);
.....
}
long beginTimestamp = System.currentTimeMillis();
ConsumeReturnType returnType = ConsumeReturnType.SUCCESS;
boolean hasException = false;
try {
//获取消费锁
this.processQueue.getLockConsume().lock();
....
// 消费消息
status = messageListener.consumeMessage(
Collections.unmodifiableList(msgs), context);
} catch (Throwable e) {
log.warn("consumeMessage exception: {} Group: {} Msgs: {} MQ: {}",
RemotingHelper.exceptionSimpleDesc(e),
ConsumeMessageOrderlyService.this.consumerGroup,
msgs,
messageQueue);
hasException = true;
} finally {
// 释放消息消费锁
this.processQueue.getLockConsume().unlock();
}
.....
}
上面的代码,用到了两级锁:
- 第三级的本地锁 LockObject:queue分区上级别的 操作锁。
这个锁的粒度更大, 不仅仅锁住 消息的消费操作,还锁住了位点的提交,以及持续消费的一批消息的操作。
- 第四级的本地锁: 分区上的快照 消费锁
这个锁的粒度更小, 仅仅锁住 消息的消费操作,保证同一个消息queue 分区上的消息消费,只有一个线程能够执行,保证分区消费的次序不会打乱。
4级锁的总结
我们做一个关于顺序消费的总结:
通过4把锁的机制,消息队列 messageQueue 的数据都会被消费者实例单线程的执行消费;
当然,假如消费者扩容,消费者重启,或者 Broker 宕机 ,顺序消费也会有一定几率较短时间内乱序,所以消费者的业务逻辑还是要保障幂等。
这里还需要考虑broker 锁的异常情况,假如一个broke 队列上的消息被consumer 锁住了,万一consumer 崩溃了,这个锁就释放不了,所以broker 上的锁需要加上锁的过期时间。
注意消息的积压
在使用顺序消息时,一定要注意其异常情况的出现,对于顺序消息,当消费者消费消息失败后,消息队列 RocketMQ 版会自动不断地进行消息重试(每次间隔时间为 1 秒),重试最大值是Integer.MAX_VALUE.这时,应用会出现消息消费被阻塞的情况。
因此,建议您使用顺序消息时,务必保证应用能够及时监控并处理消费失败的情况,避免消息积压现象的发生。
关于消息的积压,参考答案请参见尼恩《技术自由圈》前面的一篇文章
阿里面试:如何保证RocketMQ消息有序?如何解决RocketMQ消息积压?
关于积压监控,请参考尼恩的 《RocketMQ 四部曲视频》,如果能够回答到上面的层次,已经非常牛掰了。
尼恩的 《RocketMQ 四部曲视频》,从架构师视角揭秘 RocketMQ 的架构哲学,让大家彻底的了解这个高深莫测 RocketMQ 组件的宏观架构,提升大家的架构水平和设计水平。
说在最后:有问题可以找老架构取经
RocketMQ 相关的面试题,是非常常见的面试题。
以上的内容,如果大家能对答如流,如数家珍,基本上 面试官会被你 震惊到、吸引到。
最终,让面试官爱到 “不能自已、口水直流”。offer, 也就来了。
在面试之前,建议大家系统化的刷一波 5000页《尼恩Java面试宝典PDF》,里边有大量的大厂真题、面试难题、架构难题。很多小伙伴刷完后, 吊打面试官, 大厂横着走。
在刷题过程中,如果有啥问题,大家可以来 找 40岁老架构师尼恩交流。
另外,如果没有面试机会,可以找尼恩来改简历、做帮扶。
尼恩指导了大量的小伙伴上岸,前段时间,刚指导一个40岁+被裁小伙伴,拿到了一个年薪100W的offer。
尼恩技术圣经系列PDF
- 《NIO圣经:一次穿透NIO、Selector、Epoll底层原理》
- 《Docker圣经:大白话说Docker底层原理,6W字实现Docker自由》
- 《K8S学习圣经:大白话说K8S底层原理,14W字实现K8S自由》
- 《SpringCloud Alibaba 学习圣经,10万字实现SpringCloud 自由》
- 《大数据HBase学习圣经:一本书实现HBase学习自由》
- 《大数据Flink学习圣经:一本书实现大数据Flink自由》
- 《响应式圣经:10W字,实现Spring响应式编程自由》
- 《Go学习圣经:Go语言实现高并发CRUD业务开发》
……完整版尼恩技术圣经PDF集群,请找尼恩领取
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》PDF,请到下面公号【技术自由圈】取↓↓↓





![[电子榨菜]状态管理redux,以及react-redux](https://img-blog.csdnimg.cn/direct/ee68ba1740bf4fc2aea642a5f7135129.png)