我们之前介绍了各种常见垃圾回收器的基本原理,本小节我们讨论一个更深入的问题——垃圾回收器的底层是如何做的。
在并发标记的过程中,因为标记期间应用线程还在继续跑,对象间的引用可能发生变化,多标和漏标的情况就有可能发生。这就好比你在拖地,但是你的孩子却在跑来跑去,结果你一直拖不干净。
主流的垃圾收集器基本上都是基于可达性分析算法来判定对象是否存活的,也就是”三色标记法“。根据对象是否被垃圾收集器扫描过而用白、灰、黑三种颜色来标记对象的状态的一种方法。而其中
-
白色:表示对象尚未被垃圾收集器访问过。显然在可达性分析刚刚开始阶段,所有的对象都是白色的,若在分析结束之后对象仍然为白色,则表示这些对象为不可达对象,对这些对象进行回收。
-
灰色:表示对象已经被垃圾收集器访问过,但是这个对象至少存在一个引用(属性)还没有被扫描过。
-
黑色:表示对象已经被垃圾收集器访问过,且这个对象的所有引用都已经被扫描过。黑色表示这个对象扫描之后依然存活,是可达性对象,如果有其他对象引用指向了黑色对象,无须重新扫描,黑色对象不可能不经过灰色对象直接指向某个白色对象。
1.三色标记的基本过程
我们接下来看一下如何进行三色标记的:
初始状态
初始阶段只有GC Roots是黑色的,其他对象都是白色的,如果没有被黑色对象引用那么最终都会被当做垃圾对象回收。
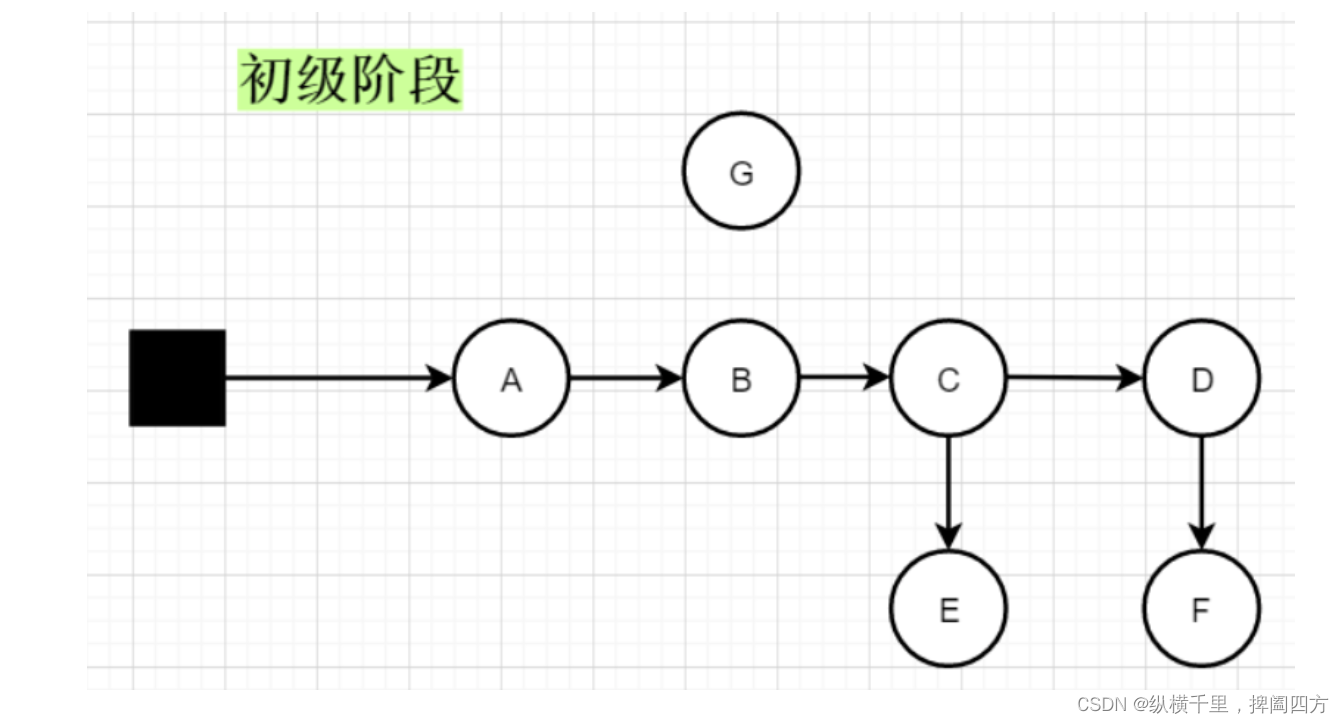
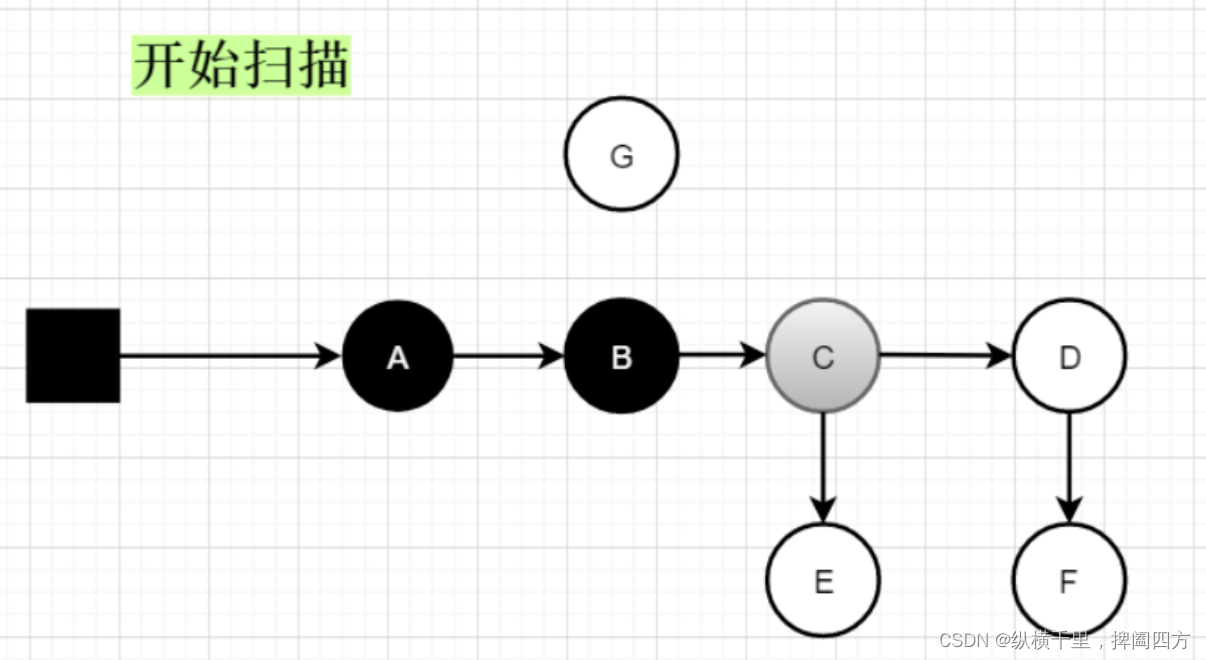
开始扫描
A和B均为扫描过的对象并且其引用也已经被垃圾回收器扫描过所以此时A、B对象均变为了黑色,而刚扫描到对象C,由于C的D和E还没有被扫描到,所以C暂时为灰色。
顺利扫描结束
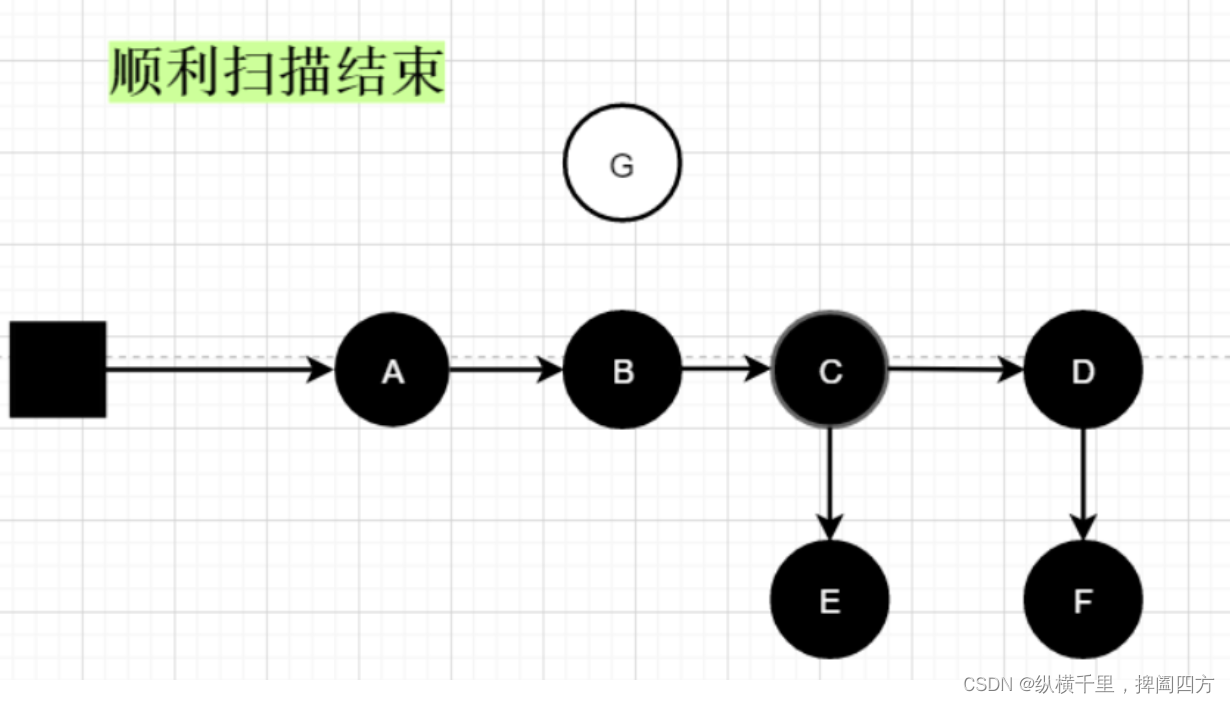
此时扫描完成,黑色对象就是存活的对象,即可可达对象,白色对象G为不可达对象,在垃圾回收时就会被回收掉。
2 三色标记的缺点
我们知道CMS和G1等垃圾回收器是一个并发回收的垃圾回收器,上面的图片只是展示了一种理想状态下的三色标记,实际上在并发的情况下会存在多标和漏标的问题。
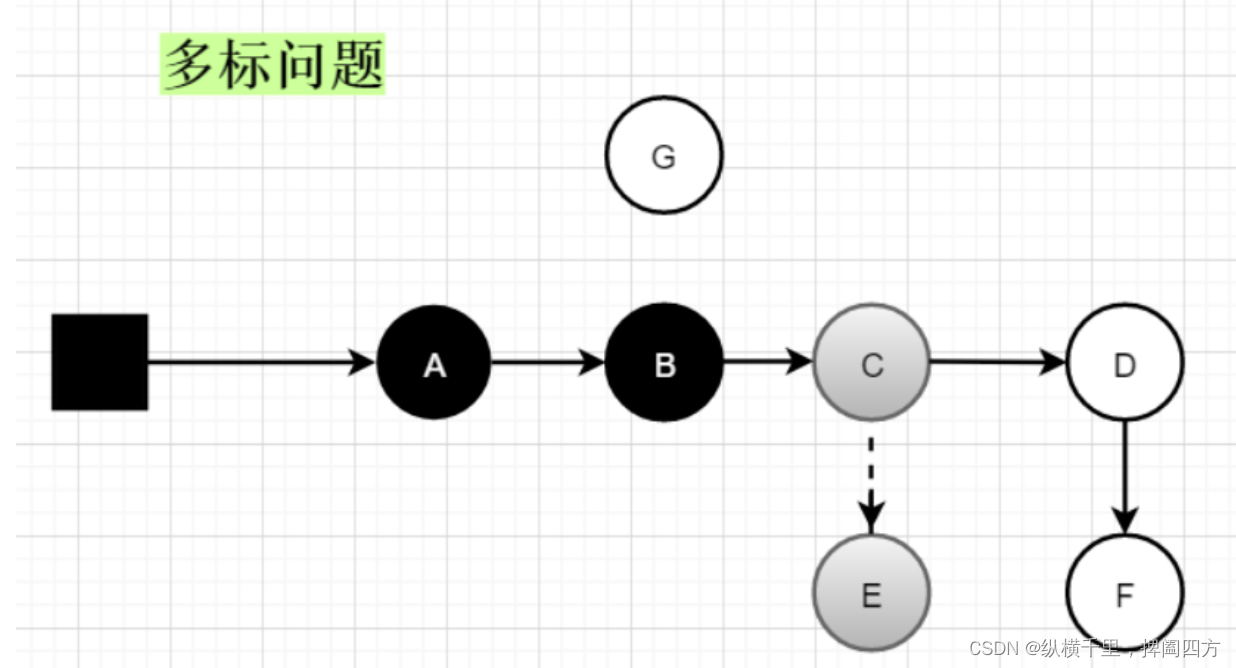
假如GC线程已经扫描到了E对象,此时E对象为灰色,这个时候用户线程将C的引用E断开,那么GC就会认为E对象是可达对象,而不会对E进行垃圾回收,但实际上E是个垃圾对象,这个时候就会产生多标问题,多标问题其实还可以接受,E作为浮动垃圾,那么等到下次垃圾回收的时候回收掉。
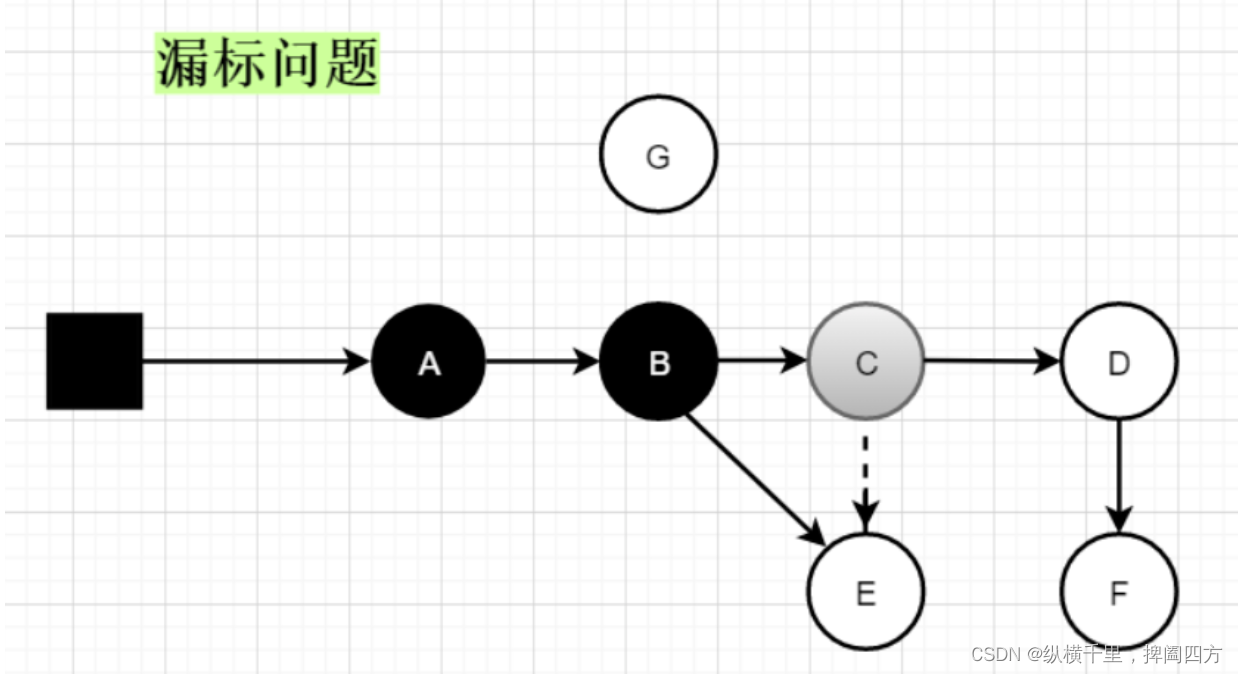
假如用户线程先断开了C到E的引用,那么E对象就认为是不可达对象,而此时B对象又引用了E对象,但是三色标记又不会重新从B点开始标记到E,那么E就会被认为是垃圾对象,但实际上E是有引用的,那么此时对E进行垃圾回收,之后就一定会产生错误,这就是漏标问题。
3 解决多标和漏标的问题
我们上面提到的多标带来的浮动垃圾问题。在并发标记过程中,如果由于方法运行结束导致部分局部变量(gcroot)被销毁,这个gcroot引用的对象之前又被扫描过(被标记为非垃圾对象),那么本轮GC不会回收这部分内存。这部分本应该回收但是没有回收到的内存,被称之为“浮动垃圾”。浮动垃圾并不会影响垃圾回收的正确性,只是需要等到下一轮垃圾回收中才被清除。
另外,针对并发标记(还有并发清理)开始后产生的新对象,通常的做法是直接全部当成黑色,本轮不会进行清除。这部分对象期间可能也会变为垃圾,这也算是浮动垃圾的一部分。
但是漏标问题就比较严重了,漏标会导致被引用的对象被当成垃圾误删除,这是严重bug,必须解决,有两种解决方案: 增量更新(Incremental Update) 和原始快照(Snapshot At The Beginning,SATB) 。
上面演示了三色标记法存在的一些问题,那么如何解决这些问题呢。首先存在以上问题有两个条件同时满足才会发生
-
赋值器插入了一条或者多条从黑色对象到白色对象的引用。
-
赋值器删除了所有的从灰色对象到白色对象的直接引用或者间接引用。
那么要想解决并发扫描时对象消失的问题只需要破坏任何一个条件即可。因此产生了两种解决方案——增量更新(Incremental Update)和原始快照(Snapshot At The Beginning, SATB)。
增量更新就是当黑色对象插入新的指向白色对象的引用关系时, 就将这个新插入的引用记录下来, 等并发扫描结束之后, 再将这些记录过的引用关系中的黑色对象为根, 重新扫描一次。 这可以简化理解为, 黑色对象一旦新插入了指向白色对象的引用之后, 它就变回灰色对象了。
原始快照就是当灰色对象要删除指向白色对象的引用关系时, 就将这个要删除的引用记录下来, 在并发扫描结束之后, 再将这些记录过的引用关系中的灰色对象为根, 重新扫描一次,这样就能扫描到白色的对象,将白色对象直接标记为黑色(目的就是让这种对象在本轮gc清理中能存活下来,待下一轮gc的时候重新扫描,这个对象也有可能是浮动垃圾)。关于SATB的问题,我们下一篇单独分析。
增量更新破坏的是第一个条件,当黑色对象插入新的指向白色对象的引用关系时。就将这个新插入的引用记录下来,等并发扫描结束之后,再将这些记录过的引用关系中的黑色对象作为根对象,再重新扫描一遍。比如漏标问题中,一旦B对象直接指向了E对象,那么在并发扫描之后,就会将B对象作为灰色对象,再重新扫描一遍。这样虽然避免了漏标问题,但是重新标记会导致STW的时间变长。
原始快照破坏的是第二个条件,当灰色对象要删除指向白色对象的引用关系时,就将这个要删除的引用记录下来,在并发扫描结束之后再将这些记录过的引用关系中的灰色对象为根对象再重新扫描一遍。例如漏标问题的途中,C断开E的引用关系时会保存一个快照,然后等扫描结束之后,会把C当作根再重新扫描一遍,假如B没有引用E,那么E对象也会认为是可达对象,这样E就成了浮动垃圾,只能等下次垃圾回收时再回收。
无论是对引用关系记录的插入还是删除,虚拟机的记录操作都是通过写屏障实现的。在HotSpot虚拟机中,CMS是基于增量更新来做并发标记的,G1、Shenandoah则是用SATB来实现的。
现代追踪式(可达性分析)的垃圾回收器几乎都借鉴了三色标记的算法思想,尽管实现的方式不尽相同:比如白色/黑色集合一般都不会出现(但是有其他体现颜色的地方)、灰色集合可以通过栈/队列/缓存日志等方式进行实现、遍历方式可以是广度/深度遍历等等。
对于读写屏障,以Java HotSpot VM为例,其并发标记时对漏标的处理方案如下:
-
CMS:写屏障 + 增量更新
-
G1,Shenandoah:写屏障 + SATB
-
ZGC:读屏障
工程实现中,读写屏障还有其他功能,比如写屏障可以用于记录跨代/区引用的变化,读屏障可以用于支持移动对象的并发执行等。功能之外,还有性能的考虑,所以对于选择哪种,每款垃圾回收器都有自己的想法。
为什么G1用SATB?CMS用增量更新?
我的理解:SATB相对增量更新效率会高(当然SATB可能造成更多的浮动垃圾),因为不需要在重新标记阶段再次深度扫描被删除引用对象,而CMS对增量引用的根对象会做深度扫描,G1因为很多对象都位于不同的region,CMS就一块老年代区域,重新深度扫描对象的话G1的代价会比CMS高,所以G1选择SATB不深度扫描对象,只是简单标记,等到下一轮GC再深度扫描。