在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
双向循环神经网络与概率图模型中的“前向-后向”算法具有相似性。
双向循环神经网络主要用于序列编码和给定双向上下文的观测估计。
由于梯度链更长,因此双向循环神经网络的训练代价非常高。
在序列学习中,我们以往假设的目标是: 在给定观测的情况下 (例如,在时间序列的上下文中或在语言模型的上下文中), 对下一个输出进行建模。 虽然这是一个典型情景,但不是唯一的。根据可获得的信息量,我们可以用不同的词填空,不同长度的上下文范围重要性是相同的。所以无法利用这一点的序列模型将在相关任务上表现不佳。
1.隐马尔可夫模型中的动态规划
这一小节是用来说明动态规划问题的, 具体的技术细节对于理解深度学习模型并不重要, 但它有助于我们思考为什么要使用深度学习, 以及为什么要选择特定的架构。

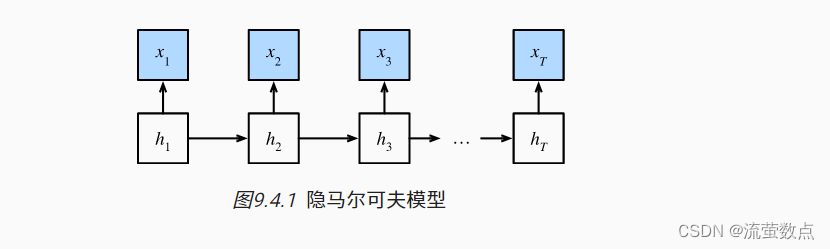
因此,对于有T个观测值的序列, 我们在观测状态和隐状态上具有以下联合概率分布:
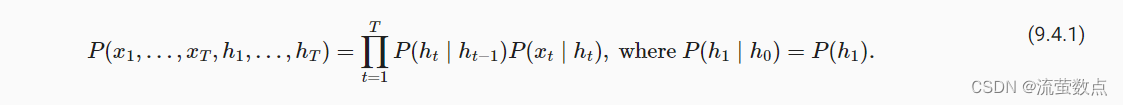

动态规划(英语:Dynamic programming,简称 DP),是一种在数学、管理科学、计算机科学、经济学和生物信息学中使用的,通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。动态规划常常适用于有重叠子问题和最优子结构性质的问题。
要了解动态规划的工作方式, 我们考虑对隐变量h1,…,hT的依次求和。 根据 (9.4.1),将得出:
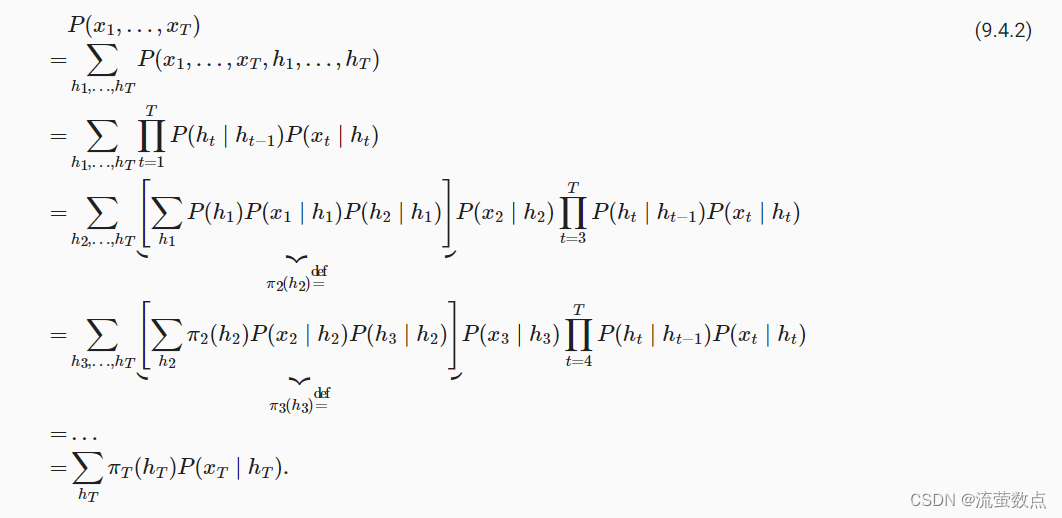
通常,我们将前向递归(forward recursion)写为:
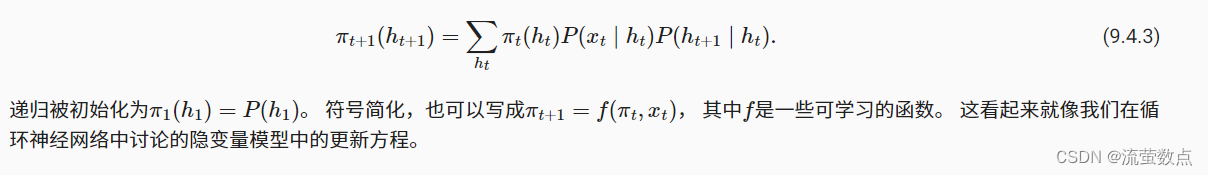 与前向递归一样,我们也可以使用后向递归对同一组隐变量求和。这将得到:
与前向递归一样,我们也可以使用后向递归对同一组隐变量求和。这将得到:

因此,我们可以将后向递归(backward recursion)写为:
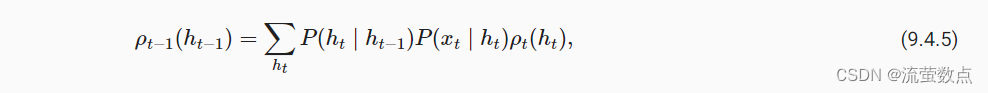
初始化ρT(hT)=1。 前向和后向递归都允许我们对T个隐变量在O(kT) (线性而不是指数)时间内对(h1,…,hT)的所有值求和。 这是使用图模型进行概率推理的巨大好处之一。 它也是通用消息传递算法 (Aji and McEliece, 2000)的一个非常特殊的例子。 结合前向和后向递归,我们能够计算
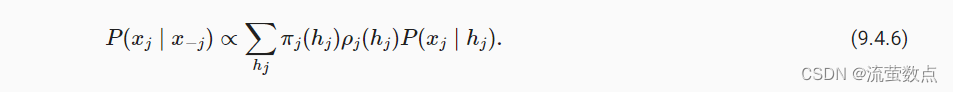 因为符号简化的需要,后向递归也可以写为
因为符号简化的需要,后向递归也可以写为=g(
,
), 其中g是一个可以学习的函数。 同样,这看起来非常像一个更新方程, 只是不像我们在循环神经网络中看到的那样前向运算,而是后向计算。 事实上,知道未来数据何时可用对隐马尔可夫模型是有益的。 信号处理学家将是否知道未来观测这两种情况区分为内插和外推, 有关更多详细信息,请参阅 (Doucet et al., 2001)。
2.双向模型
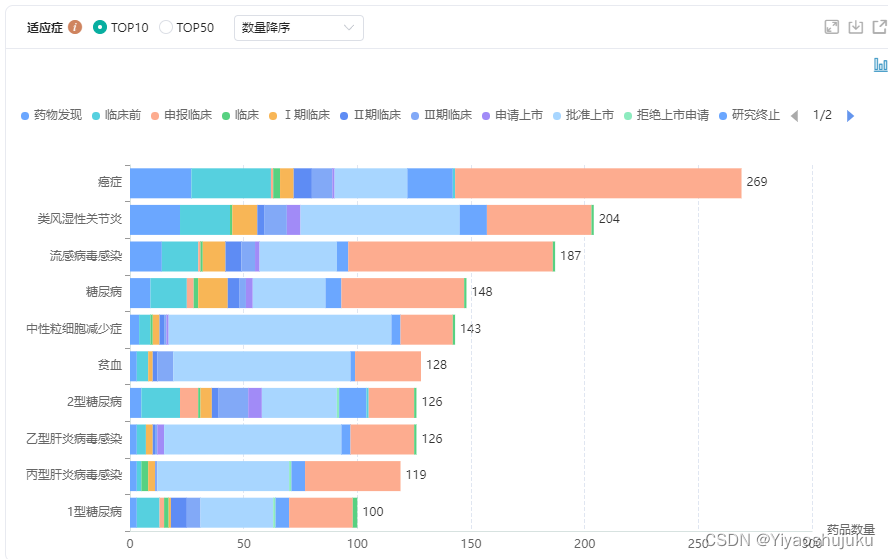
如果我们希望在循环神经网络中拥有一种机制, 使之能够提供与隐马尔可夫模型类似的前瞻能力, 我们就需要修改循环神经网络的设计。 幸运的是,这在概念上很容易, 只需要增加一个“从最后一个词元开始从后向前运行”的循环神经网络, 而不是只有一个在前向模式下“从第一个词元开始运行”的循环神经网络。 双向循环神经网络(bidirectional RNNs) 添加了反向传递信息的隐藏层,以便更灵活地处理此类信息。 图9.4.2描述了具有单个隐藏层的双向循环神经网络的架构。
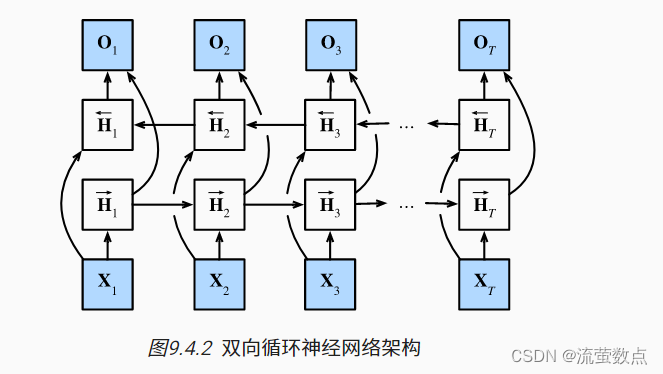
事实上,这与隐马尔可夫模型中的动态规划的前向和后向递归没有太大区别。 其主要区别是,在隐马尔可夫模型中的方程具有特定的统计意义。 双向循环神经网络没有这样容易理解的解释, 我们只能把它们当作通用的、可学习的函数。 这种转变集中体现了现代深度网络的设计原则: 首先使用经典统计模型的函数依赖类型,然后将其参数化为通用形式。
2.1定义
双向循环神经网络是由 (Schuster and Paliwal, 1997)提出的, 关于各种架构的详细讨论请参阅 (Graves and Schmidhuber, 2005)。 让我们看看这样一个网络的细节。

2.2模型的计算代价及其应用
双向循环神经网络的一个关键特性是:使用来自序列两端的信息来估计输出。 也就是说,我们使用来自过去和未来的观测信息来预测当前的观测。 但是在对下一个词元进行预测的情况中,这样的模型并不是我们所需的。 因为在预测下一个词元时,我们终究无法知道下一个词元的下文是什么, 所以将不会得到很好的精度。 具体地说,在训练期间,我们能够利用过去和未来的数据来估计现在空缺的词; 而在测试期间,我们只有过去的数据,因此精度将会很差。 下面的实验将说明这一点。
另一个严重问题是,双向循环神经网络的计算速度非常慢。 其主要原因是网络的前向传播需要在双向层中进行前向和后向递归, 并且网络的反向传播还依赖于前向传播的结果。 因此,梯度求解将有一个非常长的链。
双向层的使用在实践中非常少,并且仅仅应用于部分场合。 例如,填充缺失的单词、词元注释(例如,用于命名实体识别) 以及作为序列处理流水线中的一个步骤对序列进行编码(例如,用于机器翻译)。
3.双向循环神经网络的错误应用
由于双向循环神经网络使用了过去的和未来的数据, 所以我们不能盲目地将这一语言模型应用于任何预测任务。 尽管模型产出的困惑度是合理的, 该模型预测未来词元的能力却可能存在严重缺陷。 我们用下面的示例代码引以为戒,以防在错误的环境中使用它们。
pip install mxnet==1.7.0.post1pip install d2l==0.15.0from mxnet import npx
from mxnet.gluon import rnn
from d2l import mxnet as d2l
npx.set_np()
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
lstm_layer = rnn.LSTM(num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)

上述结果显然令人瞠目结舌。