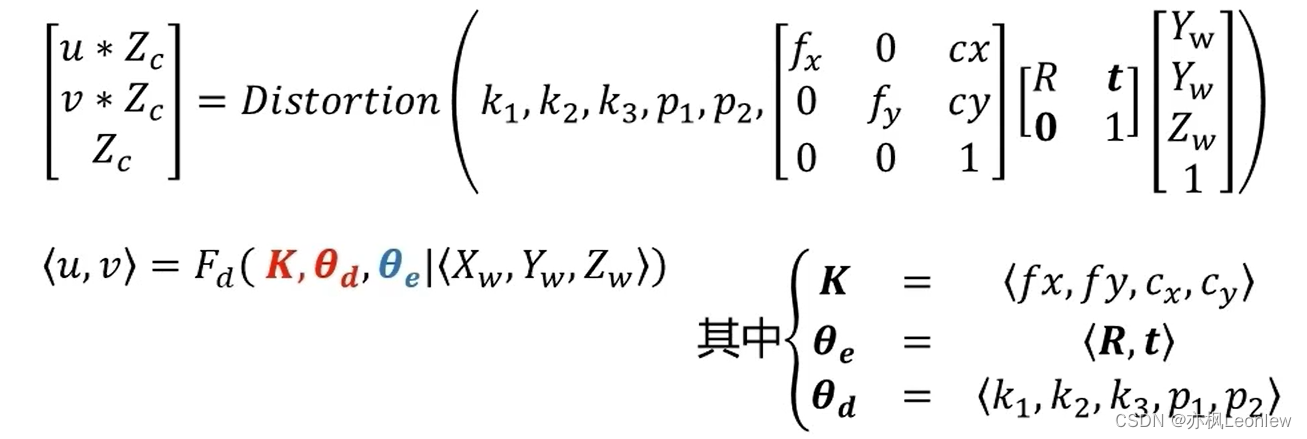目录
一、事故表现
二、事故问题分析
三、测试环境重现
四、解决方案
一、事故表现
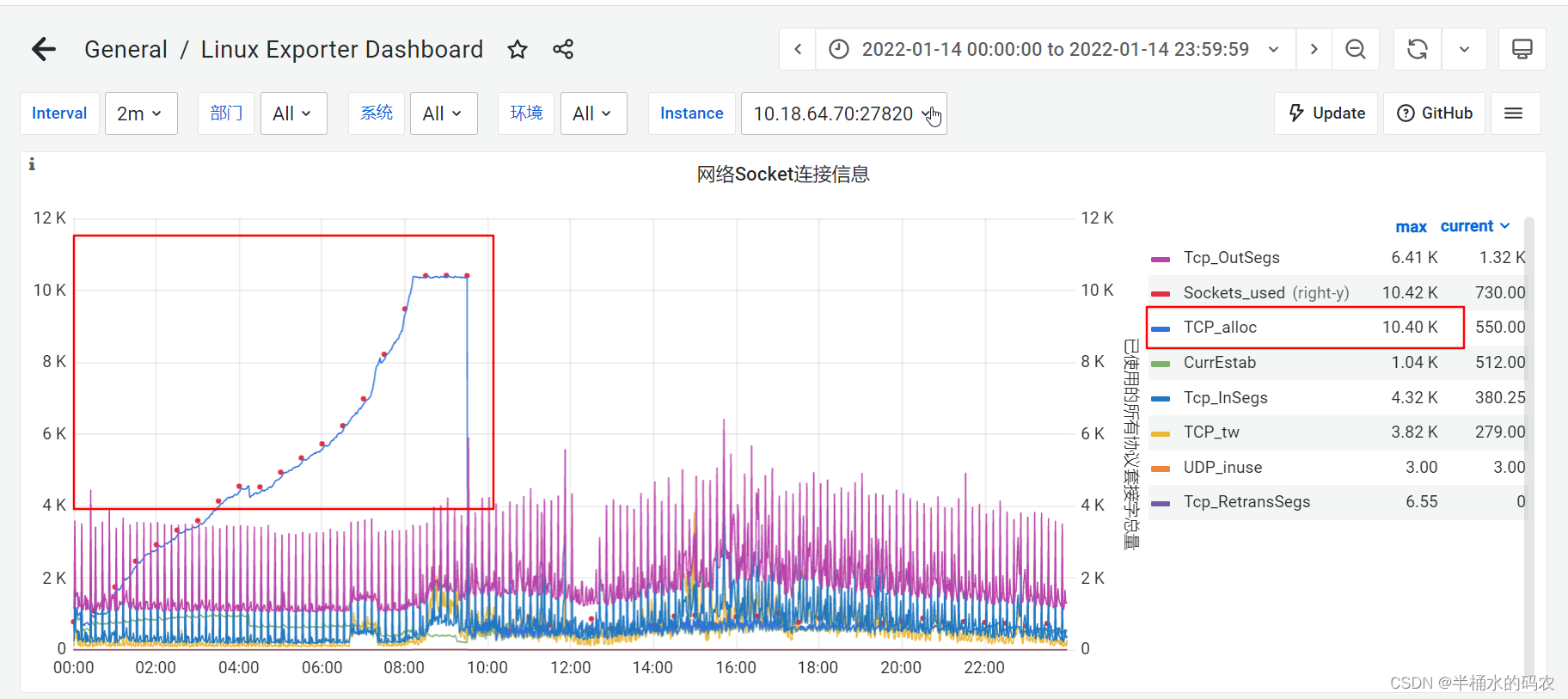
2022-01-14日凌晨00:00开始,TCP_alloc:已分配TCP连接,一直未释放。导致未释放的
TCP连接一直积压。最终服务LOGISTICS-DS-ES-COMMON-SERVICE假死,不响应数据。导致TMS排车调度无法查询运力资源池数据,排车失败。
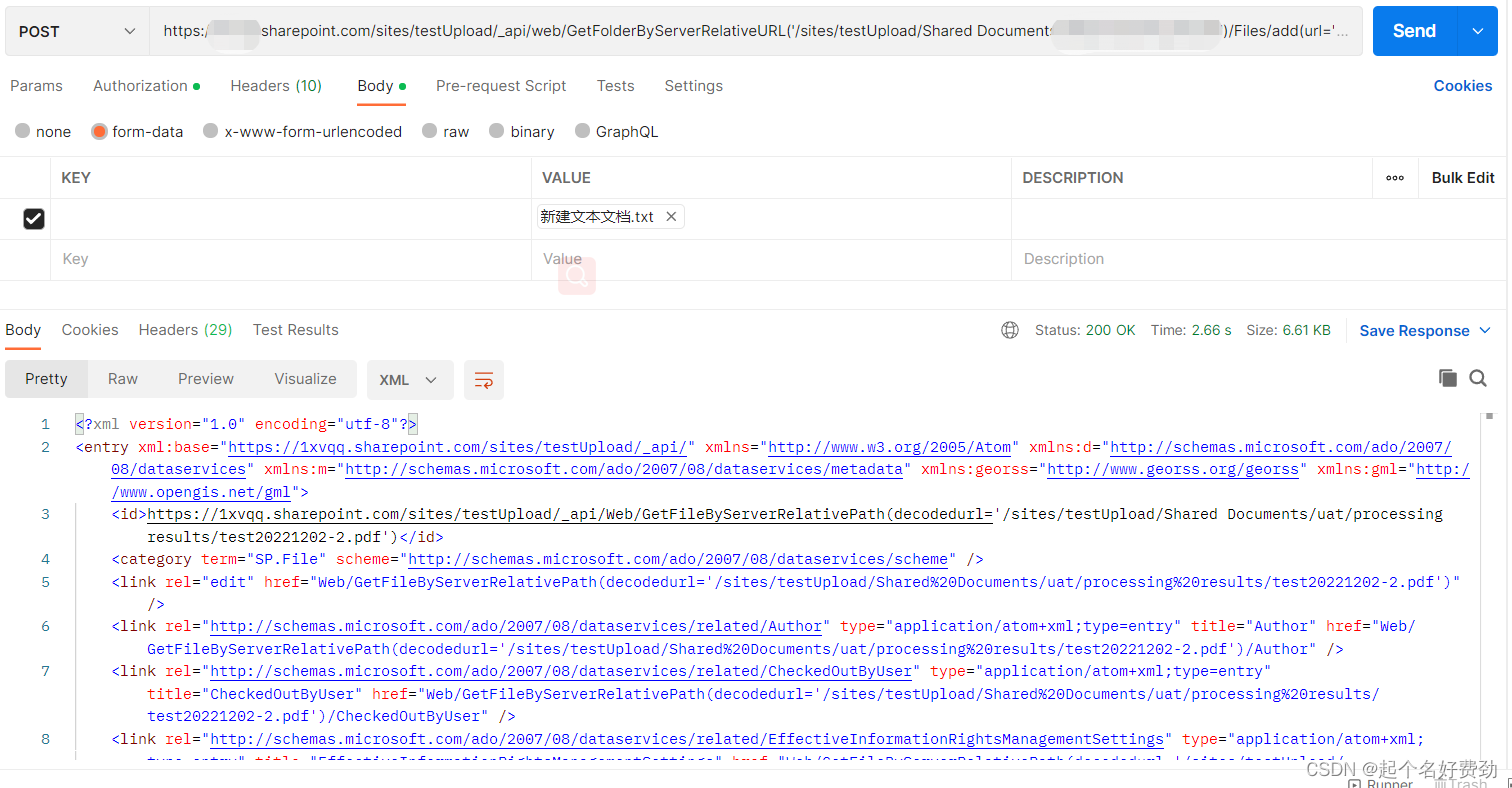
日志:
2022-01-14日志已经丢弃,截图为测试环境复现的报错截图。2022-01-13日晚23:30左右,日志开始大量报数据库密码错误。
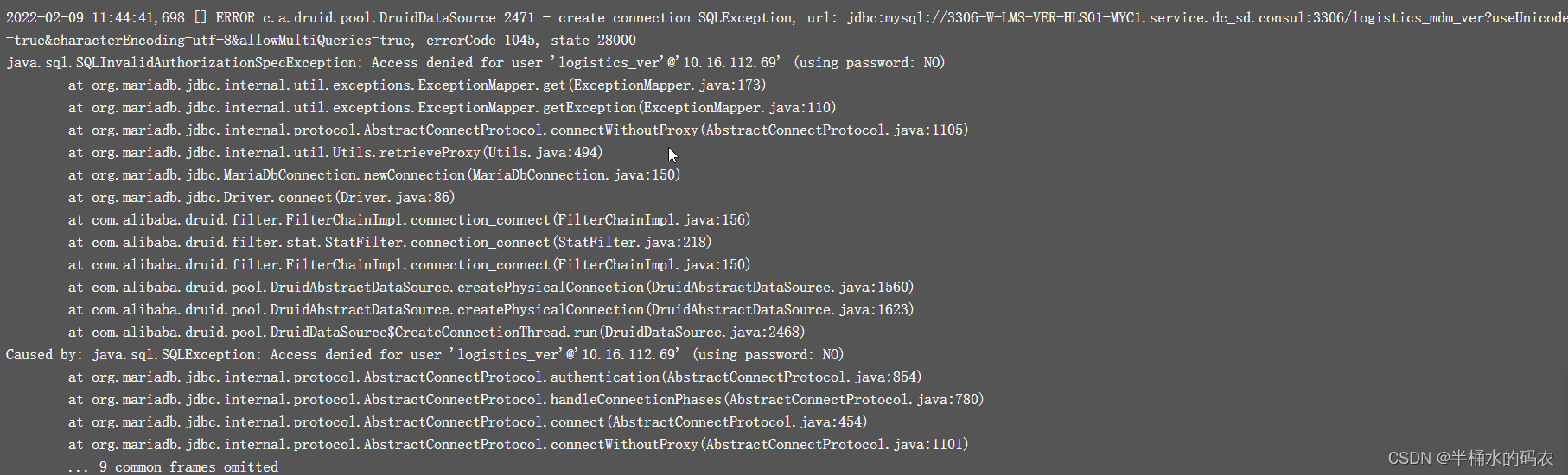
查看apollo配置中心的修改历史发现:服务在初识上线的时候,配置的是测试环境的数据库。因为此服务并未查询数据库任何信息,故之前一直没有报错。
二、事故问题分析
- 生产环境数据库连接配置成了测试环境数据库;
- 测试环境在2021-09月份,有人清空表数据,DC项目组修改数据库密码;
- 因为druid连接池的重试机制,会话一直保存在数据库内,并未报错;
- 2022-01-14 未知原因,数据库会话丢失,导致druid连接池用错误账号重试连接,日志报错;
- druid连接池不断重试,导致未释放的TCP连接一直积压
- 服务假死,无法响应请求。
三、测试环境重现
1.服务连接本地数据库,正常运行。
2.本地数据库修改用户名密码:(模拟9月份测试环境修改用户名密码)
3.断开本地网络连接,模拟会话丢失场景
4.测试环境日志丢失报错
5.tcp连接数逐步提升
6.服务假死,无法响应请求
四、解决方案
- 紧急解决方案:重新配置数据库连接信息,重启服务;
- 配置druid连接池重试机制:connectionErrorRetryAttempts=0;
- maven中去除mysql连接依赖;
- 运力资源池为运力中心自身的数据。现在为运力中心通过DC去查询运力中心自己的数据,不合理。要求运力服务直接查询运力资源池信息。