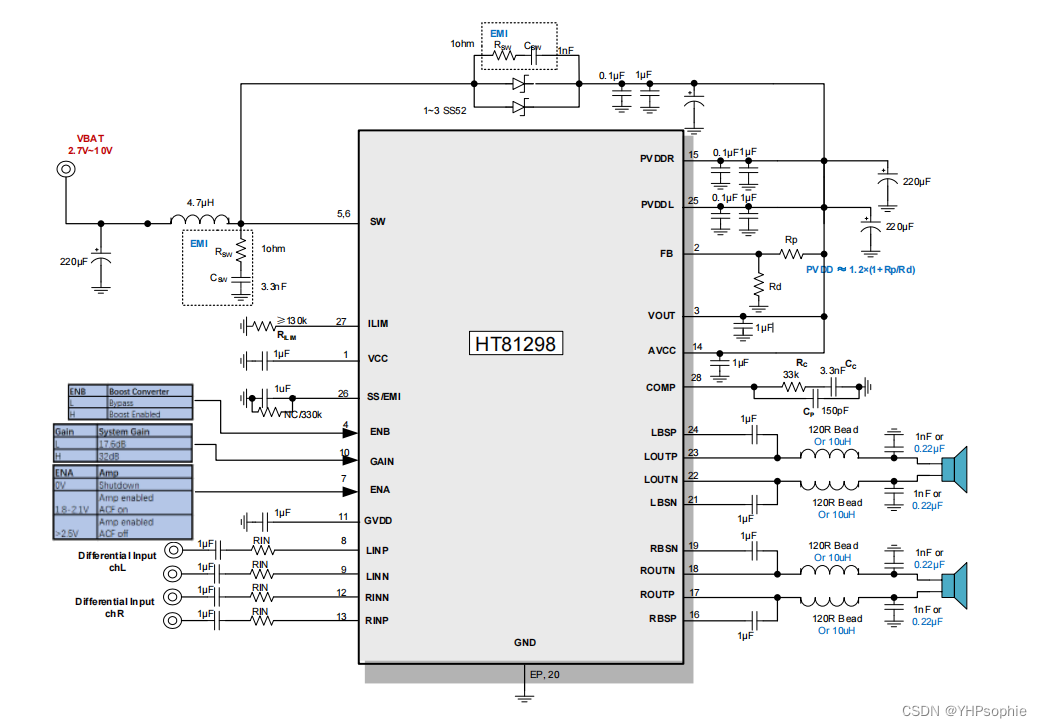
跳表是一种有序的数据结构,它通过在每个节点中维持多个指向其他节点的指针,从而达到快速访问节点的目的。其核心思想就是通过建立多级索引来实现空间换时间。
在Redis中,使用跳表作为Zset的一种底层实现之一,这也是跳表在Redis中的唯一使用场景。
跳表的实现
跳表由zskiplistNode和zskiplist两个结构定义。其中zskiplistNode表示跳跃表的节点,zskiplist则表示跳跃表节点的相关信息。

zskiplistNode
typedef struct zskiplistNode {
sds ele; // 元素值
double score; // 分值
struct zskiplistNode *backward; // 后退指针
struct zskiplistLevel { // 各层信息
struct zskiplistNode *forward; // 该层前向指针
unsigned long span; // 该层的跨度
} level[];
} zskiplistNode;
前进节点
每个层都有一个指向表尾方向的前进指针,用于从表头向表尾方向访问节点。
跨度
记录两个节点之间的距离。跨度是用来计算rank的,在查找某个节点的过程中,将沿途访问过的所有层的跨度累加起来,得到的结果就是目标节点在跳表中的rank。
后退指针
用于表示表尾向表头方向的访问节点,后退节点每次只能后退至前一个节点。
zskiplistList
typedef struct zskiplist {
struct zskiplistNode *header, *tail; // 头、尾指针
unsigned long length; // 跳表长度
int level; // 跳表层数
} zskiplist;
header
指向跳跃表的表头节点。
tail
指向跳跃表的表尾节点。
level
记录当前跳表的长度,即跳表包含节点的数量。
跳表的操作
新建跳表
/* Create a new skiplist. */
zskiplist *zslCreate(void) {
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++) {
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
}
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
}
- 首先分配内存
- level设置为1,length设置为0,后退指针设置为null,尾节点设置为null
- 头指针指向一个高度为32的节点
- 为头指针的前进节点设置为null,span设置为0
插入节点
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // update记录每层的应该指向新增节点的节点
unsigned long rank[ZSKIPLIST_MAXLEVEL]; // rank记录每层需要更新的span值
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1]; // 最高层rank为0,非最高层rank初始化为上一层的rank值
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{ // 对分值&元素遍历对比 直至找到合适的位置
rank[i] += x->level[i].span;
x = x->level[i].forward;
}
update[i] = x;
}
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel(); // 根据幂次定律生成响应的层数
if (level > zsl->level) { // 对于高出现有的层数,依次遍历,更新rank、后置节点和跨度
for (i = zsl->level; i < level; i++) {
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
}
zsl->level = level;
}
x = zslCreateNode(level,score,ele); // 生成节点
for (i = 0; i < level; i++) {
x->level[i].forward = update[i]->level[i].forward; // 针对每一层实现节点的插入。新插入的节点x的forward指向update
update[i]->level[i].forward = x; // update的forward指向x节点
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]); // 对x节点更新span
update[i]->level[i].span = (rank[0] - rank[i]) + 1; // 对update节点更新span
}
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++) { // 所有高出的层级更新span++
update[i]->level[i].span++;
}
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x; // 更新zsl的尾节点
zsl->length++; // 更新zsl的长度
return x;
}
更新节点分值
/* Update the score of an element inside the sorted set skiplist.
* Note that the element must exist and must match 'score'.
* This function does not update the score in the hash table side, the
* caller should take care of it.
*
* Note that this function attempts to just update the node, in case after
* the score update, the node would be exactly at the same position.
* Otherwise the skiplist is modified by removing and re-adding a new
* element, which is more costly.
*
* The function returns the updated element skiplist node pointer. */
zskiplistNode *zslUpdateScore(zskiplist *zsl, double curscore, sds ele, double newscore) {
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x; // 记录需要更新节点在每一层的位置
int i;
/* We need to seek to element to update to start: this is useful anyway,
* we'll have to update or remove it. */
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--) {
while (x->level[i].forward &&
(x->level[i].forward->score < curscore ||
(x->level[i].forward->score == curscore &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
{
x = x->level[i].forward;
}
update[i] = x;
}
/* Jump to our element: note that this function assumes that the
* element with the matching score exists. */
x = x->level[0].forward;
serverAssert(x && curscore == x->score && sdscmp(x->ele,ele) == 0);
/* If the node, after the score update, would be still exactly
* at the same position, we can just update the score without
* actually removing and re-inserting the element in the skiplist. */
if ((x->backward == NULL || x->backward->score < newscore) &&
(x->level[0].forward == NULL || x->level[0].forward->score > newscore))
{ // 如果针对最后一个节点的更新分值变大或者对第一个节点的更新分值减小,可以直接更新分值即可,无需移动节点
x->score = newscore;
return x;
}
/* No way to reuse the old node: we need to remove and insert a new
* one at a different place. */
zslDeleteNode(zsl, x, update); // 首先将旧分值节点删除
zskiplistNode *newnode = zslInsert(zsl,newscore,x->ele); // 为新分值新建一个新的节点,并插入
/* We reused the old node x->ele SDS string, free the node now
* since zslInsert created a new one. */
x->ele = NULL;
zslFreeNode(x);
return newnode;
}
根据排名获取节点
/* Finds an element by its rank from start node. The rank argument needs to be 1-based. */
zskiplistNode *zslGetElementByRankFromNode(zskiplistNode *start_node, int start_level, unsigned long rank) {
zskiplistNode *x;
unsigned long traversed = 0;
int i;
x = start_node;
for (i = start_level; i >= 0; i--) { // 从最高层开始查找,如果上层找到直接return,否则进入下一层
while (x->level[i].forward && (traversed + x->level[i].span) <= rank)
{
traversed += x->level[i].span; // 每一层更新已查找的排名
x = x->level[i].forward;
}
if (traversed == rank) { // 对比排名
return x;
}
}
return NULL; // 最终不存在
}
删除节点
/* Internal function used by zslDelete, zslDeleteRangeByScore and
* zslDeleteRangeByRank. */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update) {
int i;
for (i = 0; i < zsl->level; i++) {
if (update[i]->level[i].forward == x) {
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
} else {
update[i]->level[i].span -= 1;
}
}
if (x->level[0].forward) {
x->level[0].forward->backward = x->backward;
} else {
zsl->tail = x->backward;
}
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
}
Zset获取元素的分值

Zset除了使用zskiplist来实现之外,结构中还使用字典为有序集合创建了一个成员到分值的映射。字典中的每个键值对都保存了一个集合元素,其中键保存了元素的成员,值保存了元素的分值。通过字典可以O(1)的实现查看某个元素的分值。zscore命令就是根据这一特性实现的。
另外需要主要的是,虽然zset结构同时使用跳表和字典来保存有序集合元素,但是两种结构通过指针共享相同元素的成员和分值,所以同时使用跳表和字典来保存集合元素不会产生任何重复成员或者分值,也不会因此而浪费额外的内存。