下面要构建一个简单的计算器,规则如下:
1)可以由一系列语句构成,每条语句由换行符终止
2)一条语句可以是表达式、赋值语句或空行
3)可以有加减乘除、小括号以及变量出现
例如,文件名t.expr的内容如下:
193
a = 5
b = 6
a+b*2
(1+2)*3
用ANTLR写出来的语法是:
grammar Expr;
prog: stat+ ;
stat: expr NEWLINE
| ID '=' expr NEWLINE
| NEWLINE
;
expr: expr ('*'|'/') expr
| expr ('+'|'-') expr
| INT
| ID
| '(' expr ')'
;
ID : [a-zA-Z]+ ; // 匹配标识符
INT : [0-9]+ ; // 整数
NEWLINE:'\r'? '\n' ;
WS : [ \t]+ -> skip ; // 丢弃空白字符
可以看到ANTLR非常强大,可以出现递归定义,expr的定义里面又出现了expr。
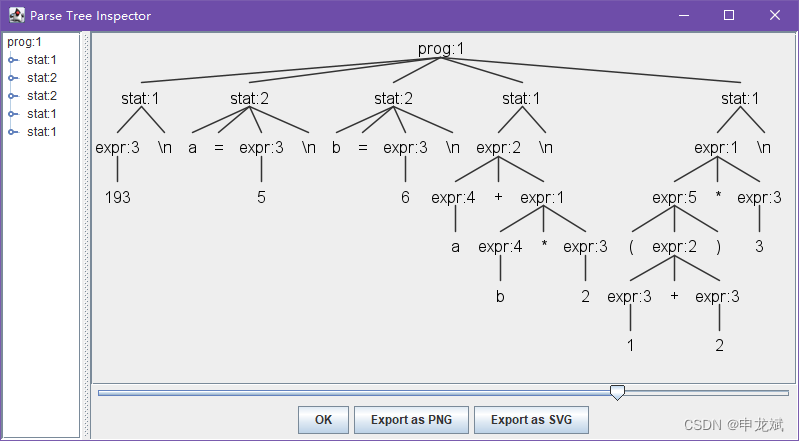
生成语法分析树:
antlr4-parse Expr.g4 prog -gui t.expr
生成Python代码:
antlr4 -Dlanguage=Python3 Expr.g4
几个关键源代码:
1)ExprLexer.py 词法分析器
2)ExprLexer.tokens 词法符号
3)ExprListener.py 语法监听器
4)ExprParser.py 语法解析器
可以自己补一个主程序:
import sys
from antlr4 import *
from antlr4.InputStream import InputStream
from ExprLexer import ExprLexer
from ExprParser import ExprParser
input_stream = FileStream('t.expr')
lexer = ExprLexer(input_stream)
token_stream = CommonTokenStream(lexer)
parser = ExprParser(token_stream)
tree = parser.prog()
lisp_tree_str = tree.toStringTree(recog=parser)
print(lisp_tree_str)
该程序也可以用文本形式打印出语法分析树。
(prog
(stat (expr 193) \n)
(stat a = (expr 5) \n)
(stat b = (expr 6) \n)
(stat (expr (expr a) + (expr (expr b) * (expr 2))) \n)
(stat (expr (expr ( (expr (expr 1) + (expr 2)) )) * (expr 3)) \n)
)
g4文件还可以拆分为更小的逻辑单元,下面内容保存在文件CommonLexerRules.g4中:
lexer grammar CommonLexerRules;
ID : [a-zA-Z]+ ; // 匹配标识符
INT : [0-9]+ ; // 整数
NEWLINE:'\r'? '\n' ;
WS : [ \t]+ -> skip ; // 丢弃空白字符
另一个文件可以使用import导入写好的规则:
```python
grammar LibExpr;
import CommonLexerRules;
prog: stat+ ;
stat: expr NEWLINE
| ID '=' expr NEWLINE
| NEWLINE
;
expr: expr ('*'|'/') expr
| expr ('+'|'-') expr
| INT
| ID
| '(' expr ')'
;
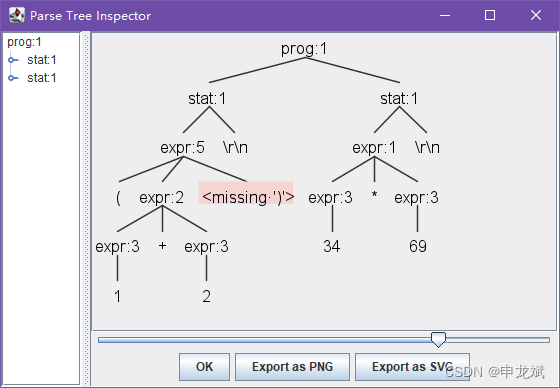
ANTLR4的容错处理
antlr4-parse LibExpr.g4 prog -gui
(1+2
34*69
^Z
可以看到缺少右括号的错误提示。
利用访问器构建一个计算器
可以在语法规则里添加标签,这样生成的源代码里。
grammar LabeledExpr;
prog: stat+ ;
stat: expr NEWLINE # printExpr
| ID '=' expr NEWLINE # assign
| NEWLINE # blank
;
expr: expr op=('*'|'/') expr # MulDiv
| expr op=('+'|'-') expr # AddSub
| INT # int
| ID # id
| '(' expr ')' # parens
;
MUL : '*' ; // assigns token name to '*' used above in grammar
DIV : '/' ;
ADD : '+' ;
SUB : '-' ;
ID : [a-zA-Z]+ ; // match identifiers
INT : [0-9]+ ; // match integers
NEWLINE:'\r'? '\n' ; // return newlines to parser (is end-statement signal)
WS : [ \t]+ -> skip ; // toss out whitespace
生成访问器程序:
antlr4 -Dlanguage=Python3 -no-listener -visitor LabeledExpr.g4
生成的程序中有一个与以前不太一样的源程序LabeledExprVisitor.py:
# Generated from LabeledExpr.g4 by ANTLR 4.11.1
from antlr4 import *
if __name__ is not None and "." in __name__:
from .LabeledExprParser import LabeledExprParser
else:
from LabeledExprParser import LabeledExprParser
# This class defines a complete generic visitor for a parse tree produced by LabeledExprParser.
class LabeledExprVisitor(ParseTreeVisitor):
# Visit a parse tree produced by LabeledExprParser#prog.
def visitProg(self, ctx:LabeledExprParser.ProgContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#printExpr.
def visitPrintExpr(self, ctx:LabeledExprParser.PrintExprContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#assign.
def visitAssign(self, ctx:LabeledExprParser.AssignContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#blank.
def visitBlank(self, ctx:LabeledExprParser.BlankContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#parens.
def visitParens(self, ctx:LabeledExprParser.ParensContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#MulDiv.
def visitMulDiv(self, ctx:LabeledExprParser.MulDivContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#AddSub.
def visitAddSub(self, ctx:LabeledExprParser.AddSubContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#id.
def visitId(self, ctx:LabeledExprParser.IdContext):
return self.visitChildren(ctx)
# Visit a parse tree produced by LabeledExprParser#int.
def visitInt(self, ctx:LabeledExprParser.IntContext):
return self.visitChildren(ctx)
del LabeledExprParser
我们现在要评估计算器里的表达式的值,需要自己构建一个访问器:
from LabeledExprVisitor import LabeledExprVisitor
from LabeledExprParser import LabeledExprParser
class EvalVisitor(LabeledExprVisitor):
def __init__(self):
self.memory = {} # 计算器的“内存”,保存着变量名和变量值的关系
def visitAssign(self, ctx):
var_name = ctx.ID().getText() # id在'='的左侧,变量名
value = self.visit(ctx.expr()) # 计算右侧表达式的值
self.memory[var_name] = value
return value
def visitPrintExpr(self, ctx):
value = self.visit(ctx.expr()) # 计算expr子节点的值
print(value)
return 0
def visitInt(self, ctx):
return ctx.INT().getText()
def visitId(self, ctx):
name = ctx.ID().getText()
if name in self.memory:
return self.memory[name]
return 0
def visitMulDiv(self, ctx):
left = int(self.visit(ctx.expr(0))) # 左侧子表达式的值
right = int(self.visit(ctx.expr(1))) # 右侧子表达式的值
if ctx.op.type == LabeledExprParser.MUL:
return left * right
return left / right
def visitAddSub(self, ctx):
left = int(self.visit(ctx.expr(0))) # 左侧子表达式的值
right = int(self.visit(ctx.expr(1))) # 右侧子表达式的值
if ctx.op.type == LabeledExprParser.ADD:
return left + right
return left - right
def visitParens(self, ctx):
return self.visit(ctx.expr())
主程序:
import sys
from antlr4 import *
from antlr4.InputStream import InputStream
from LabeledExprLexer import LabeledExprLexer
from LabeledExprParser import LabeledExprParser
from EvalVisitor import EvalVisitor
input_stream = FileStream('t.expr')
lexer = LabeledExprLexer(input_stream)
token_stream = CommonTokenStream(lexer)
parser = LabeledExprParser(token_stream)
tree = parser.prog()
visitor = EvalVisitor()
visitor.visit(tree)
对于文章一开头的t.expr里的几个表达式,可以求出下面三个值:
193
17
9