笔记整理:王大壮
链接: https://aclanthology.org/2022.findings-acl.147v1.pdf
动机
关系抽取是一项重要的自然语言处理任务,旨在预测给定文本中两个给定实体之间的关系。其中,对文本上下文信息的良好理解对于实现出色的模型性能至关重要。在不同的上下文信息里,句法信息已被证明对任务有帮助。然而,现有研究大多数需要对现有基线架构进行修改以利用句发信息,而本文受预训练任务启发,设计了相应的句法依赖预测预训练任务来增强编码器,避免对基线架构的改动。
论文方法
本文方法主要可以分为3步,模型整体框架如下:

1.句法依赖提取
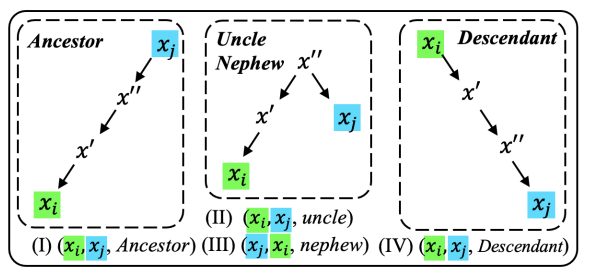
•首先需要使用一个已有的依赖分析工具来对获得输入的句法依赖树。•接着构建一阶依赖关系:句法依赖树中直接具有依赖关系的词与词及其依赖关系类型构成一个元组:( , ,type)(二阶及三阶依赖关系形式化同此)。•然后是构建二阶依赖关系:能通过一个中间词进行连接的两词,其关系类型根据两词与中间词之间连接方向性决定,见下图:

•最后是构建三阶依赖关系:能通过两个中间词进行连接的两词,其关系类型见下图:
2.句法依赖掩码及预测
以往的利用依赖信息进行预训练的方法主要关注于预测有依赖连接的上下文词,而本文主要关注于预测依赖信息及依赖关系,提出一种弱监督学习任务:掩码依赖预测来增强文本编码能力。依赖掩码掩码两种类型:
•掩码词连接( ,[MASK]),对应任务就是预测与该词有依赖关系的词;•掩码依赖关系( , ,[MASK]),对应任务就是预测两词之间的依赖关系。
接着需要恢复掩码依赖连接喝类型:
•首先应用基本编码器对输入进行编码,然后获得每个词的隐藏状态。•接着使用三个有相同结构的模块来恢复掩码依赖连接和类型(分别对应一阶、二阶和三阶依赖)•以一阶依赖为例进行说明(同理可以得到二阶情况和三阶情况):
1) 对依赖连接的预测得分(二分类):
2) 对依赖关系类型的预测得分(⨁代表拼接操作)(多分类):
3.利用句法引导编码器进行关系抽取
对上述预训练任务得到的句法引导编码器在关系抽取任务上进行微调,其预测得分如下:
计算方式如下:

实验
1.在BERT和XLNet的base和large版本上做了加上图卷积网络、图注意力网络以及三种依赖预测的对比实验:

可以发现本文利用依赖信息的方法优于基线及加上GCN和GAT来利用依赖信息的方法,同时,加入了二阶掩码预训练任务的模型在多数情况下表现出了更好的性能。
2.和以往工作的对比实验:
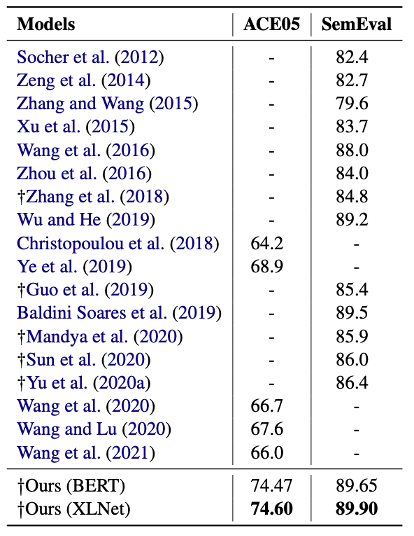
可以看到,本文所提出的方法在两个数据集上都达到了最优的性能,且由于本文方法不需要在关系抽取任务上额外输入句法依赖信息,将拥有更快地运行速度。
3.本文还做了在未经预训练任务的transformer上的实验,结果如下:

总结
该论文提出了一种使用句法依赖掩码和恢复的预训练任务来提升文本编码器对上下文的编码能力和需要深度理解文本的关系抽取任务。通过设计三种阶级的依赖掩码预测任务,最终的句法引导编码器被融合入了句法信息,同时,该编码器可以用于不同的需要句法信息的下游任务。在两个关系抽取英语基准数据集上的实验结果体现了所提出方法的有效性。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。