Seaborn可视化图形绘制
- 频次直方图、KDE和密度图
- 矩阵图
- 分面频次直方图
- 条形图
- 折线图
Seaborn的主要思想是用高级命令为统计数据探索和统计模型拟合创建各种图形,下面将介绍一些Seaborn中的数据集和图形类型。虽然所有这些图形都可以用
Matplotlib命令实现(其实Matplotlib就是Seaborn的底层),但是用SeabornAPI会更方便。
频次直方图、KDE和密度图
在进行统计数据可视化时,我们通常想要的就是频次直方图和多变量的联合分布图。在Matplotlib里面我们已经见过,相对比较简单:
data = np.random.multivariate_normal([0, 0], [[5, 2], [2, 2]], size=2000)
data = pd.DataFrame(data, columns=['x', 'y'])
for col in 'xy':
plt.hist(data[col], normed=True, alpha=0.5)

除了频次直方图,我们还可以用KDE获取变量分布的平滑估计。在seaborn通过sns.kdeplot来实现:
for col in 'xy':
sns.kdeplot(data[col], shade=True)
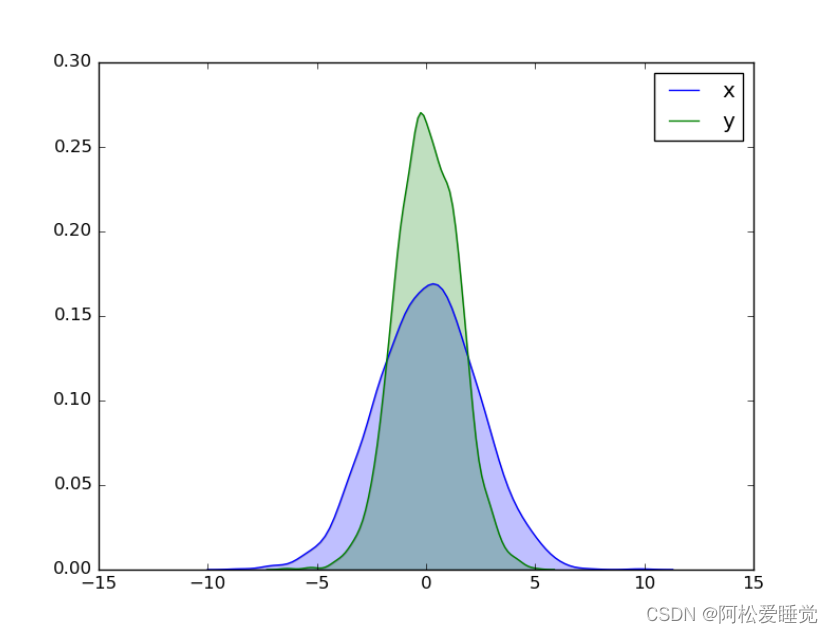
使用distplot可以将频次直方图和KDE结合起来:
sns.distplot(data['x'])
sns.distplot(data['y'])

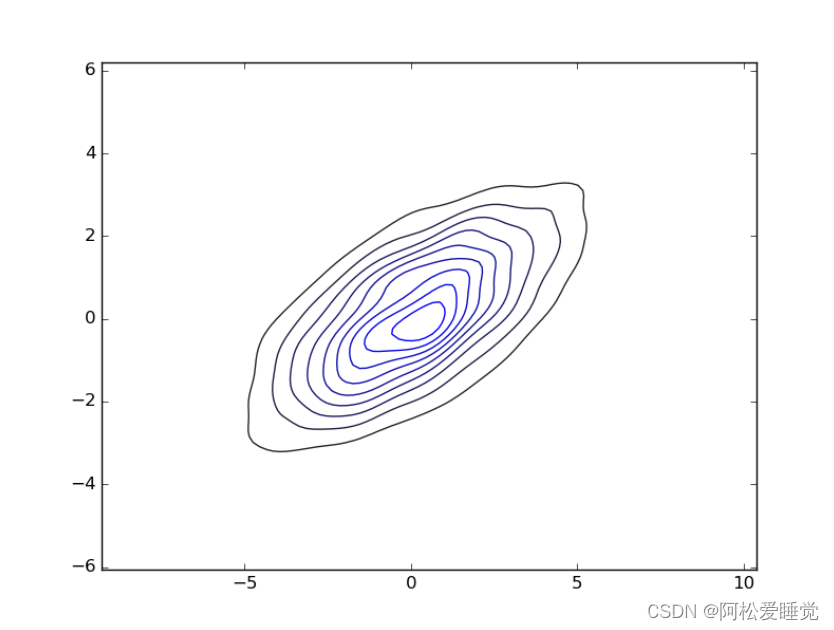
如果向kdeplot输入的是二维数据集,那么就可以获得一个二维数据可视化图:sns.kdeplot(data);
矩阵图
当我们需要对多维数据进行可视化是,最终都要使用矩阵图,矩阵图对于探索多维数据不同维度间的相关性非常有效。
下面将用鸢尾花数据集来演示,其中有三种鸢尾花的花瓣与花萼数据:
data = pd.read_csv("iris.csv")
sns.pairplot(data,hue="species") #hue 选择分类列

分面频次直方图
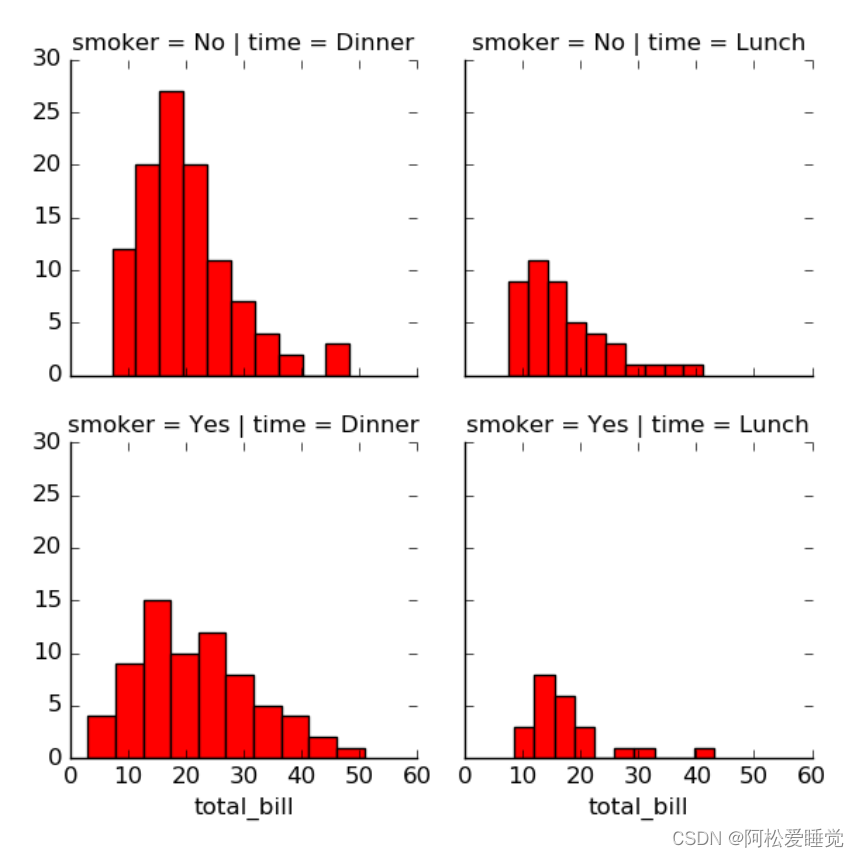
有时观察数据最好的方法就是借助数据子集的频次直方图,Seaborn的 FacetGrid函数让这件事变得非常简单。
来看看某个餐厅统计的服务员收取小费的数据:
tips = pd.read_csv('tips.csv')
g = sns.FacetGrid(tips, col="time", row="smoker")
g = g.map(plt.hist, "total_bill", color="r")
条形图
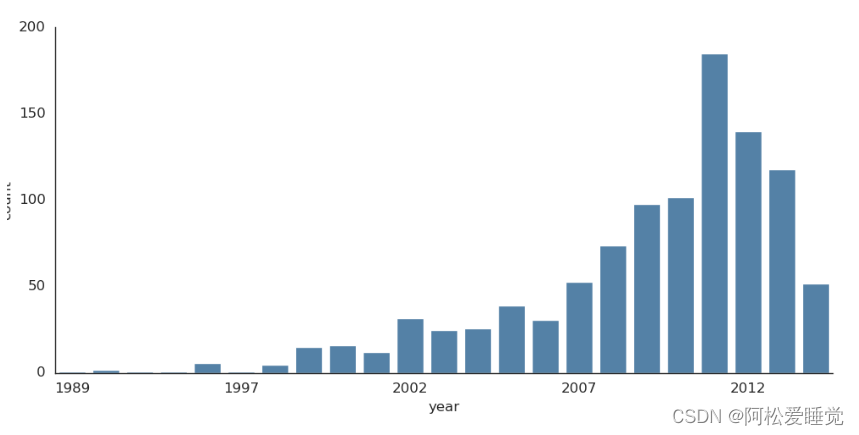
对于时间序列数据可以使用sns.factorplot画出条形图,下面将使用行星数据来演示:
planets = pd.read_csv('planets.csv')
with sns.axes_style('white'):
g = sns.factorplot("year", data=planets, aspect=2,
kind="count", color='steelblue')
g.set_xticklabels(step=5)
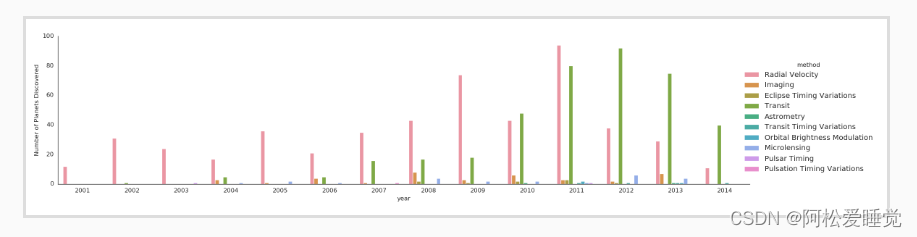
还可以对用不同方法发现行星的数量:
with sns.axes_style('white'):
g = sns.factorplot("year", data=planets, aspect=4.0, kind='count',
hue='method', order=range(2001, 2015))
g.set_ylabels('Number of Planets Discovered')
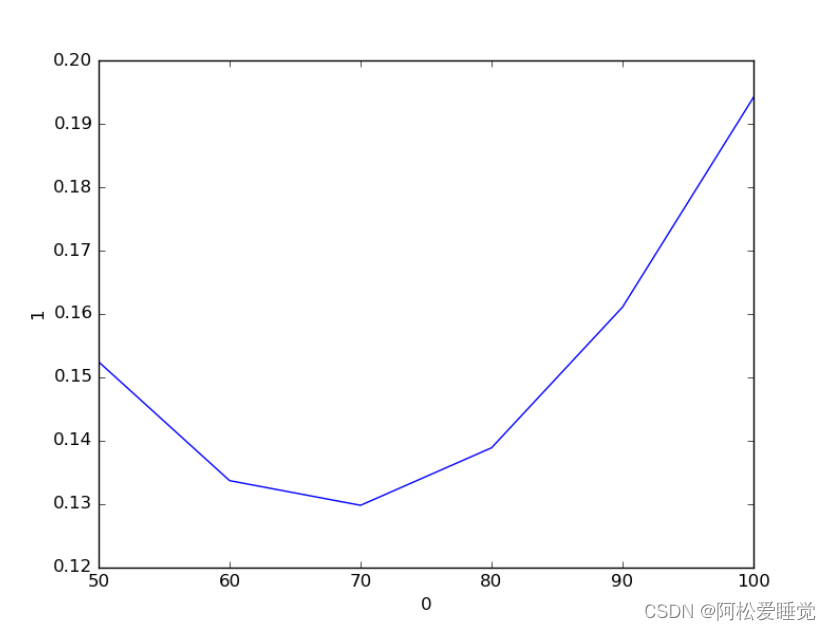
折线图
seaborn绘制折线图使用lineplot函数,该函数所传数据必须为一个pandas数组,这一点跟matplotlib里有较大的区别,并且一开始使用较为复杂。
首先sns.lineplot里有几个参数值得注意:
-
x:plot图的x轴label; -
y:plot图的y轴label; -
ci:与估计器聚合时绘制的置信区间的大小; -
data: 所传入的pandas数组。
x = np.linspace(100, 50, 6)
y = np.array([0.194173876, 0.161086478, 0.138896531, 0.129826697, 0.133716787, 0.152458326])
summary = []
for i in range(6):
x_t = x[i]
y_t = y[i]
summary.append([x_t, y_t])
data =pd.DataFrame(summary )
sns.lineplot(x=0,y=1,ci=None,data=data)