Flink CheckPoint机制
CheckPoint本质上就是检查点,类似于玩游戏的时候,需要偶尔存档,怕家里断电导致自己白玩。

Flink也是一样的,机器也是可能宕机,那么Flink如何保证自身不受宕机影响呢?
一般来说,存档有两种策略,一种是“随时”,即处理完一条数据就存档一次,这样保证了数据的高可用,但是会对系统带来巨大的性能损失,而且机器宕机是一个小概率事件。
另外一种就是周期性存档,即每过一段事件,就存档一次,flink采用的就是这种
听起来很简单,但还有一个问题,周期性触发存档的时候,如果正好在处理一个数据,这时候怎么办?
- 停止处理数据,进行存档:这种是肯定不行的,因为任务正在处理,你不知道处理到什么状态了,你只能把所有的状态信息都存下来,这很麻烦的。
- 把正在处理的数据处理完,再进行存档:这听起来不错,但是分布式系统的节点之间需要通过网络通信来传递数据,如果我们保存检查点的时候刚好有数据在网络传输的路上,那么下游任务是没法将数据保存起来的;故障重启之后,我们只能期待上游任务重新发送这个数据。然而上游任务是无法知道下游任务是否收到数据的,只能盲目地重发,这可能导致下游将数据处理两次,结果就会出现错误。
怎么解决?
我们的策略是:当所有任务都恰好处理完一个相同的输入数据的时候,将它们的状态保存下来。首先,这样避免了除状态之外其他额外信息的存储,提高了检查点保存的效率。
其次,一个数据要么就是被所有任务完整地处理完,状态得到了保存;要么就是没处理完,状态全部没保存:这就相当于构建了一个“事务”(transaction)。如果出现故障,我们恢复到之前保存的状态,故障时正在处理的所有数据都需要重新处理;所以我们只需要让源(source)任务向数据源重新提交偏移量、请求重放数据就可以了。这需要源任务可以把偏移量作为算子状态保存下来,而且外部数据源能够重置偏移量;
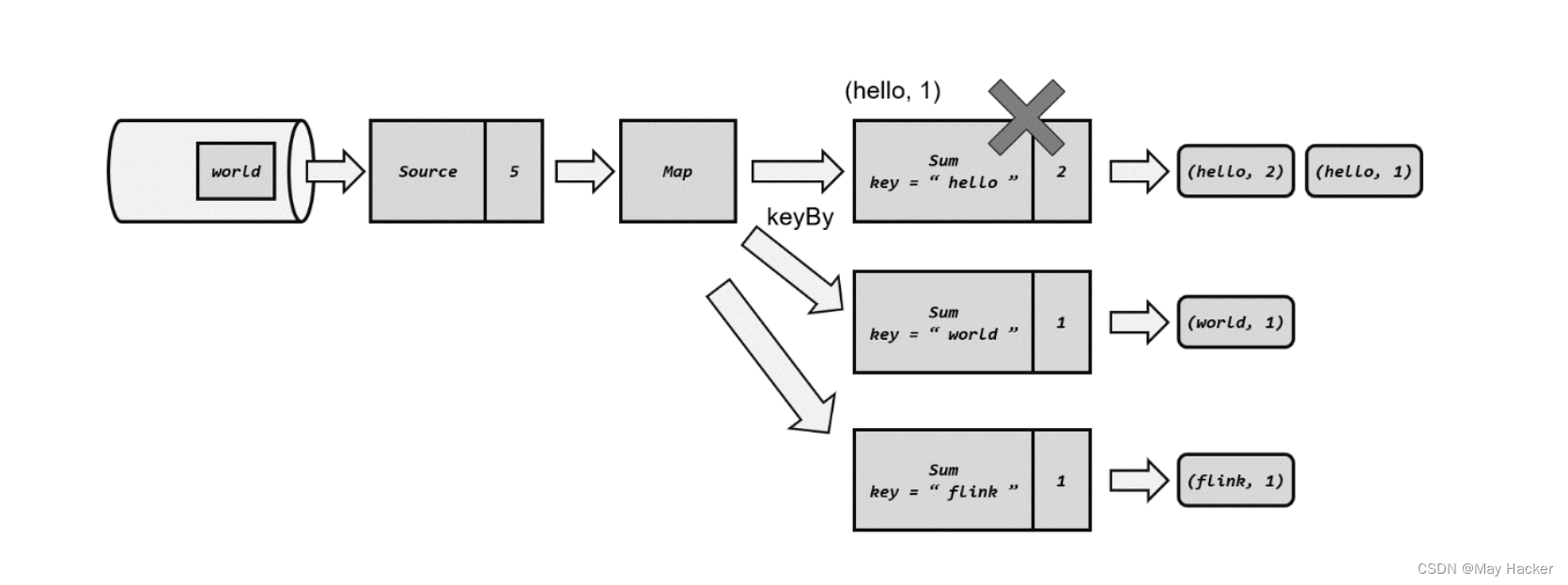
Kafka 就是满足这些要求的一个最好的例子,比如下面,我们以一个wordCount任务流程为例,一个正常的检查点保存机制是怎样的:
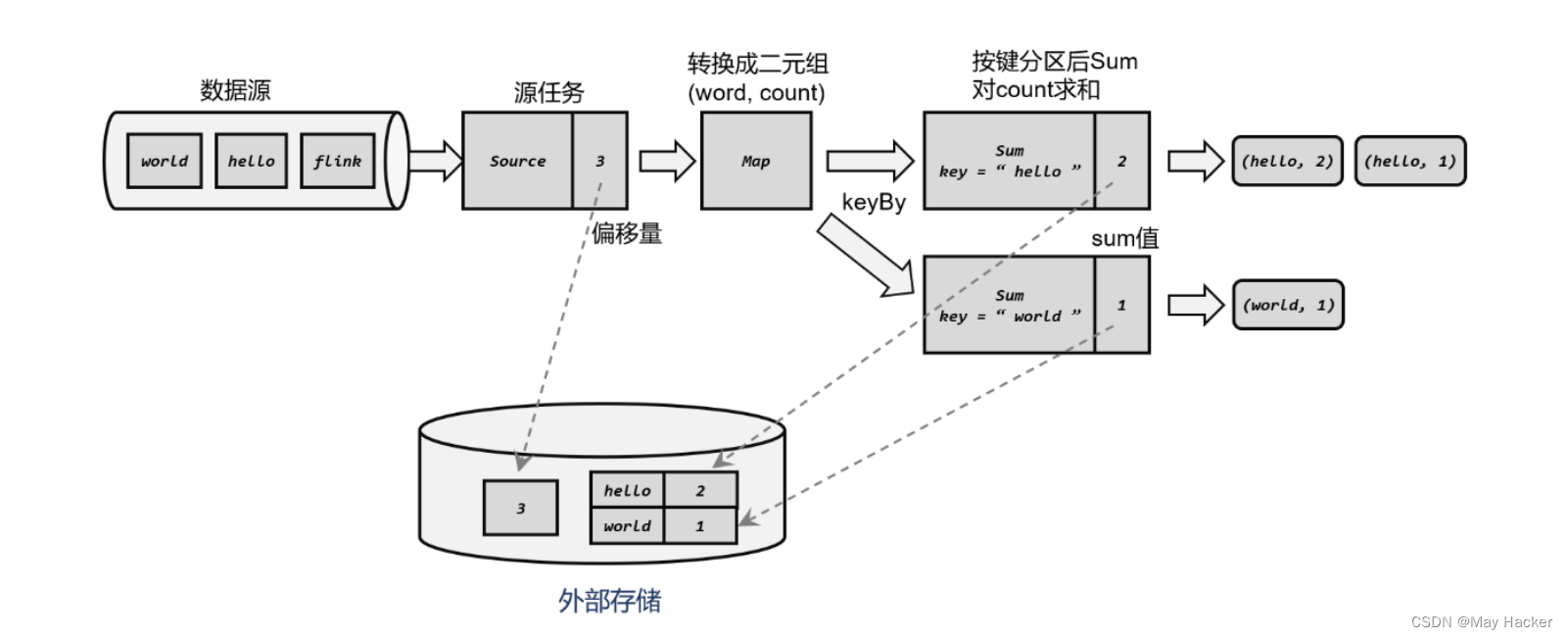
源任务处理了三条数据,下游任务也完成了对这三条数据的处理,所以符合我们的策略(当所有任务都恰好处理完一个相同的输入数据的时候,进行存档)
我们来看下故障状态下的处理流程,当源任务又完成处理了2条数据时,偏移量变成了5,但是在求和任务时,宕机了,这时候根据我们的策略,这2条数据没有被所有的数据完成,那么我们就不会在外部存储我们的状态
即我们已经持久化保存的状态是这样的:
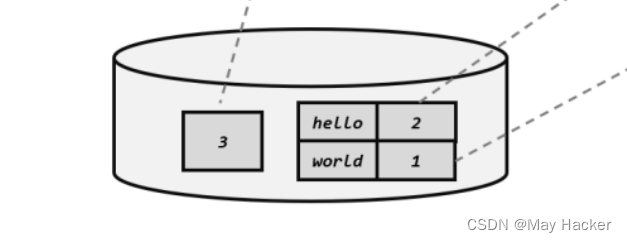
当应用重启的时候,我们根据这个检查点状态进行恢复就可以,但是这样有个问题,对源算子来说,任务已经完成,4,5偏移量对应的数据已经给你下游发过去了,我又不知道你失败了
这种情况下我们的策略就很有优势,我们只需要根据检查点保存的偏移量,重置上游数据源任务的偏移量,要求进行重放数据就可以。
所以,如果要保证精准一次性,上游组件必须支持数据重放,kafka就支持。
现在来看,文章标题是不是就明白了。