前言
众所周知,kubernetes在2020年的1.20版本时就提出要移除docker。这次官方消息表明在1.24版本中彻底移除了dockershim,即移除docker。但是在1.24之前的版本中还是可以正常使用docker的。考虑到可能并不是所有项目环境都紧跟新版换掉了docker,本次就再最后体验一下可支持docker的最新k8s版本1.23.15,后续可能就研究怎么使用其他CRI,例如containerd了。
一、部署介绍及规划:
本次部署各组件版本:
顺便简单过一下组件作用
- etcd:
3.5.6负责存储集群的持久化数据 - k8s-server:
1.23.15(所有基础组件版本) -
- kube-apiserver:核心枢纽,提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
-
- kube-controller-manager:集群的管理控制中心,负责维护集群状态
-
- kube-scheduler:调度中心,负责节点资源管理,调度创建pod等
-
- kube-proxy:网络代理,负责为Service提供cluster内部的服务发现和负载均衡
-
- kubelet:负责维护pod生命周期
-
- kubctl:管理集群命令
-
- ……
明确目标:
部署: 快速部署三节点单master集群;
扩容: 新增一个节点,扩为双master集群,部署keepalived+nginx实现apiserver高可用,有条件的可以扩为三master集群
本次测试节点信息:
| 主机名(角色) | IP地址 | 节点规划 |
|---|---|---|
| k8s-master1 | 192.168.100.101 | etcd、kube-apiserver、kube-controller-manager、kube-proxy、kubelet、nginx、keepalived |
| k8s-node1 | 192.168.100.102 | etcd、kube-proxy、kubelet |
| k8s-node2 | 192.168.100.103 | etcd、kube-proxy、kubelet |
| k8s-master2(待扩容机器) | 192.168.100.104 | kube-apiserver、kube-controller-manager、kube-proxy、kubelet、nginx、keepalived |
| VIP(负载均衡器) | 192.168.100.105 |
服务器版本:
[root@k8s-master1 ~]# cat /etc/centos-release
CentOS Linux release 7.8.2003 (Core)
[root@k8s-master1 ~]# uname -a
Linux k8s-master1 3.10.0-1127.el7.x86_64 #1 SMP Tue Mar 31 23:36:51 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux
二、部署前准备
系统初始化
为了方便二次执行,直接全部复制,改了IP执行就可
# 1、关闭防火墙和selinux
sed -i "s/SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
setenforce 0
systemctl stop firewalld
systemctl disable firewalld
# 2、配置hosts解析
cat >> /etc/hosts << EOF
192.168.100.101 k8s-master1
192.168.100.102 k8s-node1
192.168.100.103 k8s-node2
192.168.100.104 k8s-master2
EOF
# 3、关闭swap分区(避免有性能等其他问题)
swapoff -a #临时关闭
sed -i "s/^.*swap*/#&/" /etc/fstab #永久关闭
mount -a
# 4、将桥接的IPV4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
modprobe br_netfilter #载入模块
sysctl -p /etc/sysctl.d/k8s.conf #生效
# 5、配置ntp
yum -y install ntp vim wget
sed -i "s/^[^#].*iburst*/#&/g" /etc/ntp.conf #注释原有server配置
sed -i "/server 3/a\server ntp.aliyun.com" /etc/ntp.conf #添加阿里云ntpserver
systemctl restart ntpd
systemctl enable ntpd
ntpq -p
拓展内容(可忽略,直接跳到第三步)
1、上边初始化时net.bridge.bridge-nf-call-ip6tables参数说明
为什么要开启 net.bridge.bridge-nf-call-ip6tables 配置(启用iptables过滤bridge网桥流量)
简述:
网桥是处于二层,iptables工作于三层
- 1、集群内一pod访问其他的service ip,会经过三层iptables的DNAT转发到pod_ip:port
- 2、当不开启此配置,当被访pod回复请求时,如果发现目标是在同一个节点,即同一网桥时,会直接走网桥到源pod,这样虽然能到源pod,但是由于没有原路返回,客户端与服务端的通信就不在一个 “频道” 上,不认为处在同一个连接,也就无法正常通信。
常见的问题现象就是偶现DNS解析失败,当 coredns 所在节点上的 pod 解析 dns 时,dns 请求落到当前节点的 coredns pod 上时,就可能发生这个问题。
感兴趣可以看详细说明:为什么 kubernetes 环境要求开启 bridge-nf-call-iptables ? - 腾讯云开发者社区-腾讯云 (tencent.com)
官方解读看这里:Network Plugins | Kubernetes
2、简单了解下TLS证书
因为k8s集群需要PKI证书来基于TLS/SSL来做认证,组件之间的通信都是通过证书来完成,可以理解为“口令”,组件通信时验证证书无误后,才会建立联系,交互信息,所以证书在部署及环境使用过程中也是比较重要的一项。
基础概念
- CA(Certification Authority):认证机构:负责颁发证书的权威机构(发送与接收组件双方之间的信任纽带)
- CSR(Certificate Signing Request):它是向CA机构申请数字签名证书时使用的请求文件
请求中会附上公钥信息以及国家,城市,域名,Email等信息,准备好CSR文件后就可以提交给CA机构,等待他们给我们签名,签好名后我们会收到crt文件,即证书。
证书:
CA机构对申请者的身份验证成功后,用CA的根证书对申请人的一些基本信息以及申请人的公钥进行签名(相当于加盖发证书机 构的公章)后形成的一个数字文件。实际上,数字证书就是经过CA认证过的公钥,除了公钥,还有其他的信息,比如Email,国家,城市,域名等。
证书的编码格式:
- PEM(Privacy Enhanced Mail):通常用于数字证书认证机构CA,扩展名为.pem, .crt, .cer, 和.key。内容为Base64编码的ASCII码文件,有类似"-----BEGIN CERTIFICATE-----" 和 "-----END CERTIFICATE-----"的头尾标记
- DER(Distinguished Encoding Rules):与PEM不同之处在于其使用二进制而不是Base64编码的ASCII。扩展名为.der或者.cer
公钥私钥:
- 每个人都有一个公钥与私钥
- 私钥用来进行解密和签名,是给自己用的。
- 公钥由本人公开,用于加密和验证签名,是给别人用的。
- 当该用户发送文件时,用私钥签名,别人用他给的公钥解密,可以保证该信息是由他发送的。即数字签名。
- 当该用户接受文件时,别人用他的公钥加密,他用私钥解密,可以保证该信息只能由他看到。即安全传输。
简述CA原理
CA的产生,是因为多个组件之间通信时,需要加一第三方来判断数据来源是否合规,保证通信的安全性。
引入一个看到的比较好的例子,用介绍信来介绍原理
普通的介绍信
假设 A 公司的张三先生要到 B 公司去拜访,但是 B 公司的所有人都不认识他,常用的办法是带公司开的一张介绍信,在信中说:兹有张三先生前往贵公司办理业务,请给予接洽…云云。然后在信上敲上A公司的公章。
张三先生到了 B 公司后,把介绍信递给 B 公司的前台李四小姐。李小姐一看介绍信上有 A 公司的公章,而且 A 公司是经常和 B 公司有业务往来的,这位李小姐就相信张先生不是歹人了。
这里,A公司就是CA机构,介绍信及颁发给张三的证书
引入中介权威机构的介绍信
如果和 B 公司有业务往来的公司很多,每个公司的公章都不同,那前台就要懂得分辨各种公章,非常麻烦。
所以,有C公司专门开设了一项“代理公章”的业务。
今后,A 公司的业务员去 B 公司,需要带2个介绍信:
介绍信1
含有 C 公司的公章及 A 公司的公章。并且特地注明:C 公司信任 A 公司。
介绍信2
仅含有 A 公司的公章,然后写上:兹有张三先生前往贵公司办理业务,请给予接洽…云云。
主要的好处在于: 对于B公司而言,就不需要记住各个公司的公章分别是什么;他只需要记住中介公司 C 的公章即可。当他拿到两份介绍信之后,先对介绍信1的 C 公章,验明正身;确认无误之后,再比对介绍信1和介绍信2的两个 A 公章是否一致。如果是一样的,那就可以证明介绍信2,即A公司是可以信任的了。
最后直白一点,其实我们的身份证一定程度上也相当于是颁发给我们的证书~
本次集群内部署使用的为自签的CA证书
三、开始部署
1、etcd集群部署
Etcd 是 CoreOS 推出的高可用的分布式键值存储系统,内部采用 raft 协议作为一致性算法,主要用于k8s集群的服务发现及存储集群的状态和配置等,所以先部署ETCD数据库。
本次使用三台组建集群(集群模式最少三节点),与k8s集群复用三台节点(k8s-master1、k8s-node1、k8s-node2),也可以放在集群之外,网络互通即可。
三节点,可容忍一个节点故障;
五节点,可容忍两个节点故障
1.1、使用cfssl工具配置证书 (重点)
CFSSL是CloudFlare开源的一款PKI/TLS工具。 CFSSL 包含一个命令行工具 和一个用于 签名,验证并且捆绑TLS证书的 HTTP API 服务。 使用Go语言编写。
是一个开源的证书管理工具,使用json文件生成证书,相比openssl更方便使用。
详细的不多说,直接开始(master1节点操作)
如果下载不下来,可以点这里下载,为本次文章使用的所有软件包,官方拉取纯净版
# 下载工具包
mkdir /opt/software && cd /opt/software
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssl_1.6.0_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssljson_1.6.0_linux_amd64
wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssl-certinfo_1.6.0_linux_amd64
# 复制到/usr/local/bin目录,并赋予执行权限
cp cfssl_1.6.0_linux_amd64 /usr/local/bin/cfssl
cp cfssljson_1.6.0_linux_amd64 /usr/local/bin/cfssljson
cp cfssl-certinfo_1.6.0_linux_amd64 /usr/local/bin/cfssl-certinfo
chmod +x /usr/local/bin/cfssl*
1.2、创建给etcd使用的自签证书颁发机构(CA)
1.2.1、创建工作目录
mkdir -p ~/TLS/{etcd,k8s} && cd ~/TLS/etcd
1.2.2、配置证书生成策略,让CA软件知道颁发有什么功能的证书
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"etcd": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
可用参数介绍:
这个策略,有一个default默认的配置,和一个profiles,profiles可以设置多个profile,这里的profile是etcd。
- default:默认策略,指定了证书的默认有效期是一年(8760h)
- etcd:表示该配置(profile)的用途是为etcd生成证书及相关的校验工作
-
- expiry:也表示过期时间,如果不写以default中的为准
-
- signing:表示该证书可用于签名其它证书;生成的 ca.pem 证书中 CA=TRUE
-
- key encipherment:密钥加密
-
- server auth:表示可以该CA 对 server 提供的证书进行验证
-
- client auth:表示可以用该 CA 对 client 提供的证书进行验证
1.2.3、创建用来生成 CA 证书签名请求(CSR)的 JSON 配置文件
cat > ca-csr.json << EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai"
}
]
}
EOF
可用参数介绍:
- CN:Common Name,CA名字
- key:生成证书的算法
- hosts:表示哪些主机名(域名)或者IP可以使用此csr申请证书,为空或者""表示所有的都可以使用
- names:一些其它的属性
-
- C:Country, 国家
-
- ST:State,州或者是省份
-
- L:Locality Name,地区,城市
-
- O:Organization Name,组织名称,公司名称(在k8s中常用于指定Group,进行RBAC绑定)
-
- OU:Organization Unit Name,组织单位名称,公司部门
1.2.4、生成自签CA证书
[root@k8s-master1 etcd]# cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
2022/11/29 01:42:38 [INFO] generating a new CA key and certificate from CSR
2022/11/29 01:42:38 [INFO] generate received request
2022/11/29 01:42:38 [INFO] received CSR
2022/11/29 01:42:38 [INFO] generating key: rsa-2048
2022/11/29 01:42:38 [INFO] encoded CSR
2022/11/29 01:42:38 [INFO] signed certificate with serial number 679003178885428426540893262351942198069353062273
# 当前目录下会生成 ca.pem和ca-key.pem文件
[root@k8s-master1 etcd]# ls
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem
1.3、使用自签CA签发etcd证书
1.3.1、配置etcd请求证书申请文件
cat > server-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"192.168.100.101",
"192.168.100.102",
"192.168.100.103"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai"
}
]
}
EOF
注:hosts项中ip为etcd集群内部通信的ip,如果后续etcd集群有扩容需求,那么在hosts项里可以预留几个IP
1.3.2、生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=etcd server-csr.json | cfssljson -bare server
# 查看
[root@k8s-master1 etcd]# ls
ca-config.json ca.csr ca-csr.json ca-key.pem ca.pem server.csr server-csr.json server-key.pem server.pem
1.4、部署etcd
先在master1节点操作,后边把配置拷贝到另外两个节点修改启动etcd即可
# 下载二进制包
cd /opt/software
wget https://github.com/etcd-io/etcd/releases/download/v3.5.6/etcd-v3.5.6-linux-amd64.tar.gz
# 创建工作目录
mkdir -p /opt/etcd/{bin,cfg,ssl}
tar -zxvf etcd-v3.5.6-linux-amd64.tar.gz
cp etcd-v3.5.6-linux-amd64/{etcd,etcdctl} /opt/etcd/bin/
# 拷贝证书至工作目录
cp ~/TLS/etcd/*.pem /opt/etcd/ssl/
# 添加etcd配置
cat > /opt/etcd/cfg/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd-1"
ETCD_DATA_DIR="/home/data/"
ETCD_LISTEN_PEER_URLS="https://192.168.100.101:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.100.101:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.100.101:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.100.101:2379"
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.100.101:2380,etcd-2=https://192.168.100.102:2380,etcd-3=https://192.168.100.103:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF
配置介绍:
- ETCD_NAME: 节点名称,集群中唯一
- ETCD_DATA_DIR:数据存放目录
- ETCD_LISTEN_PEER_URLS:集群通讯监听地址
- ETCD_LISTEN_CLIENT_URLS:客户端访问监听地址
- ETCD_INITIAL_CLUSTER:集群节点地址
- ETCD_INITIALCLUSTER_TOKEN:集群Token
- ETCD_INITIALCLUSTER_STATE:加入集群的状态:new是新集群,existing表示加入已有集群
1.4.1、使用systemd管理etcd
cat > /usr/lib/systemd/system/etcd.service << EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
[Service]
Type=notify
EnvironmentFile=/opt/etcd/cfg/etcd.conf
ExecStart=/opt/etcd/bin/etcd \
--cert-file=/opt/etcd/ssl/server.pem \
--key-file=/opt/etcd/ssl/server-key.pem \
--peer-cert-file=/opt/etcd/ssl/server.pem \
--peer-key-file=/opt/etcd/ssl/server-key.pem \
--trusted-ca-file=/opt/etcd/ssl/ca.pem \
--peer-trusted-ca-file=/opt/etcd/ssl/ca.pem \
--logger=zap
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
1.4.2、拷贝配置到另外两个节点
scp -r /opt/etcd/ 192.168.100.102:/opt/
scp -r /opt/etcd/ 192.168.100.103:/opt/
scp /usr/lib/systemd/system/etcd.service 192.168.100.102:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/etcd.service 192.168.100.103:/usr/lib/systemd/system/
1.4.3、修改另外两个节点中的etcd配置
#[Member]
ETCD_NAME="etcd-1" # 节点名称,可改为etcd-2和etcd-3
ETCD_DATA_DIR="/home/data/" # 自定义数据目录
ETCD_LISTEN_PEER_URLS="https://192.168.100.101:2380" #改为当前节点IP
ETCD_LISTEN_CLIENT_URLS="https://192.168.100.101:2379" #改为当前节点IP
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.100.101:2380" #改为当前节点IP
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.100.101:2379" #改为当前节点IP
ETCD_INITIAL_CLUSTER="etcd-1=https://192.168.100.101:2380,etcd-2=https://192.168.100.102:2380,etcd-3=https://192.168.100.103:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
1.4.4、启动etcd
需要注意的是三台节点的etcd服务需要同时启动,就三台机器,命令行工具多窗口执行即可
systemctl daemon-reload
systemctl start etcd
systemctl enable etcd
systemctl status etcd
# 查看集群节点状态如下即正常(记得修改命令中endpoint的IP为自己的IP)
[root@k8s-master1 software]# ETCDCTL_API=3 /opt/etcd/bin/etcdctl --cacert=/opt/etcd/ssl/ca.pem --cert=/opt/etcd/ssl/server.pem --key=/opt/etcd/ssl/server-key.pem --endpoints="https://192.168.100.101:2379,https://192.168.100.102:2379,https://192.168.100.103:2379" endpoint health --write-out=table
+------------------------------+--------+-------------+-------+
| ENDPOINT | HEALTH | TOOK | ERROR |
+------------------------------+--------+-------------+-------+
| https://192.168.100.101:2379 | true | 24.422088ms | |
| https://192.168.100.102:2379 | true | 23.776321ms | |
| https://192.168.100.103:2379 | true | 24.170148ms | |
+------------------------------+--------+-------------+-------+
2、安装docker
所有节点都操作
# 安装
yum install -y yum-utils
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install -y docker-ce-20.10.21
# 启动
systemctl start docker
systemctl enable docker
# 修改docker数据目录(可选操作)
cat > /etc/docker/daemon.json << EOF
{
"data-root": "/home/docker"
}
EOF
# 重启
systemctl restart docker
3、部署master节点
3.1、部署kube-apiver
3.1.1、生成kube-apiserver证书
自签CA证书(这个和上边那个etcd的CA区分开,单独给k8s使用的CA)
cd ~/TLS/k8s
# 添加CA配置
cat > ca-config.json << EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"expiry": "87600h",
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
]
}
}
}
}
EOF
cat > ca-csr.json << EOF
{
"CN": "kubernetes",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai",
"O": "k8s",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -initca ca-csr.json | cfssljson -bare ca -
使用自签CA签发kube-apiserver的证书
hosts里要写入集群内的所有节点IP,包括后续要用的负载均衡VIP的IP,如果有扩容需求,可以预留几个IP
cat > apiserver-csr.json << EOF
{
"CN": "kubernetes",
"hosts": [
"10.0.0.1",
"127.0.0.1",
"192.168.100.101",
"192.168.100.102",
"192.168.100.103",
"192.168.100.104",
"192.168.100.105",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai",
"O": "k8s",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes apiserver-csr.json | cfssljson -bare apiserver
3.1.2、下载二进制包,调整配置
官方地址:https://github.com/kubernetes/kubernetes/blob/master/CHANGELOG/CHANGELOG-1.23.md#downloads-for-v12315
如果下载不下来,可以点这里下载,为本次文章使用的所有软件包,官方拉取纯净版
# 下载/配置
cd /opt/software
wget https://dl.k8s.io/v1.23.15/kubernetes-server-linux-amd64.tar.gz
tar zxvf kubernetes-server-linux-amd64.tar.gz
mkdir -p /opt/kubernetes/{bin,cfg,ssl,logs}
cd kubernetes/server/bin
cp kube-apiserver kube-scheduler kube-controller-manager kubectl kubelet kube-proxy /opt/kubernetes/bin
cp kubectl /usr/bin
创建配置文件
两个\必须要啊。第一个是转义符,使用转义符是为了使用EOF保留换行符;第二个是换行符,不然就跑一行去了
好像不加换行符服务启动识别有点问题
cat > /opt/kubernetes/cfg/kube-apiserver.conf << EOF
KUBE_APISERVER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--etcd-servers=https://192.168.100.101:2379,https://192.168.100.102:2379,https://192.168.100.103:2379 \\
--bind-address=192.168.100.101 \\
--secure-port=6443 \\
--advertise-address=192.168.100.101 \\
--allow-privileged=true \\
--service-cluster-ip-range=10.0.0.0/16 \\
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction \\
--authorization-mode=RBAC,Node \\
--enable-bootstrap-token-auth=true \\
--token-auth-file=/opt/kubernetes/cfg/token.csv \\
--service-node-port-range=30000-32767 \\
--kubelet-client-certificate=/opt/kubernetes/ssl/apiserver.pem \\
--kubelet-client-key=/opt/kubernetes/ssl/apiserver-key.pem \\
--tls-cert-file=/opt/kubernetes/ssl/apiserver.pem \\
--tls-private-key-file=/opt/kubernetes/ssl/apiserver-key.pem \\
--client-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--service-account-issuer=https://kubernetes.default.svc.cluster.local \\
--service-account-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--etcd-cafile=/opt/etcd/ssl/ca.pem \\
--etcd-certfile=/opt/etcd/ssl/server.pem \\
--etcd-keyfile=/opt/etcd/ssl/server-key.pem \\
--requestheader-client-ca-file=/opt/kubernetes/ssl/ca.pem \\
--proxy-client-cert-file=/opt/kubernetes/ssl/apiserver.pem \\
--proxy-client-key-file=/opt/kubernetes/ssl/apiserver-key.pem \\
--requestheader-allowed-names=kubernetes \\
--requestheader-extra-headers-prefix=X-Remote-Extra- \\
--requestheader-group-headers=X-Remote-Group \\
--requestheader-username-headers=X-Remote-User \\
--enable-aggregator-routing=true \\
--audit-log-maxage=30 \\
--audit-log-maxbackup=3 \\
--audit-log-maxsize=100 \\
--audit-log-path=/opt/kubernetes/logs/k8s-audit.log"
EOF
配置介绍:
- –logtostderr :启用日志(true为输出到标准输出,false为输出到日志文件里)
- –v :日志等级
- –log-dir :日志目录
- –etcd-servers :etcd集群地址
- –bind-address :监听地址
- –secure-port :https安全端口
- –advertise-address :集群通告地址
- –allow-privileged :启动授权
- –service-cluster-ip-range :Service虚拟IP地址段,这里掩码给16位,可以创建(2的16次方-2)=65534个地址
- –enable-admission-plugins : 准入控制模块
- –authorization-mode :认证授权,启用RBAC授权和节点自管理
- –enable-bootstrap-token-auth :启用TLS bootstrap机制
- –token-auth-file :bootstrap token文件
- –service-node-port-range :Service nodeport类型默认分配端口范围
- –kubelet-client-xxx :apiserver访问kubelet客户端证书
- –tls-xxx-file :apiserver https证书
- –service-account-issuer:此参数可作为服务账号令牌发放者的身份标识(Identifier)详细可参考官方解析和阿里云解析
- –service-account-signing-key-file:指向包含当前服务账号令牌发放者的私钥的文件路径
- –etcd-xxxfile :连接etcd集群证书
- –requestheader-client-ca-file,–proxy-client-cert-file,–proxy-client-key-file,–requestheader-allowed-names,–requestheader-extra-headers-prefix,–requestheader-group-headers,–requestheader-username-headers,–enable-aggregator-routing:启动聚合层网关配置
- –audit-log-xxx :审计日志
更多参数可查看官方介绍
拷贝生成证书到工作目录
cp ~/TLS/k8s/*.pem /opt/kubernetes/ssl/
3.1.3、启用TLS bootstrapping机制
当集群开启了 TLS 认证后,每个节点的 kubelet 组件都要使用由 apiserver 使用的 CA 签发的有效证书才能与 apiserver 通讯,此时如果节点多起来,为每个节点单独签署证书将是一件非常繁琐的事情;TLS bootstrapping 功能就是让 kubelet 先使用一个预定的低权限用户连接到 apiserver,然后向 apiserver 申请证书,kubelet 的证书由 apiserver 动态签署
详细内容见官方说明
工作流程:
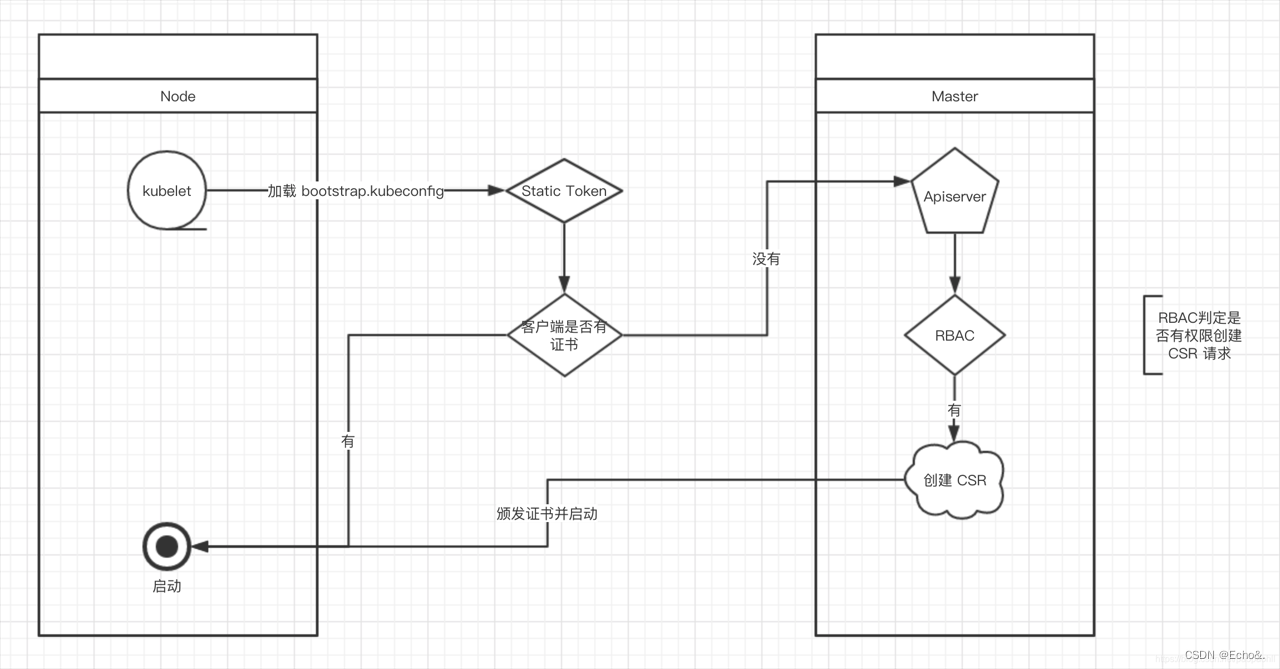
创建令牌认证文件
# 生成随机数
[root@k8s-master1 cfg]# head -c 16 /dev/urandom | od -An -t x | tr -d ' '
a2dfd3748230d54213367c6dcb63efde
# 将生成的数创建token文件(将上边生成的数替换第一个值)
cat > /opt/kubernetes/cfg/token.csv << EOF
a2dfd3748230d54213367c6dcb63efde,kubelet-bootstrap,10001,"system:node-bootstrapper"
EOF
3.1.4、配置systemd管理服务
cat > /usr/lib/systemd/system/kube-apiserver.service << EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-apiserver.conf
ExecStart=/opt/kubernetes/bin/kube-apiserver \$KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
启动服务
systemctl daemon-reload
systemctl start kube-apiserver
systemctl enable kube-apiserver
systemctl status kube-apiserver
小提示:
启动会报下边这俩错,忽略就行,这个是说这俩参数准备弃用了,但是现在还能用(就跟前几年说移除docker一样)
FlagFlag --logtostderr has been deprecated, will be removed in a future release, see https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/2845-deprecate-klog-specific-flags-in-k8s-components
Flag --log-dir has been deprecated, will be removed in a future release, see https://github.com/kubernetes/enhancements/tree/master/keps/sig-instrumentation/2845-deprecate-klog-specific-flags-in-k8s-components
3.2、部署kube-controller-manager
3.2.1、生成证书
cd ~/TLS/k8s
# 创建证书请求文件
cat > kube-controller-manager-csr.json << EOF
{
"CN": "system:kube-controller-manager",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-controller-manager-csr.json | cfssljson -bare kube-controller-manager
3.2.2、生成kubeconfig文件 (重点)
该文件存放一些集群组件之间交互的认证信息,用于集群组件访问apiserver,操作分为四步
前三步都会往配置文件里写入一些内容,可以每歩执行前后对照着内容看看
A.生成kubeconfig文件,设置集群参数
# 配置个临时变量
KUBE_CONFIG="/opt/kubernetes/cfg/kube-controller-manager.kubeconfig"
KUBE_APISERVER="https://192.168.100.101:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
配置介绍:
- set-cluster:设置集群的名字(这里设置为kubernetes)
- –certificate-authority:集群的CA证书
- –embed-certs:将ca.pem证书内容嵌入到生成的 kubectl.kubeconfig 文件中(不加时,写入的是证书文件路径)。
- –server:apiserver地址
- –kubeconfig:文件名称,这里给controller-manager用,就叫做kube-controller-manager.kubeconfig
该命令执行完会在指定目录下生成一个我们命名的那个叫kube-controller-manager.kubeconfig的文件,文件里只有集群的信息和CA证书内容
B.设置客户端认证参数
kubectl config set-credentials kube-controller-manager \
--client-certificate=./kube-controller-manager.pem \
--client-key=./kube-controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
配置介绍:
- set-credentials:设置客户端名字,这里用连接apiserver的组件名称
- –client-certificate:客户端的证书文件,apiserver用来做验证
- –client-key:也是客户端证书,key文件
上边这两歩,就相当于之前说的范例里A公司和中介C公司的介绍信内容内嵌在这个配置文件中,去拜访B公司时候使用
C.设置上下文参数
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-controller-manager \
--kubeconfig=${KUBE_CONFIG}
配置介绍:
- set-context:设置上下文,设置配置文件中的contexts项,后边跟上下文名称,这里设置为default(多用于操作多个k8s集群时区分当前是在哪个上下文,即哪个集群里操作的)
- –cluster:集群名称,要和上边第一步的名称完全一致
- –user:用户名称,要和第二歩的客户端名称完全一致
D.设置当前默认上下文
使用kubeconfig中的一个环境项作为当前配置,官方解读
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
# 等集群拉起后,可以通过这个命令查看当前所在的是哪个集群的上下文
kubectl config current-context
配置说明:
- 设置context(上下文)用哪个kubeconfig,这里就是设置default的上下文,使用我们上边配置的kube-controller-manager.kubeconfig
3.2.3、创建controller-manager配置文件
cat > /opt/kubernetes/cfg/kube-controller-manager.conf << EOF
KUBE_CONTROLLER_MANAGER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--leader-elect=true \\
--kubeconfig=/opt/kubernetes/cfg/kube-controller-manager.kubeconfig \\
--bind-address=127.0.0.1 \\
--allocate-node-cidrs=true \\
--cluster-cidr=10.244.0.0/16 \\
--service-cluster-ip-range=10.0.0.0/24 \\
--cluster-signing-cert-file=/opt/kubernetes/ssl/ca.pem \\
--cluster-signing-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--root-ca-file=/opt/kubernetes/ssl/ca.pem \\
--service-account-private-key-file=/opt/kubernetes/ssl/ca-key.pem \\
--cluster-signing-duration=87600h0m0s"
EOF
配置介绍:
- –kubeconfig:连接apiserver配置文件。
- –leader-elect:当该组件启动多个时,自动选举(HA)
- –cluster-signing-cert-file:自动为kubelet颁发证书的CA
- –cluster-signing-key-file:自动为kubelet颁发证书的CA
3.2.4、配置systemd管理、启动服务
# 配置systemd管理
cat > /usr/lib/systemd/system/kube-controller-manager.service << EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-controller-manager.conf
ExecStart=/opt/kubernetes/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动服务
systemctl daemon-reload
systemctl start kube-controller-manager
systemctl enable kube-controller-manager
systemctl status kube-controller-manager
小提示:
启动会额外有这俩报错,是因为没有配置cloud-provider参数,这个对于内部使用的集群基本用不着
Dec 20 21:34:03 cluster-node1 kube-controller-manager[72926]: E1220 21:34:03.576016 72926 core.go:212] failed to start cloud node lifecycle controller: no cloud provider provided
Dec 20 21:34:03 cluster-node1 kube-controller-manager[72926]: E1220 21:34:03.596638 72926 core.go:92] Failed to start service controller: WARNING: no cloud provider provided, services of type LoadBalancer will fail
3.3、部署kube-scheduler
也是一样的步骤:生成证书、生成kubeconfig文件、创建配置文件、systemd管理及启动服务
3.3.1、生成证书
# 切换工作目录
cd ~/TLS/k8s
# 创建证书请求文件
cat > kube-scheduler-csr.json << EOF
{
"CN": "system:kube-scheduler",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-scheduler-csr.json | cfssljson -bare kube-scheduler
3.3.2、生成kubeconfig文件
KUBE_CONFIG="/opt/kubernetes/cfg/kube-scheduler.kubeconfig"
KUBE_APISERVER="https://192.168.100.101:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-scheduler \
--client-certificate=./kube-scheduler.pem \
--client-key=./kube-scheduler-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-scheduler \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
3.3.3、创建服务配置文件
cat > /opt/kubernetes/cfg/kube-scheduler.conf << EOF
KUBE_SCHEDULER_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--leader-elect \\
--kubeconfig=/opt/kubernetes/cfg/kube-scheduler.kubeconfig \\
--bind-address=127.0.0.1"
EOF
3.3.4、配置systemd管理、服务启动
# 配置systemd管理
cat > /usr/lib/systemd/system/kube-scheduler.service << EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-scheduler.conf
ExecStart=/opt/kubernetes/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl start kube-scheduler
systemctl enable kube-scheduler
systemctl status kube-scheduler
3.4、配置kubectl管理集群
3.4.1、配置kubectl证书
cd ~/TLS/k8s
cat > admin-csr.json <<EOF
{
"CN": "admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai",
"O": "system:masters",
"OU": "System"
}
]
}
EOF
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin
3.4.2、配置kubectl使用的kubeconfig
mkdir /root/.kube
KUBE_CONFIG="/root/.kube/config"
KUBE_APISERVER="https://192.168.100.101:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials cluster-admin \
--client-certificate=./admin.pem \
--client-key=./admin-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=cluster-admin \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
3.4.3、验证
各组件状态正常即可
[root@k8s-master1 k8s]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Healthy ok
controller-manager Healthy ok
etcd-2 Healthy {"health":"true","reason":""}
etcd-0 Healthy {"health":"true","reason":""}
etcd-1 Healthy {"health":"true","reason":""}
3.5、部署kubelet
master也是要作为节点存在的,所以也要部署kubelet和kube-proxy
3.5.1、定义kubelet配置参数
cat > /opt/kubernetes/cfg/kubelet-config.yml << EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 10255
cgroupDriver: cgroupfs
clusterDNS:
- 10.0.0.240
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /opt/kubernetes/ssl/ca.pem
authorization:
mode: Webhook
webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 110
EOF
配置说明:
更多配置详情可翻阅官方范例和官方参数解读
- evictionHard:驱逐资源硬限制(当达到下面配置项的阈值后会触发驱逐)
- imagefs.available:容器运行时镜像存储空间剩余量
- memory.available:宿主机可用内存
- nodefs.available:宿主机可用磁盘空间(一般是指根目录)
- nodefs.inodesFree:宿主机可用inode(df -i可查看总量)
3.5.2、创建配置文件
cat > /opt/kubernetes/cfg/kubelet.conf << EOF
KUBELET_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--hostname-override=k8s-master1 \\
--network-plugin=cni \\
--kubeconfig=/opt/kubernetes/cfg/kubelet.kubeconfig \\
--bootstrap-kubeconfig=/opt/kubernetes/cfg/bootstrap.kubeconfig \\
--config=/opt/kubernetes/cfg/kubelet-config.yml \\
--cert-dir=/opt/kubernetes/ssl \\
--pod-infra-container-image=registry.cn-hangzhou.aliyuncs.com/google-containers/pause-amd64:3.0"
EOF
配置说明:
- –hostname-override :kubectl get node显示的名称,集群唯一,保持和主机名一致即可(不可重复)
- –network-plugin:启用CNI(官方解读)
- –kubeconfig:空路径,会自动生成,后面用于连接apiserver
- –bootstrap-kubeconfig:首次启动向apiserver申请证书的配置(下一步就是生成这个配置)
- –config:配置文件参数(上一步配置的参数文件)
- –cert-dir:kubelet证书目录
- –pod-infra-container-image :管理Pod网络的pause容器的镜像
3.5.3、生成bootstrap.kubeconfig文件
# 临时变量
KUBE_CONFIG="/opt/kubernetes/cfg/bootstrap.kubeconfig"
KUBE_APISERVER="https://192.168.100.101:6443"
TOKEN="a2dfd3748230d54213367c6dcb63efde" # !!与/opt/kubernetes/cfg/token.csv文件中数据保持一致
# 生成配置
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials "kubelet-bootstrap" \
--token=${TOKEN} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user="kubelet-bootstrap" \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
3.5.4、授权kubelet-bootstrap用户允许请求证书
在启动kubelet后,kubelet会自动用上一步的kubeconfig配置去向apiserver申请证书,而配置里的client用户是kubelet-bootstrap,所以要先给该用户一个权限才可以
kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap
3.5.5、配置systemd管理、启动服务
cat > /usr/lib/systemd/system/kubelet.service << EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kubelet.conf
ExecStart=/opt/kubernetes/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# 启动
systemctl daemon-reload
systemctl start kubelet
systemctl status kubelet
3.5.6、批准kubelet的证书申请
# 查看证书申请csr(certificatesigningrequest),状态为pending等待中
[root@k8s-master1 ~]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
node-csr-6m-PtPGVEiw089UJ9dnNf3cjbiMdKizuq27umnYdD7I 86s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap <none> Pending
# 批准kubelet证书申请
[root@k8s-master1 ~]# kubectl certificate approve node-csr-6m-PtPGVEiw089UJ9dnNf3cjbiMdKizuq27umnYdD7I
certificatesigningrequest.certificates.k8s.io/node-csr-6m-PtPGVEiw089UJ9dnNf3cjbiMdKizuq27umnYdD7I approved
# 查看csr状态,状态为Approved,Issued(已批准)
[root@k8s-master1 ~]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
node-csr-6m-PtPGVEiw089UJ9dnNf3cjbiMdKizuq27umnYdD7I 6m12s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap <none> Approved,Issued
# 查看node(cni网络插件还没安装,所以当前还是NotReady状态)
[root@k8s-master1 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 NotReady <none> 39s v1.23.15
3.6、部署kube-proxy
3.6.1、生成证书
# 切换到工作目录
cd ~/TLS/k8s
# 创建证书请求文件
cat > kube-proxy-csr.json << EOF
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"L": "ShangHai",
"ST": "ShangHai",
"O": "k8s",
"OU": "System"
}
]
}
EOF
# 生成证书
cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes kube-proxy-csr.json | cfssljson -bare kube-proxy
3.6.2、生成kubeconfig配置文件
KUBE_CONFIG="/opt/kubernetes/cfg/kube-proxy.kubeconfig"
KUBE_APISERVER="https://192.168.100.101:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/opt/kubernetes/ssl/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-credentials kube-proxy \
--client-certificate=./kube-proxy.pem \
--client-key=./kube-proxy-key.pem \
--embed-certs=true \
--kubeconfig=${KUBE_CONFIG}
kubectl config set-context default \
--cluster=kubernetes \
--user=kube-proxy \
--kubeconfig=${KUBE_CONFIG}
kubectl config use-context default --kubeconfig=${KUBE_CONFIG}
3.6.3、定义配置参数,指定kubeconfig文件
cat > /opt/kubernetes/cfg/kube-proxy-config.yml << EOF
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
metricsBindAddress: 0.0.0.0:10249
clientConnection:
kubeconfig: /opt/kubernetes/cfg/kube-proxy.kubeconfig
hostnameOverride: k8s-master1
#mode: "ipvs"
clusterCIDR: 10.244.0.0/16
EOF
单独介绍下mode参数
这个是配置kube-proxy的工作模式,目前用的基本就是这两种,都是基于内核的netfilter实现的:
- iptables: 默认使用的模式,通过创建一条条iptables规则链来访问集群内service。这种模式pod内ping不通service的IP
- ipvs: 专门用来做负载均衡的技术,lvs就用的这个。pod可以ping通service的IP
这里就先不展开详细说了,要单独开单章说明。
这里部署就先用默认的iptables模式就可以,在服务量级不大的时候,iptables和ipvs性能差不多
3.6.4、创建配置文件
cat > /opt/kubernetes/cfg/kube-proxy.conf << EOF
KUBE_PROXY_OPTS="--logtostderr=false \\
--v=2 \\
--log-dir=/opt/kubernetes/logs \\
--config=/opt/kubernetes/cfg/kube-proxy-config.yml"
EOF
3.6.5、配置systemd管理、启动服务
cat > /usr/lib/systemd/system/kube-proxy.service << EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=/opt/kubernetes/cfg/kube-proxy.conf
ExecStart=/opt/kubernetes/bin/kube-proxy \$KUBE_PROXY_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF
# 启动服务
systemctl daemon-reload
systemctl start kube-proxy
systemctl enable kube-proxy
systemctl status kube-proxy
3.7、安装cni网络插件
这里选择用calico来作为网络插件使用
calico官网:https://www.tigera.io/project-calico/
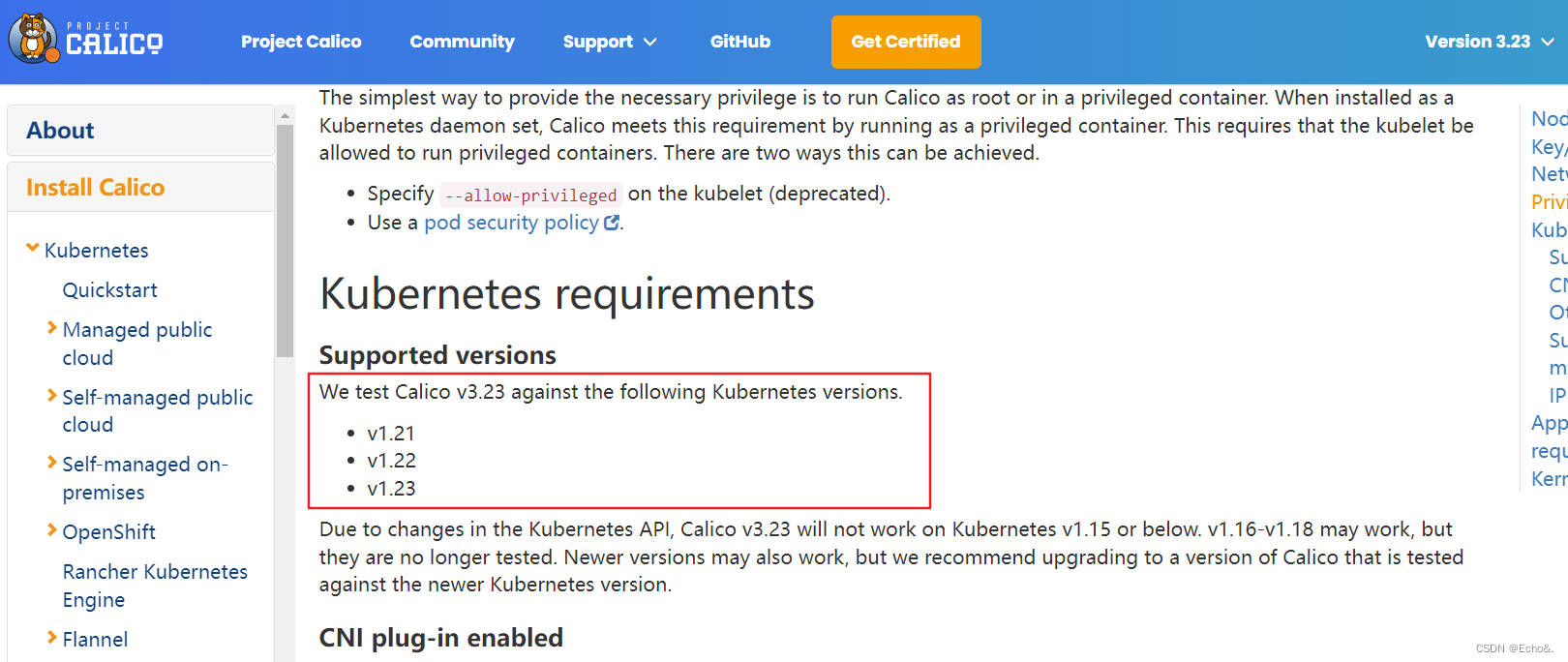
查看版本对应关系
从官网文档说明里得知,calico-v3.23版本支持k8s的v1.23版本,所以这里就选择安装v3.23版本好了
3.7.1、拉取配置
如果拉取不到,可以点这里下载,为本次文章使用的所有软件包,官方拉取纯净版
mkdir /opt/kubernetes/calico && cd /opt/kubernetes/calico
# 下载官方yaml文件
curl https://projectcalico.docs.tigera.io/archive/v3.23/manifests/calico.yaml -O
3.7.2、根据环境修改文件配置项
修改calico.yaml中calico-node容器的env环境变量
a、改CALICO_IPV4POOL_CIDR项为我们上边定义的clusterCIDR(指定pod的IP池)
containers:
- name: calico-node
image: docker.io/calico/node:v3.23.5
..........
- name: CALICO_IPV4POOL_CIDR
value: "10.244.0.0/16"
b、添加 IP_AUTODETECTION_METHOD 环境变量:
containers:
- name: calico-node
image: docker.io/calico/node:v3.23.5
..........
env:
# 这是需要我们添加的环境变量
- name: IP_AUTODETECTION_METHOD
value: "interface=ens33"
#我这里网卡是ens33,就填的ens33
如果这个不指定的话,可能calico-node启动会报这个错
Readiness probe failed: calico/node is not ready: BIRD is not ready: Error querying BIRD: unable to connect to BIRDv4 socket: dial unix /var/run/calico/bird.ctl: connect: connection refused
3.7.3、启动服务
可以提前把yaml里container所需镜像下好,再启动
# 拉起
kubectl apply -f calico.yaml
# 查看服务
[root@k8s-master1 calico]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-54756b744f-nkxxm 1/1 Running 0 4m36s
calico-node-8kmr5 1/1 Running 0 4m36s
# 等calico的pod都Running后,查看node状态也变为ready
[root@k8s-master1 calico]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 97m v1.23.15
如果有启动失败,可以describe查看event或者docker logs查看容器日志排错
这样一个单节点集群就完成了👍
3.8、配置apiserver访问kubelet权限
允许使用kubectl来查看pod日志
不然会有如下报错
Error from server (Forbidden): Forbidden (user=kubernetes, verb=get, resource=nodes, subresource=proxy) ( pods/log calico-node-8kmr5)
编辑配置并启动
mkdir /opt/kubernetes/yaml && cd /opt/kubernetes/yaml
# 配置
cat > apiserver-to-kubelet-rbac.yaml << EOF
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
annotations:
rbac.authorization.kubernetes.io/autoupdate: "true"
labels:
kubernetes.io/bootstrapping: rbac-defaults
name: system:kube-apiserver-to-kubelet
rules:
- apiGroups:
- ""
resources:
- nodes/proxy
- nodes/stats
- nodes/log
- nodes/spec
- nodes/metrics
- pods/log
verbs:
- "*"
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: system:kube-apiserver
namespace: ""
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: system:kube-apiserver-to-kubelet
subjects:
- apiGroup: rbac.authorization.k8s.io
kind: User
name: kubernetes
EOF
kubectl apply -f apiserver-to-kubelet-rbac.yaml
这样再去执行kubectl logs就可以了
4、新增Worker节点
现在192.168.100.101(master)已经拉起一套单节点的k8s集群,后边就是把另外两个node节点也给加进来
4.1、node节点准备
mkdir -p /opt/kubernetes/{cfg,bin,log,ssl}
4.2、把master上的配置信息拷贝到node节点中(master节点操作)
注:这里注意,要把cfg/kubelet.kubeconfig这个文件删除,因为是apiserver那边颁发证书后自动生成的,每个节点不一样
scp /opt/kubernetes/cfg/{kubelet*,kube-proxy*,bootstrap*} 192.168.100.102:/opt/kubernetes/cfg/
scp /opt/kubernetes/cfg/{kubelet*,kube-proxy*,bootstrap*} 192.168.100.103:/opt/kubernetes/cfg/
scp /opt/kubernetes/bin/{kubelet*,kube-proxy*} 192.168.100.102:/opt/kubernetes/bin/
scp /opt/kubernetes/bin/{kubelet*,kube-proxy*} 192.168.100.103:/opt/kubernetes/bin/
scp /opt/kubernetes/ssl/ca.pem 192.168.100.102:/opt/kubernetes/ssl/
scp /opt/kubernetes/ssl/ca.pem 192.168.100.103:/opt/kubernetes/ssl/
scp /usr/lib/systemd/system/{kubelet,kube-proxy}.service 192.168.100.102:/usr/lib/systemd/system/
scp /usr/lib/systemd/system/{kubelet,kube-proxy}.service 192.168.100.103:/usr/lib/systemd/system/
4.3、修改配置(node节点操作)
# a. 修改cfg/kubelet.conf文件中hostname-override值为所在node节点主机名
vim cfg/kubelet.conf
.....
--hostname-override=k8s-node1 \
.....
# b.修改cfg/kube-proxy-config.yml文件中hostnameOverride值为所在node节点主机名
vim kube-proxy-config.yml
.....
hostnameOverride: k8s-node1
......
# c.删除kubelet.kubconfig
rm /opt/kubernetes/cfg/kubelet.kubeconfig
4.4、启动服务(node节点操作)
systemctl daemon-reload
systemctl start kubelet kube-proxy
systemctl enable kubelet kube-proxy
4.5、master中查看证书申请并同意
[root@k8s-master1 kubernetes]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
node-csr-1seYXEb3ZkQvuSPVuW5_jKM8y0MhCOBZ5xX4qkcigUo 13s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap <none> Pending
node-csr-V2YmiDZhAu1CY87EZbZAKCweGHF1JZb635oecD39l-c 3m14s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap <none> Pending
[root@k8s-master1 kubernetes]#
[root@k8s-master1 kubernetes]# kubectl certificate approve node-csr-1seYXEb3ZkQvuSPVuW5_jKM8y0MhCOBZ5xX4qkcigUo node-csr-V2YmiDZhAu1CY87EZbZAKCweGHF1JZb635oecD39l-c
certificatesigningrequest.certificates.k8s.io/node-csr-1seYXEb3ZkQvuSPVuW5_jKM8y0MhCOBZ5xX4qkcigUo approved
certificatesigningrequest.certificates.k8s.io/node-csr-V2YmiDZhAu1CY87EZbZAKCweGHF1JZb635oecD39l-c approved
4.6、查看集群node状态
会在新加节点上启动一些初始服务,如calico-node,所以需要稍等一会状态就可变为ready
[root@k8s-master1 kubernetes]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 151m v1.23.15
k8s-node1 Ready <none> 4m49s v1.23.15
k8s-node2 Ready <none> 4m49s v1.23.15
到此,简易的单master,双node的三节点集群就搭建完成了
5、部署Coredns
一般情况下,pod之间通信都是用service的clusterIP,但是ip有难以记忆等问题,所以需要加一个DNS来解析,可以使用service_name来进行服务之间相互调用。大概是从k8s的1.11版本以来,k8s就直接从kube-dns转为coredns了,所以本次DNS选择coredns
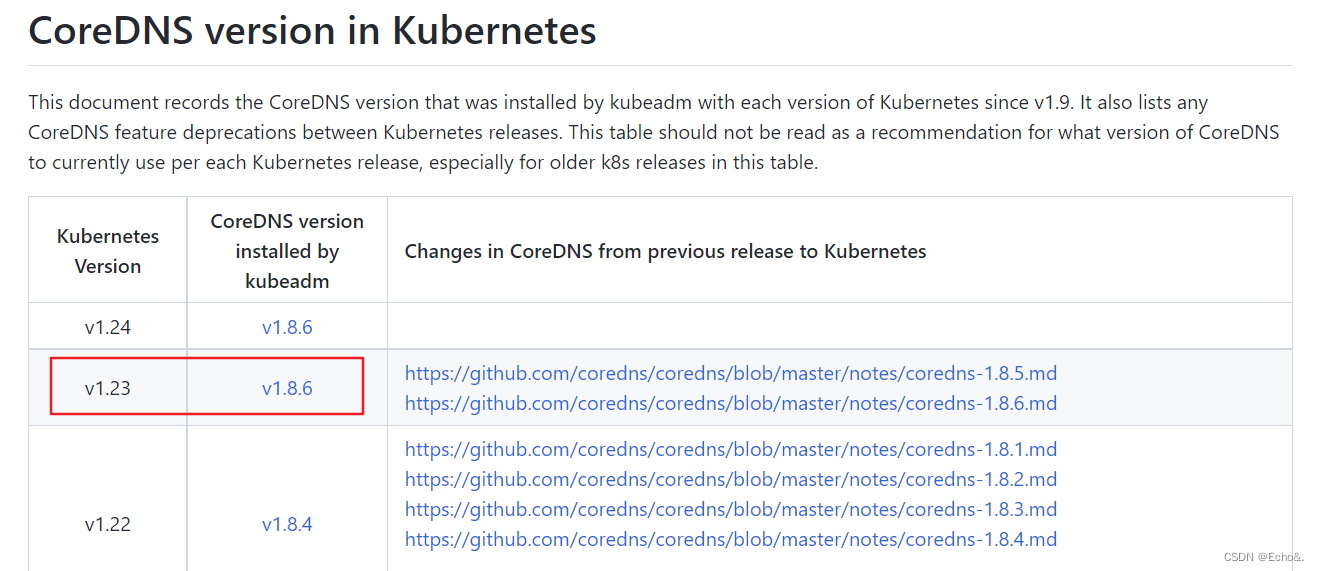
还是一如既往的去看下coredns和k8s之间的版本联系,通过这里官方给出的kubeadm部署使用的版本记录得出,coredns:1.8.6肯定是可以在k8s1.23版本中使用的,所以本次就使用1.8.6版本的coredns了
5.1、拉取配置
如果配置和镜像下载不下来,可以点这里下载,为本次文章使用的所有软件包,官方拉取纯净版
# 这里就用容器形式部署DNS了,方便快捷
mkdir /opt/kubernetes/coredns && cd /opt/kubernetes/coredns
curl https://raw.githubusercontent.com/kubernetes/kubernetes/master/cluster/addons/dns/coredns/coredns.yaml.base -O
mv coredns.yaml.base coredns.yaml
5.2、修改配置
修改coredns.yaml中的带有__DNS__的值
1、原文:__DNS__DOMAIN__
改为:cluster.local (dns域,和上边kubelet中配置的保持一致)
2、原文:__DNS__MEMORY__LIMIT__
改为:500Mi
3、原文:__DNS__SERVER__
改为:10.0.0.240 (这里是dns的svc—ip,要和上边kubelet中配置的clusterDNS值一致)
修改使用镜像
原文:image: registry.k8s.io/coredns/coredns:v1.10.0
改为:image: coredns/coredns:1.8.6
5.3、运行
kubectl apply -f coredns.yaml
[root@k8s-master1 coredns]# kubectl get pod,svc -n kube-system
NAME READY STATUS RESTARTS AGE
pod/calico-kube-controllers-54756b744f-p9n9m 1/1 Running 0 5h2m
pod/calico-node-6k4xn 1/1 Running 0 5h2m
pod/calico-node-cnzm9 1/1 Running 0 5h2m
pod/calico-node-qqwnr 1/1 Running 0 5h2m
pod/coredns-57c6b56d8d-hcn58 1/1 Running 0 21m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/kube-dns ClusterIP 10.0.0.240 <none> 53/UDP,53/TCP,9153/TCP 22m
5.4、测试
# 查看当前的svc
[root@k8s-master1 coredns]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.0.0.1 <none> 443/TCP 6h59m
# 启动一个临时pod(busybox)测试解析
[root@k8s-master1 coredns]# kubectl run -ti --rm busybox-test --image=busybox:1.35 sh
/ # nslookup kubernetes
Server: 10.0.0.240
Address: 10.0.0.240:53
** server can't find kubernetes.cluster.local: NXDOMAIN
Name: kubernetes.default.svc.cluster.local
Address: 10.0.0.1
# 测试端口
/ # nc -vz kubernetes 443
kubernetes (10.0.0.1:443) open
/ #
/ # nc -vz 10.0.0.1 443
10.0.0.1 (10.0.0.1:443) open
6、部署一个官方的dashboard
根据官方配置即可kubernetes/dashboard:用于 Kubernetes 集群的通用 Web UI (github.com)
6.1、拉取官方配置文件
如果拉取不到,可以点这里下载,为本次文章使用的所有软件包,官方拉取纯净版
mkdir /opt/kubernetes/dashboard && cd /opt/kubernetes/dashboard
curl https://raw.githubusercontent.com/kubernetes/dashboard/v2.7.0/aio/deploy/recommended.yaml -O
6.2、修改配置
集群角色简介:
- ClusterRole:是集群的权限
- ServiceAccount:是集群的用户
- ClusterRoleBinding:起到把权限和用户绑在一起的作用
官方的配置里创建的serviceaccount用户(kubernetes-dashboard)没有权限打开面板页面
所以我们把默认用户绑到集群原有的cluster-admin规则上即可,修改配置
# ClusterRoleBinding 这块内容修改为如下内容,需要修改的地方是roleRef.name,
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kubernetes-dashboard
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
#name: kubernetes-dashboard
name: cluster-admin
subjects:
- kind: ServiceAccount
name: kubernetes-dashboard
namespace: kubernetes-dashboard
# 修改service
# 默认是ClusterIP类型,要改为NodePort方便访问(加一行即可)
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
type: NodePort
ports:
- port: 443
targetPort: 8443
selector:
k8s-app: kubernetes-dashboard
6.3、拉起服务
[root@k8s-master1 dashboard]# kubectl apply -f recommended.yaml
[root@k8s-master1 dashboard]# kubectl get pod,svc -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
pod/dashboard-metrics-scraper-6f669b9c9b-6hkkf 1/1 Running 0 56m
pod/kubernetes-dashboard-758765f476-nh988 1/1 Running 0 56m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/dashboard-metrics-scraper ClusterIP 10.0.203.46 <none> 8000/TCP 56m
service/kubernetes-dashboard NodePort 10.0.51.31 <none> 443:30143/TCP 56m
6.4、获取token
[root@k8s-master1 dashboard]# kubectl get secret -n kubernetes-dashboard |grep dashboard-token
kubernetes-dashboard-token-2qcjl kubernetes.io/service-account-token 3 10m
[root@k8s-master1 dashboard]# kubectl describe secret kubernetes-dashboard-token-2qcjl -n kubernetes-dashboard
Name: kubernetes-dashboard-token-2qcjl
Namespace: kubernetes-dashboard
.......
token: eyJhbGciOiJSUzI1NiIsImtpZCI6.......# 复制这段内容,是下边登录的密码
6.5、访问测试(Chrome)
现在新版本可以直接在Chrome访问了
192.168.100.101:30143(IP是集群任意节点IP,端口是上边service/kubernetes-dashboard的port值)
输入上一步获取的token后,登录有如下内容即为成功
7、再装一个metrics
实现目的:可以通过kubectl top xxx看状态等
7.1、拉取官方配置
如果拉取不到,可以点这里下载,为本次文章使用的所有软件包,官方拉取纯净版
mkdir /opt/kubernetes/metrics && cd /opt/kubernetes/metrics
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
7.2、修改配置
因为yaml里用的镜像是国外的,所以要改一下
先找一个可用的镜像
[root@k8s-master1 metrics]# docker search metrics-server
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mirrorgooglecontainers/metrics-server-amd64 17
bitnami/metrics-server Bitnami Docker Image for Metrics Server 13 [OK]
rancher/metrics-server 5
rancher/metrics-server-amd64
2
修改yaml中镜像
原内容:
image: k8s.gcr.io/metrics-server/metrics-server:v0.6.2
imagePullPolicy: IfNotPresent
改为:
image: bitnami/metrics-server:0.6.2
imagePullPolicy: IfNotPresent
添加不验证证书配置
不然启动后describe时events里会报Readiness probe failed: HTTP probe failed with statuscode: 500
原内容:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
image: bitnami/metrics-server:0.6.2
新增:
containers:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --metric-resolution=15s
- --kubelet-insecure-tls # 新增的这个,不验证证书
image: bitnami/metrics-server:0.6.2
7.3、拉起服务及验证
kubectl apply -f components.yaml
[root@k8s-master1 metrics]# kubectl get pod -n kube-system |grep metr
metrics-server-7c65894ccb-8dxnr 1/1 Running 0 5m32s
# 验证
[root@k8s-master1 metrics]# kubectl top nodes
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
k8s-master1 176m 8% 1329Mi 70%
k8s-node1 76m 3% 985Mi 52%
k8s-node2 83m 4% 1065Mi 56%
到此,基本上就差不多了,下边为扩展(集群扩容、高可用)内容
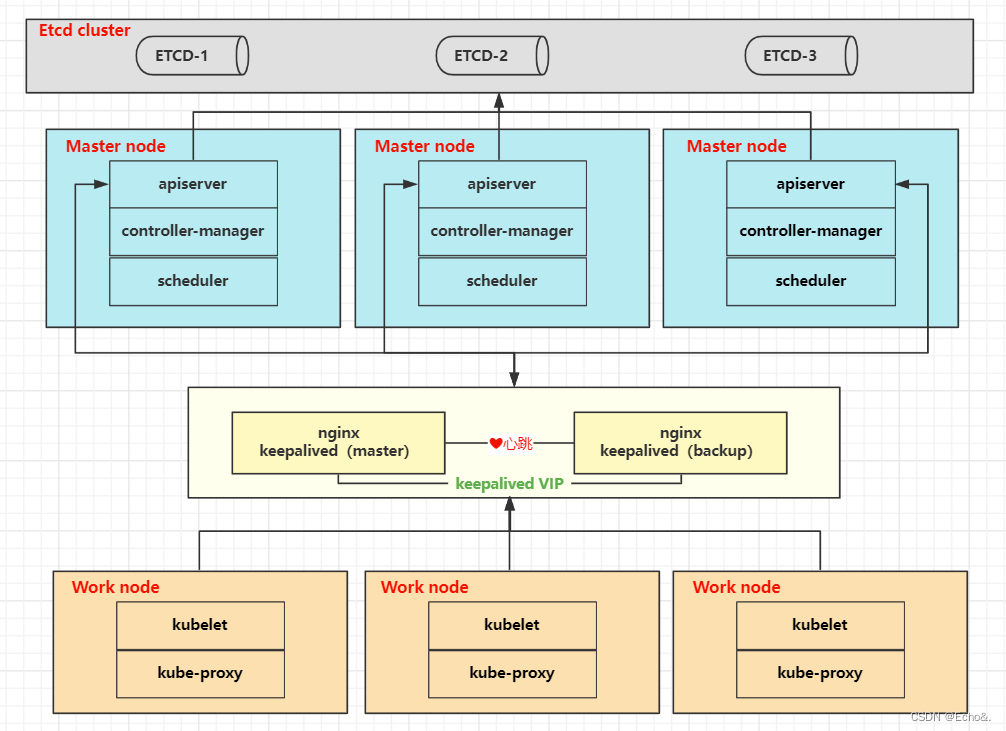
四、扩容-新增master节点(高可用架构)
k8s集群利用deployment实现对pod应用级的高可用,那么master节点上的etcd、apiserver、scheduler和controller manager要怎么实现高可用呢?
首先这四者的运行高可用方式是有区别的
etcd: 我们这次就已经部署分布式的三节点etcd集群了,即为高可用
scheduler、controller manager:
- 是依赖ETCD实现选主的功能,同一时间只有一个leader节点工作。
- 他们每个节点都会在etcd中注册endpoint信息,会定期更新注册信息(相当于心跳了)
- 每个从节点的服务会定期检查endpoint的信息,如果endpoint的信息在时间范围内没有更新,它们会尝试更新自己为leader节点。
apiserver:
- 接入层服务,集群的唯一入口,相当于一个无状态的服务
- 不同于scheduler和controller,需要借助etcd来选主,多节点时,无论在哪个apiserver节点请求,都是相同的结果
- 高可用可以多建几个apiserver的实例,然后通过nginx负载均衡+keepalived(VIP)来实现高可用
粗浅的高可用架构图
话不多说,继续
1、部署新增master2节点
按照规划,这里要新增一台192.168.100.104机器,划为master2
1.1、系统初始化+安装docker
这个前边步骤里都有,就不赘述了,按照前边的步骤
【二.1、系统初始化】和【三.2、安装docker】操作即可
1.2、开始部署
因master2的部署操作和master1基本一致,所以就把配置文件拷贝过来,修改下启动服务即可
# 创建etcd的ssl目录(master2中操作)
mkdir /opt/etcd
# 拷贝master1文件(master1中操作)
scp -r /opt/kubernetes/ 192.168.100.104:/opt/
scp -r /opt/etcd/ssl/ 192.168.100.104:/opt/etcd/
scp /usr/lib/systemd/system/kube* 192.168.100.104:/usr/lib/systemd/system/
scp /usr/bin/kubectl 192.168.100.104:/usr/bin/
# 删除kubelet自动生成的配置(master2中操作)
rm -f /opt/kubernetes/cfg/kubelet.kubeconfig
rm -f /opt/kubernetes/ssl/kubelet*
1.3、修改配置(master2中操作)
vim /opt/kubernetes/cfg/kube-apiserver.conf
...
--bind-address=192.168.100.104 \
--advertise-address=192.168.100.104 \
...
vim /opt/kubernetes/cfg/kube-controller-manager.kubeconfig
server: https://192.168.100.104:6443
vim /opt/kubernetes/cfg/kube-scheduler.kubeconfig
server: https://192.168.100.104:6443
vim /opt/kubernetes/cfg/kubelet.conf
--hostname-override=k8s-master2
vim /opt/kubernetes/cfg/kube-proxy-config.yml
hostnameOverride: k8s-master2
vim ~/.kube/config
...
server: https://192.168.100.104:6443
1.4、启动服务(master2中操作)
systemctl daemon-reload
systemctl start kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy
systemctl enable kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy
systemctl status kube-apiserver kube-controller-manager kube-scheduler kubelet kube-proxy
1.5、审批kubelet的申请(master1中操作)
[root@k8s-master1 opt]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
node-csr-iMojU9INDQmkgNOCvh8IbW33qj8CQ4sj2Tsizet-mKQ 10m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap <none> Pending
[root@k8s-master1 opt]# kubectl certificate approve node-csr-iMojU9INDQmkgNOCvh8IbW33qj8CQ4sj2Tsizet-mKQ
certificatesigningrequest.certificates.k8s.io/node-csr-iMojU9INDQmkgNOCvh8IbW33qj8CQ4sj2Tsizet-mKQ approved
[root@k8s-master1 opt]# kubectl get csr
NAME AGE SIGNERNAME REQUESTOR REQUESTEDDURATION CONDITION
node-csr-iMojU9INDQmkgNOCvh8IbW33qj8CQ4sj2Tsizet-mKQ 11m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap <none> Approved,Issued
1.6、验证
# master1中操作
[root@k8s-master1 opt]# kubectl get nodes -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master1 Ready <none> 8d v1.23.15 192.168.100.101 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
k8s-master2 NotReady <none> 38s v1.23.15 192.168.100.104 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
k8s-node1 Ready <none> 8d v1.23.15 192.168.100.102 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
k8s-node2 Ready <none> 8d v1.23.15 192.168.100.103 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
# 需要等待片刻,等calico在master2节点上拉起后,节点才会变为ready
# master2中操作
[root@k8s-master2 opt]# kubectl get nodes -owide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
k8s-master1 Ready <none> 8d v1.23.15 192.168.100.101 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
k8s-master2 Ready <none> 11m v1.23.15 192.168.100.104 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
k8s-node1 Ready <none> 8d v1.23.15 192.168.100.102 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
k8s-node2 Ready <none> 8d v1.23.15 192.168.100.103 <none> CentOS Linux 7 (Core) 3.10.0-1127.el7.x86_64 docker://20.10.21
到此,实现了双master集群,有条件的,上三master,这里条件有限,测试就两个了。生产环境最好是三个起。
2、部署nginx+keepalived高可用架构
按照上图的架构,在集群中需要增加
- 一个nginx,实现请求负载均衡apiserver
- 一个keepalived,实现用VIP访问nginx,故障时VIP转移,保证nginx始终可被访问
如果是公有云的服务,如腾讯云、阿里云之类的,可直接用他们的CLB、SLB什么的,效果一样
2.1、安装nginx+keepalived(master1/2都操作)
yum install epel-release -y
# 要安装stream模块
yum install nginx nginx-mod-stream keepalived -y
2.2、添加stream配置(master1/2都操作)
cat >> /etc/nginx/nginx.conf << "EOF"
stream {
log_format main '$remote_addr $upstream_addr - [$time_local] $status $upstream_bytes_sent';
access_log /var/log/nginx/k8s-access.log main;
upstream k8s-apiserver {
server 192.168.100.101:6443; # Master1 APISERVER IP:PORT
server 192.168.100.104:6443; # Master2 APISERVER IP:PORT
}
server {
listen 16443; # 由于nginx与master节点复用,这个监听端口不能是6443,否则会冲突
proxy_pass k8s-apiserver;
}
}
EOF
2.3、检测并启动nginx(master1/2都操作)
[root@k8s-master1 nginx]# nginx -t
nginx: the configuration file /etc/nginx/nginx.conf syntax is ok
nginx: configuration file /etc/nginx/nginx.conf test is successful
[root@k8s-master1 nginx]# systemctl start nginx
[root@k8s-master1 nginx]# systemctl enable nginx
Created symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service.
# 测试访问一下
[root@k8s-master1 nginx]# curl -k https://192.168.100.105:16443/version
{
"major": "1",
"minor": "23",
"gitVersion": "v1.23.15",
"gitCommit": "b84cb8ab29366daa1bba65bc67f54de2f6c34848",
"gitTreeState": "clean",
"buildDate": "2022-12-08T10:42:57Z",
"goVersion": "go1.17.13",
"compiler": "gc",
"platform": "linux/amd64"
}[root@k8s-master1 nginx]#
2.4、配置keepalived(master1/2都操作)
这里要注意修改配置
- router_id:master1节点中值为nginx_master,master2节点中值为nginx_backup
- state:master1节点中值为MASTER,master2节点中值为BACKUP
- priority:master1节点中值为100,master2节点值修改为90
cd /etc/keepalived/
mv keepalived.conf keepalived.conf_bak
cat > keepalived.conf << EOF
global_defs {
notification_email {
acassen@firewall.loc
failover@firewall.loc
sysadmin@firewall.loc
}
notification_email_from Alexandre.Cassen@firewall.loc
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id nginx_master #每个keepalived节点的唯一标识
}
vrrp_script check_nginx { #监测nginx的状态
script "/etc/keepalived/check_nginx.sh" #监控脚本
interval 3 #检测间隔时间,即两秒检测一次
fall 2 #检测失败的最大次数,超过两次认为节点资源发生故障
weight -20 #自动调整优先级的参数,检测成功优先级不变,失败则优先级-20,就会发生切换
}
vrrp_instance VI_1 {
state MASTER #虚拟路由器的初始状态,可选择MASTER或者BACKUP
interface ens33 #要修改为实际网卡名
virtual_router_id 51 #每个虚拟路由的唯一标识ID,本次master和backup同属一个路由,所以值要保持一致
priority 100 #当前节点的优先级,值越大越优先,主节点比备节点大即可
advert_int 1 #VRRP通告的时间间隔,默认为1秒
authentication { #设置同一虚拟路由之间的认证机制
auth_type PASS #认证类型,这里用密码
auth_pass 1111 #预共享密钥,仅前8位有效(就是配置的密码,可以配置为随机数,但是master和backup要一致)
}
virtual_ipaddress { #配置VIP
192.168.100.105/24 #要保证这个IP没有被占用
}
track_script { #定义执行的跟踪脚本
check_nginx
}
}
EOF
2.5、配置检测nginx状态脚本
实现效果:
- 使用ss命令去检测nginx的16443端口是否存活
-
- 如果端口存在,则返回状态0,keepalived不做任何处理
-
- 如果端口不存在,则尝试重启nginx,重新判断端口是否存活
-
-
- 如果端口不存在,则返回状态为1,keepalived会做master降级,VIP漂移操作
-
-
-
- 如果端口存在,则返回状态为0,keepalived不做任何处理
-
cat > check_nginx.sh << "EOF"
#!/bin/bash
count=$(ss -antp |grep 16443 |wc -l)
if [ "$count" -eq 0 ];then
systemctl restart nginx # 尝试重启nginx
sleep 2
count=$(ss -antp |grep 16443 |wc -l) # 这里要重新赋值才行
if [ $count -eq 0 ];then
echo "$count"
exit 1
else
exit 0
fi
else
exit 0
fi
EOF
chmod +x check_nginx.sh
2.6、启动keepalived
systemctl start keepalived
systemctl enable keepalived
# 验证,刚开始启动,因为master1优先级高,所以VIP是在master1上
[root@k8s-master1 keepalived]# ip a |grep ens33 -A 3
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:3a:0d:16 brd ff:ff:ff:ff:ff:ff
inet 192.168.100.101/24 brd 192.168.100.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.100.105/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::30c0:4897:a86f:f217/64 scope link noprefixroute
valid_lft forever preferred_lft forever
# 测试访问
[root@k8s-master1 keepalived]# curl -k https://192.168.100.105:16443/version
{
"major": "1",
"minor": "23",
"gitVersion": "v1.23.15",
"gitCommit": "b84cb8ab29366daa1bba65bc67f54de2f6c34848",
"gitTreeState": "clean",
"buildDate": "2022-12-08T10:42:57Z",
"goVersion": "go1.17.13",
"compiler": "gc",
"platform": "linux/amd64"
}[root@k8s-master1 keepalived]#
2.7、测试VIP漂移效果
首先要注释掉nginx检测脚本里的重启nginx指令,不然停止nginx后,keepalived又自动拉起了
# 注释掉重启命令,测试完别忘了打开
[root@k8s-master1 keepalived]# cat check_nginx.sh
......
#systemctl restart nginx
......
master1中手动停止nginx
[root@k8s-master1 keepalived]# systemctl stop nginx
[root@k8s-master1 keepalived]# ss -antp |grep 16443
# master1中查看vip是否还在
[root@k8s-master1 keepalived]# ip a |grep ens33 -A 3
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:3a:0d:16 brd ff:ff:ff:ff:ff:ff
inet 192.168.100.101/24 brd 192.168.100.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet6 fe80::30c0:4897:a86f:f217/64 scope link noprefixroute
valid_lft forever preferred_lft forever
# 查看keepalived状态
[root@k8s-master1 keepalived]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2022-12-31 16:15:33 CST; 11min ago
Main PID: 88195 (keepalived)
CGroup: /system.slice/keepalived.service
├─88195 /usr/sbin/keepalived -D
├─88196 /usr/sbin/keepalived -D
├─88197 /usr/sbin/keepalived -D
├─99640 /usr/sbin/keepalived -D
├─99642 /bin/bash /etc/keepalived/check_nginx.sh
└─99658 sleep 2
Dec 31 16:26:14 k8s-master1 Keepalived_vrrp[88197]: /etc/keepalived/check_nginx.sh exited with status 1
Dec 31 16:26:17 k8s-master1 Keepalived_vrrp[88197]: /etc/keepalived/check_nginx.sh exited with status 1
Dec 31 16:26:20 k8s-master1 Keepalived_vrrp[88197]: /etc/keepalived/check_nginx.sh exited with status 1
......
master2中查看效果
[root@k8s-master2 keepalived]# systemctl status keepalived
● keepalived.service - LVS and VRRP High Availability Monitor
Loaded: loaded (/usr/lib/systemd/system/keepalived.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2022-12-31 16:13:01 CST; 15min ago
Main PID: 50116 (keepalived)
CGroup: /system.slice/keepalived.service
├─50116 /usr/sbin/keepalived -D
├─50117 /usr/sbin/keepalived -D
└─50118 /usr/sbin/keepalived -D
Dec 31 16:24:53 k8s-master2 Keepalived_vrrp[50118]: Sending gratuitous ARP on ens33 for 192.168.100.105
Dec 31 16:24:53 k8s-master2 Keepalived_vrrp[50118]: Sending gratuitous ARP on ens33 for 192.168.100.105
......
[root@k8s-master2 keepalived]# ip a |grep ens33 -A 3
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000
link/ether 00:0c:29:ad:ec:3f brd ff:ff:ff:ff:ff:ff
inet 192.168.100.104/24 brd 192.168.100.255 scope global noprefixroute ens33
valid_lft forever preferred_lft forever
inet 192.168.100.105/24 scope global secondary ens33
valid_lft forever preferred_lft forever
inet6 fe80::e166:6ae9:6fa:258e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
测试访问
注意:别在master1上curl,不然会有16443的进程,被keepalived检测到,就会导致VIP又漂到master1上了
[root@k8s-master2 keepalived]# curl -k https://192.168.100.105:16443/version
{
"major": "1",
"minor": "23",
"gitVersion": "v1.23.15",
"gitCommit": "b84cb8ab29366daa1bba65bc67f54de2f6c34848",
"gitTreeState": "clean",
"buildDate": "2022-12-08T10:42:57Z",
"goVersion": "go1.17.13",
"compiler": "gc",
"platform": "linux/amd64"
}[root@k8s-master2 keepalived]#
请求日志
[root@k8s-master2 keepalived]# tail -f /var/log/nginx/k8s-access.log
192.168.100.104 192.168.100.101:6443 - [31/Dec/2022:16:06:16 +0800] 200 418
192.168.100.104 192.168.100.101:6443 - [31/Dec/2022:16:10:46 +0800] 200 85
192.168.100.104 192.168.100.104:6443 - [31/Dec/2022:16:10:52 +0800] 200 418
验证没问题之后,可以把master1上的nginx检测脚本恢复,就会自动把nginx拉起了
3、调整所有节点上的server配置
之前部署时,所有kube服务里的apiserver配置还都是192.168.100.101:6443,即master1的apiserver地址
所以现在虽然VIP已经生效,但是服务并没有去调用这个地址
因此最后一步就是,修改所有节点上的配置文件(包括master和node),让服务去调用
说是配置文件,其实也就只是kubeconfig文件
sed -i "s/192.168.100.101:6443/192.168.100.105:16443/g" /opt/kubernetes/cfg/*
# 验证访问
[root@k8s-master1 cfg]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master1 Ready <none> 9d v1.23.15
k8s-master2 Ready <none> 21h v1.23.15
k8s-node1 Ready <none> 9d v1.23.15
k8s-node2 Ready <none> 9d v1.23.15
好了,这次是真结束了,恭喜,一套二进制部署的高可用k8s集群就完成了😄
End…


![移动Web【空间转换[空间位移、透视、空间旋转、立体呈现、3D导航、空间缩放]、动画、综合案例】](https://img-blog.csdnimg.cn/801a522e3c5c46b996b659934d9665af.png)


![健康码识别[QT+OpenCV]](https://img-blog.csdnimg.cn/b1643a77eb38432abc2e9b5b86d46048.gif)




![[ Azure - Database ] Azure Database for MySQL 配置Auditing并查看使用](https://img-blog.csdnimg.cn/9e84f146faef43e8bc933508270ecc08.png)