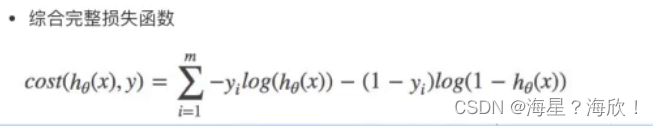周三晚上发了一则朋友圈,今天整理一下:

AIMD 过程可推导出 TCP 吞吐公式:
T = a R T T b p T=\dfrac{a}{RTT}\dfrac{b}{\sqrt{p}} T=RTTapb
a,b 分别为与 AIMD 参数和过程有关,该公式结论内置公平性。设 MSS = 1460,下面是一个合理的示例:
T = 1700 R T T × p T=\dfrac{1700}{RTT×\sqrt{p}} T=RTT×p1700
算一下 20ms RTT(普遍情况) 要达到 1Gbps (lastmile 的普遍诉求)吞吐可容忍的丢包率 p:
1 ∗ 1024 ∗ 1024 ∗ 1024 / 8 = 1700 0.02 p 1∗1024∗1024∗1024/8=\dfrac{1700}{0.02\sqrt{p}} 1∗1024∗1024∗1024/8=0.02p1700
p 约等于 0.0000004,这简直是奢求,对 buffer 要求太高,BDP 越大,buffer overflow 容忍所需 buffer 越大。这解释了 TCP 效率低,更甚者,Reno/CUBIC 等 AIMD 算法族遭遇丢包都会视为拥塞,即使是非拥塞噪声丢包或节点问题丢包也会算在内。
这误判着实让 AIMD TCP 效率更低。
Reno 族算法无法区分丢包类型,即便转发节点配备理论上 BDP 大小的 buffer 也无济于事。
Reno 族算法无状态,只对单独事件反应,比如收到 reordering 个 dupACK 就会 mark lost。若为算法引入历史记忆,可去除些丢包噪声:
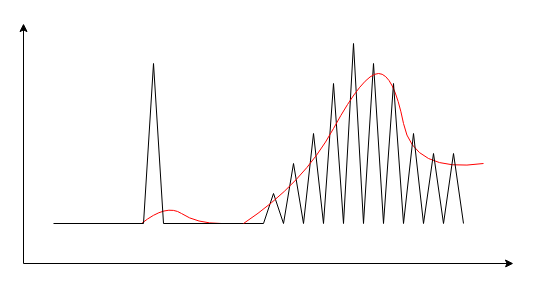
既然 RTT 可移指平均,丢包率 p 亦可。既然吞吐公式来自 AIMD 过程,根据公式构造一个拥塞控制算法即合理的,这次将 p 也移指平均。
或许移指平均不够精确,但至少是个方向,剩下的就是找个足够好的降噪函数了。
这将大大提高 Reno/CUBIC 的 AIMD 效率。
浙江温州皮鞋湿,下雨进水不会胖。



![[oeasy]python0036_牛说_cowsay_小动物说话_asciiart_figlet_lolcat_管道(祝大家新年快乐~)](https://img-blog.csdnimg.cn/img_convert/8b6f79671afda55a6d99a05ecd921f83.png)