目录
C++11简介
统一的列表初始化
{}初始化
std::initializer_list
std::initializer_list使用场景:
声明
auto
decltype
nullptr
范围for循环
STL中一些变化
新容器
array容器
forward_list容器
容器中的一些新方法
C++11简介
C++11相关文档
统一的列表初始化
{}初始化
在C++98中,标准允许使用花括号{}对数组或者结构体元素进行统一的列表初始值设定。比如:
struct A
{
int _x;
int _y;
};
int main()
{
int array1[] = { 1, 2, 3, 4, 5 };
int array2[5] = { 0 };
A p = { 1, 2 };
return 0;
}struct A
{
int _x;
int _y;
};
int main()
{
int x1 = 1;
// 要能看懂,但是不建议使用
int x2 = { 2 };
int x3{ 2 };
// 要能看懂,但是不建议使用
int array1[]{ 1, 2, 3, 4, 5 };
int array2[5]{ 0 };
A p{ 1, 2 };
// C++11中列表初始化也可以适用于new表达式中
int* pa = new int[4]{ 0 };
return 0;
}// 日期类
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
// 都是在调用构造函数
Date d1(2022, 12, 31);
// C++11 要能看懂,但是不建议使用
Date d2 = { 2022, 12, 31 }; // ->调用构造函数
Date d3{ 2022, 12, 31 };
return 0;
}std::initializer_list
上面的{}使用添加,甚至可添加等号(=),也可不添加的使用方式,更多的是为了此种方式的使用而开发的。只是给上面的也配置了,然而这,对于上面的普通使用就会显得十分臃肿,所以上面并不建议使用C++11扩大的{}使用规制。
概念引入:
对于STL所封装的容器是支持一下的使用方法的:
#include<vector>
#include<list>
using namespace std;
int main()
{
vector<int> v1 = { 1, 2, 3, 4, 5, 6 };
vector<int> v2 { 1, 2, 3, 4, 5, 6 };
list<int> lt1 = { 1, 2, 3, 4, 5, 6 };
list<int> lt2{ 1, 2, 3, 4, 5, 6 };
return 0;
}这难道是因为为{}搞了一个operator{}重载吗?并不是的,因为{}是不属于运算符,所以并不可能是运算符重载,而是为{}封装成了一个类型:
#include<iostream>
#include<vector>
#include<list>
using namespace std;
int main()
{
auto a = { 1, 2, 3, 4, 5, 6 }; // 利用auto将a变为{}的类型
cout << typeid(a).name() << endl; // 打印出a类型,即{}的类型
return 0;
}
std::initializer_list使用场景:
initializer_list的相关文档
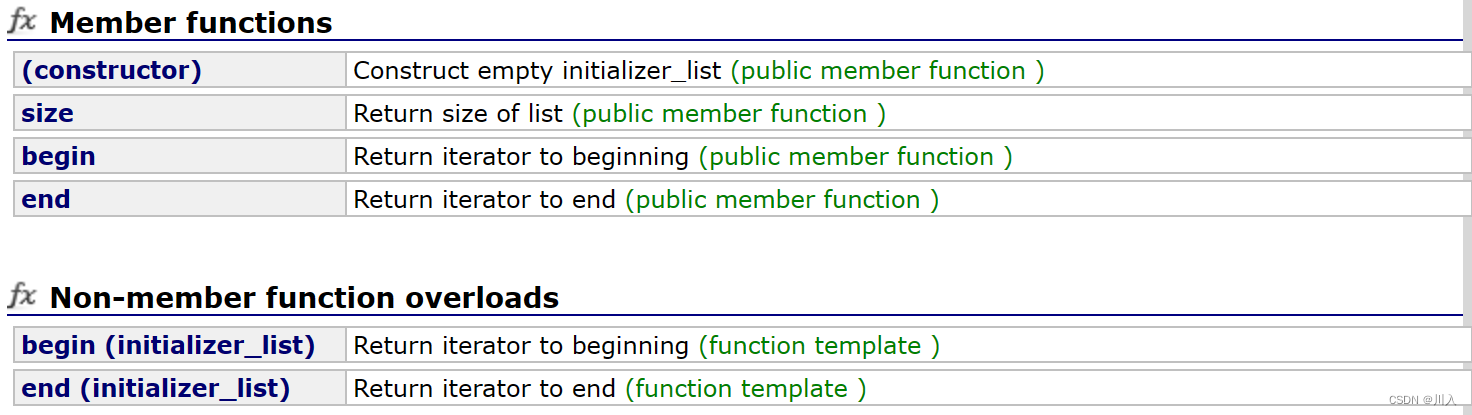
在initializer_list的封装里拥有begin,end。可以说是将initializer_list封装成了一个迭代器,而STL中容器就是利用此,通过调用构造函数利用initializer_list所封装的迭代器进行初始化。(该构造函数为C++11新增)。对于operator=也是同理:
(以list容器举例:)
list的构造函数的相关文档
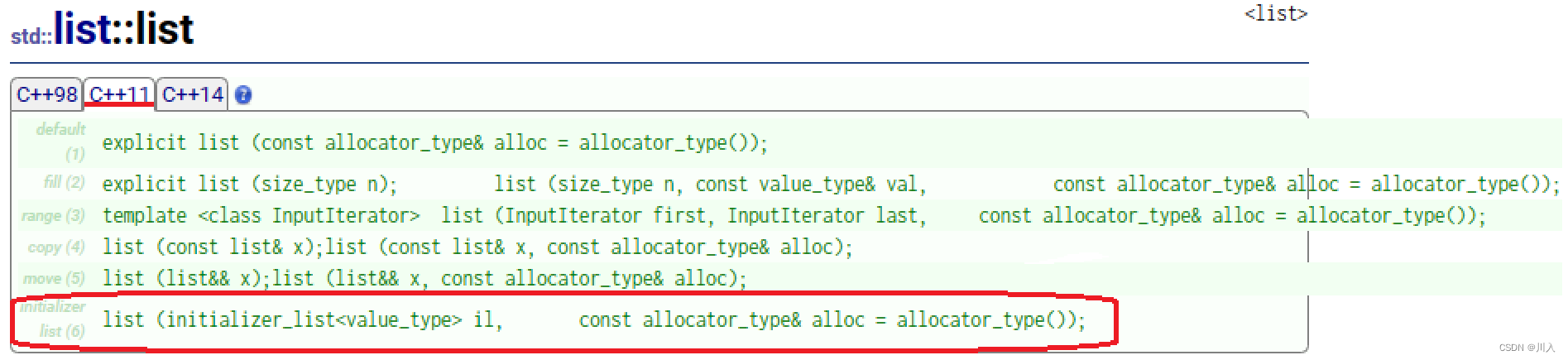
list的operator=的相关文档

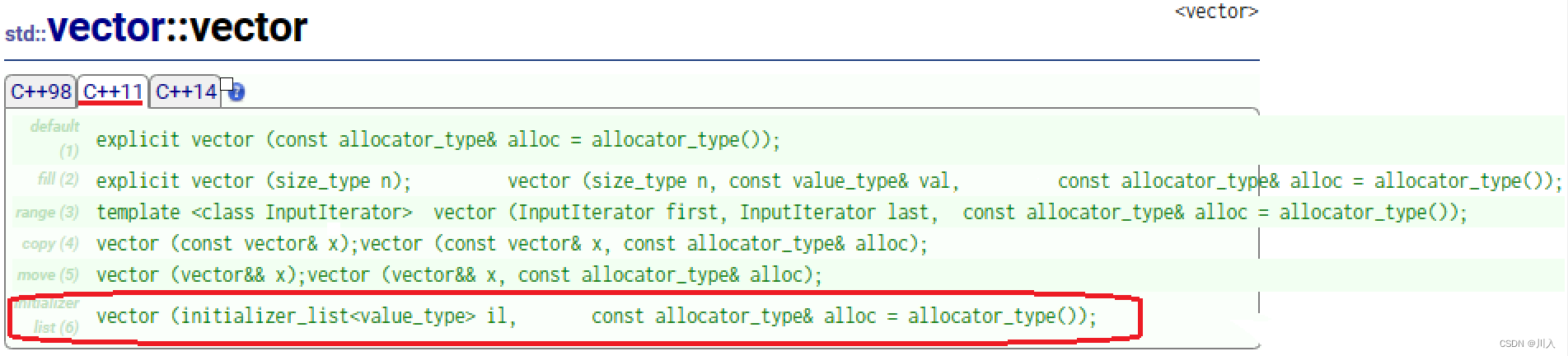

- std::initializer_list一般是作为构造函数的参数,C++11对STL中的不少容器就增加
- std::initializer_list作为参数的构造函数,这样初始化容器对象就更方便了。也可以作为operator=的参数,这样就可以用大括号赋值。
在C++98支持的对于自定义对象,支持多个同类型的数据初始化:
#include<vector>
using namespace std;
// 日期类
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
Date d1(2022, 12, 31);
Date d2(2022, 12, 31);
Date d3(2022, 12, 31);
vector<Date> v = { d1, d2, d3 };
return 0;
}而C++11有了对于{}的支持,也就有了一下的使用方法:
#include<iostream>
#include<vector>
using namespace std;
// 日期类
class Date
{
public:
Date(int year, int month, int day)
:_year(year)
, _month(month)
, _day(day)
{
cout << "Date(int year, int month, int day)" << endl;
}
private:
int _year;
int _month;
int _day;
};
int main()
{
vector<Date> v = { {2022, 12, 31},{2022, 1, 1} };
return 0;
}这样的支持其实是相当于隐式类型的转换了。在C++98里面是单参数的构造函数支持隐式类型的转换,现在相当于多参数的构造函数也支持隐式类型的转换了。
#include<string>
using namespace std;
int main()
{
// 单参数的构造函数支持隐式类型的转换:string支持了一个char*
string str = "123456789";
return 0;
}其本质是:利用“123456789”构造了一个匿名对象的string,然后再拷贝构造给str。编译器一看,在一个步骤里面,于是直接进行了优化:直接变成构造,即:隐式类型的转换。
同样的道理,再拥有{}的使用之后,也就支持 {2022, 12, 31} 隐式类型的转换。其,其实也是先构造了一个匿名对象的Date,然后再拷贝构造给v。编译器直接优化:直接变成构造。不用写为:vector<Date> v = { d1, d2, d3 }; 而直接写为;vector<Date> v = { {2022, 12, 31}, {2022, 1, 1} }; 即,其会调用隐式类型的转换。
执行:上面的 vector<Date> v = { {2022, 12, 31},{2022, 1, 1} }; 代码:
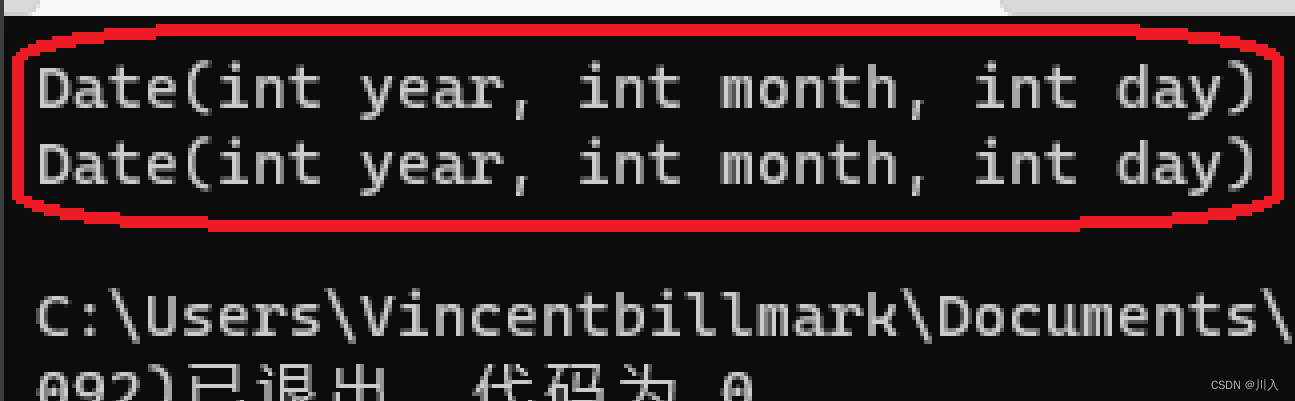
这就是C++11添加{}用法的主要原因,支持了多参数的隐式类型的转换,使得使用更加方便:
#include<map>
#include<string>
using namespace std;
int main()
{
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
return 0;
}此处是两层的支持:
- map支持了initializer_list的构造
- initializer_list是每个地方的数据{"sort", "排序"},其又是一个pair,pair又支持链表的初始化,是匿名对象再拷贝构造的优化,直接调用构造,每一个{"sort", "排序"}单位都是调用一个pair构造,多参数的隐式类型的转换。
#include<map>
#include<string>
using namespace std;
int main()
{
// 构造
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
// 赋值重载
dict = { {"erase", "删除"}, {"find", "寻找"} };
return 0;
}note:
C++1{}初始化的使用添加,使得在C++11之后的一切对象都可以用列表初始化,但是不建议普通对象进行使用,普通对象建议还是使用以前的方式。对于容器如果有需求,在容器初始化的时候是有其的价值的。
声明
c++11提供了多种简化声明的方式,尤其是在使用模板时。
auto
#include<iostream>
#include<map>
#include<string>
using namespace std;
int main()
{
int i = 10;
auto p = &i;
auto pf = strcpy;
cout << typeid(p).name() << endl;
cout << typeid(pf).name() << endl;
// 对于过于复杂的类型,可以不用写直接使用auto让编译器自行推测
map<string, string> dict = { {"sort", "排序"}, {"insert", "插入"} };
//map<string, string>::iterator it = dict.begin();
auto it = dict.begin();
return 0;
}auto也一定的坏处,以auto it = dict.begin(); 为例:知道的人当然明白其是一个迭代器,但是如果是一个不明白的人,那么就需要去查看 dict.begin() 的返回值是什么,才能知道返回值 auto 所推测的类型。
所以,auto在一定程度上的提高了代码的便捷性,但也一定程度上的降低了代码的可读性。
decltype
int main()
{
int x = 10;
// typeid拿到只是类型的字符串,不能用这个再去定义对象什么的
//typeid(x).name() y = 20;
decltype(x) y = 20;
return 0;
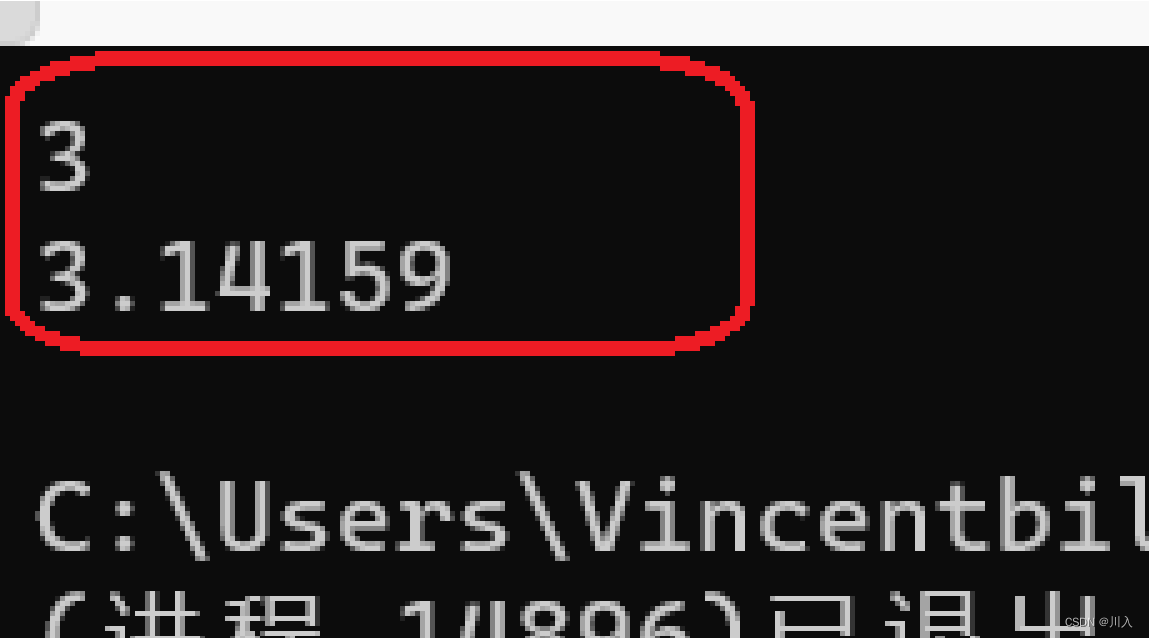
}那auto也可以,为何需要decltype?因为decltype是由decltype推导的类型决定的,而auto是由 = 的右值决定的:
#include<iostream>
using namespace std;
int main()
{
int x = 10;
decltype(x) y1 = 3.1415926;
auto y2 = 3.1415926;
cout << y1 << endl;
cout << y2 << endl;
return 0;
}
// decltype的一些使用使用场景
template<class T1, class T2>
void F(T1 t1, T2 t2)
{
decltype(t1 * t2) ret;
cout << typeid(ret).name() << endl;
}nullptr
由于C++中NULL被定义成字面量0,这样就可能回带来一些问题,因为0既能指针常量,又能表示整形常量。所以出于清晰和安全的角度考虑,C++11中新增了nullptr,用于表示空指针。
#ifndef NULL
#ifdef __cplusplus
#define NULL 0
#else
#define NULL ((void *)0)
#endif
#endif
在之前的C++98中的指针空值中,我们所使用的空指针的定义是NULL。所以,相对应的以宏将NULL定义为0,就会出现一下类似的情况等:
using namespace std;
void pointer(int)
{
cout << "pointer(int)" << endl;
}
void pointer(int*)
{
cout << "pointer(int*)" << endl;
}
int main()
{
int* p = NULL;
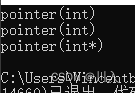
pointer(0);
pointer(NULL);
pointer(p);
return 0;
}pointer(NULL)传递的是int类型的。
范围for循环
若是在C++98中我们要遍历一个数组,可以按照以下方式:
#include<iostream>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//打印数组中的所有元素
for (int i = 0; i < sizeof(array) / sizeof(array[0]); i++)
{
cout << array[i] << " ";
}
cout << endl;
return 0;
}C++11新标准引入一种更简单的 for 语句,这种语句可以遍历容器或其他序列的所有元素。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。
void Test_For()
{
int array[] = { 1, 2, 3, 4, 5 };
for (auto e : array) //变化前
cout << e << " ";
cout << endl;
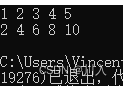
for (auto& e : array) //使用应用使得可以更改数据
e *= 2;
for (auto e : array) //变化后
cout << e << " ";
cout << endl;
}范围for自动推导类型,自动取array中的值赋值给e,自动迭代(自动++),自动的判断结束。
Note:
与普通循环类似,可以用continue来结束本次循环,也可以用break来跳出整个循环。
#include<iostream>
using namespace std;
int main()
{
int array[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
//打印数组中的所有元素
for (auto e : array)
{
if (e == 8)
break;
if (e == 4)
continue;
cout << e << " ";
}
cout << endl;
return 0;
}范围for底层就是被替换成了迭代器,如果是原生数组就是被替换成了类似迭代器的样子(如同vector迭代器实现的指针)。
STL中一些变化
新容器

array容器、forward_list容器吐槽的地方,很鸡肋:食之无味弃之可惜。
array容器
array的相关文档
vector容器可以说是动态的数据表,array容器可以说是静态的顺序表。array是固定大小的序列容器。

由于其是固定大小的序列容器。所以其并不支持插入删除,因为它的空间开好了,而且是固定大小的,所以访问都是使用 operator[] ,也可以用迭代器,所以对于vector容器而言,array容器没有什么好介绍的。
其实C++11增加array容器的初衷是想大家不要使用C语言的数组,其觉得C语言的数组不好,甚至可以说是非常的而不好。因为其期待都容器化。最主要的就是对越界的判定。对于C语言的普通数组越界也没有什么很好的方法判定,越界读是很有可能判断不出来的。
对于C语言的数组的越界判定,是判定数组后的几个连续空间,内抽查,但是如果访问的跨度很大,或正好躲过抽查,就会出现,越界判断不出来:
int main()
{
const size_t N = 10;
int arr[N];
// C语言数组越界检查,越界读基本检查不出来,越界写是抽查
arr[N]; // 越界读查不出来
//arr[N] = 1; // 越界写可能查的出来
arr[N + 10] = 1; // 越界写可能查不出来
return 0;
}C语言数组越界检查,越界读基本检查不出来。只有一个地方的越界读检查的出来:就是对于常量区或者是代码段,其上的写都检查的出来,因为这两个区域在硬件上就是保护的,从进程的地址空间,只要访问那段进程空间的地址,只要是在那段范围之内,是硬判断的,那段空间是不允许写的。
array容器,是无论你是读还是写,只要是越界都检查的出来。因为最不同的地方是调用的时候调用的是一个函数 operator[] 。其与vector容器的方括号几乎一致,一进来就先对你的下标进行检查,是否处于合理范围之内。
所以,array容器称不上画蛇添足,还是有它的价值的。但是,实际的结果是array容器用的很少:
- 一方面,大家用C语言的静态数组用习惯了,更可以说是一种先入为主的思想。
- 二方面,如果怕越界,用array容器不如用vector容器 + resize,也能使用vector容器将空间开好。
- 三方面,如果array容器的空间过于的大,会导致栈空间的溢出,栈本身就不大。vector容器在堆上,堆相对于栈是很大的。
forward_list容器
forward_list的相关文档
forward_list容器被实现为单链接列表。其支持的功能与list非常非常的像。其针对于list容器真正的优势是节省一点点的空间。list容器底层是双向链表实现,forward_list容器是单向链表实现,看起来是每一个节点都少一个指针。但是如果不是大量需要数据的情况下,省一个指针,根本起不了很大的功能。
更主要的是,forward_list容器 功能是不全的,或者是说怪怪的:
insert插入的位置与普遍的插入在前面不同,其是插入在节点的后面。因为在前面插入时间复杂度就是O(N)了。毕竟缺少了一个指向前面的指针,缺少这个指针,其需要找到前一个节点,就需要将一整个单链表遍历。
其实 insert 还好,但是 erase 就更坑了:erase不是当前位置,而是erase当前位置下一个位置。
在实际当中,如果不是非常特殊的使用要求,几乎是不会使用到 forward_list容器 的。相比起来 list容器 更好。
容器中的一些新方法
容器内部的变化:
- 都支持initializer_list构造,用来支持列表初始化。
- 比较鸡肋的接口。比如:cbegin、cend系列(没有什么价值)
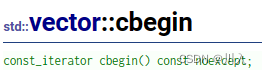
以vector容器为例:
以vector容器的begin与cbegin为例:
普通对象的就使用普通的,const对象的就是用const的,挺好的,但是它偏偏又分出了个cbegin系列。
- 右值引用参数的插入。移动构造和移动赋值
【C++】-- C++11 - 右值引用和移动语义(上万字详细配图配代码从执行一步步讲解)_川入的博客-CSDN博客


![[go学习笔记.第十八章.数据结构] 2.约瑟夫问题,排序,栈,递归,哈希表,二叉树的三种遍历方式](https://img-blog.csdnimg.cn/c059abcbe7cc4f848b6fa547111fab07.png)