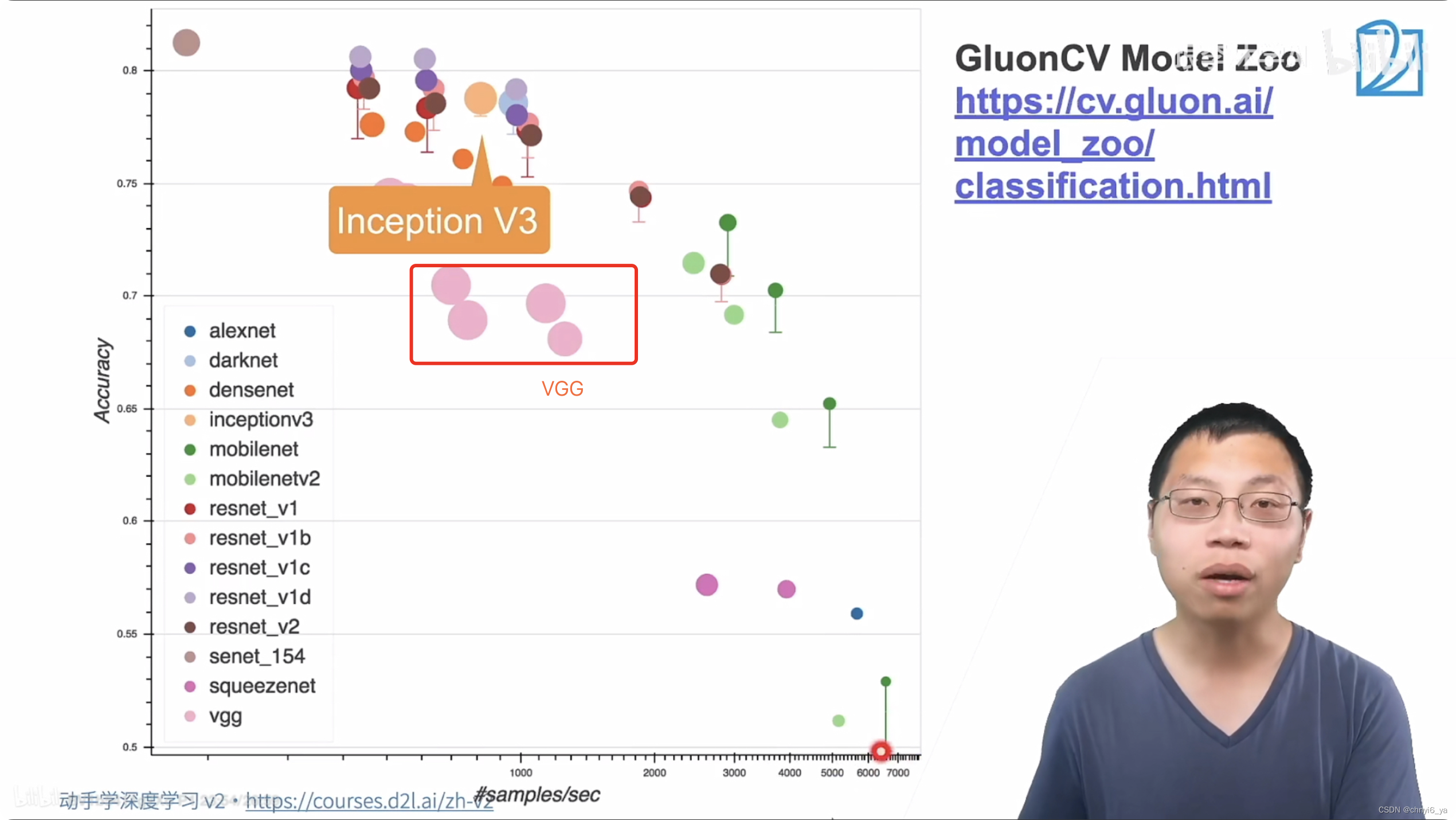
早在2019年,Intel发布第二代Xeon Scalable系列处理器的同时,也推出了E800系列网卡。该网卡的亮点除了支持100Gb,便是新增了ADQ功能。
1. 了解ADQ
ADQ 全称Application Device Queues,是一种队列和控制技术,可提高应用程序性能和可预测性。它可以过滤和隔离应用程序流量,并将其放置在特定硬件的专用通道队列中,这些通道可以以最佳方式连接到应用程序特定的执行线程,减少应用程序延迟,并提高吞吐量。
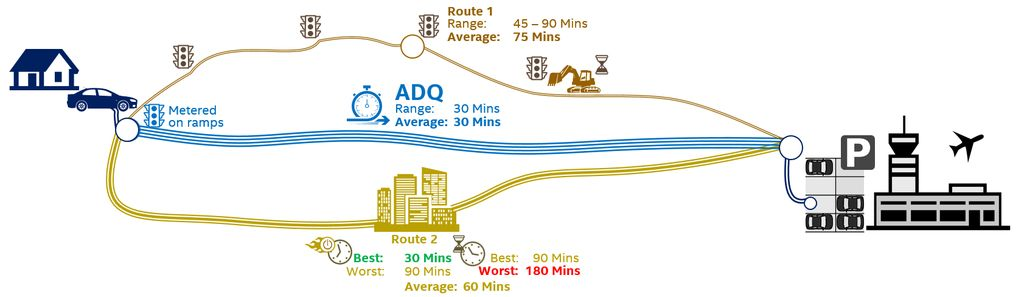
使用ADQ 就像坐上直通车。例如,我们想在高峰期到达机场,能够多快到达往往取决于路况。如果有一条专用路径,我们就可以准确预测行车时间,更快到达机场,而这也是ADQ处理网络连接所带来的益处,开辟一条用于高优先级应用程序流量的专用快速通道,如下图所示。
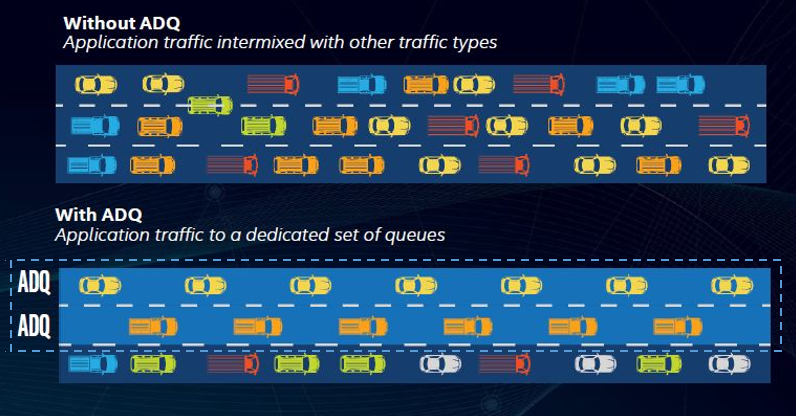
通过在应用程序线程和设备队列之间建立专用通道,ADQ不仅可以减少资源争用,还可以大大减少或避免同步操作,例如加锁或多线程共享。另外,ADQ使用轮询(Polling)来减少中断处理和上下文交换的次数,可以减少网络流量的混乱,如下图所示。
要启用ADQ,除了安装Intel的E800系列网卡和驱动外,还需要匹配较新版本的Linux系统内核(4.19以上)。可以使用iproute2、流量控制(TC)、ethtool、cgroup等工具设置ADQ。
2. 试一试最简功能的ADQ
SPDK之前推出过类似的微信文章,分别是《在SPDK中使能E810网卡ADQ 特性》和《CVL网卡的ADQ特性在SPDK的NVMF测试中的应用实例 - 上/下篇》,我们在这里适时地更新一下部分命令和参数,再补充一些配置步骤和验证结果。
2.1 准备工作
关于软硬件系统先决条件,请参阅《CVL网卡的ADQ特性在SPDK的NVMF测试中的应用实例 - 上篇》。这里以Intel E810网卡最新的ice-1.9.7驱动为例,下载地址:
https://www.intel.com/content/www/us/en/download/19630/intel-network-adapter-driver-for-e810-series-devices-under-linux.html
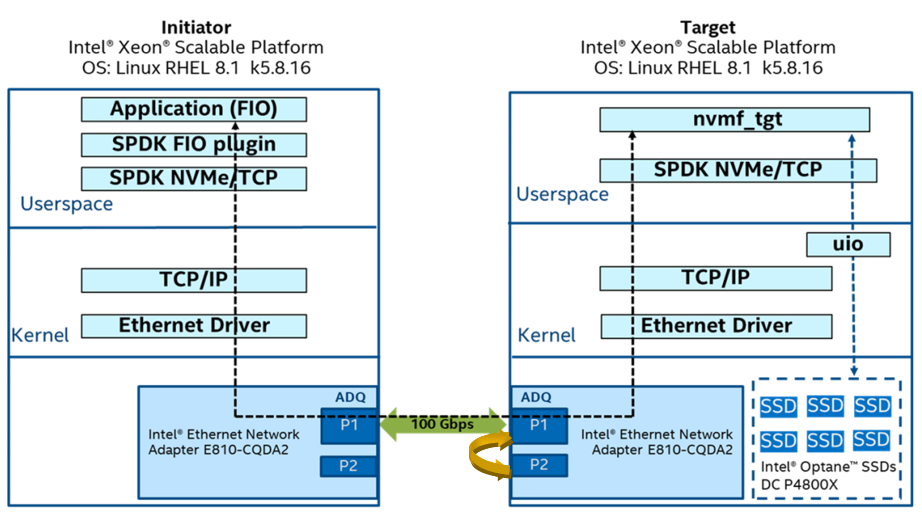
上图是SPDK NVMe/TCP与ADQ测试拓扑结构。如果是双机运行,使用绿色箭头方式连接。如果是单机运行,使用黄色箭头方式连接。注意,单机方式需要设置网络命名空间,类似下面这样,以便使数据流真正通过指定网卡环回,而不是仅仅通过内核。具体设置请查看代码spdk/test/nvmf/common.sh的nvmf_tcp_init()函数。网络命名空间设置后,涉及到网口操作的命令,都需要加上ip netns exec 前缀。
ip netns add eth10_ns_spdk
ip link set eth10 netns eth10_ns_spdk
2.2 运行自动化脚本
SPDK代码里已经准备好了应用ADQ运行FIO的自动化脚本,只需执行下面的命令。
./test/nvmf/target/perf_adq.sh --transport=tcp --iso
2.3 单步讲解
为了更好地理解上面的脚本,我们来详细剖析一下具体的步骤,包括ADQ相关的配置,SPDK所需的步骤和验证ADQ生效的方法。
2.3.1 ADQ相关的配置
# 启用向硬件添加流开关
ethtool --offload eth10 hw-tc-offload on
# ADQ驱动默认开启下面开关,我们需要关闭它进行SPDK测试
ethtool --set-priv-flags eth10 channel-pkt-inspect-optimize off
# SPDK使用非阻塞套接字,并且在轮询组轮询期间,将调用epoll_wait(在POSIX实现中使用),且超时值为0。由于套接字是非阻塞的,因此net.core.busy_read的非零值就足够了。
sysctl -w net.core.busy_poll=1
sysctl -w net.core.busy_read=1
# 这里创建 2 个流量类别和 2 个tc1队列(q2和q3),具体原理请看2.4章节
/usr/sbin/tc qdisc add dev eth10 root mqprio num_tc 2 map 0 1 queues 2@0 2@2 hw 1 mode channel
/usr/sbin/tc qdisc add dev eth10 ingress
# 配置流量类别后,将使用target地址(traddr)和端口号(trsvcid)配置tc过滤器以控制数据包
/usr/sbin/tc filter add dev eth10 protocol ip parent ffff: prio 1 flower dst_ip 10.0.0.2/32 ip_proto tcp dst_port 4420 skip_sw hw_tc 1
2.3.2 SPDK所需的步骤
Target端,创建块设备,建立子系统并监听,等待连接请求。并且作为socket应用程序,通过setsockopt()设置socket的SO_PRIORITY。
# 开启一个server,占用核0、1、2、3
build/bin/nvmf_tgt -i 0 -e 0xFFFF -m 0xF --wait-for-rpc
# 变量替换执行RPC命令
rpc_py=scripts/rpc.py
# 打开 enable_placement_id的选项,用于开启基于NAPI_ID的调度算法
$rpc_py sock_impl_set_options --enable-placement-id 1 --enable-zerocopy-send-server -i posix
$rpc_py framework_start_init
# 传输方式为tcp。硬件队列 tc1 与 SPDK 关联,tc1用于nvmf_tgt应用程序流量,优先级 1 映射到 tc1。 因此,sock-priorty 应设置为 1,以引导 Tx 数据包通过 tc1 队列。
$rpc_py nvmf_create_transport -t tcp -o --io-unit-size 8192 --sock-priority 1
# 创建malloc块设备
$rpc_py bdev_malloc_create 64 512 -b Malloc1
# 创建子系统,添加命名空间并建立监听
$rpc_py nvmf_create_subsystem nqn.2016-06.io.spdk:cnode1 -a -s SPDK00000000000001
$rpc_py nvmf_subsystem_add_ns nqn.2016-06.io.spdk:cnode1 Malloc1
$rpc_py nvmf_subsystem_add_listener nqn.2016-06.io.spdk:cnode1 -t tcp -a 10.0.0.2 -s 4420
Initiator端,运行perf(fio工具)。
# 连接到server,占用核4、5、6、7,读写类型randread,运行时间100秒
build/examples/perf -q 64 -o 4096 -w randread -t 100 -c 0xF0 -r 'trtype:tcp \
adrfam:IPv4 traddr:10.0.0.2 trsvcid:4420 subnqn:nqn.2016-06.io.spdk:cnode1'
2.4 了解tc配置
配置流量类别(traffic class,简称tc)和队列,是用好ADQ的关键。2.3.1的例子是建立2个tc。下面的例子是建立3个tc,方便起见分别用3种颜色表示。命令中@的左边表示占用cpu核的个数,右边表示从第几号核开始。
/usr/sbin/tc qdisc add dev eth10 root mqprio num_tc 3 map \
2 2 1 0 2 2 2 2 2 2 2 2 2 2 2 2 queues 4@0 6@4 2@10 hw 1
关键字“map”之后的字符串表示tc的map优先级。它将每个优先级0-15映射到指定的tc。映射中的索引(从零开始)是优先级,索引值指定tc编号。硬件队列根据命令末尾的配置映射到每个tc。所以,4@0 6@4 2@10表示:
tc0从队列0开始有4个队列(q0-q3)
tc1从队列4开始有6个队列(q4-q9)
tc2从队列10开始有2个队列(q10,q11)
再看优先级和队列的映射关系:
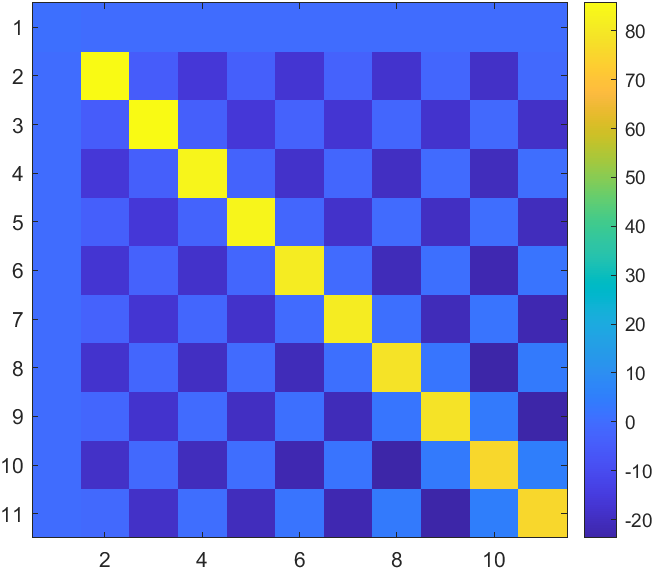
2 2 1 0 2 2 2 2 2 2 2 2 2 2 2 2表示tc2 tc2 tc1 tc0 tc2 tc2 tc2 tc2 tc2 tc2 tc2 tc2 tc2 tc2 tc2 tc2,排列顺序对应0-15优先级,如下图:
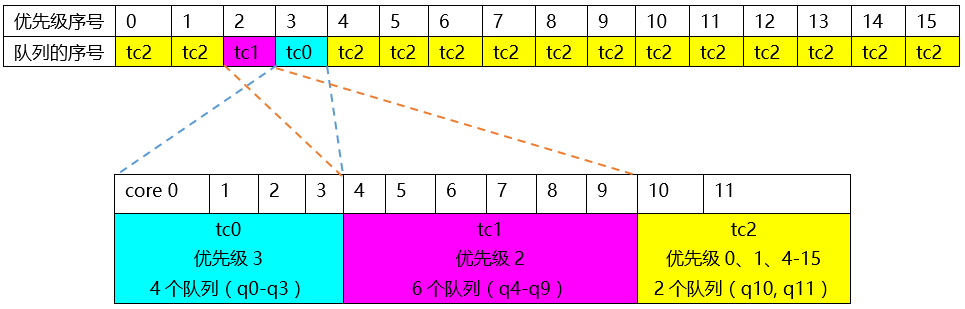
本例中,网卡硬件队列q0-q11对应CPU的core0-core11,那么可以看到:
优先级3映射到tc0,具有硬件队列q0-q3
优先级2映射到tc1、tc1,具有硬件队列q4-q9
优先级0、1、4-15映射到tc2,具有硬件队列q10和q11
这就很好地解释,为什么tc1的优先级在这里没有顺序映射,而是从第4个开始。
2.5 判断ADQ是否生效的几个方法
2.5.1 中断
ADQ启用时,FIO的过程中理想的状态下是没有系统中断的。下面的bash函数check_ints_result()可以判断有没有中断。

2.5.2 pkt_busy_poll计数器
本例中,tc1所在队列q2和q3,其Tx和Rx计数器均应处于活动状态。同时,不应有任何数据包通过tc0(即硬件队列0和1)。
watch -d "sudo ethtool -S eth0 | column"

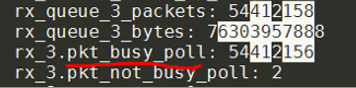
上面的屏幕截图显示了对称队列正在工作。如果Tx流量通过队列0或1,则表明未配置套接字优先级。理想情况下,tc1所在队列q2和q3的pkt_busy_poll计数器将增加。
2.5.3 busy_count数量
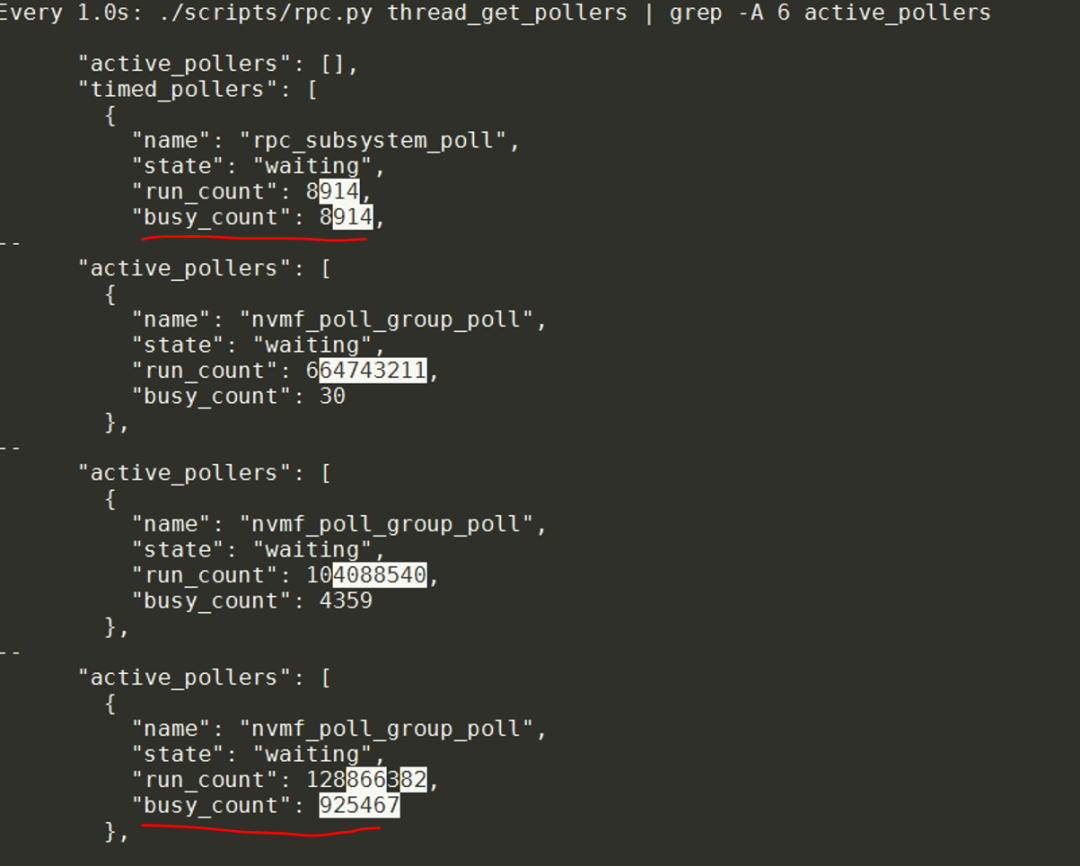
SPDK的RPC命令thread_get_pollers能够显示active_poller的busy_count参数。如果tc1有两个队列q2和q3,这里也应该有两个busy_count在增加。
3. 结 语
本文旨在演示在SPDK中实现ADQ最简功能的验证。用户还可以通过set_irq_affinity将网卡中断轮询绑定到多个cpu核心来提升性能。总的来说,ADQ 的目标是通过动态减少抖动和干扰来确保高优先级应用程序获得可预测的高性能。
4. Reference
1.《在SPDK中使能E810网卡ADQ 特性》
2.《CVL网卡的ADQ特性在SPDK的NVMF测试中的应用实例 - 上篇》
3.《CVL网卡的ADQ特性在SPDK的NVMF测试中的应用实例 -下篇》
4. Application Device Queues (ADQ) Resource Center (https://www.intel.co.uk/content/www/uk/en/architecture-and-technology/ethernet/adq-resource-center.html)

转载须知
DPDK与SPDK开源社区
公众号文章转载声明
推荐阅读
云端数据“上榜”了!
DPDK Release 22.11
Release notes for VPP 22.10
剖析SPDK读写NVMe盘过程--从hello_world开始


点点“赞”和“在看”,给我充点儿电吧~