Flink系列Table API和SQL之:动态表、持续查询、将流转换成动态表、更新查询、追加查询、将动态表转换为流、更新插入流
- 一、表和流的转换
- 二、动态表
- 三、持续查询
- 四、将流转换成动态表
- 五、更新查询
- 六、追加查询
- 七、将动态表转换为流
- 八、更新插入流(Upsert)
一、表和流的转换
- Flink中使用表和SQL基本上跟其他场景是一样的。不过对于表和流的转换,却稍显复杂。当我们将一个Table转换成DataStream时,有"仅插入流"(Insert-Only Streams)和"更新日志流"(Changelog Streams)两种不同的方式,具体使用哪种方式取决于表中是否存在更新操作。
- 这种麻烦其实是不可避免的。Table API和SQL本质上都是基于关系型表的操作方式。关系型表本身是有界的,更适合批处理的场景。所以在MySQL、Hive这样的固定数据集中进行查询,使用SQL就会显得得心应手。而对于Flink这样的流处理框架来说,要处理的是源源不断到来的无界数据流,无法等到暑假都到齐再做查询,每来一条数据就应该更新一次结果。这时如果一定要使用表和SQL进行处理,就会显得别扭,需要引入一些特殊的概念。
可以将关系型表/SQL与流处理做一个对比。
| 关系型表/SQL | 流处理 | |
|---|---|---|
| 处理的数据对象 | 字段元组的有界集合 | 字段元祖的无限序列 |
| 查询 | 可以访问完整的数据输入 | 无法访问到所有数据,必须持续等待流式输入 |
| 对数据的访问 | ||
| 查询终止条件 | 生成固定大小的结果集合终止 | 永不停止,根据持续收到的数据不断更新查询结果 |
流处理面对的数据是连续不断的,这导致了流处理中的表跟我们熟悉的关系型数据库中的表完全不同。基于表的查询操作,也就有了新的含义。
希望把流数据换成表的形式,那么这表中的数据就会不断增长。如果进一步基于表执行SQL查询,那么得到的结果就不是一成不变的,而是会随着新数据的到来持续更新。
二、动态表
- 当流中有新数据到来,初始的表中会查入一行,而基于这个表定义的SQL查询,就应该在之前的基础上更新结果。这样得到的表就会不断地动态变化,被称为动态表(Dynamic Tables)。
- 动态表是Flink在Table API和SQL中的核心概念,为流数据处理提供了表和SQL支持。所熟悉的表一般用来做批处理,面向的是固定的数据集,可以认为是"静态表"。而动态表则完全不同,它里面的数据会随时间变化。
- 其实动态表的概念,在传统的关系型数据库中已经有所接触。数据库中的表,其实是一系列INSERT、UPDATE和DELETE语句执行的结果。在关系型数据库中,我们一般把它称为更新日志流(changelog stream)。如果我们保存了表在某一时刻的快照(snapshot),那么接下来只要读取更新日志流,就可以得到表之后的变化过程和最终结果了。在很多高级关系型数据库(比如Oracle、DB2)中都有物化视图的概念,可以用来缓存SQL查询的结果。它的更新其实就是不停地处理更新日志流的过程。
- Flink中的动态表,就借鉴了物化视图的思想。
三、持续查询
- 动态表可以像静态的批处理一样进行查询操作。由于数据在不断变化,因此基于它定义的SQL查询也不可能执行一次就得到最终结果。这样依一来,对动态表的查询也就永远不会停止,一直在随着新数据的到来而继续执行。这样的查询就被称作持续查询。对动态表定义的查询操作,都是持续查询,而持续查询的结果也会是一个动态表。
- 由于每次暑假到来都会触发查询操作,因此可以认为一次查询面对的数据集,就是当前输入动态表中收到的所有数据。这相当于是对输入动态表做了一个快照(snapshot),当作有限数据集进行批处理。流式数据的到来会触发连续不断的快照查询,像动画一样连贯起来,就构成了持续查询。
持续查询的过程,可以清晰地看到流、动态表和持续查询的关系:
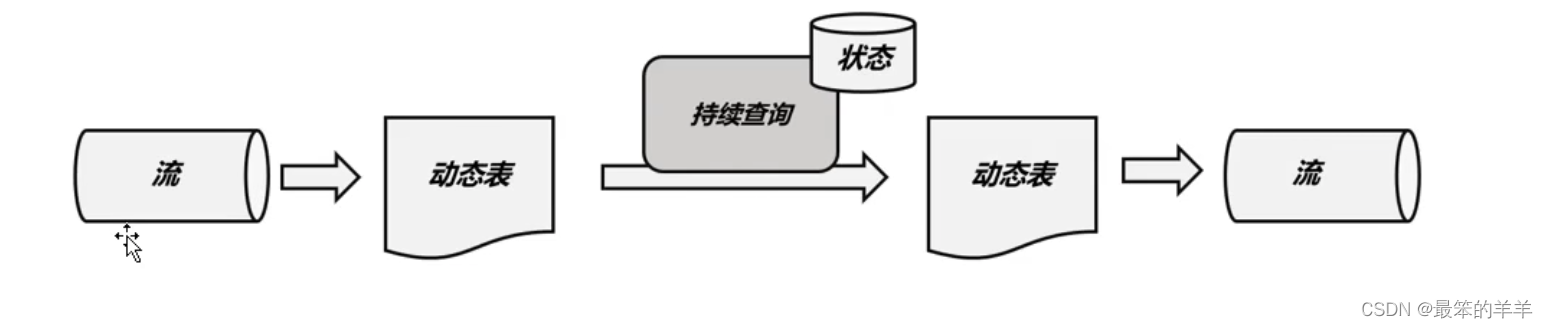
持续查询的步骤如下:
- 流stream被转换为动态表dynamic table
- 对动态表进行持续查询(continuous query),生成新的动态表
- 生成的动态表被转换成流。
这样,只要API将流和动态表的转换封装起来,就可以直接在数据流上执行SQL查询,用处理表的方式来做流处理了。
四、将流转换成动态表
- 为了能够使用SQL来做流处理,必须先把流(stream)转换成动态表
- 如果把流看作一张表,那么流中每个数据的到来,都应该看作是对表的一次插入(Insert)操作,会在表的末尾添加一行数据。因为流是连续不断的,而且之前的输出结果无法改变、只能在后面追加。所以我们其实是通过一个只有插入操作(insert-only)的更新日志(changelog)流,来构建一个表。
流转换成动态表的过程:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Event> eventStream = env.addSource(new ClickSource())
.assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forBoundedOutOfOrderness(Duration.ZERO)
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
//创建表执行环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//将dataStream转换成table
Table eventTable = tableEnv.fromDataStream(eventStream);
//直接写sql进行转换
Table resultTable = tableEnv.sqlQuery("select user,url from " + eventTable);
//基于table直接转换
Table resultTable2 = eventTable.select($("user"), $("url"))
.where($("user").isEqual("Alice"));
//转换成流打印输出
tableEnv.toDataStream(resultTable2).print("result2");
tableEnv.toDataStream(resultTable).print("result");
env.execute();
五、更新查询
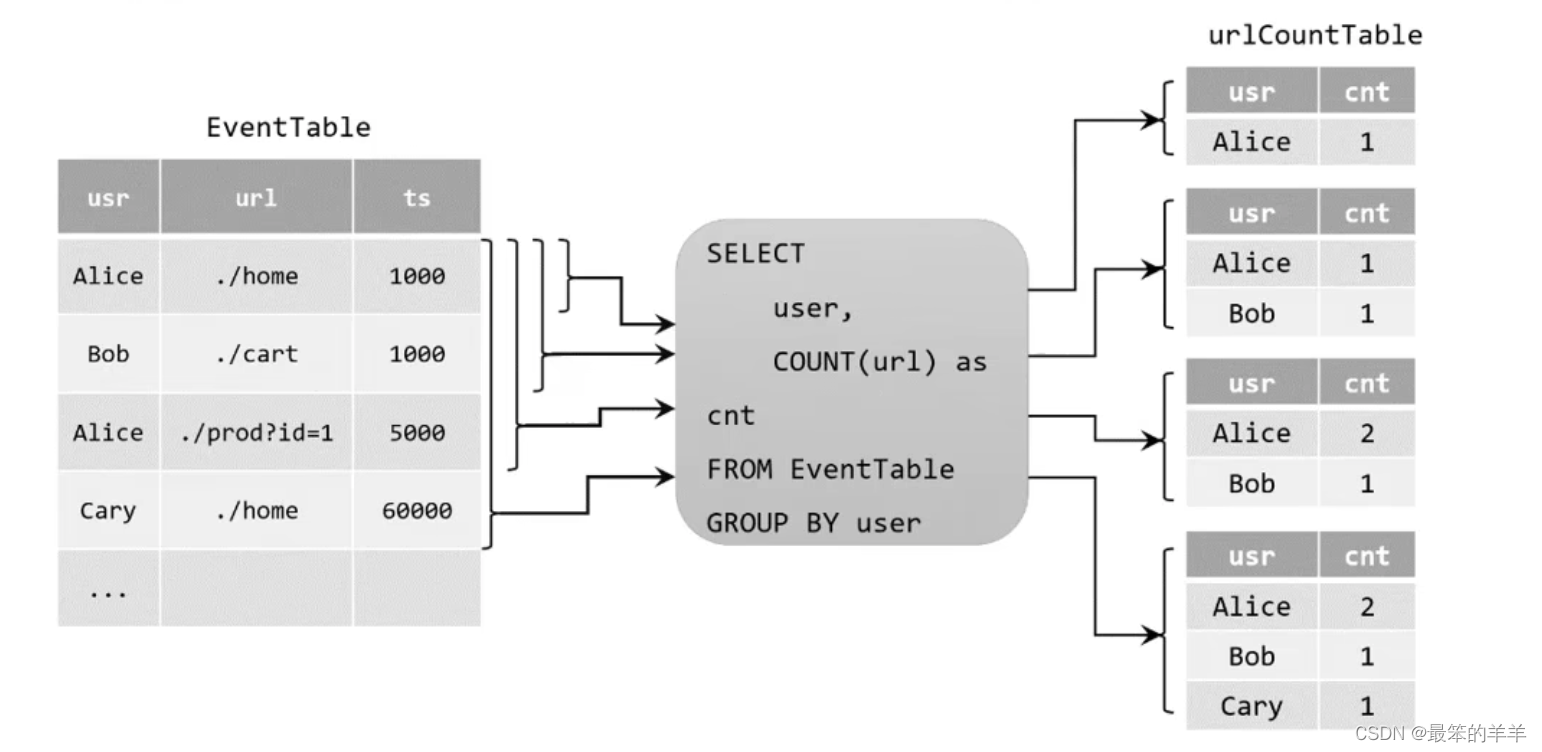
在代码中定义了一个SQL查询
Table urlCountTable = tableEnv.sqlQuery("SELECT user,COUNT(url) as cnt FROM EnentTable GROUP BY user")
这个查询很简答,主要是分组聚合统计每个用户点击次数。把原始的动态表注册为EventTable,经过查询转换后得到urlCountTable。这个结果动态表中包含两个字断,具体定义如下:
[
user: VARCHAR, //用户名
cnt: BIGINT。//用户访问url的次数
]
当原始动态表不停地插入新的数据时,查询得到的urlCountTable会持续地进行更改。由于count数量可能会叠加增长,因此这里的更改操作可以是简单的插入(Insert),也可以是对之前数据的更新(Update)。换句话说,用来定义结果表的更新日志(changelog)流中,包含了INSERT和UPDATE两种操作。这种持续查询被称为更新查询(Update Query),更新查询得到的结果表如果想要转换成DataStream,必须调用toChangelogStream()方法。
六、追加查询
- 查询过程用到了分组聚合,结果表中就会产生更新操作。如果我们执行一个简单的条件查询,结果表中就会像原始表EventTable一样,只有插入Insert操作了。
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url,user FROM EventTable WHERE user = 'Cary' ");
- 这样的持续查询,就被称为追加查询(Append Query),定义的结果表的更新日志(changelog)流中只有INSERT操作。追加查询得到的结果表,转换成DataStream调用方法没有限制,可以直接用toDataStream(),也可以像更新查询一样调用toChangeStream()。
- 这样看来似乎可以总结一个规律:只要用到了聚合,在之前的结果上有叠加,就会产生更新操作,就是一个更新查询。但是事实上,更新查询的判断标准是结果表中的数据是否会有UPDATE操作,如果聚合的结果不再改变,那么同样也不是更新查询。
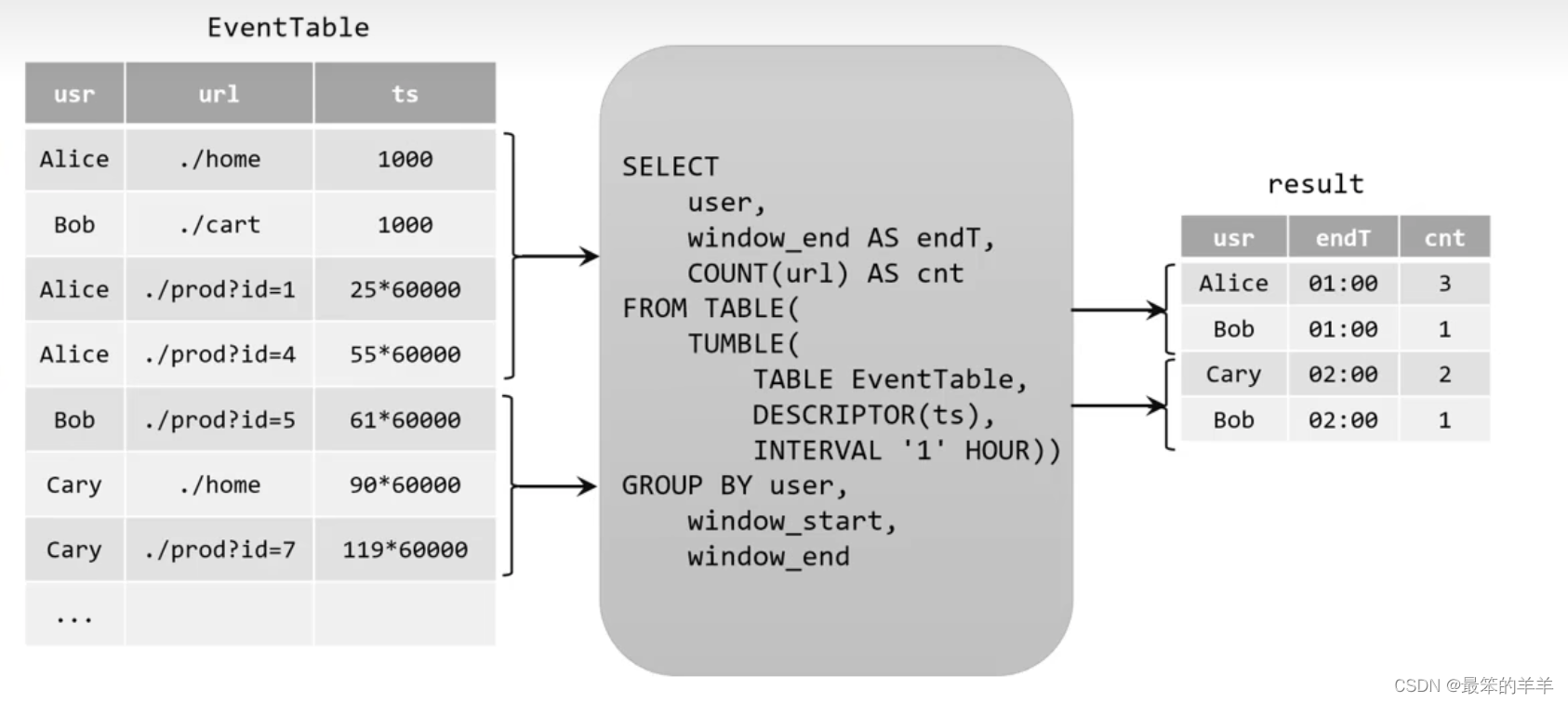
可以考虑开一个滚动窗口,统计每一小时内所有用户的点击次数,并在接过表中增加一个endT字段,表示当前统计窗口的结束时间。这时结果表的字段定义如下:
[
user: VARCHAR, //用户名
endT: TIMESTAMP, //窗口结束时间
cnt: BIGINT. //用户访问url的次数
]
- 与之前的分组聚合一样,当原始动态表不停地插入新的数据时,查询得到的结果result会持续地进行更改。比如时间戳在12:00:00到12:59:59之间有四条数据,其中Alice三次点击、Bob一次点击,所以当水位线达到13:00:00时窗口关闭,输出到结果表中的就是新增两条数据[Alice,13:00:00,3]和[Bob,13:00:00,1]。同理,当下一个小时的窗口关闭时,也会将统计结果追加到result表后面,而不会更新之前的数据。
- 我们发现,由于窗口的统计结果是一次性写入结果表的,所以结果表的更新日志流中只会包含插入INSERT操作,而没有更新UPDATE操作,所以这里的持续查询,依然是一个追加(Append)查询。结果表result如果转换成DataStream,可以直接调用toDataStream()方法。
七、将动态表转换为流
- 与关系型数据库中的表一样,动态表也可以通过插入(Insert)、更新(Update)、删除(Delete)操作,进行持续的更改。将动态表转换为流或将其写入外部系统时,就需要对这些更改操作进行编码,通过发送编码消息的方式告诉外部系统要执行的操作。
- 在Flink中,Table API和SQL支持三种编码方式:
- 仅追加流(Append-only):仅通过插入Insert更改来修改的动态表,可以直接转换为仅追加流。这个流中发出的数据,其实就是动态表中新增的每一行。
- 撤回流:撤回流是包含两类消息的流,添加(add)消息和撤回(retract)消息。
- 具体的编码规则是:INSERT插入操作编码为add消息。DELETE删除操作编码为retract消息。而UPDATE更新操作则编码为被更改行的retract消息,和更新后行的add消息。这样,我们可以通过编码后的消息指明所有的增删改操作,一个动态表就可以转换为撤回流了。
- 可以看到,更新操作对于撤回流来说,对应着两个消息,之前数据的撤回(删除)和新数据的插入。
将动态表转换为撤回流的过程:
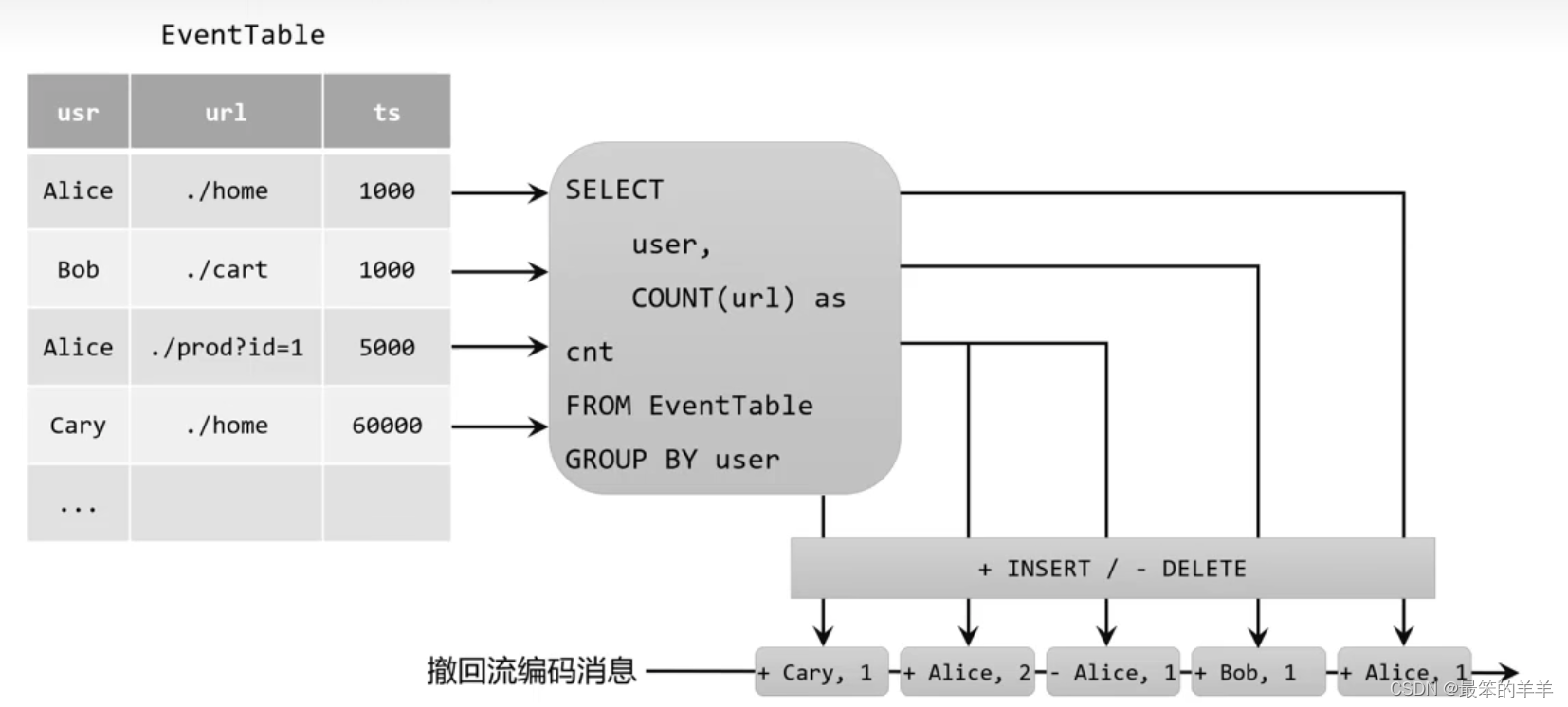
- 用+代表add消息(对应插入INSERT操作)
- 用-代表retract消息(对应删除DELETE操作)
- 当Alice的第一个点击事件到来时,结果表新增一条数据[Alice,1]
- 当Alice的第二个点击事件到来时,结果表会将[Alice,1]更新为[Alice,2],对应的编码就是删除[Alice,1]、插入[Alice,2]。这样当一个外部系统收到这样的两条消息时,就知道要对Alice的点击统计次数进行更新了。
八、更新插入流(Upsert)
- 更新插入流只包含两种类型的消息:更新插入(upsert)和删除(delete)消息。
- 所谓upsert其实就是update和insert的合成词,所以对于更新插入流来说,INSERT插入操作和UPDATE更新操作,统一被编码为upsert消息。
- DELETE删除操作则被编码为delete消息。
既然更新插入流中不区分插入(insert)和更新(update),自然会想到一个问题,如果希望更新一行数据时,怎么保证最后做的操作不是插入呢?
这就需要动态表中必须有唯一的键(key)。通过这个key进行查询,如果存在对应的数据就做更新(update),如果不存在就直接插入(insert)。这是一个动态表可以转换为更新插入流的必要条件。当然,收到这条流中数据的外部系统,也需要知道这唯一的键(key),这样才能正确地处理消息。
将动态表转换为更新插入流的过程:
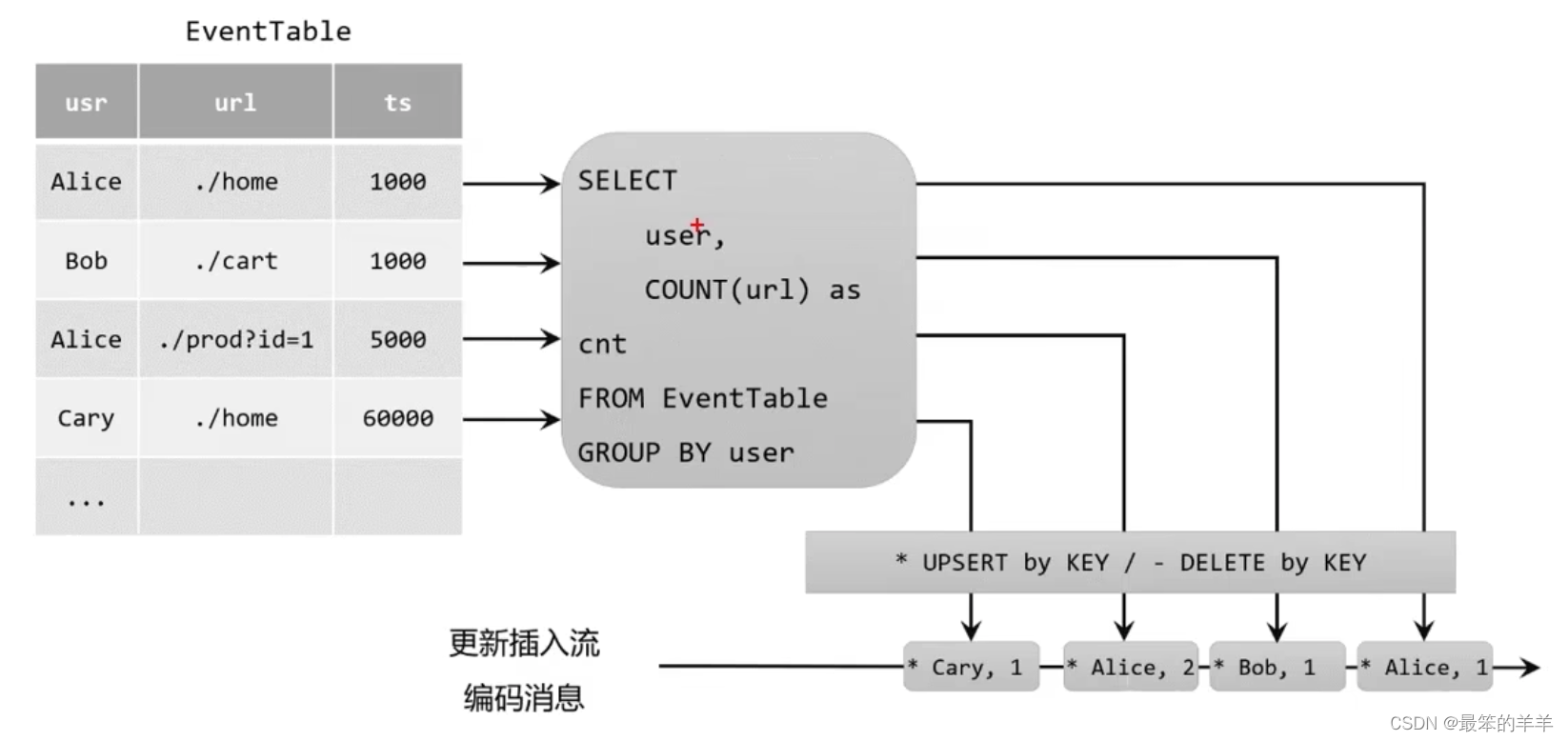
- 可以看到,更新插入流跟撤回流的主要区别在于,更新操作由于有key的存在,




![移动Web【空间转换[空间位移、透视、空间旋转、立体呈现、3D导航、空间缩放]、动画、综合案例】](https://img-blog.csdnimg.cn/801a522e3c5c46b996b659934d9665af.png)


![健康码识别[QT+OpenCV]](https://img-blog.csdnimg.cn/b1643a77eb38432abc2e9b5b86d46048.gif)



