一.什么是两阶段提交
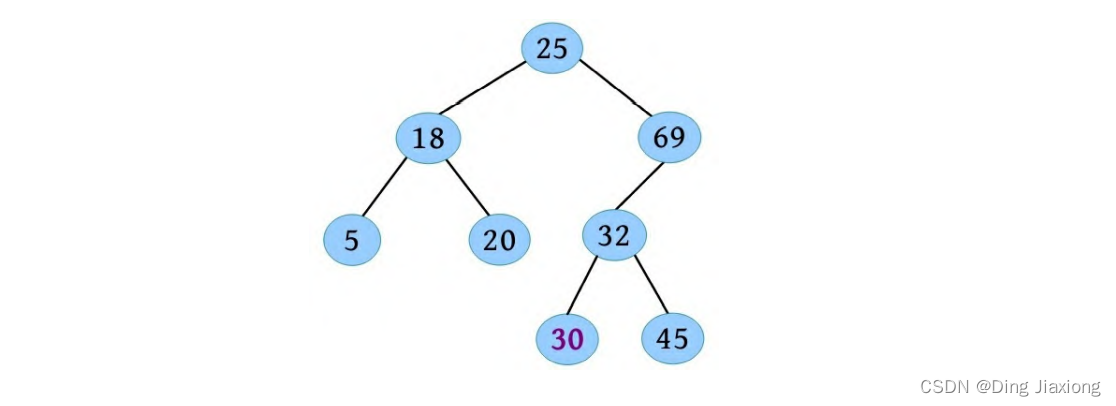
1.SQL语句(update user set name=‘李四’ where id=3)的执行流程是怎样的呢?
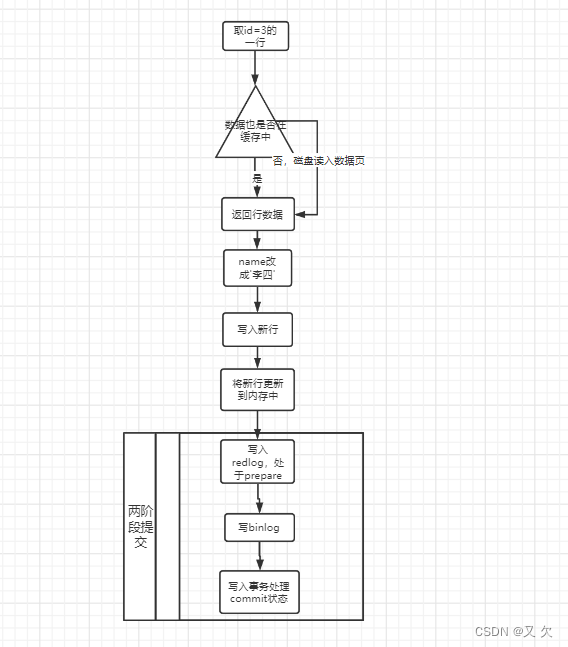
1.执行器先找引擎取 ID=3这一行。ID 是主键,引擎直接用树搜索找到这一行。
2.如果 ID=3 这一行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然后再返回。
3.执行器拿到引擎给的行数据,把name这个值改成李四 得到新的一行数据,再调用引擎接口写入这行新数据。
4.引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
5.执行器生成这个操作的 binlog,并把 binlog 写入磁盘。
6.执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交(commit)状态,更新完成。
2.redo log 和 binlog有什么不同?
1.redo log 是物理日志,记录的是“在某个数据页上做了什么修改”;
2.binlog 是逻辑日志,记录的是这个语句的原始逻辑,比如“给 ID=3 这一行的 name 字段改成李四 ”。
3.为什么必须有“两阶段提交”呢?
这是为了让两份日志之间的逻辑一致。所以只要 redo log 和 binlog 持久化到磁盘,即使 MySQL 异常,重启后数据依然可以恢复。
二:binlog是怎么写入的
1.binlog是怎么进行写入的呢?
1.事务执行过程中先把日志写到binlog cache 中,
2.吧日志写入到文件系统的 page cache中
3. 事务提交时,将 binlog cache 写入 binlog 文件
2.什么是binlog cache?
在执行事务过程中系统为每个线程分配了一片binlog cache内存。参数binlog_cache_size控制单个线程内binlog cache大小。如果超过这个大小就要暂存到磁盘,类似于先写入临时文件,在写入磁盘。

如上图所示,可以看到,每个线程有自己的 binlog cache,但是共用同一份 binlog 文件。
3.图中的 write,指的就是指把日志写入到文件系统的 page cache,并没有把数据持久化到磁盘,所以速度比较快。
page cache:是OS关于磁盘IO的缓存,位于内核中,不适用于大文件传输,因为大文件传输page cache的命中率比较低,这个时候page cache不仅没有起到作用还增加了一次数据从磁盘buffer到内核page cache的开销
4.图中的 fsync,才是将数据持久化到磁盘的操作。一般情况下,我们认为 fsync 才占磁盘的 IOPS。
也可以理解为,write是写入内存,而fsync才是写磁盘。
5.bin log有哪些写盘策略?
通过控制参数sync_binlog来进行控制
- sync_binlog=0 的时候,表示每次提交事务都只 write,不 fsync;
- sync_binlog=1 的时候,表示每次提交事务都会执行 fsync;(一般设置为1);
- sync_binlog=N(N>1) 的时候,表示每次提交事务都 write,但累积 N 个事务后才 fsync;
如果参数是0,MySQL发生异常重启会丢失内存里的bin log
如果参数是N,MySQL发生异常重启会丢失内存里的最近N个事务的bin log
三:redlog的是怎么写入的
写盘执行流程
其实redlog和binlog写盘机制都差不多,都是先写内存在写磁盘。
- 先写入 redo log buffer
- 吧 redo log buffer 写入 page cache中
- 持久化 到磁盘当中
1.什么是redo log buffer?
redo log buffer是一块内存,事务执行过程中会多次写入buffer,等到事务commit的时候才会写入redo log中
2.redo log buffer和binlog cache都是临时内存有什么不同
1.binlog cache是每一个线程都共有的,而redo log buffer是多个线程公用的。
2.binlog存储是以statement或者row格式存储的,
3.redo log是以page页格式存储的
3.red log有哪些写盘策略?
通过控制参数innodb_flush_log_at_trx_commit来进行控制
- 设置为 0 的时候,表示每次事务提交时都只是把 redo log 留在 redo log buffer 中;
- 设置为 1 的时候,表示每次事务提交时都将 redo log 直接持久化到磁盘;
- 设置为 2 的时候,表示每次事务提交时都只是把 redo log 写到 page cache;
4.redo log buffer什么时候 write?
1.InnoDB 有一个后台线程,每隔1秒,就会把 redo log buffer中的日志,调用 write 写到 page cache,然后 fsync 持久化到磁盘。
需要注意的是,事务执行中的 redo log 也是存在于 redo log buffer 的,也会被一起持久化到磁盘。(也就是说,一个还没有提交事务的 redo log,也可能已经被持久化到磁盘了)
2.一种是,redo log buffer 占用的空间即将达到 innodb_log_buffer_size 一半的时候,后台线程会主动写入 page cache。
5.写入 page cache后什么时候fsync?
1.当我们innodb_flush_log_at_trx_commit设置为1时,假设一个事务 A 执行到一半,已经写了一些 redo log 到 buffer 中,这时候有另外一个线程的事务 B 提交,那么按照这个参数的逻辑,事务 B 要把 redo log buffer 里的日志全部持久化到磁盘。这时候,就会带上事务 A 在 redo log buffer 里的日志一起持久化到磁盘。
2.事务提交时
四:组提交(group commit)
为什么要组提交?
简单来说其实组提交顾名思义就是是多个事务成为一’组’,一起刷盘,减少磁盘IO。
详细可以参考这篇文档 组提交的好处
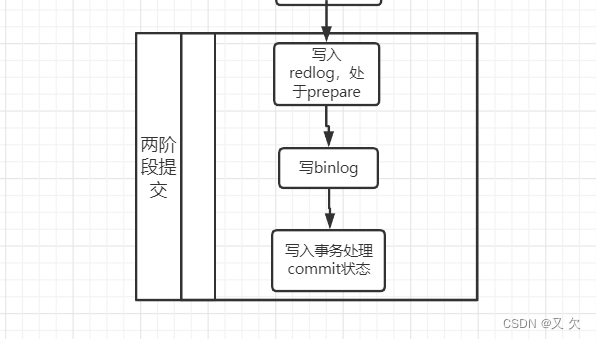
上图就是MySQL没有优化前的提交方式。
- .先写入 redo log buffer
- 吧 redo log buffer 写入 page cache中
- 持久化 到磁盘当中,red log处于perpare阶段
- 事务执行过程中先把日志写到binlog cache 中,
- 把日志写入到文件系统的 page cache中
- 事务提交时,将 binlog cache 写入 binlog 文件
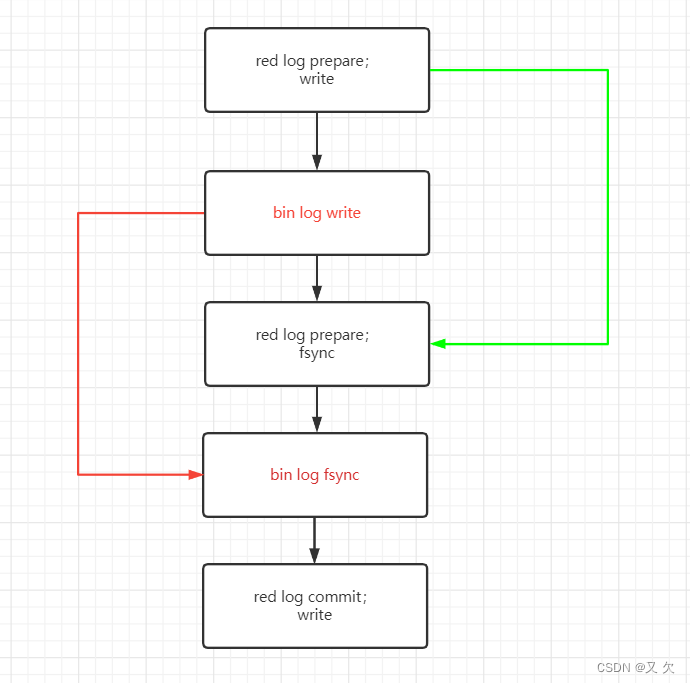
上图就是MySQL优化后的提交方式。
1 .先写入 redo log buffer
2.吧 redo log buffer 写入 page cache中
3.事务执行过程中先把日志写到binlog cache 中,
4.持久化 到磁盘当中,red log处于perpare阶段
5 把日志写入到文件系统的 page cache中
6.事务提交时,将 binlog cache 写入 binlog 文件
优化了哪里?
将red log持久化到磁盘当中的时间往后移了,这样组提交时可以提交组员会更多,组员越多节约磁盘 IOPS 的效果越好。
五.什么是双 ‘1’ 配置,配置后数据就不丢失吗?
只有在 sync_binlog 和 innodb_flush_log_at_trx_commit 都等于1的情况下,才能保证数据不丢失。
写 redo log 时,每次事务提交时,都将所有redo log fsync到磁盘
写 binlog 时,每次事务提交时,binlog 都会执行 fsync到磁盘。
数据丢失情况分析
情况一:redolog在prepare阶段持久化到磁盘(可能失败)也就是上图步骤3失败
mysql异常重启,redo log没有fsync,内存丢失,直接回滚,这种情况是不影响数据一致性
情况二:紧接着binlog持久化(可能失败)也就是上图步骤4失败
redolog fsync成功,但是binlog写入错误,此时mysql异常重启,现在有redolog的磁盘数据没有binlog的数据,此时检测redolog处于prepare阶段,但是没有binlog,回滚(虽然刚刚redolog fsync了但是不影响数据一致性,因为redolog的操作并没有写入mysql,也永远不会写入mysql)— 不懂的可以去看看我的MySQL刷脏页专栏,什么时候red log会进行刷盘
情况三:binlog完整但未commit 也就是上图步骤5失败
此时检测redolog处于prepare阶段,且binlog完整但未提交,默认添加commit标记,进而提交,写入mysql,满足数据一致性; 情况四:binlog完整且提交,写入musql,满足一致性;
情况四:binlog完整且提交,也就是图6步骤执行完成
写入musql,满足一致性;
至此MySQL的bin log和red log的两阶段提交,可以完整的保证我们数据一致性,从而保证数据不丢失。